
 起点课堂会员权益
起点课堂会员权益我下了 Obsidian 三次,终于搞懂 LLM Wiki 该怎么用
从下载到弃用再到真正掌握,Obsidian 知识库的探索之路充满曲折。本文揭秘如何让 AI 成为你的知识管家,从框架搭建到内容整理,再到定期体检,一步步教你打造真正属于自己的智能知识库。那些你曾踩过的坑,或许正是开启高效学习的关键转折点。

最近刷朋友圈,隔三差五看到有人晒 Obsidian 的知识库截图。几个做 AI 的朋友也在群里聊,说卡帕西弄了一个 LLM Wiki,用大模型自动维护自己的知识库,全靠 AI 整理。他发了一条相关的推文,然后公众号、视频号、即刻都在聊这个事。
弄得我好奇心上来了,我也下了 Obsidian。图标是紫色的宝石,挺好看的。我点开过几次,每次看到空白的界面不知道下一步该做什么,然后又关了。过了几天又打开,建了一个叫「笔记」的文件夹,在里面建了一个空白文件,不知道放什么内容又关了。
我身边的朋友有几个跟我一样的,下了删、删了下,重复了几次。反正到最后都没有用起来。我们都感觉像是在学一个新的软件,不是在弄知识库。也不是 Obsidian 不好,只是不知道用它来干嘛。
我也是这样,直到最近才搞清楚怎么用。
LLM Wiki 是什么
你平时问 AI 问题,它回答完就没有然后了。下次你再换一个角度去问,它又要重新想一遍。你给它上传一些文档让它读,它每次都是重新看,然后拼一个答案告诉你。

LLM Wiki 不一样。它不是让 AI 每次都去翻你的资料,而是把你看过的东西整理成一本属于你的百科全书。你往里面放一篇文章,AI 不光写总结,还会更新已有内容,比如这篇文章提到的人物、概念,或者跟之前哪篇文章有冲突,它都会帮你整理好。你放的内容越多,这本百科全书就越厚,问出来的东西也就越准。
你只需要负责往里面放资料、提问题。AI 会帮你整理、归纳、维护。
我踩过的三个坑
之前照着卡帕西 GitHub 上的方法,我让 Codex 帮我弄了一套知识库。但是打开 Obsidian 一看全是英文。虽然我知道每个单词什么意思,但是连在一起看就觉得不对劲。也不是看不懂,就觉得这个东西是他的不是我的,就像走进了别人的书房,书架上的书都是按别人的喜好去摆放的。
然后我就让 Codex 帮我改成中文。改完之后确实看着清晰多了,但是文件夹在那里,我也不知道该往里面放些什么。然后我用 Obsidian 的浏览器插件 Web Clipper 收藏了几篇 AI 的文章,也用 Obsidian里的Open Claudian插件连AI,帮我整理过几次笔记。说没用,还是有用的。但就像有一本很好的笔记本,拆开之后也不知道往上面写什么。
后来我回想这段经历,发现卡住的地方有3个。这种情况可能也不止我吧,大部分人应该也差不多。
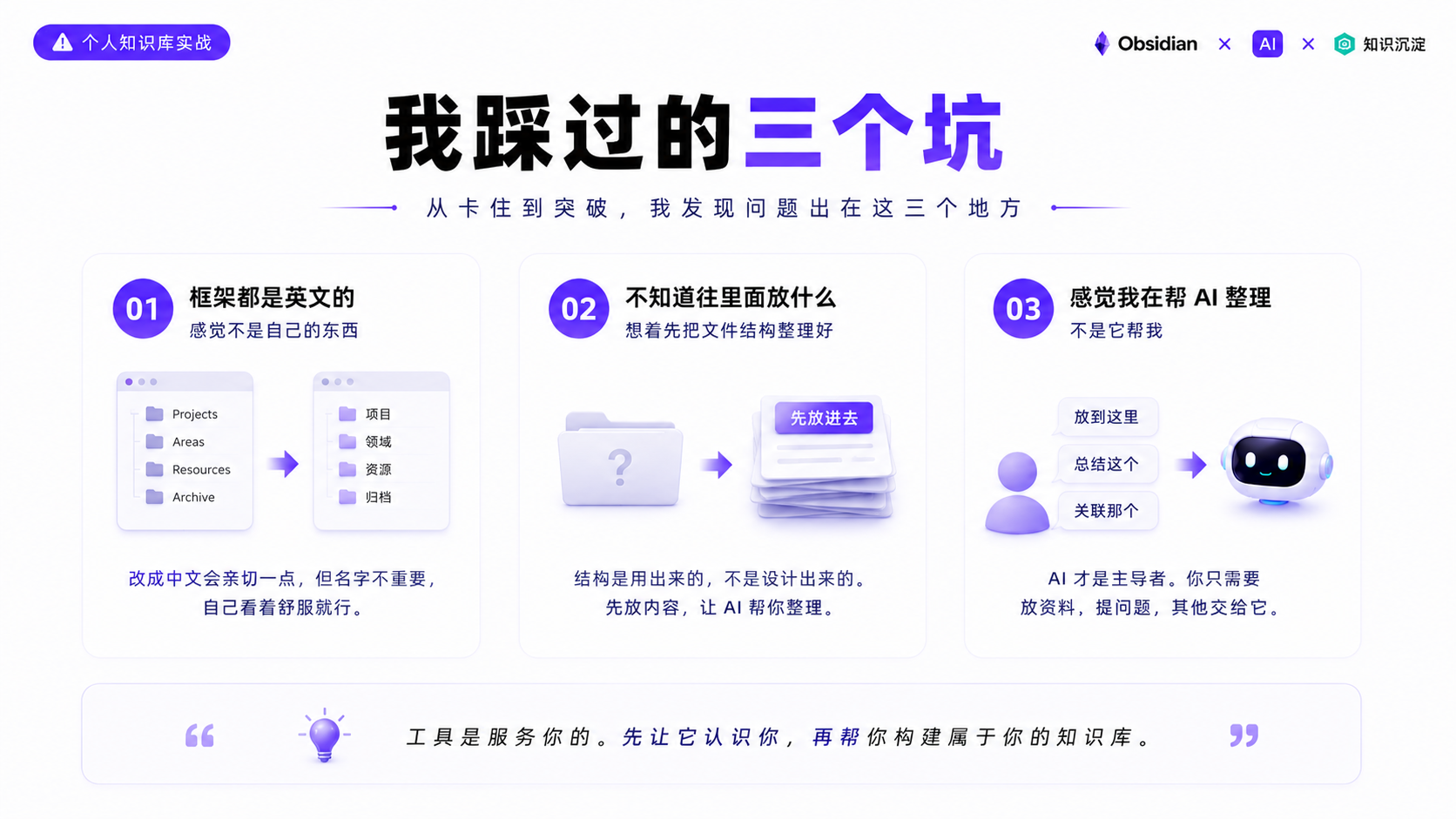
第一个卡点:框架都是英文的,感觉不是自己的东西。 不是不认识单词,只是这个框架不是为你建的,还是全英文的,就会觉得这是别人的框架。改成中文看着会亲切一点,心理上会觉得这个东西是你的。
但其实文件夹叫什么名字也不重要,每个人都有每个人的习惯,自己看着舒服就可以了。这种事不用纠结,也不用觉得改成中文是在偷懒。工具是服务你的。
第二个卡点:不知道往里面放什么,想着先把文件结构整理好。 这种情况很普遍。我当时也这样,先建好生活、工作、学习的文件夹,再往里建子文件夹,想等结构清楚了再放内容。
但这个逻辑有问题。结构是用出来的,不是提前设计出来的。你不知道会放什么,就不用先管结构,把最近看的内容放进去就行,让 AI 帮你整理,整理完就知道结构该怎么弄了。
卡帕西自己也说,他的知识库就是一边用一边构建的。他也不是先设计好再开始用的,先往里面扔了几篇论文,发现处理得不够好就去调规则,发现索引不够清晰就去改格式。规则都是碰到实际情况改出来的,不是坐着凭空想出来的。
第三个卡点:感觉我在帮 AI 整理,不是它帮我。 我之前用 Obsidian,就是把它当一个文件夹。我告诉 AI 这篇文章要放到什么文件夹,哪个笔记需要总结,哪个内容跟另一个相关,这些都是我在指挥 AI 做。
但 LLM Wiki 的设计不是这样的。在这套体系里 AI 是主导者,你只需要提供内容并告诉它归档到知识库,剩下的总结怎么写、哪些内容有关联、索引和日志怎么更新,都由 AI 自己决定。
这两种用法感觉完全不一样。第一种越用越累,因为活基本是你自己在干,AI 只是搬运工。后者越用越轻松,因为你只做两件事:放资料、提问题,AI 自己会决定怎么归类、怎么链接、怎么更新。
那这个时候我知道应该让 AI 来主导,但实际操作的时候,AI 生成的框架跟我还是没关系。它不知道我是做什么的,也不知道我关心什么内容,不知道我的工作生活重心在哪里。它建的还是一个通用模板,跟其他人都是一样的。
先让 AI 认识你
转折就是突然脑子灵光一闪,因为我平时跟 AI 聊天很多,工作上的、生活上的问题都会去跟它讨论。然后有一天突然想到:AI 已经知道了我的很多信息,我的职业、我关心的领域、最近在做的一些项目和事情,知道我思考问题的方式。这些都在之前的对话里面。
但是我用 Obsidian 的时候,AI 都不知道这些信息。相当于我在用一个全新的 AI 工具,需要重新开始告诉它怎么整理、怎么分类。
想到这个之后,我不是手动去改知识库,而是让 AI 先把它知道的关于我的信息都整理出来。
我用了这段提示词:
你是一个信息提取助手。任务:扫描我们的全部对话历史,为我整理一份个人信息档案。
提取与输出规则
只写有证据的内容:对话中明确陈述的,标注「✓ 已确认」;需要推断的,标注「~ 推断」,并注明推断依据。
没有信息的类别直接跳过,不要填充”未提及”或空占位符。
有矛盾时:并列列出两条原始表述,不要自行调和。
提取类别(有信息才写,无信息跳过)
身份:姓名/称呼、所在地、使用语言
职业:职位、公司/行业、核心职责、当前工作目标或挑战
技能与工具:专业能力、常用软件/平台、正在学习的内容
当前项目与任务:进行中的项目、遇到的具体问题、进展状态
偏好与风格:沟通方式、决策风格、明确表达过的喜好或厌恶
背景:教育、工作经历、兴趣爱好
其他:以上之外被明确提及的个人细节
输出格式
按信息量多少排序(最丰富的类别在前)。最后附一行「置信度提示」:标出哪几条是推断、应重点核查。
AI 给我整理了很多内容,我看到的时候有点感叹,为什么那么久之前的聊天内容它都知道,还知道我喜欢用的几个决策思维方式。
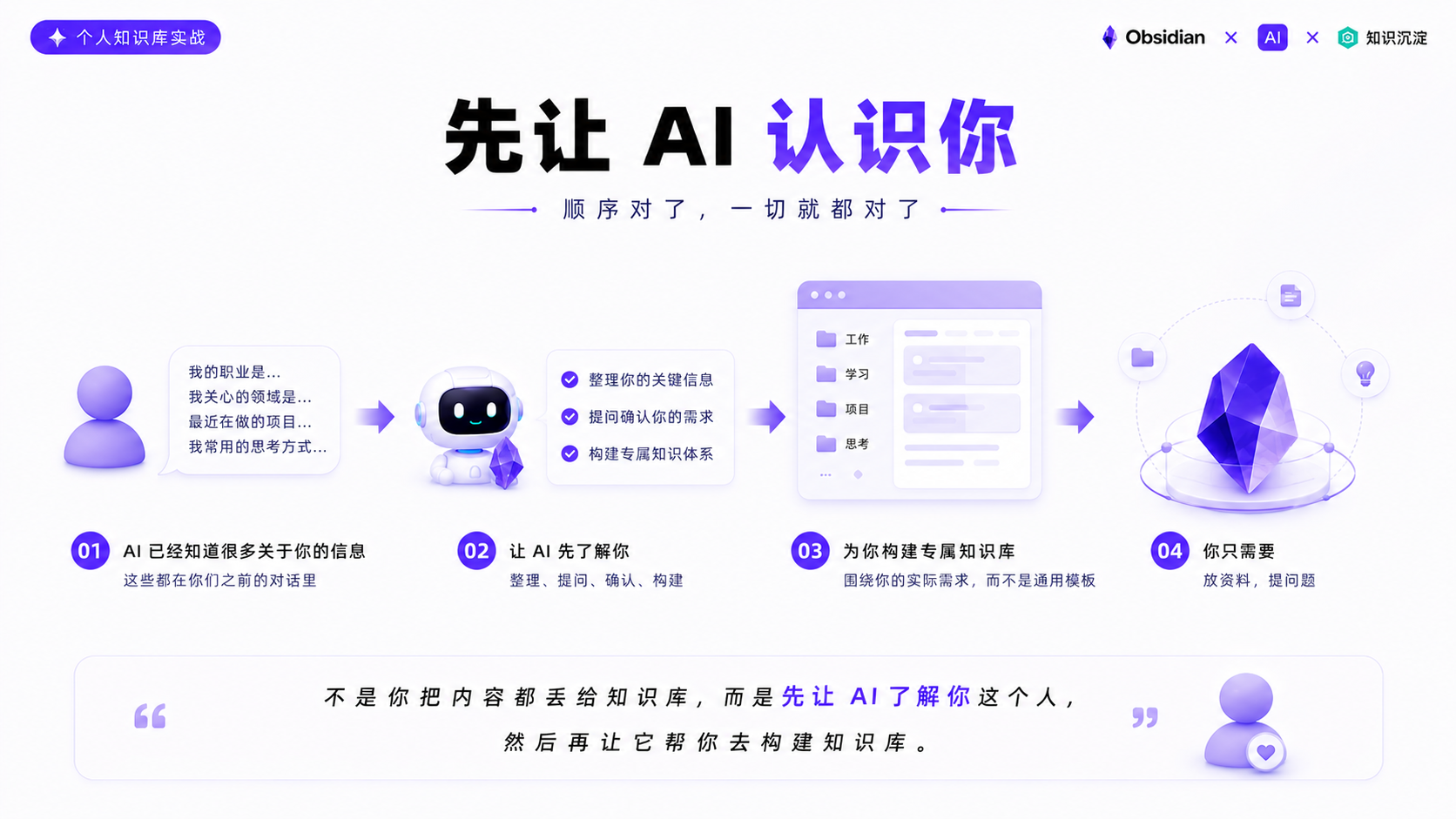
拿到这些信息之后,我就把这些发给 Codex,让它帮我建一个专属于我的知识库结构,用了另外一段提示词:
角色
你是我的「个人知识库架构师」,直接在我电脑上创建和维护文件。目标是搭一个能持续生长的本地知识库:一套互相链接的 Markdown 文件,全方位记录我(生活/工作/学习),边聊边沉淀,不重复问,不重新拼。
架构原则(参考 Karpathy 本地知识库思路)
分三层:素材层——原文原样存档,只读不改;笔记层——把素材和我的回答提炼成结构化 Markdown,用 [[wikilink]] 互相链接;规则层——AGENTS.md,写清这个库怎么读、怎么维护,换对话、换模型照此接手。
第一步:动手前先问我两件事
Q1 — 存哪里:给我完整本地路径,拿到后再建文件。
Q2 — 最想先围绕什么方向深挖:A 工作流/创作系统 B 学习计划 C 健康管理 D 财务记账 E 项目管理 F 人际关系 G 灵感收藏 H 说不准,先跳过。选了什么优先围绕那个方向;选 H 则边聊边摸,线索够了再确认。
第二步:拿到路径后,在该目录下创建
素材/(原始资料,只读不改)
生活.md(健康作息/家庭关系/财务消费/兴趣/性格价值观/居住通勤)
工作.md(职位公司/当前项目/技能工具/关键同事/职业目标/工作偏好)
学习.md(在学什么/学习目标/进度方法/时间安排)
index.md(目录:每个文件一行摘要 + 最近更新日期)
log.md(时间线:
## YYYY-MM-DD 格式,记录每次更新了什么)
AGENTS.md(规则层)+ 内容相同的 CLAUDE.md(供 Claude Code 使用)
若已有核心目标,另建 目标_[名称].md。若路径下已有同名文件,列出冲突问我,不擅自覆盖。
工作方式
一次只问一个问题,顺着回答往深挖;有核心目标时优先围绕它问。
我每答一题,立即写进对应文件,更新 index.md 和 log.md;链接统一用 [[文件名]] 或 [[文件名#章节]]。
新旧信息冲突时,标注 ⚠️ 待确认:原「旧」vs 今「新」,告知我,等确认再覆盖。
不编造我没说过的内容;不确定就问,不猜。
删除或整体覆盖已有文件前必须告知我确认;新建和追加直接执行。
我说「体检」时,扫描全库,返回三类清单:过时条目、内部矛盾、孤立笔记。
现在开始
先问我那两件事(路径 + 核心需求),等我回答,再动手建库。
然后 Codex 问了我几个问题,我回答之后它就开始构建了。
打开 Obsidian 看到的时候,感觉这跟之前生成的那个英文框架完全不是一个东西。之前那个就是一个模板,大家都是一个样。现在这个,就像一个很熟悉你的人帮你搭好了每个分类。工作文件夹里填好了我的项目,学习文件里也列了最近在研究的几个方向,分类的逻辑都是围绕我的实际需求出发的。
所以不是你把内容都丢给知识库,而是先让 AI 了解你这个人,然后再让它帮你去构建知识库。顺序对了,一切就都对了。
现在我是怎么用的
我现在基本上就是看到一篇好的文章,用 Web Clipper 一键存到素材文件夹,然后跟 AI 说把这个归档到知识库。它就会自己去读,然后去总结、更新相关的页面。有时候一篇文章会跟另外几篇文章链接上,另外一篇文章又多了一段新的总结。我不需要去管这些,它自己都可以做好。
之前想到一个问题,就是看了一些关于 Agent 设计的文章,想知道它们共同的观点是什么。我就直接问,知识库里面都有积累,它就把几篇相关文章的观点总结出来做一个对比。这种跨文档的对比,自己翻笔记很麻烦。

还有一次写竞品分析的时候,我去问知识库里面关于某个竞品的问题。它把我几个月前收录的一篇文章和最近收录的一个内容串到了一起,提了一个我自己都没注意到的变化。如果没有知识库帮我记着几个月前那篇文章,我自己都忘了这个信息。
偶尔看看 Obsidian 的关系图谱,看到密密麻麻的点和线的连接,还有一些孤立的点。这些内容看着好像没什么用,但是看到密密麻麻的画面就觉得积累了不少东西。
现在我也还在摸索,也没有特别会用。但跟几个月前比,我至少知道了这个工具在帮我做什么。它不是微信的收藏夹,也不是另外一个笔记工具,它是一本自己会长大,变厚的书。我只需要负责给它提供内容,它就能帮我把内容变成知识。收藏夹是收藏了然后就忘了,知识库会把你收藏的内容连起来,每次存都在给整本书多加一根连接线。
知识库也需要体检
但是知识库用久了还是会变乱。内容收录多了之后,有些页面链接不到其他内容,又有了那种东西很多但不好找的感觉。放着不管的话,可能又变成了另一个微信收藏夹,越来越乱。
然后我想到卡帕西的 LLM Wiki 是可以让 AI 定期给知识库做体检的。我写了一段提示词发给 Codex:
角色
你是我的 Obsidian 知识库体检助手,可以读取我的本地知识库目录。
目标
定期检查我的 Obsidian 知识库,发现结构问题、断链、重复内容、空页面、孤岛页面、未整理资料、待确认信息和过期内容。
执行步骤
扫描我的知识库目录。检查断链、重复文件、空页面、孤岛页面。检查素材区是否有长期未整理的内容。检查总索引是否覆盖了重要页面。找出标记为「待确认」「待整理」「TODO」「待补充」「未完成」的条目。输出简短体检报告。
报告格式
健康分:0-100
本次发现的问题
最优先处理的 3 件事
建议下一步怎么整理
重要规则
默认只检查,不修改文件。除非我明确说「请修复」,否则不要创建、删除、移动、重命名或改写任何内容。
隔一段时间它就会帮我体检,告诉我有哪些问题。我只需要跟它说「修复」,它就会去帮我整理。也不麻烦,也不需要每天都做,隔段时间看一下就可以了。
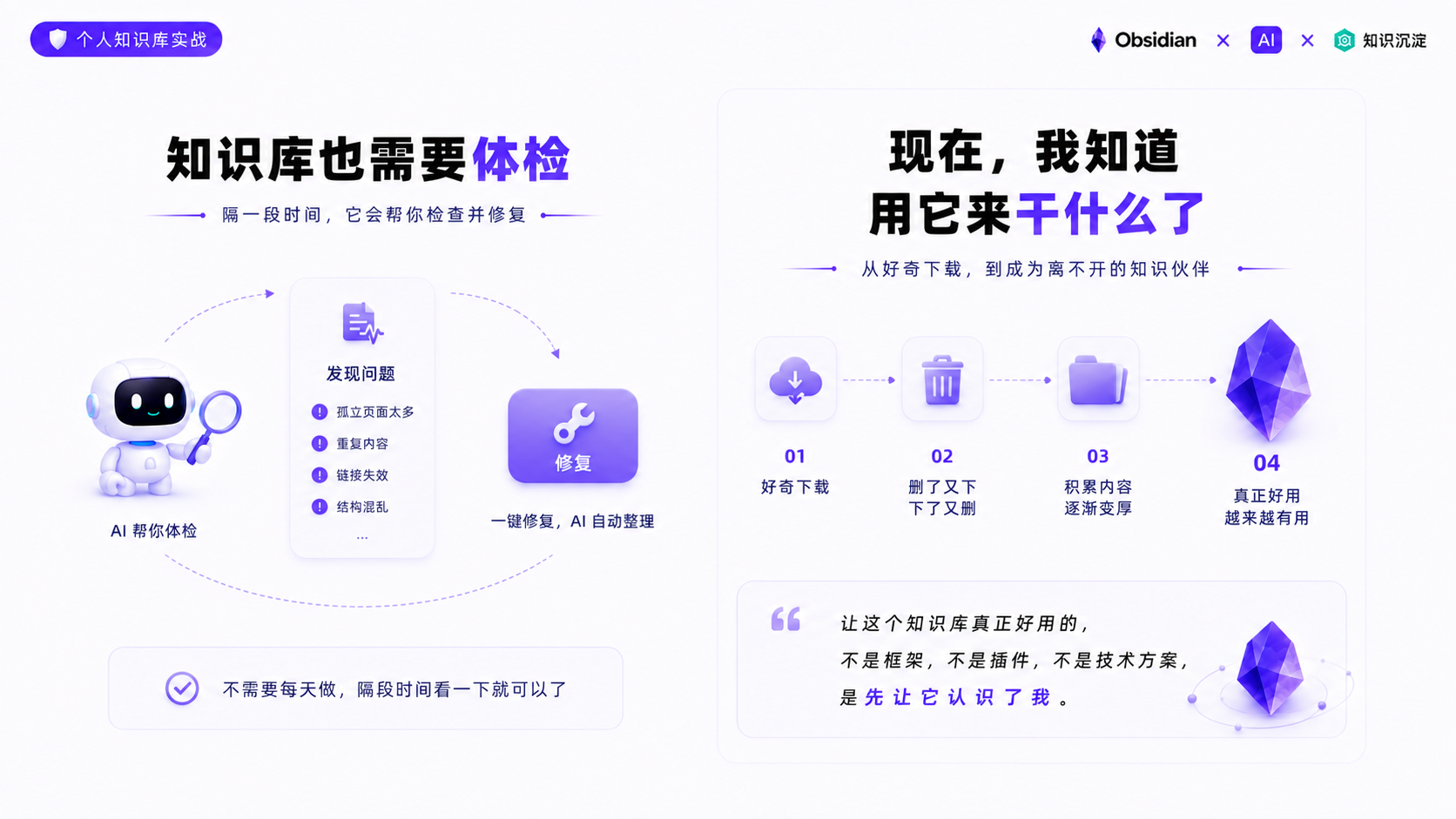
Obsidian 还是之前那个紫色的宝石图标。但跟之前不一样的是,我现在知道用它来干什么了。
从一开始好奇地下载,到删了又下、下了又删,到现在知识库里收集了不少内容。回头看也不是很复杂。让这个知识库变得好用的,是先让它认识了我。
本文由 @王三思 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


