
 起点课堂会员权益
起点课堂会员权益做推荐业务,这4种机器效果测评方法你应该知道
在与策略相关的产品功能(搜索、排序、推荐)中,往往都涉及机器学习算法,因此评估推荐效果就转化为评估机器学习算法模型的好坏。那如何评估最终推荐的效果呢?本文作者梳理分析了4种方法,供大家参考和学习。

我们一般以人工标注为准,即看做真实结果,用各种率去衡量机器预测和真实结果之间的差距。评估方式有很多种,各有各的优点。
R\P\A\F值
用Recall、Precision、Accuracy、F值,评估单个机器学习算法的效果,是最常见、最基础的方法。
对象分类:
(1)二分类:每一个评估对象有唯一的标签,YES or NO。如低俗、标题党文章。
(2)多分类(机器需要识别的标签数包含3个及3个以上,一般情况下,每一种标签的识别结果都是我们的关注目标)
- 单标签,每一个评估对象有唯一的标签,选择大于等于3,如文章分类。
- 多标签,每一个评估对象有多个标签,如文章兴趣点、文章关键词。
1. 二分类
人工标注结果为“真”的样本记做T(True),人工标注结果为“假”的样本记做F(False);
机器预测结果为“真”的样本记做P(Positive),机器预测结果为“假”的样本记做N(Negative)。
将其转化为矩阵,有四种结果:
- TP:预测正确,预测情况是P,因此真实情况也是P。
- FP:预测错误,预测情况是P,因此实际情况是N。
- FN:预测错误,预测情况是N,因此实际情况是P。
- TN:预测正确,预测情况是N,因此实际情况也是N。
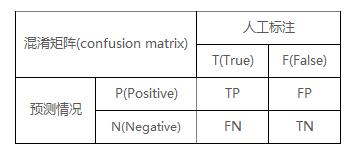
(混淆矩阵示意图)
召回率(Recall)=TP/(TP+FN),机器正确识别出”真”的样本数总和/样本总数
精准率(Precison)=TP/(TP+FP),机器正确识别出”真”的样本数总和/机器识别样本总数
准确率(Accuracy)=(TP+TNP)/(TP+FN+FP+TN),机器正确识别的样本总数/样本总数(备注:正确识别包含把“True”样本识别为“Positive”,把“False”样本识别为“Negative”两种情况)
虽然准确率可以判断总的正确率,但如果样本中T、F样本分布极度不平衡,准确率结果会含有很大的水分,基本失去参考价值。
如样本中T占95%,F占5%,我们将模型设置为所有样本均预测为P的策略,则准确率有95%那么高,但实际上毫无意义。更多经典例子来自疾病试纸和验孕试纸(有兴趣的朋友可以查阅一下),所以统计的时候需要注意统计的对象。
针对R\P\A的计算,举个栗子:
![]()
(以上数据仅做理论说明,不做实际参考)
图解一:
- 召回率(R)=140/(140+11)=92.72%
- 精准率(P)=140/(140+40)=77.78%
- 准确率(A)=(140+4809)/(140+4809+40+11)=98.98%
图解二:
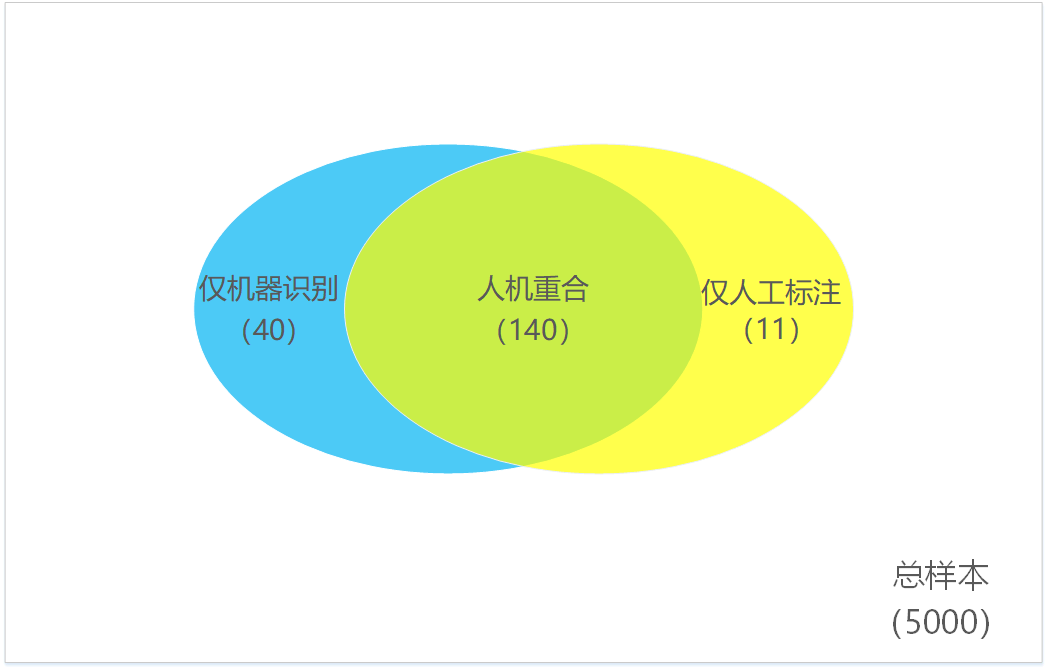
- 召回率(R)=140/151=92.72%
- 精准率(P)=140/180=77.78%
- 准确率(A)=(5000-40-11)/5000=98.98%
对于同一策略模型,同一阈值,可以统计出一组确定的精准率和召回率。调整参数,遍历0-1之间的所有阈值,就可以画出每个阈值下的关系点,从而得到一条曲线,称之为P-R曲线。
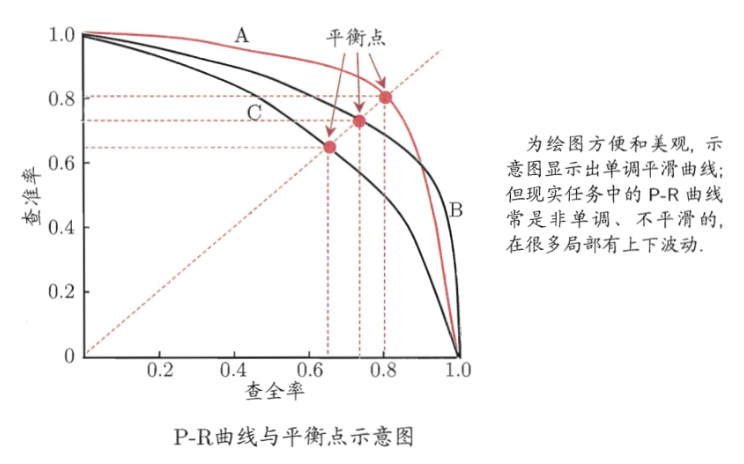
(召回率也叫查全率,精确率也叫查准率)
通过曲线发现,召回率和精准率相互制约,此起彼伏,所以只能找二者之间的平衡点。这时需要引入F值评估:F-Score(也称F-Measure),它是Precision和Recall加权调和平均数,[0,1],值越大表示效果越好。
F1 Score:召回率和精确率同等重要
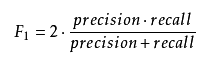
但往往我们对召回率和精准率的权重要求是不同的,这是我们需要用到 Fβ Score。
- F2:召回率的重要程度是准确率的2倍
- F0.5:召回率的重要程度是准确率的一半
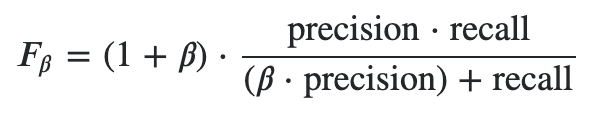
(β大于0)
2. 多分类单标签
M_i : 表示机器识别是 i 类别,同时是正确的样本数
C_i : 表示机器识别是 i 类别的总样本数
N_i : 表示 i 类别的实际总数(即人工标记为是 i 类别的样本数)
D :文章总数
K: 类别总数
- 精确率(A)=(M_0+M_1+……+M_K)/(C_1+C_2 + …… + C_K)
- 召回率(R)=(M_0+M_1+……+M_K)/(N_1+N_2+……+N_K)=(M_0+M_1+……+M_K)/D
- 覆盖率(Coverage)= 所有精确度符合要求的机器预测样本数/D
对于覆盖率,举个栗子:
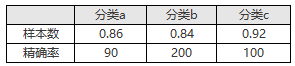
假设单个类别精度要求90%,没有满足要求的类别,覆盖率C=0;
假设单个类别精度要求85%,则满足要求的类别有a、c,则覆盖率C=(90+100)/(100+100+200)*100%=47.5%。
在实际的文本审核工作中,还需要加上“无需审核的文章量”=准确率达标的文章量,用于评估减少人工审核文章量。
3. 多分类多标签
M_i : 表示 i 标签识别正确的总样本数;
C_i : 表示 i 标签出现的总样本数;
N_i : 表示 i 标签实际总样本数(即人工标记为是 i 标签的总样本数)
K:表示标签集合的大小(即不同标签的个数)
- 准确率(A)=(M_0+M_1+……+M_K)/(C_0+C_1+……+C_K)
- 召回率(R)=(M_0+M_1+……+M_K)/(N_1+N_2+……+N_K)
但在实际工作中,考虑到人工标注可行性,评估指标不考虑多标签结果的先后顺序;并且考虑到每一篇文章人工打全所有标签的成本较大,召回率指标仅作为参考,看情况提供。
ROC、AUC
前文介绍了R\P\A\F值,但它仅能评估单点效果而无法衡量策略的整体效果,于是我们再引入ROC(Receiver Operating Characteristic)、AUC(Area Under Curve),它是一套成熟的整体策略评估方法。
先引入两个指标,这两个指标是ROC、AUC可以无视样本中T、F不平衡的原因。
- 真正率(TPR)=TP/(TP+FN),在“真”样本里预测正确的样本;
- 假正率(FPR)=FP/(FP+TN),在“假”样本里预测错误的样本。
设横坐标是FPR、纵坐标是TPR,每个点都描绘了在某一确定阈值下模型中真正的P和错误的P之间的关系,遍历0-1的所有阈值,绘制一条连续的曲线,这就是ROC曲线。
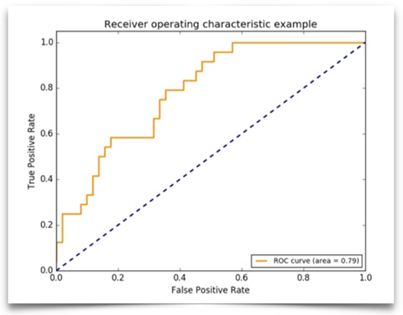
如果我们遍历阈值,多次回归模型绘制出ROC曲线上的点,这种做法非常低效。因此我们可以用另外一种方法来代替ROC,即AUC,计算曲线下的面积。
如上图虚线,若我们将对角线连接,它的面积正好是0.5,代表模型完全随机判断,P/N概率均为50%。若ROC曲线越陡,AUC就越接近正方形,面积越接近1,代表效果越好。所以,AUC的值一般都介于0.5-1之间。
MAP
除了考虑召回结果整体准确率之外,有时候还需要考虑召回结果的排序。于是我们要提起MAP(Mean Average Precision)。
先说说AP的计算,假设这N个样本中有M个正例,那么我们会得到M个Recall值(1/M, 2/M, …, M/M),如下图,N个样本里有6个正例,有6个Recall值:1/6, 2/6, …, 6/6,对于每个Recall值,我们可以计算出对于这个正例最大Precision,然后对这6个Precision取平均即得到最后的AP值。计算方法如下:
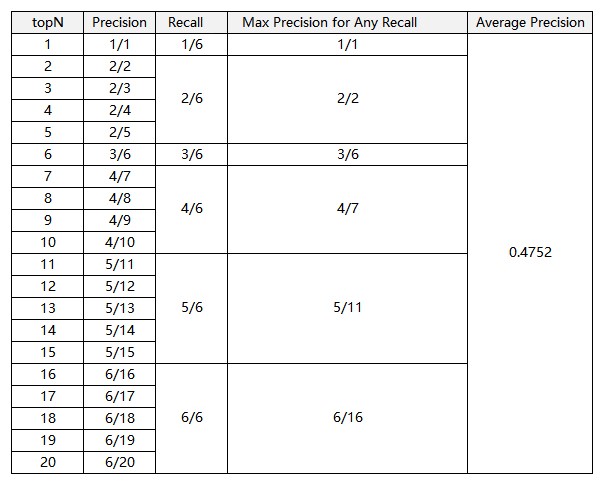
AP衡量的是学出来的模型在给定类别上的好坏,而MAP衡量的是学出的模型在所有类别上的好坏,得到AP后MAP的计算就变得很简单了,就是取所有AP的平均值。
CG/DCG/NDCG
之前的指标大多是将目标值分为P和N两种情况,但用CG/DCG/NDCG(Normalized Discounted cumulative gain)算法可以用更多维度的指标来评估。
比如可以将目标值分为Good、Fair、Bad三类,也可以按照评分。CG->DCG->NDCG是一个考虑精度逐步复杂的演变,多用于搜索结果的评估,当规定相关分值越大表示越相关时,CG/DCG/NDCG值越大表示效果越好。
累计增益(CG),只考虑结果的相关性(reli),不考虑位置因素。公式:
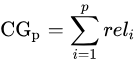
举个栗子:
假设某次搜索返回5个结果,相关度分数分别是4、2、1、1、2
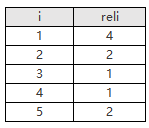
所以CG=4+2+1+1+2=10
折损累计增益(DCG),既考虑结果的相关性,也考虑位置因素:a. 高关联度的结果比一般关联度的结果更影响最终的指标得分;b. 有高关联度的结果出现在更靠前的位置的时候,指标会越高。DCG公式:
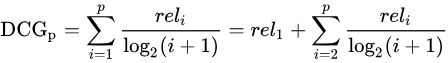
再举个栗子:
假设某次搜索返回5个结果,相关度分数分别是4、2、1、1、2
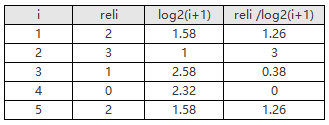
DCG=1.26+3+0.38+0+1.26=5.9
归一化折损累计增益(NDCG),由于搜索结果随着检索词的不同,返回的数量是不一致的,没法针对两个不同的搜索结果进行比较,因此需要归一化处理。NDCG公式:
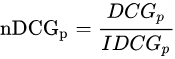
IDCG为理想情况下(相关度降序排列)最大的DCG值:
再再再举个栗子:
假设某次搜索返回5个结果,相关度分数分别是4、2、1、1、2
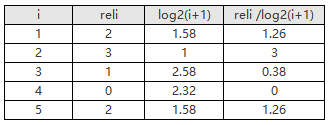
假如我们实际召回了7个物品,除了上面的5个,还有两个结果,假设第6个相关性为3,第7个相关性为0。在理想情况下的相关性分数排序应该是:3、3、2、2、1
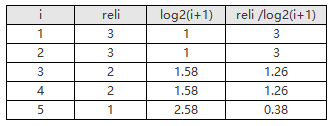
所以IDCG=3+3+1.26+1.26+0.38=8.9,NDCG=DCG/IDCG=5.9/8.9*100%=66.29%
参考文献:
- Willy_G《搜索:由流程框架到实现方法》,http://www.woshipm.com/pd/2866942.html
- 胖喵~《搜索评价指标——NDCG》,https://www.cnblogs.com/by-dream/p/9403984.html
- 残阳崔雪《性能指标(模型评估)之mAP》,https://blog.csdn.net/u014203453/article/details/77598997
本文由 @张小喵Miu 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。









讲的太好了!!!!
看不懂,看不懂;看您应该有过一些推荐策略的实战经验;想问一下,如果像学习一些策略推荐等,需要怎么入手,或者您是如何成长的 😎 ;