
 起点课堂会员权益
起点课堂会员权益CRM电销系统中,如何进行客户数据管理与精细化分配?
相较于传统CRM而言,电销CRM可能会将核心功能聚焦于客户分析管理、坐席团队管理等方面,那么,你了解CRM系统是如何在这些功能维度上进行设计的吗?在本篇文章里,作者结合自身经验发表了他的看法,一起来看一下吧。

CRM客户关系管理系统,是Customer Relationship Management的缩写,是管理企业历史客户和潜在客户的业务辅助系统。
传统CRM往往成单流程较复杂,很多时候需要通过整个团队的协作来促成订单的成交。甚至系统还会包括订单的跟进流程、签约流程、付款流程、售后服务等一系列成单流程。
电销CRM相较于传统CRM,接触客人仅通过电话,由业务员专人负责客户,单个客户的长期跟进价值不高,所以,一般不会有很复杂的成交流程,成交周期比较短,客单价相对较低。因此,电销的CRM系统一般会弱化CRM中团队协同与成交流程相关功能,而将核心功能聚焦于客户数据分析与管理、坐席团队管理与能力提升这两方面。
每个公司对于电销场景的CRM系统的需求各有不同,但很多设计思路可供借鉴。我将目前我负责的CRM系统,在客户数据的管理与精细化分配上的所做的深度思考分享一下,供大家参考。
我把客户管理与分配拆分为四个重要部分:客户数据收集、客户数据分类、坐席分类、客户数据分配。
一、数据收集
客户线索数据的产生,一般有两种类型,一种是实时数据,另一种是存量数据。实时数据基本是来源于外部广告投放或者用户的活跃行为,存量数据往往依赖于企业内部数据部门的整理分析。
基于不同业务需求,浏览商品、生成订单、异业合作活动、广告投放等各种场景,都会产生业务的新线索。如果每个新场景都进行系统对接开发,对CRM自身是高额的成本,所以我们一般会提供一些通用化的方案解决数据收集的问题。目前我采用的数据收集方案主要为以下3种:消息队列、定时轮旬同步和临时数据表。
1. 消息队列
消息队列主要用于用户实时数据的收集。由于电销场景用户活跃行为和坐席的拨打时效对成单有着非常明显的影响,通过消息队列处理实时名单,可以有效提高拨打及时率,进而提高成单率。
比如上线一个新的活动或产品,当用户在页面上产生活跃行为时,只要活动或产品侧开发按规则将客户信息推送到CRM系统的消息队列,那系统就可以自动流式接受新线索信息。
2. 定时轮旬
定时轮旬同步主要用于结构化的存量数据收集。现在互联网公司一般都会沉淀整理自己客户的用户画像,基于这些用户画像做筛选数据。
比如企业内部沉淀出一部分高价值标签的静默用户或者向外部合作企业批量获取一部分用户线索数据,就可以通过这种方式去批量查询数据后,导入到CRM系统内。
3. 临时数据表
临时数据表主要用于非结构化存量数据收集。这部分数据往往由数据部门根据业务特定需求整理得出,写入到CRM系统的临时数据表,最终导入系统。
业务想整理10天内有过浏览行为但未成交的用户和30天内有过待支付订单但未成交的用户,依赖结构化的数据很难实现,所以一般就会利用临时数据表这种方式做数据同步。
二、客户数据分类
获取到客户数据后,CRM要将获取的线索,精细化筛选分类,区分出差异化的用户群体。常用的用户分类会有两个层级:业务线和客群。
业务线分类:我们假设一个金融企业有企业贷款业务、个人信用贷款业务、车贷业务、融资租赁业务、个人理财业务等业务,每一项业务他们所面向的用户群体不同,负责的销售管理团队也各有不同。这时候,我们就需要通过业务线这个维度,对客户和销售管理团队做一个拆分,一方面可以做到数据隔离,另一方面可以在业务线下配置一些符合业务需求的特定规则。
客群分类:同一业务线下,基于销售管理团队的管理策略,还可以对客户进行更深度的精细化拆分。在电销系统内,最常用的用户分类方法有两类:基于用户数据分类和利用电销工具分类。
1. 用户数据分类
用户数据分为用户的实时行为数据、历史行为数据和个人属性数据。
实时行为数据主要用于判断用户的购买意向,通过商品数据、交互行为、版本渠道这三个关键数据,对客户分类。
- 商品数据可以通过用户的咨询意向产品作为拆分用户客群的依据,进而为坐席匹配专业度高的销售坐席。商品维度的数据包括商品ID、商品分类、商品属性等,根据公司业务各有不同。
- 交互行为数据可以通过用户的访问时长、互动深度、互动强度等,用于区分用户此次行为的购买意向度。这些行为一般包括:otp验证、注册、实名、浏览、深度浏览、加购、收藏、待支付、支付失败、支付成功、购买基础产品、产品升级等,如果对行为深度细分,还可以细化到“待支付15分钟未成交”,“页面浏览3分钟”这种程度。
- 版本与渠道可以作为客户质量的衡量标准,反向支持业务运营人员对客群进行细分。不同的用户来源,在成交结果上一般也会呈现差异。渠道与版本与商品的匹配度如果比较好,成交率必然也会更优。
用户历史行为数据和用户个人属性数据虽然也可以用于去判断用户的当前购买意向,但更主要的还是用于去判断用户的实际购买能力和消费需求。
历史行为数据包含了历史的交互行为,这些历史的交互行为对于判断用户的购买意向有一定的参考意义,但由于用户意向本身就很多变。假设一个用户一个月前有过浏览A产品的行为,但是他已经购买A产品的同类替代产品或在其他平台购买了A产品,那实际上这个用户当前其实是不需要购买A产品的。
即便如此,用户的历史行为数据对于我们判断用户的购买力,仍然有很重要的意义。比如用户的历史消费行为主要选择高客单价产品,或者用户搜索产品后浏览产品的选择,更多地愿意去选择高价产品,那么我们可以依此判断出,用户的购买能力很强。
用户的个人属性是一些相对客观的数据,不太会因为用户行为产生变化,这些数据主要也是用来判断用户的购买力。用户个人属性包括:年龄、性别、身份证号码归属地(出生地)、手机号码归属地(大概率为当前所在地区)等,不同年龄段、不同性别、地区,用户的消费需求和购买能力也存在一些显著差异,所以利用这些差异我们也可以做一些用户的精细分类。
2. 电销工具分类
常用的电销工具一般有:智能外呼机器人和预测外呼。电销工具既可以作为名单分配的对象,同时也可以作为用户数据分类的方法。我们最常使用的智能外呼,可以进行一轮用户意向的初筛,再由人工坐席进一步跟进,这样一方面可以节省人力资源,另一方面也可以让客户数据更为精准。
不管是利用用户数据分类,还是通过电销工具工具分类,最终的目的都是对客户进行筛选,以便将最有价值跟进客户抓取出来,分配给销售坐席进行跟进。在实际的业务应用场景中,我们一般是会将多种方式结合起来使用,最大化的提升业务的效率。
三、坐席分类
即便是针对于同一类客户,坐席的差异,同样会对成单结果产生影响。通过对坐席的历史业绩数据的分析整理,可以对坐席进行分类区分,进而为名单分配提供依据。最常用的坐席分类标准包括:坐席能力值、坐席擅长产品、坐席承接能力、坐席最近工作状态、坐席违规情况等。
- 坐席能力值:同样的名单,分配给优秀的坐席成单率可能达到20%,而普通的坐席成单率可能仅有10%。分配策略上,一般会优先将优质名单分配给优质坐席,这一方面有利于公司的整体销售产出,另一方面也可以激励坐席产出业绩,这样就可以被分配到更优质的客户。
- 坐席擅长产品:即便是优秀的坐席,也可能存在擅长领域的短板。所以在坐席分类时,也可以结合擅长产品的来进一步对坐席进行拆分。
- 坐席承接能力:业务目标往往多样,例如提高整体销售额、提高整体利润率、提高客户数据成单率等。部分坐席每日承接50个客户时他的成单率很高,但承接客户数达到100个时,成单率反而会断崖式下降。通过数据计算总结出每个坐席做合适的承接能力,对客户数据资源的合理配置,有重要意义。
- 坐席的工作状态与坐席违规情况:即便是最优秀的坐席,也可能存在工作状态的起伏。通过最近一到两天的数据统计,也可以区分出最近工作状态优秀与最近工作状态不佳的坐席,从而作为短期分配策略调整的依据。同样的,坐席的违规情况也是辅助调整分配策略的数据基础之一。对于违规较多、屡教不改、严重违规的坐席,我们可以在分配时排除这部分坐席,提高客户整体的服务体验。
坐席分类的标准多种多样,主要还是要根据自己的业务场景深度挖掘,我所举例的场景只是冰山一角,仅供参考。
四、客户数据分配
电销场景客户数据分配关注的核心指标主要有两个:客户分配的精准度和客户触达的及时性。
1. 客户分配的精准度
根据客户数据的分类以及坐席的分类,建立一些匹配的规则。通过发牌式的自动分发,实现把合适的客户分给合适的坐席的功能,同时通过控制不同坐席被分配的客户的上限,每个坐席在各种场景可持有客户数据的时限,来控制客户数据的利用效率。名单匹配分配的应用,在上文“坐席分类”这一part我已有过举例,此处就不再详细展开叙述。
2. 客户触达的及时性
客户触达的及时性也是电销坐席成单率的很关键的指标。目前我所负责的业务场景内,用户产生互动行为后,同类坐席对同类客人,触达越实时,则成单率越高。所以在分配策略,我们需要兼顾考虑精准度和触达及时性的关系。
需要着重指出的是,客户数据分配的及时性与触达及时性,是两个概念。分配及时,我们通过简单流式分配就能实现。但是每个小时坐席外呼的数量其实是有限的,当流量过大时,会导致很多名单已经分配到坐席但坐席来不及拨打。
一个优秀坐席一天可以承接100条名单,由于流量爆仓,到中午13点时,分配给他的名单已经达到上限100条,这时我们会面临两个问题:第一,13点以后的名单分配给谁?第二,这些优秀的坐席在晚上19:00的时候,拨打的仍然是13:00点前产出的名单,这时距离用户的活跃行为已经过去了6个小时,客户成单率会大幅下降,怎么解决这个问题?
为解决以上的问题,在客户数据分配的功能中,我采用了溢出式分配+流量预测式分配结合的方式,来提升分配的合理性。
溢出式分配,举个例子大家很容易就能理解。如果入库了10000条优质客户数据,原本想把这些客户分配给最优秀的A类坐席,而我的A类坐席仅有80人,且每人可承接100条,A类坐席可承接客户总和8000条。那么剩余2000条数据A类坐席无法承接,这时,可以根据业务事先配置过溢出规则,将剩余的2000条数据溢出分配给次优坐席B类坐席来承接。
通过溢出式分配,我们可以解决的分配优先次序的问题,但是客户流量过大,导致客户数据在坐席侧堆积的问题仍然无法处理。以上述场景举例,由于A类坐席早已达到每人可承接名单的上限,导致接下来的产生的实时名单,只能被一些溢出规则中的普通坐席承接,最好的A类坐席拨打的反而时间较久的“陈年”客户。
为了解决这一问题,在溢出式分配基础上,进一步增加了预测式分配规则来保证流量在整天时间内的均匀溢出。每个预测式分配下都会有一个基础规则和N个偏移量区间规则。
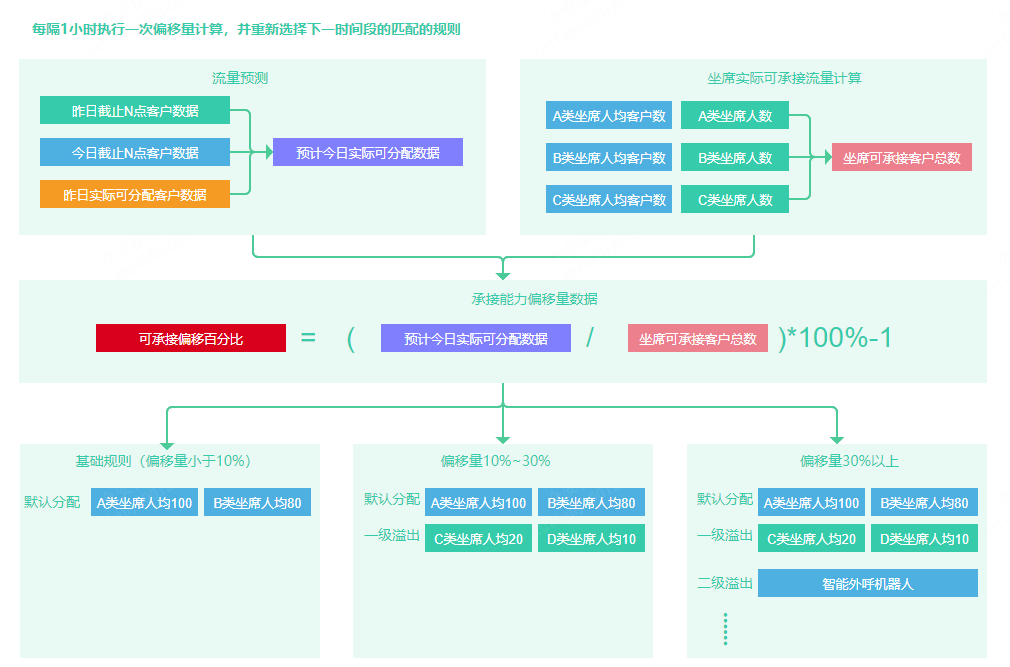
假设每天的客户数据自动分派从早上9点开始,计算今天9点时每小时新增客户数据的加权平均值(加权规则暂不做具体说明)、昨天9点每小时新增客户数据的加权平均值、昨天截止到分配时间结束的客户数据入库总量,可以预测计算出今天截止到分配时间结束的客户数据入库总量,这个数据即我所预测的今天可分配的客户量。根据每条规则中,配置的基础坐席总数和坐席每人可承接名单数,计算出今日实际坐席可承接客户数。
可承接偏移百分比=(预测的今天可分配的客户量/今日实际坐席可承接客户数-1)*100%
业务事先可以配置一些偏移区间规则,当计算出来的偏移百分比命中到指定区间时,可以执行对应的偏移量区间规则。
如果预测名单量比实际可承接名单量多10%以内,可以勉强用原规则承接。如果偏移量在10%~20%之间,可以配置规则,新增一部分溢出坐席来承接。如果偏移量达到50%以上,可以把一部分名单转人工,一部分名单转由智能语音机器人外呼。
预测规则不仅仅可以应用于本规则内的数据预测规则,甚至也可以与其他业务规则做关联绑定。比如高价值用户原本会分配给优质坐席,低价值客群会分配给普通坐席。当高价值用户客群与低价值用户客群同时爆量,我们希望高价值用户客群在流量增加时,把一部分普通坐席拉来做流量承接,同时让减少低价值客群分配给普通坐席的比例,转而有AI外呼承接。
一次性流量预测可能会存在偏差,而且流量投放、流量增长或减少的开始时间也不能确定。所以,预测式分配的流量预测一般会每隔一小时进行一次加权的重新计算,用于更新下一个时间周期(1小时)内的分配策略。
总结
客户数据分配在电销系统内有着至关重要的作用。由于篇幅所限,不能完全赘述。如有意见,欢迎一起探讨。
本文由@爱吐槽的徐教授 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









对于溢出式分配感觉有点疑问:
1、当没有溢出的时候,C类坐席用来干什么?
2、对于名单即使优质名单的溢出,是否也得再进一步区分优质名单中的优劣来去进一步溢出?
小小拙见,希望能多多交流~
1.我所给的流程图仅是一个客群的分配策略。C类坐席原来是承接普通名单,当优质名单增长,那么就将C类坐席引入到溢出规则中接收优质名单。同时普通名单分配规则预测到优质名单增长,就可以降低本规则分配到C类坐席的比例,将这部分名单转为分配到预测外呼或智能外呼。
2.在客户数据到达分配规则时,可以认为已经达到最精细化的名单质量分类,这在第二步客户分类时已经处理完毕了。建议在产品设计时,一定要划清需求、功能的边界,不要把各类功能相互杂糅,导致后续无法实现功能拓展。