
 起点课堂会员权益
起点课堂会员权益AI 工程演化:从 Prompt 到 Loop,未来的方向在哪里
AI Agent 在解决实际问题时常常陷入「问答循环」的困境——工程师花费大量时间反复调试,效率甚至低于手动操作。本文深度剖析了从 Prompt Engineering 到 Loop Engineering 的四层技术演进,揭示了如何通过「闭环自动化」让 AI 真正实现「给你目标,自己跑完全程」的革命性突破。

一个工程师让 AI Agent 修一个数据库慢查询。Agent 改了代码,测试挂了;工程师把报错贴回去,Agent 再改,CI 又挂了;工程师再排查再贴,代码审查又没过——六轮之后,工程师花的时间比自己写还多。
这不是个案,而是当前 AI Agent 的结构性困境:Agent 会回答,但不会闭环。它能生成一个方案,但不能自己验证方案是否可行、不可行时自己修正、修正后自己推进到下一步。
用第一性原理追问:剥离”提示词”、”对话”、”工具调用”这些表象,人真正需要的是什么?
不是”一个能回答问题的聊天机器人”,而是”一个能把任务彻底完成的系统”。”彻底完成”意味着从识别问题到分析原因、制定方案、实现修改、验证测试、通过审查、最终合并——整个链条,闭环。
Loop Engineering 的本质:把人和 AI 的协作,从”问答式交互”升级为”闭环式自动化” 。
不是”我问你答”,而是”我给你目标,你自己跑完全程”。
这是 Loop Engineering 的核心哲学。
从 Prompt 到 Loop 的范式革命
在 Loop Engineering 出现之前,AI 工程经历了三次演进。每一层都试图解决更深层的问题,但每一层都有自己的结构性的局限。
四层不是替代关系,而是层叠关系——每一层包裹住内层,杠杆点逐层向远离裸模型调用的方向移动。
第一层:Prompt Engineering
核心问题:”我该对模型说什么?”
Prompt Engineering 的核心假设是:模型的能力是固定的,影响输出质量的关键变量是你怎么提问。思维链、少样本学习、角色设定、格式约束——各种提示词技巧应运而生。Andrej Karpathy 在 2023 年说:”最热门的编程语言是英语。”
但 Prompt Engineering 有四个结构性死穴:
- 上下文硬限制:提示词越来越长,迟早撞到上下文长度上限。塞多了反而稀释重要信息的注意力权重。
- 无状态遗忘:LLM 大多是无状态的,每次对话结束上下文清空。多轮迭代的任务,每次重启都要重新喂背景。
- 幻觉和注意力漂移:提示词越长,模型在中途”走神”的概率越大。精心设计的约束条件,可能在第 10 步就被悄悄忽略。
- 人始终是循环里的决策节点:最致命的一点。AI 生成结果 → 人审核 → 人修改 → 人复制 → 人粘贴 → 人验证 → 人反馈——人从来没有真正解放。
Prompt Engineering 的根本局限:它只能优化单次交互,无法构建一个能可靠、连续、自主运行多步骤任务的系统。提示词是接口,不是系统。
第二层:Context Engineering
核心问题:”我该让模型看见什么?”
Karpathy 推动了这次认知转变:与其纠结如何措辞,不如控制模型推理时能”看到”什么。上下文本身成了设计的核心对象——系统提示定义角色与约束,MCP 协议接入外部工具,RAG 即时注入检索结果,对话历史维持任务连贯性。
Anthropic 把 Context Engineering 定性为”Prompt Engineering 的自然演化”——问题的视角从”如何问一个好问题”转向了”如何设计一个好的信息环境”。
但 Context Engineering 有清晰边界。它解决了”信息给得对不对”,没有解决”任务跑得动不动”。一个被精心配置了上下文的 Agent,面对需要多轮迭代、跨会话执行的复杂任务时,依然会卡住——谁来跟进下一步?谁来判断上一步是否成功?谁来决定下一个操作?仍然需要人来维持。
致命的是 Context Anxiety(上下文焦虑) :随着上下文窗口被填满,模型进入”急于完成”的状态,匆忙收尾,质量骤降。
第三层:Harness Engineering
核心问题:”我该给 Agent 搭什么环境?”
Mitchell Hashimoto(HashiCorp 创始人)提出了核心洞察:每次 Agent 出错,与其修改提示词让它下次做得更好,不如改变系统结构,让这个错误在结构上无法再次发生。这是从”调教模型”到”设计防错系统”的根本转变。
Agent = Model + Harness。模型提供推理能力,Harness 把这个能力变成可信赖的、可重复的生产力。

Harness 解决了大量可靠性问题。OpenAI Codex 团队仅三人,五个月产出约 100 万行生产级代码,零手写——靠的不是更好的提示词,而是严格的 Harness 架构约束。
但 Harness 是静态的。它建好了车间、配好了工具、定好了流程,但谁来决定今天生产什么?谁来验收产品?谁来处理异常?——这些动态的、持续运转的问题,Harness 回答不了。
第四层:Loop Engineering
核心问题:”我该设计什么循环,让 Agent 自主跑?”
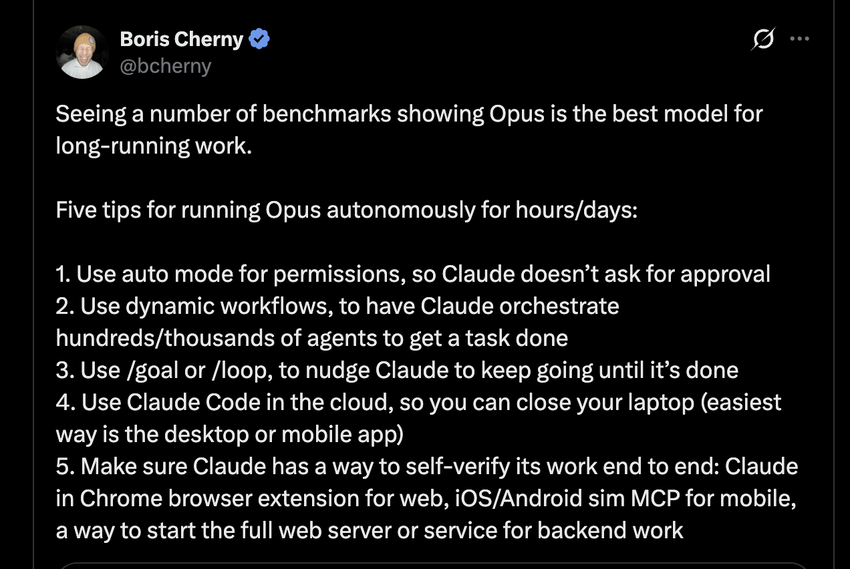
2026 年 6 月 2 日,Boris Cherny(Claude Code 作者)在 WorkOS Acquired Unplugged 活动上发言:”我不再提示 Claude 了。我有循环在运行,它们自己在提示 Claude,自己决定下一步怎么做。我的工作是写循环。”
2026 年 6 月 7 日,Addy Osmani(Google 工程总监)正式命名 Loop Engineering,并明确定义:”Replacing yourself as the person who prompts the agent. You design the system that does it instead.”
Harness 是环境(静态),Loop 是机制(动态) 。Harness 建好了车间,Loop 是排班和验收制度——决定每天生产什么、谁来做什么、怎么验收、异常怎么处理。
三、对比分析:有没有 Loop,差别在哪?
一个需要多轮迭代的工作任务(修 bug、优化查询、重构代码),典型流程是:
- 人识别问题,打开 AI 助手,输入提示词
- AI 生成方案 → 人复制执行 → 报错 → 人贴回错误信息
- AI 再生成 → 人再执行 → 测试失败 → 人再贴
- AI 再改 → 人再执行 → 审查不过 → 人再贴
- 循环往复,直到通过——或者人放弃
特征:每个环节都需要人手动推进。AI 是工具,人是发动机。人一离开工位,循环就停。AI 不记得昨天说了什么、项目有什么规范、上次踩过什么坑——每次从零开始。
有 Loop 时的理想工作流
- 人在 GitHub 提交 issue 或定义目标
- Loop 自动识别任务,触发处理
- Loop 读取项目上下文:代码库、文档、历史决策、团队规范
- Loop 在隔离环境中分析、实现、测试
- Loop 派验证者子 Agent 独立审查
- 通过验证 → 自动提交 PR;未通过 → 自主修正再迭代
- 需要人工拍板 → 带着上下文升级给人;不需要 → 自动合并
- Loop 记录处理经验,更新知识库
特征:人只在”定义目标”和”关键决策”时介入,其余环节自动闭环。第二天遇到类似问题,Loop 复用已有经验,更快完成。
数据佐证
这不是想象。Boris Cherny 从 2025 年 11 月起 100% 的代码由 Claude Code 产出,每天 10-30 个 PR。Anthropic 内部数据:每位工程师代码产出增长 200%,PR 合并量增长 67%。公开 GitHub 上约 4% 的提交已由 Claude Code 产出。
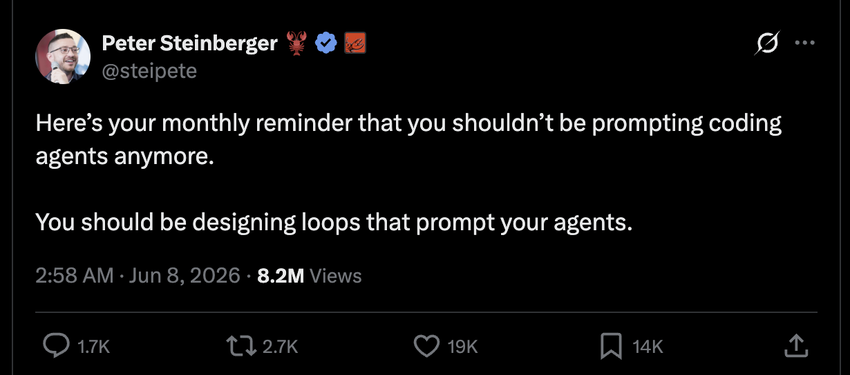
核心转变:发动机从”你”换成了一段一直在转的程序。你不再一轮一轮戳 Agent,而是设计一个会自动戳 Agent 的系统。
四、分析框架:”智能办公室”模型
综合前面的分析,我提出一个理解 Loop Engineering 的分析框架: “智能办公室”模型。
一个运转良好的公司办公室,本质上就是一个 Loop 系统:

一个任务进来,前台自动识别分配;执行者在自己的工位上干活,查阅档案获取知识;完成后质检员独立审查;日志记录全过程。下次类似任务,查日志即可复用。
Loop 就是把一个运转良好的办公室,自动化成 AI 系统。
五原语 + 记忆的详细拆解
1. Automations/Scheduling(自动触发)
Loop 的心脏。没有调度,就只是一次性运行。形式包括:Claude Code 的 /loop 命令、Codex 的 Automations 标签页、GitHub Actions cron、事件钩子(有人开了 PR 自动触发)。
2. Worktrees(工作树隔离)
当两个 Loop 同时编辑同一份代码,会出现 merge 地狱。Git worktrees 让每个 Agent 拥有独立的工作目录,执行完后清理。真正卡住并行能力的,往往不是能开几个 Agent,而是能审几个——审查带宽才是上限。
3. Skills(技能/项目知识)
项目意图的持久化。一个 SKILL.md 文件编码了项目约定、构建命令、代码规范、领域知识。没有 Skills,Loop 每次从零推导——这就是”意图债务”。写一次,每次都读,这是原则。
4. Plugins & Connectors(连接器)
让 Loop 碰到真实工具:GitHub PR、Jira/Linear tickets、Slack 通知、数据库查询。MCP 已经成为这套生态的通用协议层。连接器的完整性直接决定 Loop 能解决的问题边界。
5. Sub-agents(子 Agent)
最重要的结构性模式。写代码的 Agent 不能评判自己的工作——运动员不能兼任裁判。第二个 Agent(不同 prompt,有时用更强模型)负责验证。这种 Maker/Checker 分离,是无人值守 Loop 能让人安心走开的唯一保障。
+ Memory/State(记忆/状态)
模型没有跨会话长期记忆。Loop 必须读写持久化的东西:一个 STATE.md、一个 database row、一个 GitHub Project view。好的状态文件回答三个问题:当前在做什么?上次尝试了什么、结果如何?什么在等人工处理?
最小可用循环
一个最简单的 Loop 只需要四样东西:
- 一个触发:什么时候开始
- 一个写好的指令:要做什么
- 一个状态文件:记录过程和结果
- 一道验证门:如何知道做完了
顺序也不要反:先手动把这件事完整跑通一遍,整理成可复用的指令,包进循环,最后再配定时。
以github上的 cobusgreyling/loop-engineering 的项目为例
以github上的 cobusgreyling/loop-engineering 的项目为例,逐步拆解每一个环节的设计逻辑。理解这个流程的关键不是记住步骤顺序,而是弄清楚:每一步解决什么问题,跳过它会出什么毛病。
第一步:Schedule/Automation —— 任务从哪来?
这是 Loop 的起点,也是最容易被忽略的一步。很多工程师的直觉是”我手动触发就行了”,但手动触发不是 Loop,那叫脚本。Loop 的本质区别在于:它自己知道什么时候该动。
触发方式分两种:时间驱动和事件驱动。时间驱动就是 cron——每天凌晨两点扫描一次依赖更新;事件驱动就是钩子——有人提了 issue、有人推了代码、有人改了配置,Loop 自动响应。好的 Loop 设计,时间驱动负责”定期巡检”,事件驱动负责”实时反应”,两者互补。
这一步如果设计不好,后果不是”不工作”,而是”总在你不想它工作的时候工作”——比如在你演示的时候突然触发了重构循环。
第二步:Triage Skill —— 该做什么?谁来做?
任务进来之后,Loop 要做的第一件事不是动手,而是判断。这个判断包含两个层面:一是分类——这是 bug 修复、功能开发、依赖升级还是安全补丁?不同类别走不同流程。二是优先级排序——哪些该立刻处理,哪些可以排队,哪些直接拒绝。
Triage 为什么不能跳?因为如果没有分流,所有任务都会涌进同一条流水线。一个简单的依赖更新和一个涉及核心架构的重构,需要的资源、审批流程和验证标准完全不同。不区分就硬跑,轻则浪费 token,重则让高风险操作绕过了该有的审查。
Triage Skill 本质上就是”智能办公室”里前台的角色——不是自己干活,而是确保每一件事被送到正确的处理通道。
第三步:Read+Write STATE/Memory —— Loop 的眼睛和笔记本
动手之前,Loop 必须先”看清”当前状态。这一步做两件事:读和写。
读,是加载上下文:项目当前的 STATE.md 里记录了什么?上次跑到哪一步了?有哪些已知问题和团队约定?这些信息决定了 Loop 接下来的行为不会是”从零开始”的盲目操作。一个没有读状态的 Loop,就像一个从不看项目文档的新人——每次都重新踩同样的坑。
写,是更新状态:每一步执行后把关键信息写回去——做了什么、结果如何、还有什么没做。这一步如果缺失,Loop 就失去了跨迭代的记忆连续性。下次触发时,它不知道上次做了一半的工作,要么重复劳动,要么覆盖已经完成的部分。
Memory 的层次也很关键。粗分三层:即时状态(这次循环的执行记录)、项目知识(SKILL.md 等持久化约定)、历史经验(过去循环中学到的规则)。三层信息用途不同——即时状态保证当前循环不失控,项目知识保证行为符合团队规范,历史经验保证不在同一个地方跌倒两次。
第四步:Isolated Worktree —— 给每个任务一个干净的工作台
这一步解决的是并发冲突。当多个 Loop 同时运行时,如果都在同一个工作目录上操作,就像两个人同时编辑同一份文档——互相覆盖,merge 地狱。
Git worktrees 的设计思路是:每个任务克隆一个独立的工作目录,互不干扰。任务完成后,再通过标准的 Git 流程(分支、PR)合并回主分支。这个隔离不只是技术上的便利,更是一种结构性的保障——一个 Loop 的失败不会污染另一个 Loop 的工作成果。
但这里有一个容易被忽视的瓶颈:审查带宽。你可以同时开十个 worktree 让十个 Agent 并行干活,但谁审查这十个 PR?如果只有一个工程师审查,并行度再高也没用,瓶颈卡在人身上。所以 Isolated Worktree 的真正限制不是 Git 能开多少分支,而是你的审查队列能消化多少。
第五步:Implementer Sub-agent —— 干活的人
这是 Loop 的执行核心——一个独立的子 Agent,按照 Triage 分配的任务和加载的上下文,实际完成工作。它写代码、改配置、跑脚本,把”要做什么”变成”做完了”。
这里的关键设计决策是为什么是 Sub-agent 而不是主 Loop 自己做。原因有三个:
- 第一,上下文隔离——主 Loop 保留全局视角,子 Agent 只需要在干净、聚焦的上下文里工作,避免信息过载导致注意力漂移。
- 第二,模型选择灵活——实现可以用快模型省成本,验证可以用强模型保质量。
- 第三,可并行——多个子 Agent 可以同时跑不同的任务,主 Loop 负责调度。
子 Agent 的行为边界由 Skills 定义——它能调用什么工具、遵循什么规范、在什么条件下必须停下来问人。没有 Skills 约束的子 Agent,就像一个没有操作手册的新人,什么都敢做但什么都做不靠谱。
第六步:Verifier Sub-agent —— 说不的人
这是整个 Loop 设计中最关键的架构决策。实现者不能验证自己的工作——这不是管理建议,而是结构性约束。
为什么?因为 LLM 有一个系统性倾向:自我确认偏差。当模型刚完成一段代码,它会被自己的输出”锚定”——在审查时会倾向于认为自己的逻辑是对的,对显而易见的错误视而不见。这不是模型不够聪明,而是上下文的惯性:刚写完的逻辑还在工作记忆里占据主导地位,自然地顺着自己的思路检查。
所以 Verifier 必须是一个独立的子 Agent,运行在干净的上下文中。它看不到实现过程,只看到最终产出和验收标准。它拿到的不是”这段代码好不好”,而是”这段代码是否满足以下清单”。清单来自哪里?来自你预先定义的 Skills、测试用例、代码规范——所有客观的、可逐条检查的标准。
如果这一步缺失或弱化,Loop 会”规模化地生产自信的错误”——跑得越快,错的越多,而且每次都觉得自己没问题。
第七步:Tests+Gates —— 客观的验收尺子
Verifier 的主观判断之外,Loop 还需要一层机器验证。测试套件、类型检查、lint、编译——这些都是不可谈判的硬门。通过就是通过,不通过就是不通过,不存在”差不多”。
这一层的设计哲学是:能用机器判定的,绝不依赖 AI 判断。AI 可以评估代码质量、架构合理性,但”测试全过””无新增 lint 报错””构建成功”这些事,交给确定性程序远比交给另一个 LLM 可靠。
Gate 的设置需要平衡两个极端:太松,坏代码溜过去;太严,Loop 永远通不过,空转烧 token。好的 Gate 策略是分级的——编译和核心测试是硬门(不过不能继续),lint 和代码风格是软门(不过可以继续但必须修复),性能回归是观察门(记录但不阻断)。
第八步:MCP/Git/Tickets —— Loop 的手脚
验证通过之后,产出需要落到真实的系统里才有价值。这一步是 Loop 和外部世界的接口:提交 Git commit、创建 Pull Request、更新 Jira/Linear ticket、发送 Slack 通知、触发下游 CI。
MCP(Model Context Protocol)正在成为这一层的标准协议。它的价值不在于某个具体工具的对接,而在于统一接口——不管是 GitHub 还是 Jira 还是 Slack,Agent 都通过同一套协议访问,新工具的接入成本从”写一整套集成代码”降到”注册一个 MCP server”。
这一步如果缺失,Loop 就是一个封闭的沙箱——能跑通,但产出落不到任何真实系统里,等于白干。
第九步:Need Human? —— Loop 的刹车和方向盘
这是整个流程的分叉点。Loop 在这一步判断:这件事我能自己拍板,还是必须升级给人?
判断依据不应该是”我能不能做”,而是”做了之后的后果我能不能兜住”。一个配置更新,回滚成本很低,可以自动通过;一个涉及数据库迁移的操作,出问题影响面大,必须人工确认。
好的升级设计不是简单的”是/否”二选一,而是带着上下文升级。不是扔给工程师一句”需要你确认”,而是附上:做了什么、为什么这么做、验证结果如何、可能的风险是什么、推荐的操作是什么。工程师拿到的不应该是一个决策题,而是一个已经有充分信息的审批题——他只需要判断,不需要再从头理解。
两条出路:
Yes(需要人)→ Escalate with context:带着完整上下文升级给人。Loop 暂停在这个节点,等待人工决策后继续。暂停不是失败,而是设计——这就是 Loop 比无人看管的自动化更安全的地方。
No(不需要人)→ Commit/PR:自动提交。但”自动提交”不意味着”无人负责”——每一次自动提交都有完整的审计日志、可追溯的决策链路。出了问题,你能回溯到是哪个 Loop、基于什么判断、在什么时间做了这个决定。
流程总结:为什么这九步缺一不可?
这九步构成了一个完整的认知闭环:感知(Schedule+Triage)→ 理解(Read State)→ 隔离(Worktree)→ 执行(Implementer)→ 验证(Verifier+Tests)→ 行动(MCP/Git)→ 决策(Need Human)→ 产出(Commit/PR)或升级(Escalate)→ 记忆(Write State) 。
跳过任何一步,都会在某个维度上打开漏洞:

一个设计得当的 Loop,不是每个环节都做到极致,而是每个环节都做到刚好不漏。
四层演化的核心脉络

从 Prompt 到 Loop,人类把对 AI 的控制权从更具体的层级移交到更抽象的层级。最终,人只需要关心三件事:我的目标是什么?哪些规则必须遵守?什么时候需要我来拍板?
五、开源项目案例与范式转变总结
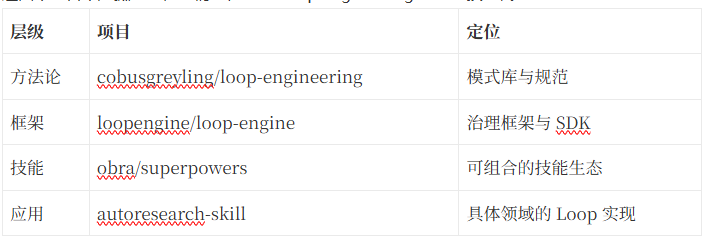
案例1:cobusgreyling/loop-engineering——Loop Engineering 的方法论文档
GitHub:cobusgreyling/loop-engineering | 210+ stars | MIT License
这个仓库不只是代码,更是 Loop Engineering 的方法论文档。它提供了:
- 7 个生产级模式:覆盖从简单定时任务到复杂多 Agent 协作的场景
- 3 个 CLI 工具:直接在命令行中管理 Loop
- 安全指南:权限管理、密钥轮换、审计日志
- 真实失败案例:Ralph Wiggum 循环、过度烘焙(Overbaking)等
它的五原语框架已成为 Loop Engineering 的标准参考。核心主张:Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead.
用”智能办公室”模型解读:这个仓库就是办公室的”管理制度手册”——定义了每个角色该做什么、流程该怎么走、出了问题怎么处理。
案例2:loopengine/loop-engine——企业级 Loop 治理框架
官网:loopengine.io | npm 包 @loop-engine/*
这是一个完整的 Loop 治理框架,提供了 SDK、Actors(执行者)、Signals(信号)、Adapters(适配器)等模块,支持 Vercel AI SDK、OpenAI、Anthropic 等多种后端。
核心模式:wrapTool——把 AI 工具调用包进治理循环。高影响操作(如金额超过 $5000 的采购单)需要人工审批,低影响操作自动通过。这直接解决了”AI 自主行动的边界在哪”这个关键问题。
生产级示例展示了 Loop 从简单到复杂的递进:
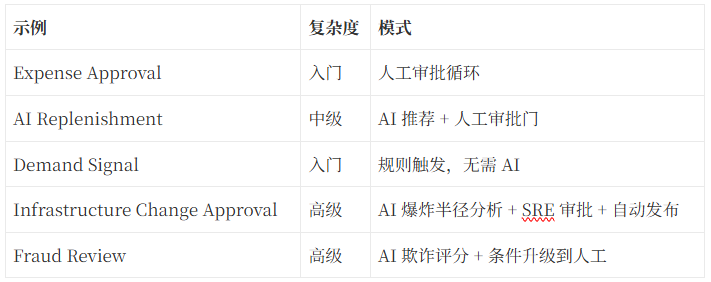
关键设计思想:不是全自动化,而是高自动化 + 关键节点人工审批。这呼应了 Loop Engineering 的核心原则——人保留决策权,AI 保留执行权。
用”智能办公室”模型解读:loopengine 就是办公室的”审批系统”——什么级别的事情谁有权批,什么操作需要升级,都有明确定义。
案例3:obra/superpowers——223k+ 星的 Agentic 技能框架
GitHub:obra/superpowers | 223k+ stars | MIT License
这是目前最成功的 Agentic skills framework。Jesse Vincent(Request Tracker 作者)构建了 14 个技能,覆盖完整的开发生命周期,强制 AI 遵循专业开发流程。
7 阶段开发工作流:Brainstorming → Git Worktrees → Planning → Execution → Testing → Code Review → Finalization
核心创新是 Subagent-Driven Development:每个任务派一个全新的子 Agent 执行,两级审查:
- Spec Compliance:代码是否符合规格
- Code Quality:代码质量是否达标
强制 TDD:RED-GREEN-REFACTOR——先写测试(红),再写实现(绿),再重构。代码写在测试之前?删掉重来。
跨平台支持 Claude Code、Cursor、Codex、OpenCode、Gemini CLI。2026 年 1 月被 Anthropic 官方接受进入 Claude 插件市场。
用”智能办公室”模型解读:superpowers 就是办公室的”员工培训体系”——它不是给办公室添工具,而是给员工立规矩。技能自动触发,Agent 不需要被提醒就遵循专业流程。设计哲学很直白:流程必须清晰到”一个热情但缺乏判断力的初级工程师也能遵循”。
案例4:autoresearch-skill——Loop 在研究领域的延伸
受 Karpathy 的 autoresearch 启发,这个项目展示了 Loop 的另一扇门:不只是工程任务可以 Loop 化,研究任务也可以。给定一个研究目标,AI 自动搜索、分析、总结、迭代,直到得出结论或需要人工介入。
用”智能办公室”模型解读:这是把 Loop 从”工程部门”扩展到”研究部门”——同样的循环机制,不同的工作内容。
四个项目的生态定位
这四个项目不是孤立的,它们正在形成 Loop Engineering 的完整技术栈:
六、Loop Engineering 的关键设计问题
什么时候该用 Loop?
不是所有任务都适合 Loop 化。四个必要条件,缺一个成本就容易大过收益:
- 每周至少重复一次:低频任务不值得自动化,搭建成本靠反复运行摊平
- 结果能自动验证:有测试、有编译、有明确的对错判断。否则人还是要一遍遍看
- Token 预算扛得住:循环一定会有空转和无效尝试,计量收费下账单跟着跑
- Agent 有高级工程师级工具:要能跑测试、查日志、开 PR
典型翻车模式

设计一个好 Loop 的核心问题
- 完成由谁判定? AI 自己?独立验证 Agent?人?——不能让执行者兼任裁判
- 反馈信号从哪来? 测试结果?用户行为?独立评审 Agent?
- 什么时候必须停? 迭代次数上限、预算上限、风险升级——没有止损的 Loop 要么烧钱,要么”规模化地生产自信的错误”
- 记忆写入什么、何时被消费? 哪些信息需要持久化?什么情况下读取?写入的东西经过验证了吗?提炼成可复用形式了吗?下次任务开始时会读到吗?——三个环节断掉任何一个,记忆就只是占地方的日志
记忆的递进层次
记忆不是”存聊天历史”——那本质是个回收站。一个理想的记忆回路应该完成五步递进:
出错并记下来 → 弄清为什么错 → 验证自己的诊断 → 把诊断提炼成通用规则 → 新任务直接查规则而不是重新踩坑
弱模型停在第一步,记忆库就是一堆错题集。强模型走完全程,把教训变成规则。
两个关键设计原则
原则一:给验收清单,而非操作步骤。 告诉 AI”要做到哪些标准”,而不是”按这个步骤做”。一条模糊的标准(”代码质量要高”)会让整个 Loop 空转,换成可检查的写法(”测试全过且无新增 lint 报错”)它才收敛得了。
原则二:实现者和验证者必须分离。 模型自我批判的效果不好,它会倾向于认可自己刚做完的东西。有效的做法是再开一个独立的验证 Agent,在干净的上下文里打分。
Loop 之后:第五层范式会是什么?
从前面的分析中可以提取出一条清晰的演化暗线:

每一层都解决了上一层解决不了的问题,同时又暴露了新的结构性瓶颈。按这个逻辑推演,Loop 的瓶颈在哪,第五层就该从那长出来。
Loop 的三个结构性瓶颈
瓶颈一:Loop 不能设计自己。 当前的 Loop 需要人来定义——触发条件、流程步骤、验收标准、升级规则,全部靠人预设。Loop 跑得再快,它的结构是静态的。如果业务变化了、团队规范调整了、或者 Loop 自己发现了更优的执行路径,它没法自我重构——只能等人来改。
瓶颈二:Loop 之间不能对话。 一个团队可能有代码质量 Loop、安全扫描 Loop、依赖更新 Loop,它们各跑各的。代码质量 Loop 重构了一段代码,安全扫描 Loop 发现引入了漏洞,依赖更新 Loop 又改了版本——三个 Loop 互相不知道对方在干什么,产出互相打架。单个 Loop 的闭环能力再强,Loop 之间的协调仍然靠人。
瓶颈三:Loop 不能质疑目标。 Loop 擅长回答”怎么把这件事做好”,但从不问”这件事该不该做”。你让它优化查询性能,它就优化——哪怕整个表应该被弃用了。你让它修 bug,它就修——哪怕修的成本比重写还高。古德哈特定律的根源就在这里:Loop 优化你给的目标,而不是优化你真正想要的。
这三个瓶颈指向同一个方向:Loop 缺少元认知能力——对自身、对同伴、对目标的反思能力。
第五层的三个可能形态
基于这三个瓶颈,第五层范式可能沿着三条路径分化,最终汇合。
形态一:Meta-Loop——自设计的循环
核心问题:”谁设计 Loop?”
当前:人设计 Loop → Loop 执行任务。第五层:Loop 观察自己的运行数据 → Loop 修改自己的结构 → 改进后的 Loop 继续执行。
这不是递归的玄学,而是有明确机制的闭环:
- 性能监控:每个 Loop 记录自己的运行指标——成功率、空转率、token 消耗、人工介入频率、修复后回退率
- 瓶颈定位:Meta-Loop 分析这些指标,识别结构性问题——比如”80% 的升级发生在 Triage 之后”,说明 Triage Skill 的分流逻辑需要调整
- 结构修改:Meta-Loop 不是直接改代码,而是修改 Loop 的配置和规则——调整触发条件、重写验收清单、增加或删除步骤、修改升级阈值
- AB 验证:修改后的 Loop 先在影子模式下并行运行,与原 Loop 产出对比,确认改进后替换
这与当前 Loop 的关键区别是:当前 Loop 的结构是设计时确定的,Meta-Loop 的结构是运行时演化的。就像生物体——DNA 是初始设计,但免疫系统在学习、神经突触在重组,个体的结构在生命周期中持续调整。
风险也很明确:Meta-Loop 的古德哈特问题更难检测。如果 Meta-Loop 优化”减少人工介入次数”,它可能把升级阈值调到极低,让本该由人判断的高风险操作自动通过。所以 Meta-Loop 的验收标准比普通 Loop 更难写——你验证的不只是”任务做对了”,而是”系统在往对的方向演化”。
形态二:Ecosystem Engineering——Loop 之间的市场与协议
核心问题:”多个 Loop 如何协作?”
当 Loop Engineering 普及后,每个团队、每个项目、甚至每个开发者都会有自己的 Loop。问题从”如何设计一个 Loop”变成”如何让一百个 Loop 不打架”。
这不是规模问题,而是协调问题。类比经济学:一个工厂内部的生产调度(单个 Loop)和管理学相关,但一千个工厂之间的资源配置(多个 Loop 协作)和经济学相关——后者需要市场、价格信号、合约机制。
Ecosystem Engineering 需要三层基础设施:
- 协议层:Loop 之间的通信标准。一个 Loop 完成了代码重构,如何通知安全扫描 Loop?不是靠人贴 Slack,而是靠协议——一种机器可读的事件总线,每个 Loop 发布自己的产出和状态变更,订阅方自动响应。
- 协商层:当两个 Loop 的目标冲突时,如何仲裁?代码质量 Loop 要重构,部署稳定性 Loop 要求冻结变更——谁优先?这需要一种优先级市场:每个 Loop 对自己的操作声明影响范围和紧急度,由仲裁规则或更高层的调度 Loop 决定执行顺序。
- 信任层:一个 Loop 的产出被另一个 Loop 消费时,前者如何证明自己的质量?这需要一种可验证的信任链——不是”我测过了你信我”,而是附上验证记录、测试报告、审计日志,消费方可以独立验证。
loopengine/loop-engine 的 wrapTool 模式已经在这个方向上迈出了一步——它给工具调用包了一层治理,本质上就是在单个 Loop 内部建立信任边界。Ecosystem Engineering 是把这个逻辑扩展到 Loop 之间。
形态三:Intent Engineering——目标的精准表达与质疑
核心问题:”我真正想要的是什么?”
这是最深的一层。当执行被完全自动化后,意图表达就成了最稀缺的资源。
Prompt Engineering 教你说清楚”做什么”,Context Engineering 教你给对”看什么”,Harness Engineering 教你建对”在哪做”,Loop Engineering 教你设计”怎么循环”——但所有这些的前提都是:你知道自己要什么。
现实是,大多数时候你并不真的知道。你以为你要的是”优化查询性能”,实际上你要的是”用户不抱怨页面慢”——前者是指标,后者是意图。指标可以被游戏,意图不能。
Intent Engineering 要解决的不是”如何更好地表达意图”,而是如何发现你表达的意图和你真正的意图之间的差距。这需要一种全新的机制:
意图反问:系统在执行前,不只接受你的目标,还反向追问——”你优化查询性能,是为了降低成本还是改善体验?如果是改善体验,也许该优化的是前端缓存而非数据库查询。”这种追问的质量,决定了 Loop 是在优化指标还是在优化意图。
结果回溯:Loop 完成后,不只报告”任务完成”,还评估”完成的结果是否真正改善了你关心的问题”。测试全过了,但用户满意度没变——说明目标和意图之间存在鸿沟。
意图演化:人的意图不是静态的。随着 Loop 的执行和结果的积累,你对问题的理解会深化,意图本身会进化。Intent Engineering 需要一种机制,让 Loop 不只是执行固定目标,而是跟着你的理解一起迭代目标。
这呼应了文章开头的哲学:每一次跃迁的”术”在升级,但”道”始终是同一个——你对问题本身的理解,是所有技术范式无法替代的核心。Intent Engineering 是把这句话从哲学判断变成工程实践:不再假设”人知道自己的意图”,而是把”发现和校准意图”本身作为系统的一部分。
八、范式转变总结
从 Prompt 到 Loop,AI 工程经历了四次跃迁。暗线很清楚:人一直在练一件事——把”我想要什么”说得越来越精确。一开始说给一个模型听,现在说给一整套能自动运转的系统听。
每一次跃迁,”术”在升级,但”道”始终是同一个问题:你对问题本身的理解,是所有技术范式无法替代的核心。
- Prompt Engineering 的术是措辞技巧,背后的道是:你需要知道你想要什么,才能说清楚。
- Context Engineering 的术是信息架构设计,背后的道是:你需要知道什么信息是相关的,才能给对。
- Harness Engineering 的术是系统结构设计,背后的道是:你需要理解 Agent 的失败模式,才能设计防错结构。
- Loop Engineering 的术是循环程序设计,背后的道是:你需要知道什么叫”完成”,才能让 Agent 自主停止。
有一个值得认真对待的担忧:当 Agent 越来越自主,当 Loop 越来越精密,会有人把 Loop Engineering 当成一种”外包判断力”的方式——让 Loop 决定做什么,让 Agent 决定怎么做,人只需要按一下”启动”。Boris Cherny 对此的表述很克制:”你可以用 Loop 来更快地完成你理解的工作,也可以用 Loop 来回避对工作的理解。这是两件完全不同的事。”
Loop 是放大器。能放大你的能力,也能放大你的懒惰。
在 Loop Engineering 时代,人保留的是意图表达权、规则制定权、关键节点决策权;AI 获得的是执行权、优化权、自主迭代权。这是一次权力结构的重组——不是人变得不重要了,而是人需要在更高的层次上发挥作用。
给实践者的落地路径
- 找任务,别找循环:先在日常工作里找一件事——重复做过三次以上,而且结果能客观判断对错。找不到这样的事,就还没到上循环的时候
- 自己先跑通一遍:手动从头到尾做一次,把每一步、每个判断都记下来。你自己都说不清的流程,别指望机器替你想清楚
- 把”做完了”写成一把尺子:把”做得好”这种模糊话改成机器能逐条检查的条件。写不出可验证标准,通常说明你自己还没想清楚
- 把指令整理成能复用的一块:写成固定指令、Skill 或文档。写一次,以后每次都调用
- 给它配一道会说”不”的关:一个测试、一次检查、一道人工审核门都行。没有任何东西能反驳的循环,等于让 Agent 自己给自己打分
- 最后才挂定时,小预算试跑:一开始给小额度,盯紧两个数:烧了多少 token,错误率多高。确认它真在干正事,再慢慢放权
本文由 @一葉 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pexels,基于CC0协议






- 目前还没评论,等你发挥!


