
 起点课堂会员权益
起点课堂会员权益借助Canvas黑魔法,实现营销增益模型Uplift Model
编辑导语:运营人员要如何结合数据分析,找到营销敏感人群,提升触达和转化效果,降低营销成本?不妨看看本文作者的案例剖析吧。在本篇文章里,作者结合Amazon SageMaker Canvas产品进行了营销场景建模实践,一起来看。

在后互联网时代,随着营销成本的高涨,如何从存量人群中精准找到营销敏感人群进行触达,进而提高ROI一直是业务中重要的课题。
这样的业务场景需求也同样延伸到对数据分析师能力的考察上,例如有这样一个高频业务面试题:如果饿了么打算给用户精准发券,如何预测哪些用户会使用?
到业务层面讨论问题,之所以要预测会使用优惠券的人群,目的是在成本有限的前提下,使营销产出最大化,而这关键的一点就是要找出真正被营销打动的人,即营销敏感型人群。
一、营销增益模型理论
在数字营销领域,有一个经典的营销增益模型uplift modeling,可以帮助我们达成该目标。
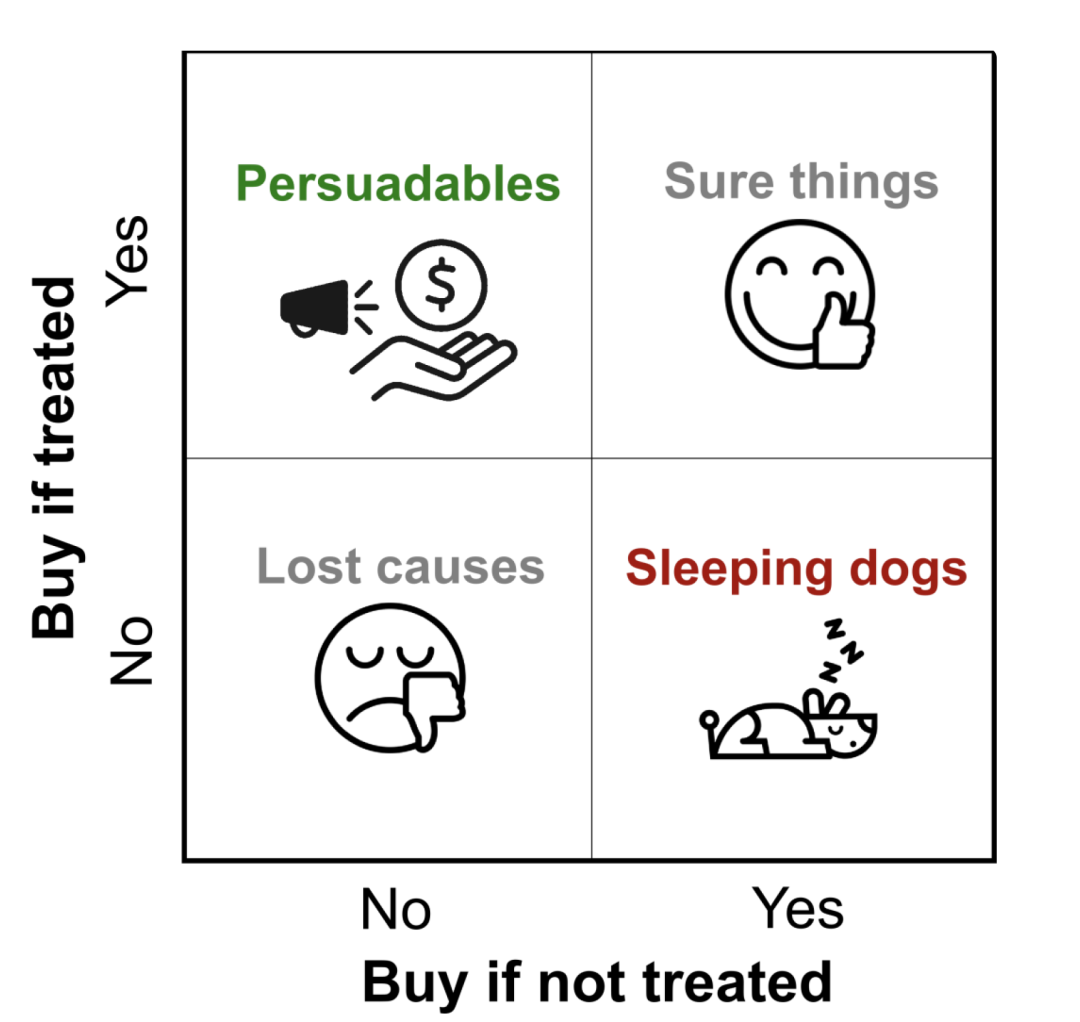
uplift模型根据营销干预(比如优惠券)和干预结果(是否购买)两个维度把用户分为四类:
- 营销敏感人群 Persuadables:不发送优惠券则不买,发送优惠券则购买;
- 自然转化人群 Sure things:不论是否发送优惠券均会购买;
- 流失人群 Lost causes:不论是否发送优惠券均不会购买;
- 反广告人群 Sleeping Dogs:不发送优惠券会购买,发送优惠券反而不买。
为达到营销转化效率最大化,我们的思路就是识别出营销敏感人群(Persuadables)群体,对他们发放优惠券。
在讨论如何找到营销敏感人群之前,先来看看如何从数据层面定义这群人?因为数据预测是基于概率思维,所以可以把前面对人群的定义用概率替换:发券时,购买的概率大;不发券,购买概率小。进一步可以分别在发券以及不发券时计算期望收益,得到收益差。
这个收益差就是“增益”,增益越大,那就可以认为这个人受优惠券的影响越大,也就是说该人是营销敏感型的概率也就越大。
所以,以终为始来看最终要得到的模型是怎么样的:
- 输入用户、以及是否给券的信息,输出期望收益(消费金额);
- 把给券和不给券时的金额做差,就得到优惠券对这个人的增益。
至此,我们就知道了模型的原理,现在需要去收集数据进行建模。但是又有一个问题:在同一场景下,我们是无法同时得到一个人给券时的消费金额和不给券时的消费金额。这是因果推断中典型的反事实问题,该如何解决呢?
此时,我们要回归到建模思维,这里的“人” 不是独立的个体,而是一组特征集:比如都是25岁、男性、月均收入1w、居住在一线城市、未婚的小明和小亮,从营销的角度,认为他们具有相同的画像。从建模思维来说它们都是同样的“人”。这样我们就能得到同一个特征集的人,同时给券和不给券的期望收益。
OK,现在就可以从落地角度来看如何找到营销敏感人群:
- 对人群进行分组,进行营销干预测试,获得样本数据。
- 从业务层面出发,对用户特征进行讨论。
- 基于1.中回收的数据及2.中特征,进行uplift Modeling。
- 预测用户营销属性(属于哪类人群)。
接下来结合业务数据集做落地实践。
二、建模实践 Uplift Modeling
1. 营销干预测试获得数据
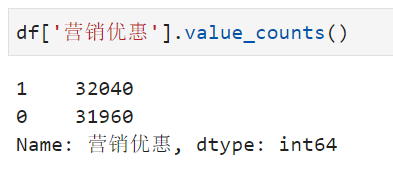
从人群中抽取样本(64000人)进行测试:对一半会员32040人发券,剩余31960人不发券。
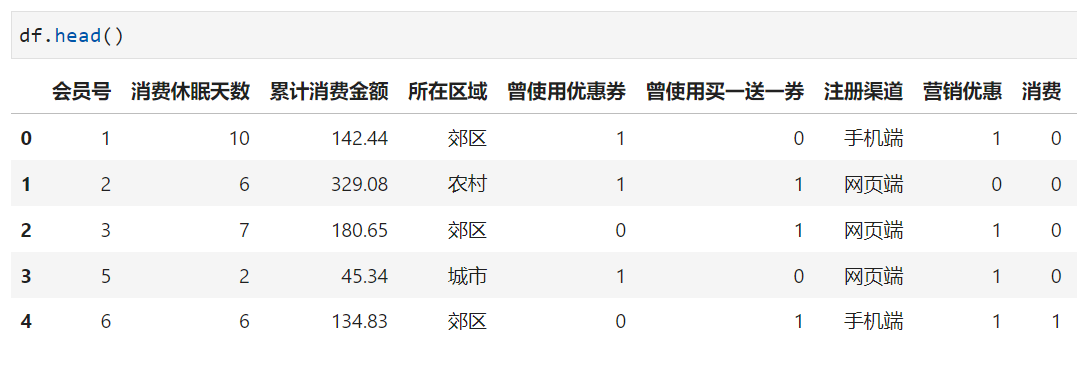
一段时间后,回收数据,结合现有会员标签看看有什么数据可用:
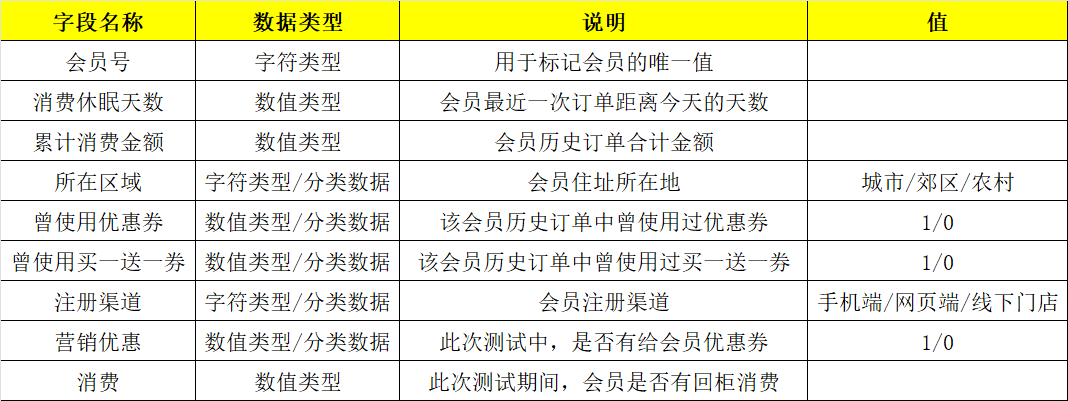
具体对每个字段的解释如图所示。
2. 特征工程
使用pd.get_dummies()就能把数据中字符类型的分类数据进行独热编码(one-hot encoding),形成如图中的稀疏矩阵。
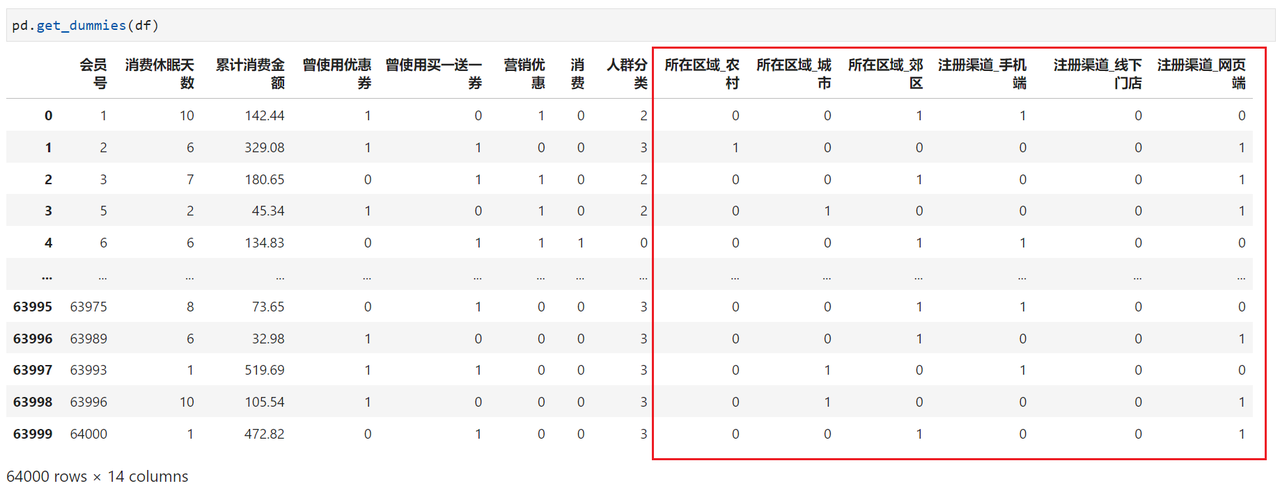
在理论部分, 我们说可以根据营销干预(Treament)和干预结果(Response)两个维度把用户分为四类,但是在实际业务落地过程中,“反广告人群”其实是很难检测的,因此在给会员标记人群分类标签时,根据反馈结果把人群分成以下四类:
- 营销敏感人群 Persuadables | TR(Treament and Response),命名为0。
- 自然转化人群 Sure things | CR(Control and Response),命名为1。
- 流失人群 Lost causes | TN(Treament and No-response),命名为2。
- 空白人群 | CN(Control and No-response),命名为3。
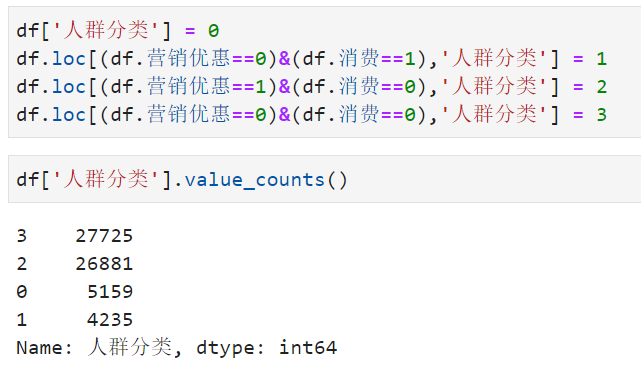
至此,我们就完成了特征工程,接下来进入建模阶段。
3. Amazon SageMaker Canvas——机器学习建模
在理论阶段,我们定义的营销增益模型是用于预测给券后每个会员的增益,再圈选出增益最大的那部分人群定义为营销敏感人群。
在实际落地时,有一种更简单的逻辑,就是直接针对每个会员的特征,判断该会员是属于哪个人群,一步到位,然后对营销敏感人群进行营销即可。
在机器学习模型中,这属于多分类模型(Multi-class classification),也就是说,建模的逻辑是输入会员特征(features),输出分类标签(人群分类:TR | CR | TN | CN)即可。
features = [‘消费休眠天数’, ‘累计消费金额’, ‘曾使用优惠券’, ‘曾使用买一送一券’, ‘人群分类’, ‘所在区域_农村’, ‘所在区域_城市’, ‘所在区域_郊区’, ‘注册渠道_手机端’, ‘注册渠道_线下门店’, ‘注册渠道_网页端’]
基于标准的机器学习流程,到这一步,我们需要进行模型选择、调参:
- 模型选择:可以实现多分类的模型有很多,例如逻辑回归、决策树、随机森林、XGBoost等,需要对不同模型的预测效果作评价对比,选择最终落地部署使用的模型;
- 调参:可以借助GridSearchCV工具帮助调参,但是这个过程往往也是最消耗时间、精力的流程。
其实这两个步骤在实操中属于较为机械、重复的步骤,为了提高效率,这里我使用亚马逊云科技的黑魔法:Amazon Sagemaker Canvas来实现。
① 上传数据
将在特征工程阶段形成的数据集拆成建模数据集(train)和验证数据集(valid)。把建模数据集上传到Canvas后,它可以自动呈现出各字段的描述,帮助判断数据的有效性。
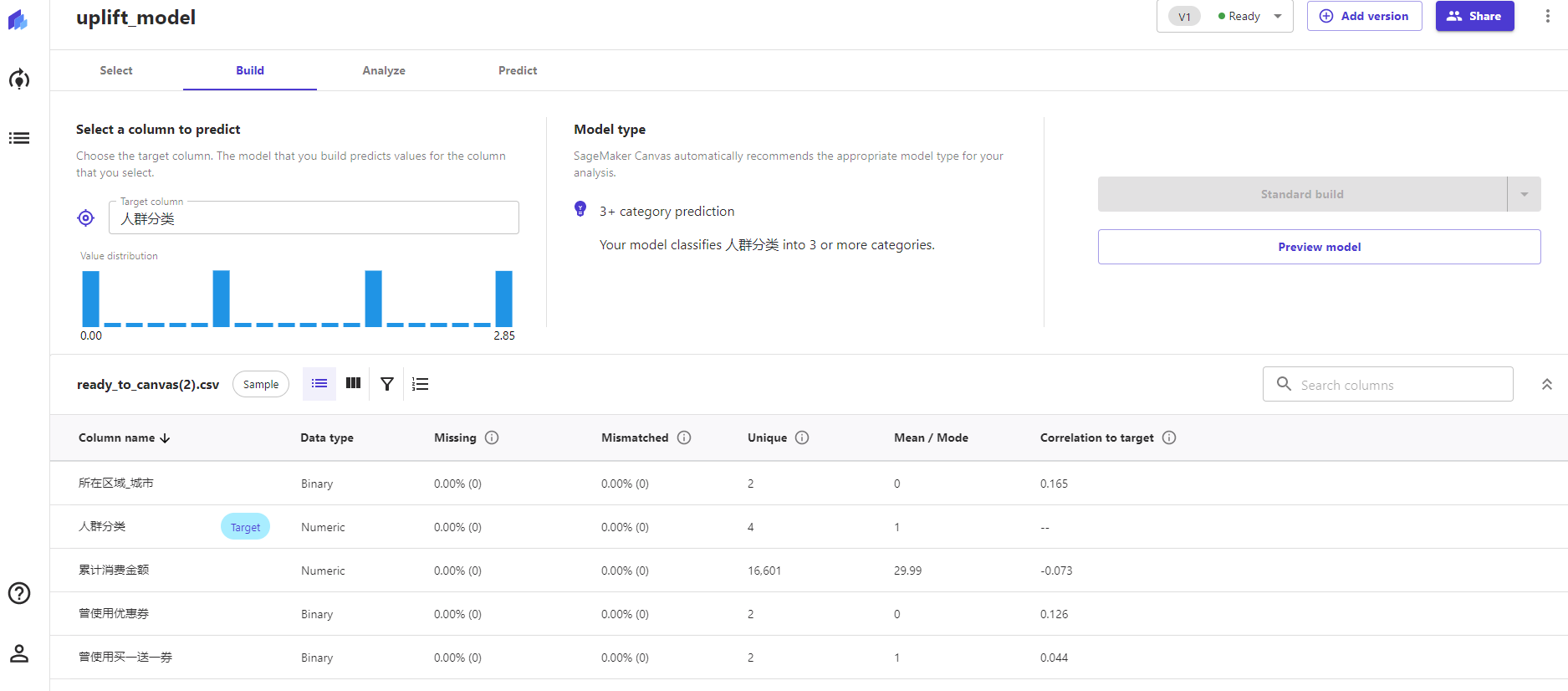
在Target Column中选择输出的标签:人群分类,Canvas能自动识别输入与输出之间的关系,例如在这个案例中,Model type部分就自动选择了多分类模型。不必再担心模型选择恐惧症。
② 建模分析
完成数据设置后,就可以进行建模(Standard build),因为Canvas会自动对模型参数进行调优(终于摆脱了被调参支配的恐惧),所以整个建模的过程耗时比较久。
本案例中,建模数据集一共是7.7万行,11个特征,建模+调参的过程花费了3个小时。不过这个过程完全是在云端进行,丝毫不影响本地电脑进行其他任务(摆脱了以往在本地建模时不敢乱动的苦恼)。
最后生成的模型效果也很好,准确率达到了85%,Canvas会把不同特征在模型中的重要性列出来。在我看来,业务实战中机器学习建模的重点除了在模型本身之外,还在于“可解释性”,而这里呈现的特征重要性(Column impact)能帮助分析师在业务层面得到共识认可。
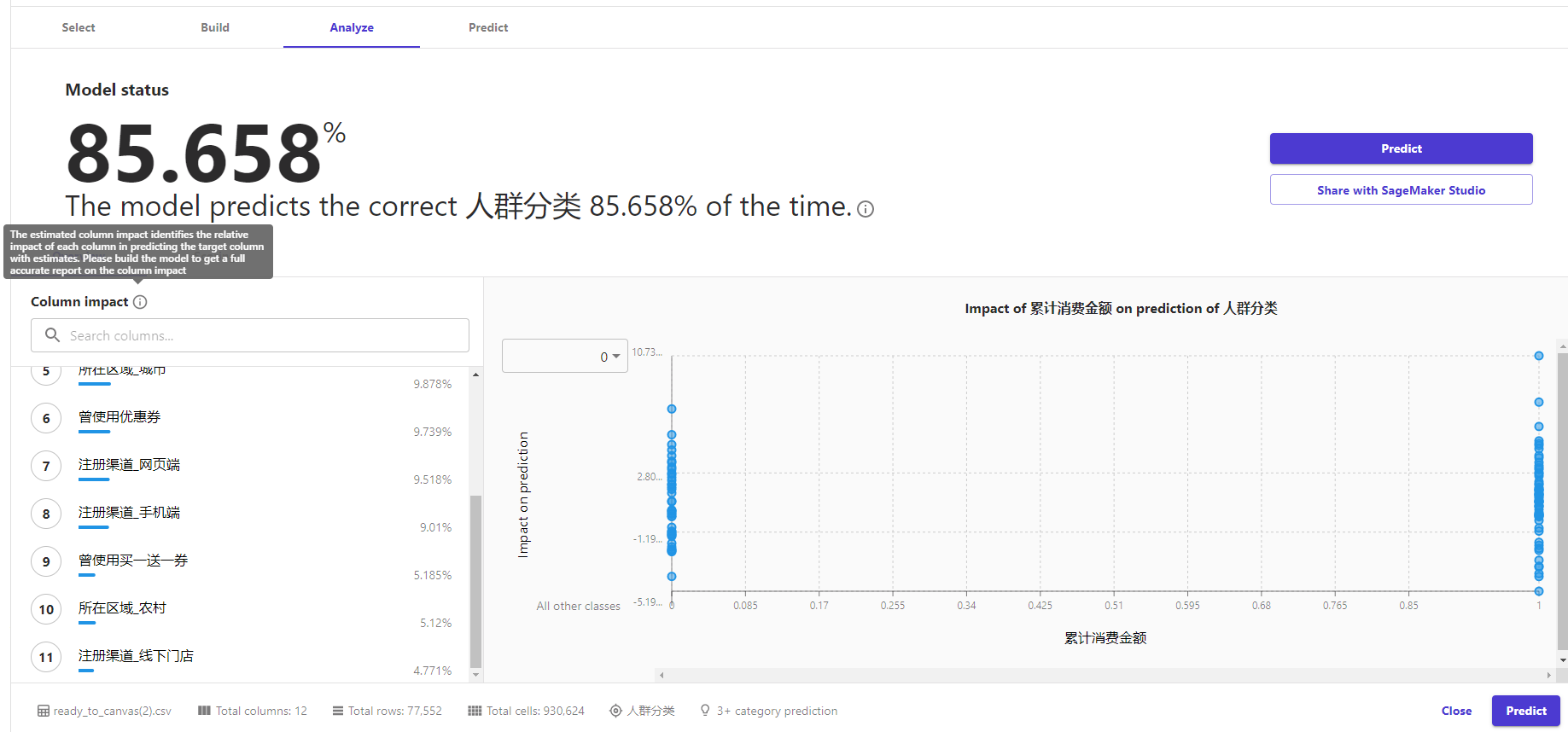
③ 预测
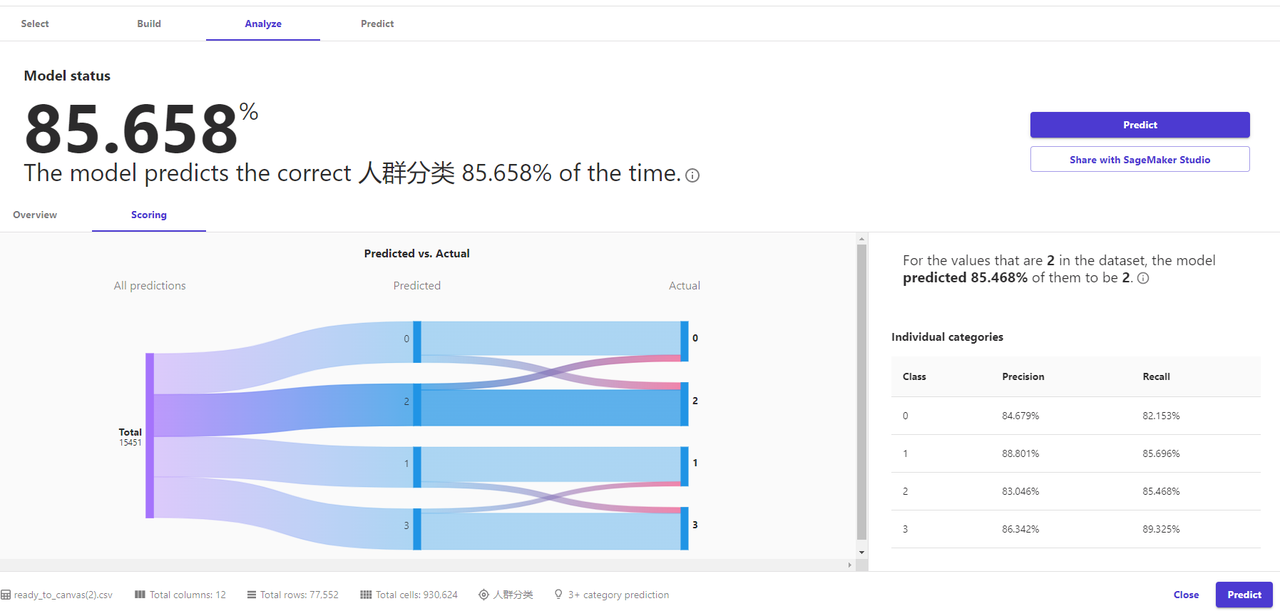
完成建模后,把验证数据集上传到Canvas,检验模型对新数据的预测准确性与泛化能力。
得到的预测结果如图,自动把每个会员归类到不同的人群标签,及给出对应的概率值。
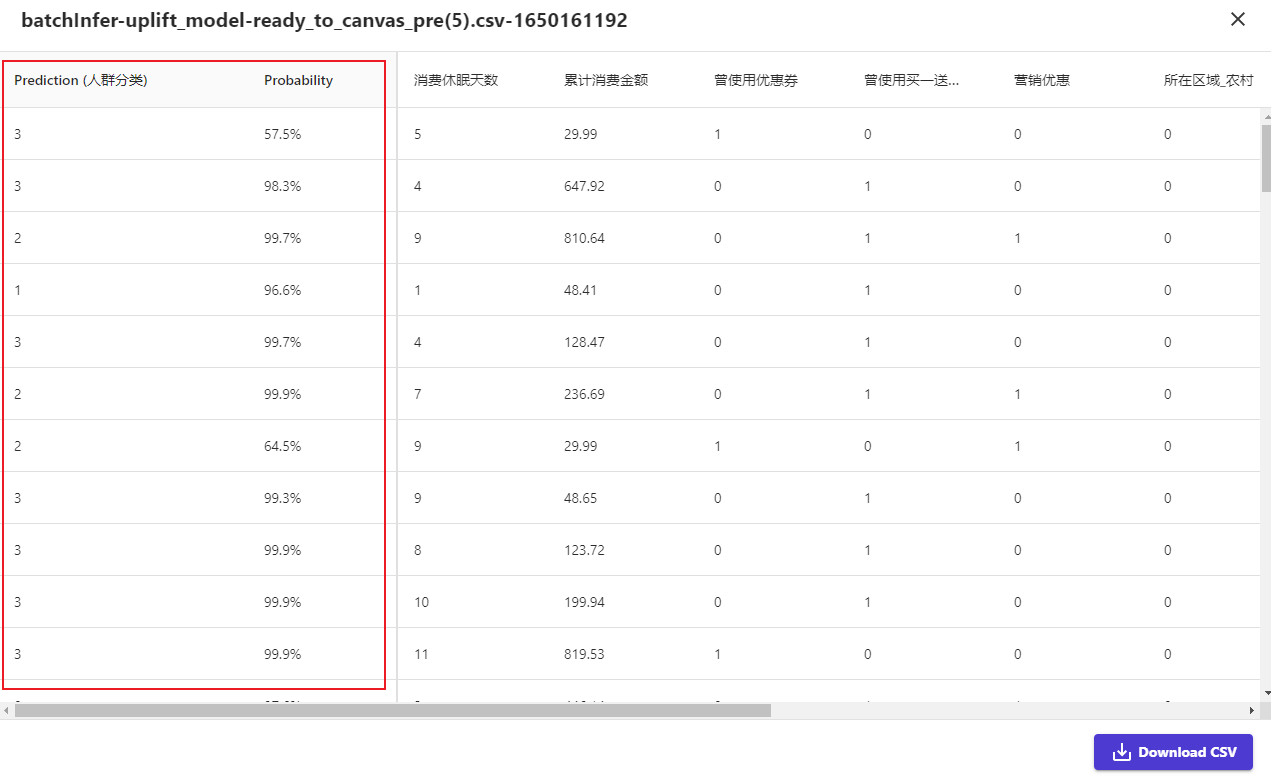
4. 模型评价
对落地而言,评价营销增益模型的好坏在于是否能帮助业务增长。
从这个角度,可以借助IRR和NIR指标进行评价:
- IRR (Incremental Response Rate, 营销增益响应率) :用于衡量营销活动带来的购买率,也就是假设我们营销活跃严格按照模型给出的人群建议进行营销,最终目标人群中购买人数的比例 减去 非目标人群中购买人数的比例(即自然购买率),就认为是营销增益模型带来的增益。
- NIR (Net Increment Revenue 净增量收入) :计算营销活动带来的收益(假设商品利润是10元,边际营销成本是0.15元)。


计算结果如图,表示如果严格按照模型给出的目标人群进行营销,最终能带来的增益是 +18.98%,即2357.65元。
但是这个模型的结果是好是坏还需要有一个标准来做衡量,在实际业务中采用“通发”的策略作为基本策略(Baseline),计算结果如图,通发策略只带来了+3%的增益,与1771元。
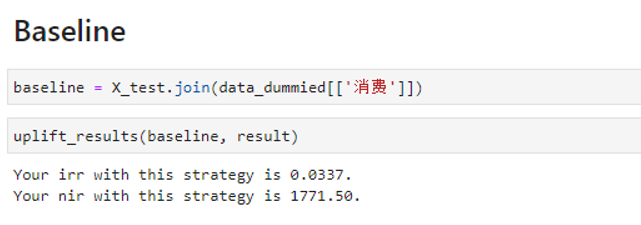
明显,此次通过Amazon Sagemaker Canvas黑魔法进行开发的营销增益模型效果显著。
三、产品体验
在机器学习建模流程中,重业务逻辑的部分主要集中在数据清洗、特征工程环节,真正建模、调优的过程大部分情况下是比较机械、但难度高、耗时长,亚马逊云科技把这部分繁琐的工作单独提出来打造成Canvas数据产品,能极大提高数据分析师建模效率的同时,能让分析师把更多精力放在重要的业务逻辑构建上。
饼干哥哥用过同类型的国内某电商平台的A产品。对于测试样本比例、模型选择、模型参数等,A产品需要使用者需要耗费较多精力进行测试,但是它却无法提供线上的Gridsearch CV能力,所以使用起来成本较高,非常依赖经验。
A产品界面
对比而言,Amazon SageMaker Canvas的使用及界面都是极简风格,它把复杂的模型选择、调参等过程自动化处理,使用者只需关注输入前的特征工程,以及模型的预测落地即可。不仅是数据分析师,连运营业务、产品经理等人群不需要掌握复杂的算法原理、甚至是无需代码都能轻松完成精准的模型开发,极大降低了机器学习的门槛。
最后,虽然Amazon SageMaker Canvas有提供诸如混淆矩阵及准确率、召回率、F1值、AUC值等评价指标,但例如在此次实操案例中,需要的评价指标是更靠近业务的计算逻辑,因此,如果Amazon SageMaker Canvas可以开放自定义验证/评价逻辑的能力,能或许可以更好地帮助完成模型在业务落地的“最后一公里”。
本文由 @饼干哥哥 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。









还没有试过用可画做ppt欸,下次可以试试,感觉非常的方便和现代化。
饼干分析的很详细专业性很强,就是代码不太明白看不懂!