
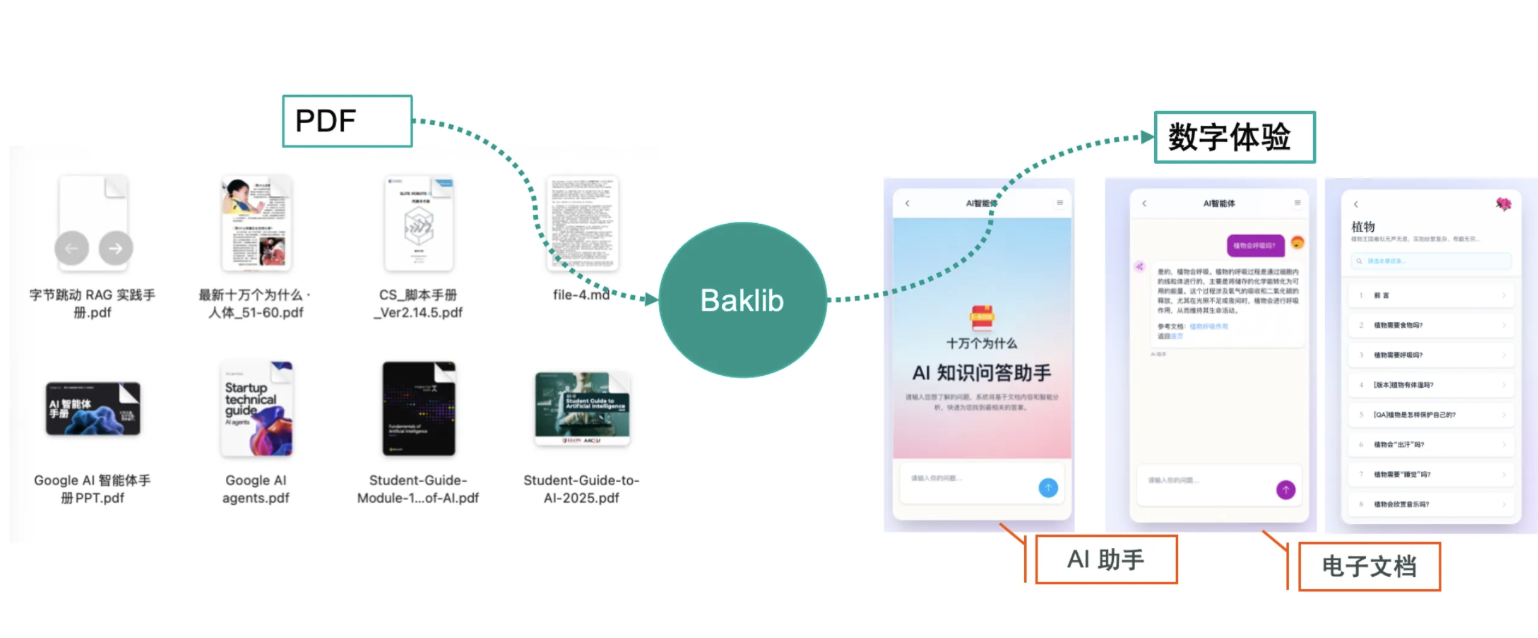
 起点课堂会员权益
起点课堂会员权益企业需要构建多少内容,才能撑起优秀的数字体验?
在B2B/SaaS/AI企业的数字触点布局中,如何通过内容资产与场景设计满足多元受众需求?本文基于Perplexity、OpenAI等头部企业的子域架构分析,揭示行业普遍存在的四类骨干内容(品牌门脸+产品文档+接口参考+可用性公告),并拆解六层体验架构与18类场景清单。从内容分工到权限边界,带你看懂成熟企业如何构建可复用的数字体验矩阵。

一、开篇:优秀数字体验依赖哪些内容资产与场景?
研究问题
在 B2B / SaaS / AI 企业的对外数字触点规划中,有个问题是:企业要构建哪些内容与体验场景,才能让潜在客户、付费用户、开发者与采购方各得其所? 内容、运营、产品三条线往往各说各话——内容侧关心品牌话术与文档表述是否一致,运营侧关心获客、自助与客服渠道如何分工,产品侧关心用户旅程与权限边界如何落地——而这些诉求最终都会沉淀为可对外访问的信息资产,并投影到 www、docs、help、api 等不同的对外入口上。
本研究在多家公司的个案调研中亦记录到一种常见摩擦:品牌对外表述更新后,官网 CMS、帮助中心与对外白皮书仍可能并行保留旧版本;同一表述的调整有时需分别进入多个后台,甚至依赖研发修改落地页代码。此类现象通常并非单岗执行疏漏,而是数字体验被拆成多个孤岛后的结构性结果——每种体验场景对应独立工具、权限与数据副本;当内容资产未统一时,入口越多,重复维护的放大效应越强。
本文的研究问题是:成熟企业为撑起优秀数字体验,沉淀了哪些内容类型、服务了哪些场景、面向了哪些受众?
研究方法
本文基于对 Perplexity、Anthropic、OpenAI、Cursor、Intercom、Mintlify 等多家互联网 / SaaS / AI 公司根域的子域采集:将各根域出现的二级域名标签去重后跨企业计次,汇总为 subdomain_score.json;并结合 OpenAI、Intercom、Mintlify 等个案笔记做架构拆解。分析时保留在多域分析中至少被独立确认 2 次及以上的条目——全量约 161 个标签 key,过滤后 26 个高频标签(约 16.1%),合计分值 122。方法论细节见第二节。
核心发现
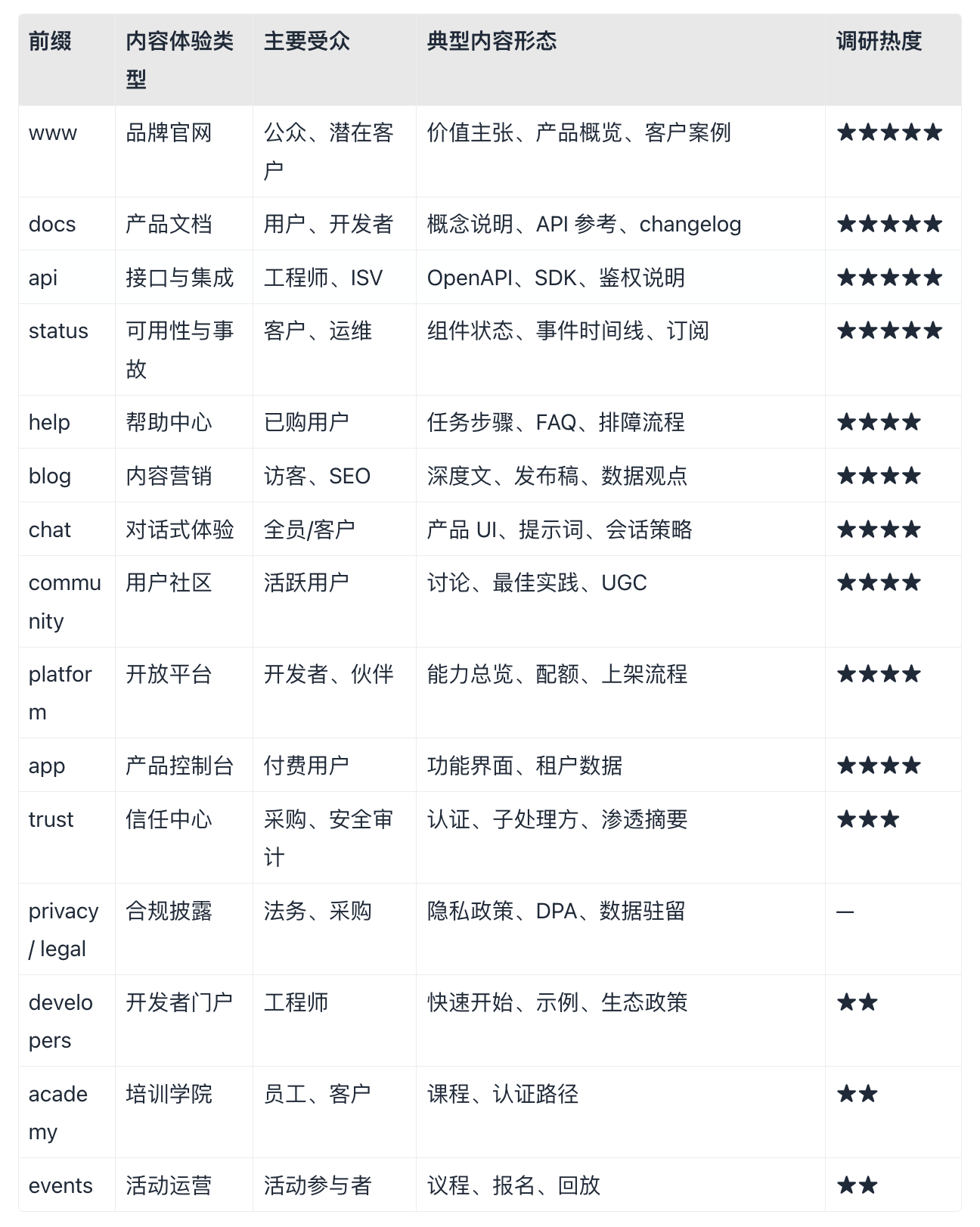
骨干内容高度同构:过滤后 Top 4 前缀(www、api、docs、status)合计分值 57,约占有效信号总量 46.7%——跨企业样本中,近半数可观测信号落在「品牌门脸 + 产品文档 + 接口参考 + 可用性公告」四类内容体验上。
场景可按族群归纳:行业常将企业对外数字体验按 5 大族群、18 类场景 做内容体验清单(见第六节);成熟样本在一品牌主域下往往对应约 10~20 个二级前缀,MVP 阶段常见 4 类骨干内容(www + docs + help + status)——子域数量是内容建设成熟度的技术侧面,不是规划起点。
前缀映射体验惯例:docs、api、status 等命名在用户侧已形成路径预期,在技术侧承担部署与权限隔离——子域分拆本身并非负担;负担往往来自内容资产未统一时的多副本维护。
个案印证内容分工:OpenAI 双根域矩阵、Intercom 全场景客服云、Mintlify 极简四件套,展示同一规律下的不同内容剖面——不是比谁挂的门牌多,而是看谁为关键受众准备了对的材料。
本文结构与读者收益
全文给出研究方法论、六层体验架构、计分数据段、子域前缀→内容类型映射表、头部公司个案深读、三岗位分阶段 Checklist,以及 AI 检索(GEO)环境下的补充原则。三类读者可各取所需:
- 内容岗:带走 docs / help 边界定义、品牌话术单一来源与跨站一致性巡检思路。
- 运营岗:带走 help 与 docs 分工参照、status 韧性配置与 trust 售前链接清单。
- 产品经理:带走受众 × 场景 × 权限矩阵、MVP 四类骨干内容与阶段扩展路线图。
下文第二节说明为何用二级域名做研究,第三至九节依次展开理论框架、数据发现、案例与实操清单。
二、为什么用二级域名做研究?
规划数字体验时,团队常问「我们该有哪些站」。直接访谈或内部文档往往滞后于对外事实——而已上线的子域前缀是公开、可验证、跨企业可比对的样本:它记录了「这家公司认为哪些体验值得单独开门」。
2.1 二级域名作为「可观测的体验分工信号」
二级域名(如 docs.yourcompany.com)在技术上只是 DNS 记录;在组织行为上,它通常意味着四件事已被单独决策:
- 一类内容值得独立运营:营销叙事、API 参考、故障公告等发布节奏与负责人不同。
- 一类受众需要专属路径:开发者不会与采购方挤在同一信息架构里找材料。
- 权限或合规需要边界:auth、pay、intranet 等与公网营销流量隔离。
- 用户已形成路径预期:找文档去 docs,找接口去 api,查故障去 status——命名即体验承诺。
因此,跨企业统计子域前缀,等价于统计「哪些内容体验类型被成熟公司反复单独建站」——不是把门牌当目的,而是把门牌当证据。
2.2 样本采集与过滤规则
样本范围:Perplexity、Anthropic、OpenAI、Cursor、Intercom、Mintlify 等公司的根域子域列表。
计分方式:同一前缀在 N 个独立根域出现,则计 N 分;汇总为 subdomain_score.json。
噪声过滤:仅出现 1 次的标签排除;保留 value ≥ 2 的 26 个高频标签用于下文排名。
与内容类型的连接:每个前缀在第三节映射表中对应「体验场景 + 主要受众 + 典型内容形态」。
2.3 研究边界与局限性
可见 ≠ 全部:内网、未解析主机名、托管在第三方域的体验不计入主域表,个案中需分开讨论。
前缀 ≠ 唯一方案:同一内容类型也可走路径(/docs)或独立根域;研究捕捉的是行业惯例,不是唯一正确答案。
数量是果不是因:子域多寡反映内容与场景已展开的程度;规划时应从受众与场景反推内容,而非从数字反推采购清单。
三、理论框架:数字体验 = 多受众 × 多场景 × 一套内容资产
上一节建立了观察工具。本节用三个维度——受众、场景、内容资产——把分散在各入口下的体验需求收拢为一张可对照的地图,便于跨部门对齐「要建设什么」。
3.1 三个维度拆开看

把三者叠在一起,就得到「数字体验地图」:不是「网站越多越好」,而是每种受众在关键场景下,都能拿到对的、一致的、可更新的信息。
3.2 二级域名是「门牌」,内容是「楼里有什么」
门牌解决的是用户如何找到对的体验;楼里存放的才是内容资产。行业惯例让门牌可预测,但团队真正要规划的是:
- 每种场景下写什么、谁维护、多久更新一次;
- 哪些材料应在多个场景复用同一事实源(如价格口径、SLA、数据驻留说明);
- 哪些场景必须独立发布节奏(如 status 与营销站)。
讨论「要几个子域」,实质是讨论「要几种已成型的内容体验」——这与采购几个 SaaS 不是同一道题,但现实中二者常被混为一谈,从而引出后文的碎片化痛点。
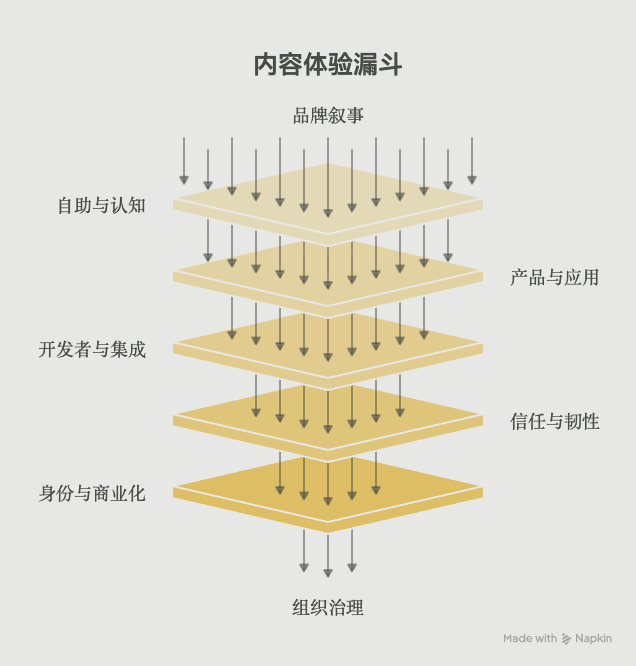
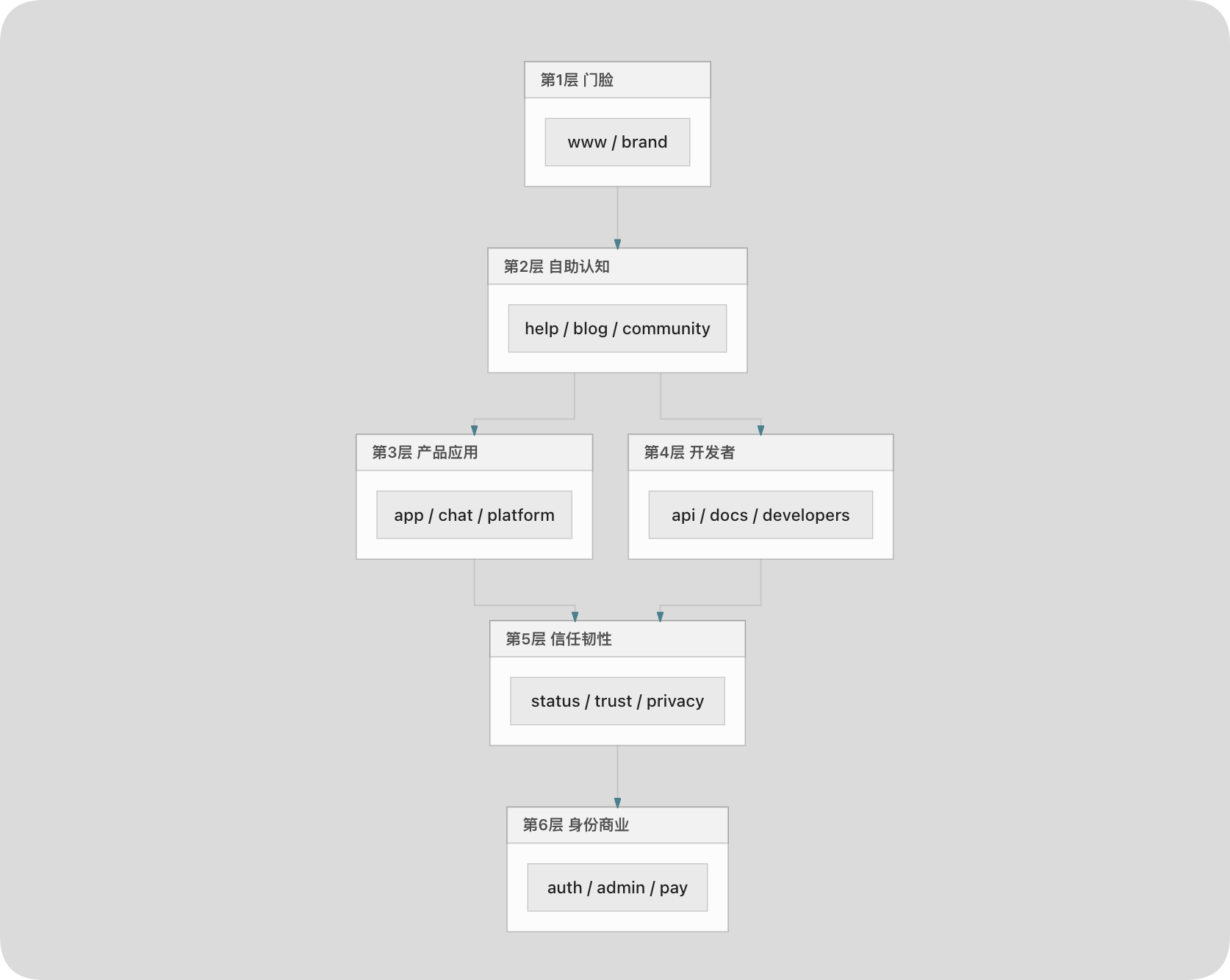
3.3 六层体验架构(内容建设检查清单)
本研究思维导图将常见体验归纳为六层,便于排期与跨部门对齐——每一层对应一类应持续建设的内容,而非仅一类 DNS 记录:
第1层 门脸层 www / brand / CDN → 品牌叙事、第一触点
第2层 自助与认知层 help / blog / community → 自助解答、SEO、降客服成本
第3层 产品与应用层 app / chat / platform → 登录后价值闭环
第4层 开发者与集成层 api / docs / developers → 可编程、生态增长
第5层 信任与韧性层 status / trust / privacy → 合规、故障透明、采购信任
第6层 身份与商业化层 auth / admin / pay → 权限边界、计费、组织治理
六层体验架构关系(示意)
四、研究发现:头部公司的内容体验骨干结构
4.1 统计方法与范围
本研究对 Perplexity、Anthropic、OpenAI、Cursor、Intercom、Mintlify、Baklib 等多家公司的根域进行子域采集,将各根域出现的二级域名标签去重后跨企业计次,汇总为 subdomain_score.json。分析时排除仅出现 1 次的标签(视为噪声或待核实项),保留在多域分析中至少被独立确认 2 次及以上的条目。
全量约 161 个标签 key;过滤后保留 26 个高频标签(约 16.1%),合计分值 122。
下文排名与占比均基于该过滤集;解读方向是哪些内容体验类型被反复单独建站,而非枚举域名采购单。
4.2 Top 标签与集中度
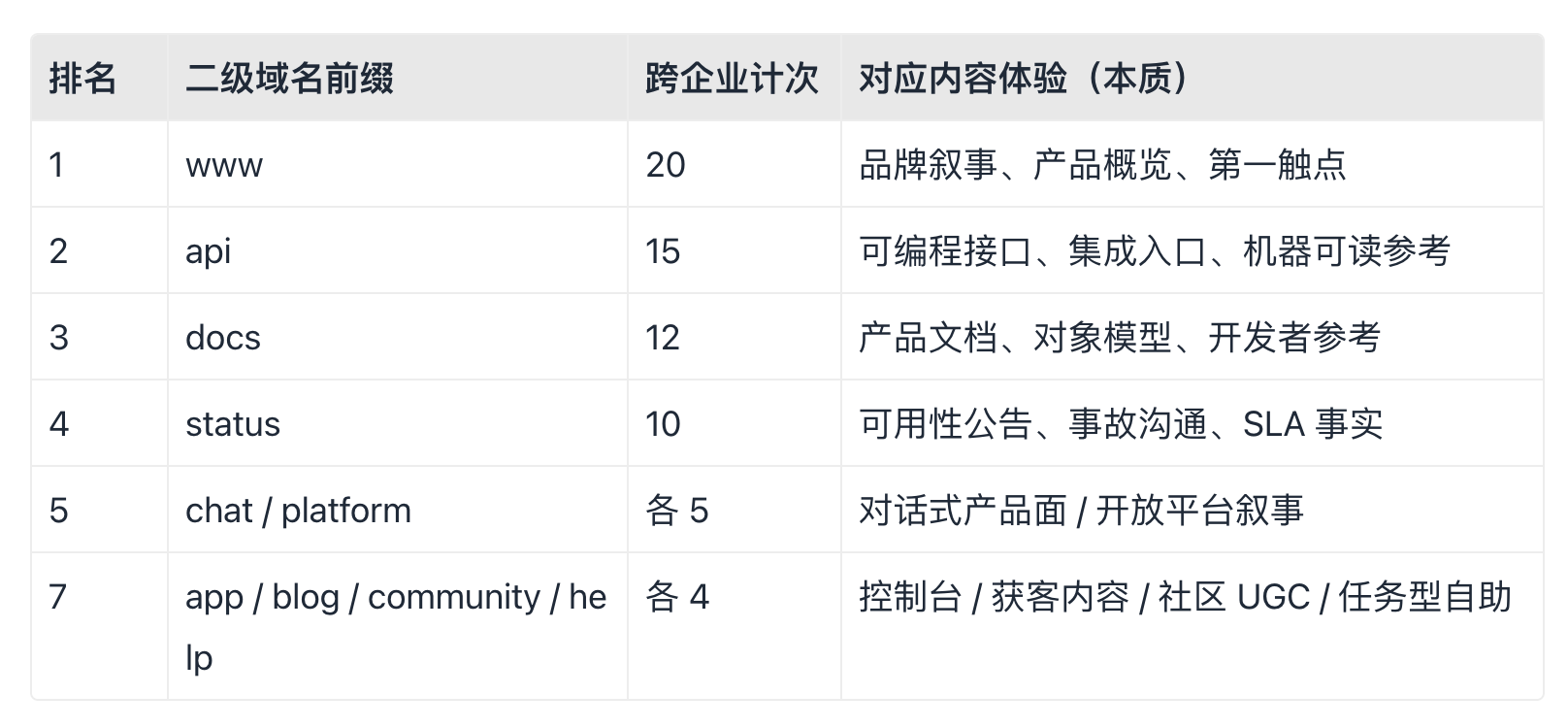
头部集中:前四名(www、api、docs、status)合计分值 57,约占过滤集总分 46.7%。据本研究对多家公司的二级域名聚合统计,近半数有效信号落在「门脸 + 文档 + 接口 + 可用性」这四类内容骨干上——说明成熟数字企业在「最少必须建设什么」上高度同构。
中腰标签(4~5 分档)体现 产品化 + 自助化 双轨:chat、platform 与 help、blog、community 并存,对应「登录后用产品」与「未登录先自助」两条内容路径。
长尾标签(2~3 分)覆盖 trust、privacy、auth、admin、pay、labs、events、academy 等,适合作为成熟期内容清单的补充项,而非 MVP 必写项。
4.3 子域前缀 → 内容体验类型映射表
门牌是表象,下表将高频前缀翻译为应建设的内容与体验(完整 18 场景见第六节):
4.4 语义聚类(对照自家内容架构用)

五、案例段:成熟企业沉淀了哪些内容类型
5.1 现代 AI / SaaS 公司的「内容布局公式」
本研究对 Perplexity、Anthropic、OpenAI、Cursor、Framer、Intercom、Mintlify 等样本的归纳显示,一种常见的内容—入口布局是:
主品牌域名(官网叙事)
├── api. 接口参考与集成事实
├── www. / chat. 品牌门脸 / 对话产品面
├── docs. 产品文档与开发者参考
├── trust / legal / privacy 采购与合规材料
├── platform / dashboard / admin 控制台与治理叙事
├── cdn
– / static
– 静态资源(非独立内容场景)
└── status. 可用性与事故时间线
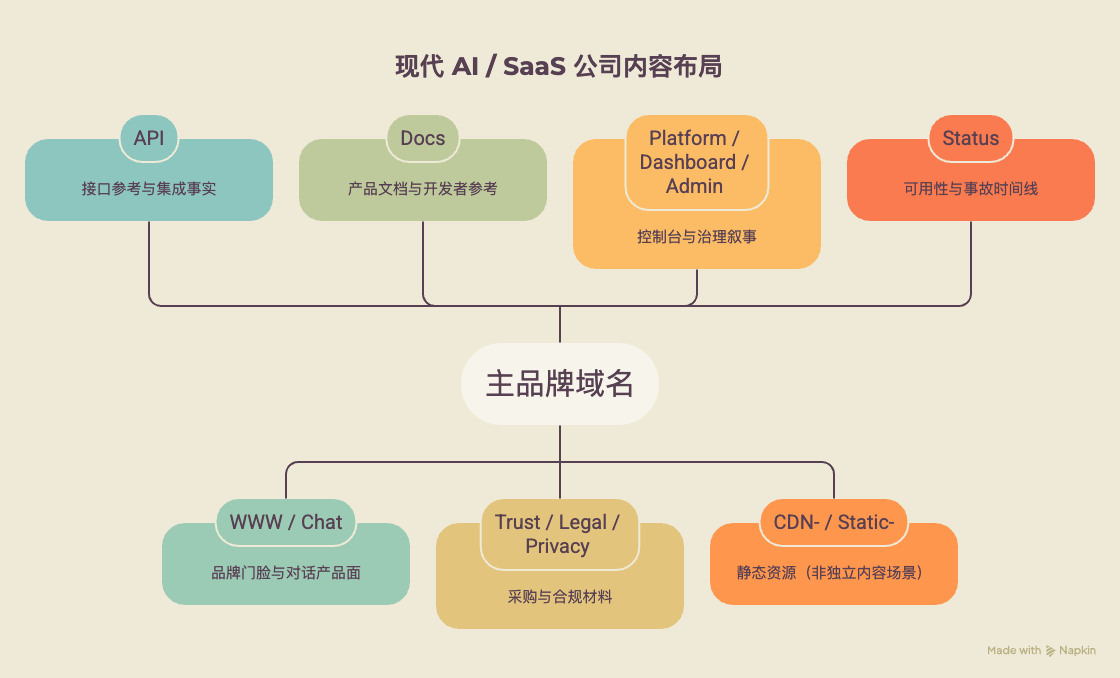
这不是某一家公司的专利,而是用户预期 + 技术隔离 + 合规叙事叠加后,内容分工在行业中的默认落点。
- Perplexity(据本研究采集):www、docs、api、labs、blog、podcast 等并存——检索产品、实验叙事、内容营销各走专域,材料不混写在同一 IA 里。
- Anthropic:www、docs、api、console(类控制台)、legal——开发者路径与合规披露分离清晰,采购常见问题有固定入口。
- OpenAI:chat、platform、admin 承载产品与管理;trust、privacy、status 承接采购与安全审计可引用的陈述。
- Cursor:www、api(部分能力在 cursor.sh 根域)、trust——体量相对精简,但文档、接口、信任三类骨干内容齐全。
5.2 个案深读:OpenAI 的双根域内容矩阵
本研究 openai.com.md 调研笔记显示,OpenAI 将体验拆成多张「内容门」:
- 对话与核心产品:chat、labs、playground、platform、api、sora 等——产品行为与交互说明。
- 品牌与叙事:www、blog、research、community、cookbook——研究进展、案例与社区内容。
- 帮助与韧性:help、help2(分流)、status——任务型支持与事故事实。
- 信任与合规:trust、privacy——可分享给采购方的固定 URL。
- 账号与交易:accounts、auth、oauth、pay——身份与商业化边界。
同时 chatgpt.com 与 openai.com 两条根域并存:前者贴近终端用户对话链路(含 realtime、webrtc、ws 等实时能力主机),后者承载开发者平台、研究叙事与企业向合规叙述。对产品经理的启示是:内容规划要先画受众矩阵,再决定材料挂在哪个根域、哪扇门后。
5.3 个案深读:Intercom 的「全场景客服云」
intercom.com.md 主表列出 20+ 个二级主机名,呈现典型的成熟 B2B SaaS 内容全景:
产品入口:app、app.eu(区域化)。
文档与支持:docs、docs.eu、help——概念文档与任务帮助分域,且具备欧盟区副本。
生态与内容:developers、community、blog、engineering、academy。
信任与运营:trust、privacy、status。
商业与组织:partners、careers、events、go。
5.4 个案深读:Mintlify 的「极简骨干内容」
文档托管厂商 Mintlify 的主表仅 4 个 *.mintlify.com 主机:www、api、dashboard、status。用户文档则大量落在 *.mintlify.app 与客户自定义域——平台方自身对外只保留最小骨干内容集,客户侧场景由 SaaS 代为展开。这对「自己要做品牌方」的企业仍有参考价值:再小的团队,也会优先建设 api 参考、status 事实与控制台说明这三类材料。
5.5 业界常见的外部参照(常识性,非本研究实测)
以下模式在公开产品中广泛可见,具体主机名因公司而异:
- Stripe:开发者文档与 API 参考独立于营销主站;状态页面向集成方提供事故订阅——与样本中 docs + api + status 骨干一致。
- GitHub:文档站、社区讨论与产品主站职责分离,开发者路径与社区内容不会全部挤在 www。
- Notion:帮助中心(Help Center)与营销首页分工明确,任务型「如何操作」与品牌叙事分开承载。
这些案例共同说明:用户并不期待「所有材料都在首页找」;清晰的内容分工与可预期的入口,反而降低认知成本。
5.6 研究发现侧面:子域数量与阶段
作为内容建设成熟度的可观测指标(非规划起点),样本呈现:

Mintlify 极简、Intercom 全景、OpenAI 双根域,是同一内容规律在不同体量下的剖面。
六、三岗位分阶段 Checklist
内容岗
MVP(骨干四类内容)
建立单一品牌话术库(公司介绍、产品一句话、三大卖点)。
定义 docs 与 help 的内容类型边界(概念 vs 步骤)。
为 status 准备对外事故沟通模板(非技术同事可填空发布)。
成长期
blog 与 www 共用可引用数据块(客户数、认证、价格口径)。
api / developers 区统一术语表与错误码说明。
trust / legal 与产品发布流程挂钩:发版即检查合规页。
成熟期
community / partners 制定UGC 与伙伴素材规范。
academy / videos 与 docs 学习路径互链,避免平行宇宙。
全站建立内容过期巡检(季度)。
运营岗
MVP
梳理 help 与 docs 题目重复率,确定主站与迁移计划。
配置 status 订阅渠道(邮件 / Slack / 企业微信)。
定义官网核心转化事件(注册、预约 demo、下载)。
成长期
blog / events 与获客渠道一一映射,可复盘 ROI。
chat(若上线)设定拒答与升级人工规则,与 help 分工。
trust 页纳入销售售前包(固定链接)。
成熟期
community 活跃指标与产品反馈闭环对接。
partners 门户与渠道政策版本同步。
多区域运营时检查 docs / app 区域镜像(参考 Intercom 的 实践)。
产品经理
MVP
绘制受众-场景矩阵(至少 4 格:潜客 / 用户 / 开发者 / 运维)。
确认 api 与 docs 发布解耦(网关变更不拖垮文档站)。
定义 status 服务组件清单(与监控告警一致)。
成长期
platform / app / chat 的登录态与租户模型写清。
开放平台(developers + api)配额、计费、SLA 对外一致。
采购常见问题(trust)与路线图可见性策略。
成熟期
intranet / jobs / legal 权限模型与 HR、法务流程对齐。
labs / 实验性子域与生产隔离策略。
评估是否需要第二品牌根域(产品子品牌 vs 公司品牌)。
七、AI 时代补充:给人看,也给 AI 读
大模型与 AI 搜索(业界常称 GEO,Generative Engine Optimization,与经典 SEO 并列)改变了一点:内容的消费者不再只有人类。Agent 会抓取帮助文档、API 参考、信任页来回答「这家公司的 API 是否支持欧盟区」「上次故障是什么时候」。
中立地看,企业内容策略宜增加两条原则:
结构化与可机器读:同一主题,除渲染良好的网页外,保留 Markdown、OpenAPI、JSON-LD 等机器友好形态——并非重复劳动,而是同一源头的多通道输出(Headless / 内容中台思路)。
入口语义稳定:docs、api、status 等惯例命名,有利于爬虫与 Agent 建立可预期的抓取路径;随意 renamed 子域会增加外部知识过期率。
本文由 @学江 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务









总感觉以下的三个评论都是 AI
品牌话术在多个入口间保持一致的痛点说得很准,很多时候不是不想统一,而是工具链没打通。如果能配上内容单一事实源的机制就更落地了。
子域数量作为成熟度指标有一定参考,但容易让人误以为建更多子域就是体验更好,实际是内容一致性更难。认可数据方法,但规划起点还是受众。
企业要撑起好的数字体验,得先想清楚给谁看、看什么、在哪看。正文从子域分析出发,发现四类骨干内容占了近一半,再落到六层架构和三岗位 checklist,其实是在说规划比门牌更重要。