
 起点课堂会员权益
起点课堂会员权益为什么语音助手“能用”但不“好用”?一个架构层面的根本缺陷
语音交互正迎来一场颠覆性变革。从传统ASR-NLP-TTS的串行架构,到GPT-4o等端到端语音模型的崛起,技术正在突破'文字作为中间媒介'的思维定式。新一代语音分词器技术让AI能直接处理包含语调、情感的原始语音信号,这不仅解决了传统方案的信息丢失问题,更开启了社交、车载、内容生产等领域的新场景。但这场变革背后,暗藏着技术伦理与交互哲学的全新命题。

你有没有想过,当你对手机说”导航去最近的星巴克”时,它到底做了什么?
表面上看,这不过是一个简单的语音指令。但在毫秒级的时间里,手机完成了一条漫长的信息接力:把你的声音转成文字,再理解文字的意思,再查询位置,再把结果念给你听。
这条接力链,工程师们已经跑了将近三十年。
而现在,这条链正在断裂——不是因为它失败了,而是因为有人发现,这整条链可能根本就不应该存在。
一、我们一直在做一件”有损压缩”的事
理解今天AI语音技术的变革,需要先搞清楚过去的系统在做什么。
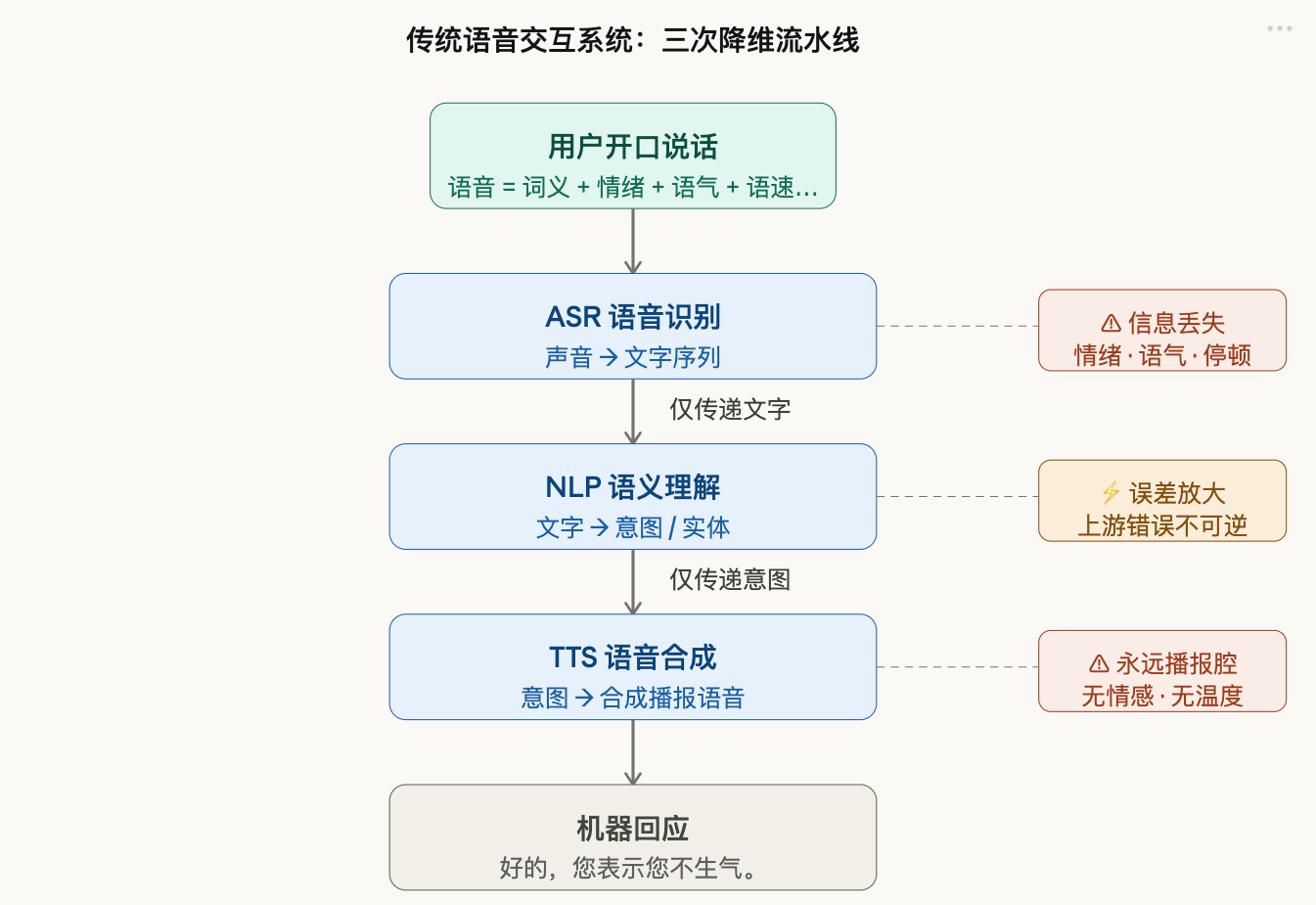
传统的语音交互系统,遵循一个近乎固定的流程:
音频 → ASR(语音转文字)→NLP(理解与处理)→TTS(文字转语音)→ 音频
ASR(Automatic Speech Recognition,自动语音识别)负责”听”,TTS(Text-to-Speech,语音合成)负责”说”,中间的NLP(自然语言处理)负责”想”。
这个架构的逻辑很清晰,工程上也很优雅——分模块、可优化、可替换。但它有一个几乎被所有人忽视的致命缺陷:
文字是一种有损压缩。
当ASR把你的语音转化为文字的那一刻,一大批信息就永久消失了:你说话时的语气是急切还是平静、语调是上扬还是下沉、停顿发生在哪里、你的情绪是疑惑还是笑着问的——这些信息,语言学上称为”副语言信息”(Paralinguistic Information),它们往往比文字本身承载着更多真实意图。
举个例子,同一句”你觉得呢”,温柔地问和冷冷地问,意思可以截然相反。但在传统系统里,这两句话到了NLP那里,是完全一样的五个字。
误差不止于此。ASR一旦识别错误,这个错误会像多米诺骨牌一样,沿着流水线一路污染到最终输出。更不用说多个模块串行处理带来的延迟——这是系统架构层面无法靠”调参”解决的天花板。
这就是为什么,用了那么多年语音助手,大多数人的直觉是:它“能用”,但不“好用”。
二、一个根本性的问题:文字真的必要吗?
AI大模型时代,有一群研究者开始认真追问一个看似异想天开的问题:
在语音交互里,文字这个中间环节,真的必要吗?
为什么不能让机器直接理解语音,直接以语音回应,就像人和人说话一样?
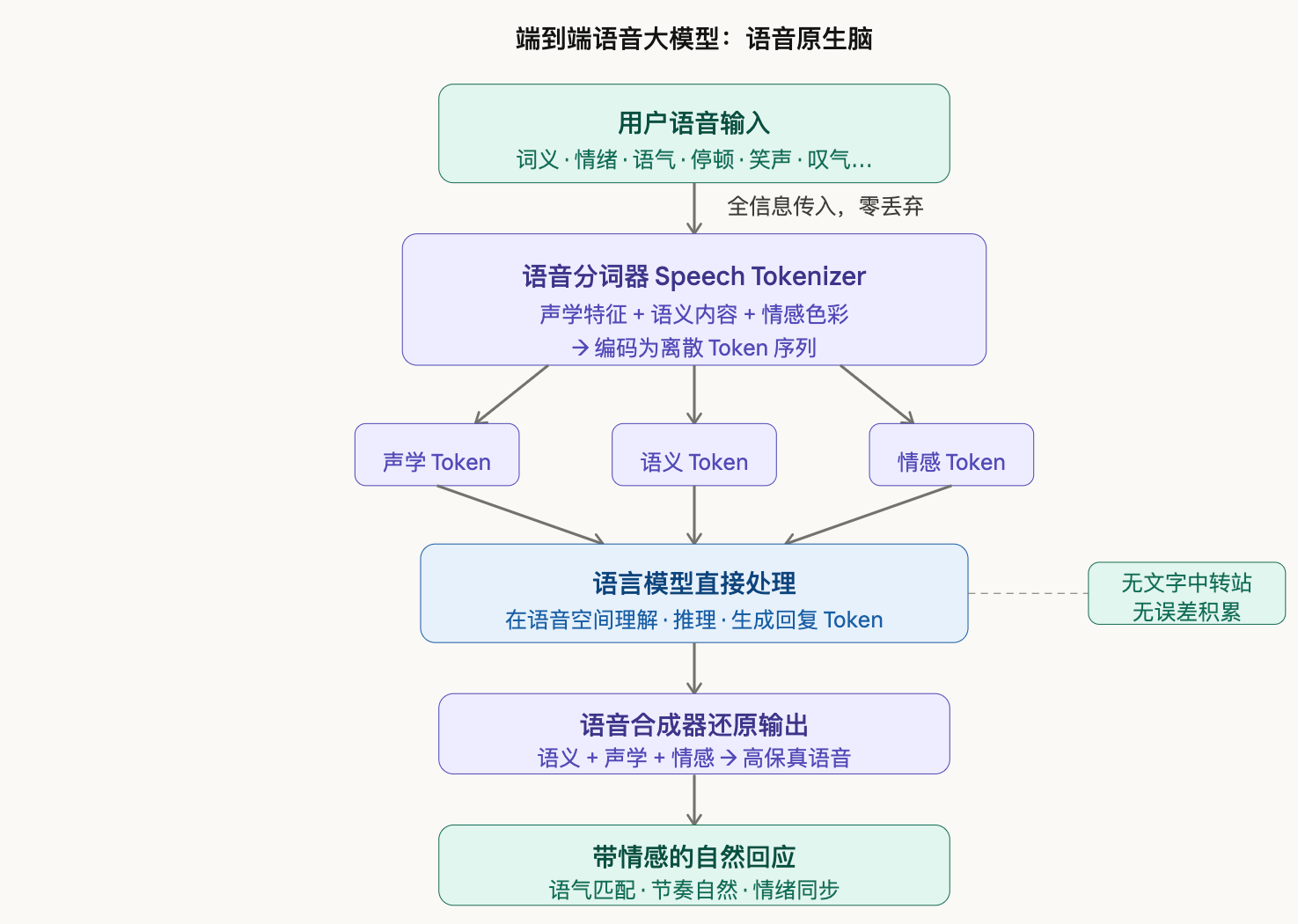
这个问题催生了”端到端语音模型”(End-to-End Speech Model)的研究方向,也是GPT-4o语音模式、Moshi等新一代系统背后的核心逻辑。
实现这一跃迁的关键,是一个叫做**语音分词器(Speech Tokenizer)**的技术突破。
简单来说,它把连续的语音信号切成一段段”语音Token”——这些Token不像文字那样只携带语义,它们同时保留了语调、音色、情感等声学特征。有了这套”语音词表”,语言模型就能直接处理语音,不再需要文字作为中介。
这带来的改变是多维度的:
信息不再丢失。
语气、情绪、节奏,这些此前被”转写”步骤抹去的信息,现在成了模型理解你的核心输入。模型听到的,不只是”你说了什么”,还有”你怎么说的”。
误差不再积累。
没有ASR→NLP→TTS的接力,也就没有了逐级放大的识别错误。
延迟大幅降低。
一体化处理意味着理论上可以做到近实时响应,”打断对话”这种人类说话时最自然的行为,在技术上也终于有了实现基础。
交互更自然。
当你笑着问一个问题,模型能”感受到”你在笑,回答的语气也可以轻松一些。这种细节,是传统架构永远无法实现的。
端到端不是简单地”少了一个步骤”,它是对”理解”这件事的重新定义——从阅读文字到感受语声。
三、但落地从来都不是一道简单题
理念的突破和工程的落地,中间永远隔着一段不小的距离。
以ASR在垂直业务场景的应用为例。某二手交易平台曾面临这样的问题:用户在卖货时,会用语音描述商品,比如”iPhone 15 Pro Max 256G钛金色”。这段话如果被识别错,后续的商品分类、定价建议全都会出错。
通用ASR模型在这里的表现往往差强人意——垂直领域的专有名词、型号编码、品牌缩写,本来就不是通用模型的强项。
他们的解法是搭建一套”ASR + LLM + 向量知识库”的分层系统:ASR先转写,LLM再做语义修正,同时用产品向量库做精确/模糊的双层匹配。识别出的历史case不断沉淀,形成自迭代的数据飞轮。
这个案例的价值不在于技术多复杂,而在于它揭示了一个工程现实:端到端是方向,但在大量真实业务场景里,精心设计的级联系统依然是当下最可靠的解法。
如何在理想架构和工程可行性之间找到平衡点,是每一个做语音产品的人都绕不开的问题。
TTS这边,体验的演进路径同样值得关注。过去十年,TTS走过了这样一条路:
标准播音腔 → 多风格可选 → 圈层化定制 → 声纹级千人千面
早期的TTS,音质和自然度都有明显的”机器感”。神经网络合成技术普及后,语音质量大幅提升,”像不像人”这个问题基本被解决了。下一个战场,是”像不像你”。
车载语音助手开始有了幽默风格、可爱风格的切换;儿童绘本APP的AI讲故事,能分角色、有情绪;有声书平台的内容,再也不需要找真人配音员。
更有意思的趋势是:语音正在成为品牌资产和个人身份的延伸。 企业开始打造专属音色作为品牌识别系统的一部分;个人创作者开始用自己的声音克隆出数字分身。
当然,这里也埋着一个迟早要正面交锋的伦理议题:当TTS能够完美复刻任何人的声音,声音的所有权归谁? 这不只是技术讨论,已经是真实发生的法律与社会问题。
四、真正值钱的,是那些被解锁的新场景
技术演进本身不产生商业价值,真正产生价值的,是那些”以前根本做不到”的场景被解锁了。
社交领域:说话,比打字更真实
Airchat曾被媒体描述为”语音版Twitter”,它的核心洞察非常简单:对绝大多数人来说,说话比写字的表达门槛更低,情感密度更高。
一段30秒的语音里,你能传递的情绪和信息量,往往远超300字的文字。语音社交不是文字社交的升级版,而是一种长期被压制的原生表达需求的释放。
加上多语言实时转译能力,语音社交的边界可以突破语言壁垒,你的声音可以被世界各地的人以母语接收。这是一个真正有可能改变社交形态的方向。
智能座舱:语音,正在成为新的操作系统
过去的车载语音是”指令接收器”——你说”打开空调”,它打开空调,仅此而已。
现在的智能座舱语音助手在做的事完全不同。以豆包AI手机的System Agent为例,它可以感知全屏内容、跨应用执行任务,用语音统一调度手机上所有的应用和服务。你不需要知道某个功能在哪个APP里,只要说出你的需求,它来找路径。
这个逻辑如果迁移到车上,意味着什么?意味着语音不只是一个”功能入口”,而是整个人车交互的调度层——打破了应用孤岛,重构了信息流转的方式。这对车企来说,是软件生态的重构机会,也是构建用户粘性和品牌差异化的核心战场。
对用户来说更直接:开车时眼睛不离路,嘴上一句话,所有事情都搞定。这不是体验优化,这是安全。
内容生产:专业能力的民主化
这是一个不够性感、但持续增长的巨大市场。
AI配音工具正在让没有配音经验的内容创作者,获得接近专业水准的表达效果。有声书、有声课程、短视频配音、多语言本地化——这些原本需要大量人力的环节,正在被大幅压缩。
更有趣的新形态是个性化内容。设想一下:一个儿童绘本APP,不用固定的AI声音讲故事,而是用孩子父母的声音来讲——这种产品形态,在TTS技术成熟之前根本无法存在。
五、技术演进的终点,是一个哲学问题
回头看这整条演进路径,有一个规律越来越清晰:
语音AI解决的问题,在升级。
- 早期:机器能不能听懂人说的话?(准确率问题)
- 现在:机器能不能理解人想说的话?(意图识别问题)
- 未来:机器能不能在人开口前,就感知到人的需求?(主动感知问题)
从”工具”到”助手”,再到可能的”伙伴”,这条路的技术脉络是清晰的:端到端模型与系统级Agent的融合,会让语音AI越来越接近人类的自然沟通方式。
但这里有一个值得所有产品人深思的问题:
当AI的语音交互自然到无法与真人区分,我们究竟是在创造一个更好的工具,还是在重新定义什么是“沟通”本身?
这不只是一个技术问题。用户对AI语音产品产生情感依赖,已经是可观测的现象。当人们开始真的”喜欢”跟某个AI说话,产品设计者的责任边界在哪里?
这大概是这项技术最终留给我们的,最有价值的一道题。
本文由 @如蓝章 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


