
 起点课堂会员权益
起点课堂会员权益PM的指标思维:如何解决工业AI产品的信任问题
当AI根因分析平台的PV增长而采纳率骤降,一个隐藏的信任危机正在工业场景中蔓延。本文通过深度拆解轮胎制造业的真实案例,揭示了工程师"不敢用AI建议"背后的两大核心症结:过度追问消耗耐心与证据链缺失动摇信任,并完整呈现了从问题定位到Graph RAG解决方案落地的全流程方法论。

一、采纳率在掉,但没人觉得有问题
今年3月,我负责的AI根因分析平台刚上线了一个大版本。功能层面做了不少优化,团队氛围也不错。周会上拉了一下数据,根因分析功能的PV比上个月涨了13%。
按理说这是个好消息,团队也确实觉得数据在涨,方向没问题。
但我注意到了另一个数字:建议采纳率从46%掉到了40.1%,下降了将近6个百分点。
PV涨,说明用户在来。采纳率掉,说明用户来了,看了AI给的结果,选择不用。
这两个趋势同时发生,指向一个很明确的判断:入口不是问题,信任才是问题。
在我们的产品指标体系里,采纳率是L3产品体验层的核心指标。它直接决定L2的业务效果,也就是工厂的不良率能不能降下来,进而决定L1客户要不要续约。

换句话说,采纳率掉6个百分点,不是一个产品体验问题,是一个关系到客户续约的商业问题。
但最让我警惕的不是数字本身。而是如果不是我在看这个指标,这件事可能根本不会被发现。PV在涨,功能在迭代,团队觉得一切正常。
工业AI最危险的状态不是用户投诉,而是用户沉默。他不会告诉你他不信任你,他只是不用了。
二、采纳率:为什么我盯的不是准确率
先交代一下背景。
我们的产品是一个面向轮胎制造业的AI根因分析平台。用户是工厂里的工艺工程师、质检员、设备主管这些一线角色。他们每天早上8点看夜班的不良品报告,遇到异常就要定位原因、给方案、跟进执行。
传统做法是翻Excel、查MES、翻PLC数据、问老师傅,一个问题从发现到确认根因平均要2个小时。我们做的事情是用AI把这个过程压缩到15分钟以内。
产品上线后,技术团队最关注的指标是诊断准确率。这很自然,做AI的人第一反应都是准不准。
但我选的北极星指标不是准确率,是采纳率。
原因很简单:准确率是技术视角的指标,采纳率是用户视角的指标。AI给了一个正确答案,但工程师不信、不敢执行,这个正确答案的业务价值就是零。
工业场景放大了这个问题。C端产品推荐错了,用户顶多觉得不准,下次还会来。但工厂里如果工程师按照AI建议调了参数,结果出了一批废品,这个责任谁担?
所以一线工程师对AI建议的态度不是觉得不错就用,而是没有十足的把握就不用。准确率80%在技术上已经不错了,但对工程师来说,20%的出错概率意味着每5次有1次可能害他背锅。
准确率衡量的是AI的能力,采纳率衡量的是用户对AI的信任。这是两件事。
定了采纳率做北极星之后,下一步是把它拆开。采纳率是一个结果指标,不能直接优化。我把它拆成了三个可干预的子率:
- 点赞率:用户觉得AI回答准不准。反映的是AI能力本身
- 工单转化率:用户愿不愿意把AI的建议变成实际的工单去执行。反映的是建议的可执行性
- 归档率:用户觉得这次对话值不值得沉淀成经验。反映的是AI输出的长期价值
当时拿到的数据是:点赞率47%、工单转化率45%、归档率20%。
三个子率分别锚定了信任链条上的不同环节。点赞率低,说明AI给的东西不够准或不够相关;工单转化率低,说明就算觉得准也不敢拿去用;归档率低,说明就算用了也不觉得值得留下来。
这三个数字合在一起,画出了一条完整的信任链路:看到 → 觉得准 → 敢用 → 值得留。每一环断了,后面都归零。
三、46%掉到40%,我是怎么一步步查出来的
发现采纳率下降之后,我没有马上去想”该优化什么功能”。
第一反应是:这个下降是什么原因导致的?如果定位不清楚就动手,很可能修了A问题但真正的瓶颈在B。
先排除环境变量
采纳率下降有很多种可能。不一定是产品出了问题,也可能是外部环境变了。所以我先做了三件事:
- 查数据源质量。MES和PLC的数据接入状态正常,字段缺失率和数据延迟都在正常范围,没有异常波动。排除。
- 查用户群体。看了UV的构成,这个阶段没有新用户批量涌入,还是原来那批工艺工程师。所以不是”新手用户拉低了整体采纳率”这种结构性变化。排除。
- 查系统变更。模型版本和核心链路在那个周期内没做过更新,Agent的prompt也没改过。所以也不是上了新版本导致的回归问题。排除。
三个环境变量都排除了,问题大概率出在产品本身。
再看行为数据
排除了环境因素,接下来看用户在产品里到底发生了什么。
我做了两件事:一是拉对话日志做漏斗分析,二是直接找一线工程师聊。
对话日志里有两个明显信号:
第一,PV涨但UV降。PV涨了13%但UV在下降,说明不是更多人在用,而是少部分人在反复尝试。反复尝试但采纳率在掉,说明他们试了几次觉得不行,最终放弃了。
第二,大量用户在第3-4轮对话后流失。正常的根因分析对话,用户提问、AI分析、给建议、用户确认,大概3-5轮能完成。但数据显示很多用户在第3轮左右就不说话了,没等到AI给出最终建议。
一线工程师的反馈指向了两个具体问题:
胡主任说的一句话我印象很深。他说AI给了一个调参建议,”将XX参数调到Y”,方向他觉得可能是对的,但他找不到AI是根据哪条产线、哪个时间段、哪组数据得出的这个结论。没有原始数据支撑,他不敢签字让操作工去执行。
他的原话大意是:不是AI说得不对,是我没法验证它对不对。万一出了问题,我拿什么跟领导解释?
另一个反馈来自技术员。他说每次进来问一个问题,AI先反问他三四个问题:你说的是哪条产线?什么时间段?什么指标异常?问完一圈他都没耐心了,直接关掉去翻Excel了。
锁定两个根因
综合定量数据和定性反馈,问题指向两个根因:
根因1:对话体验拖垮了信任。意图澄清模块过于敏感,触发率太高。用户进来后AI反复追问,3-4轮还没看到分析结果。对一线工程师来说,时间压力大,他同时在处理好几个问题,耐心被消耗完就直接走了。这解释了为什么大量用户在第3-4轮流失。
根因2:结果不可信。AI给了建议,但没有给支撑这个结论的证据链。工程师不知道这个建议是基于哪些数据推导出来的,无法验证,不敢执行。这解释了为什么看完结果的用户也不采纳。
先修哪个?
两个根因都要解决,但资源有限,必须定优先级。
我的判断是:先修根因1,再修根因2。
逻辑很简单。根因1是漏斗上游的问题,用户连结果都没看到就走了。根因2是漏斗下游的问题,看到了但不敢用。
如果先修根因2,把证据链做得再完整,但用户在第3轮就流失了,根本走不到看结果那一步,改了也白改。
先把路打通,再提升终点的体验。
四、怎么修的,修完效果怎么样
先修路:重构意图澄清策略
根因1的问题很明确:AI太爱追问了。
原来的逻辑是”先问再查”。用户说了一句”帮我看看今天的不良品情况”,AI的第一反应是追问:哪条产线?什么时间段?哪个指标?
这个设计的初衷没问题,信息越完整分析越准。但它忽略了一个现实:工程师来问问题的时候,系统里其实已经有很多上下文了。MES里有产线信息,PLC里有时间段数据,对话历史里可能还有上一次的分析记录。
AI明明可以自己先查一遍已有数据,判断信息够不够,不够的时候再追问。但它没有,上来就问,把压力全推给了用户。
改造的方向是把策略从”先问再查”改成”先查再决定是否问”。
具体做了两件事:
第一,补充提示词中的可参考信息入参。把用户的历史对话、当前产线上下文、最近的异常数据作为Agent的默认输入,让它在回复之前先基于这些信息做预判。
第二,规范信息不足的判断边界。在提示词中明确定义了什么情况算”信息确实不足需要追问”,什么情况算”可以先给一个初步分析再让用户补充”。不是完全不追问了,而是追问变得有门槛。
改完之后,无效对话轮次明显减少了。用户不再被反复追问,更快看到分析结果。
再修终点:增加证据链溯源
根因2的问题很明确:AI给了结论但没给证据。
工程师需要的不只是”将XX参数调到Y”这个建议,他还需要知道:这个建议是基于哪个机台的数据?哪条产线?哪个时间段?原始数据长什么样?
解决方案的产品侧很直观:在AI的每条诊断建议后面增加一个证据链溯源卡片,关联原始数据来源,用户可以一键跳转验证。
但技术侧需要做一个选择。
原来的架构用的是Advanced RAG,也就是向量检索+关键词检索+Rerank重排的多路召回机制。对知识问答类场景来说够用了,检索命中率能做到85%以上。
但根因分析场景有一个特殊性:它不是简单的”问一个问题找一个答案”,而是需要沿着因果链条做推理。比如”胎侧气泡”这个缺陷,可能跟硫化温度有关,硫化温度又跟3号机台最近的维护记录有关,维护记录又关联到某个供应商的配件批次。
这种实体之间的关系传导,向量检索不擅长。你搜”胎侧气泡”,向量检索能找到关于胎侧气泡的文档,但很难自动跳到硫化温度、再跳到设备维护记录。它是按相似度匹配的,不是按关系链路遍历的。
所以我提出了引入Graph RAG的方案。Graph RAG的核心区别是:它把知识组织成图谱结构,实体之间有明确的关系边。检索的时候不是找相似的文档,而是从一个实体出发,沿着关系链路遍历相关的节点。
这个方案在团队里有分歧。研发的顾虑很实际:已有的Advanced RAG链路刚优化完,Graph RAG意味着额外的知识图谱构建成本和开发周期。他们倾向于在现有链路上继续调Rerank参数。
我没有直接争论哪个方案更好,而是建议两条路线各跑一轮评测。从golden case里挑了10个核心根因分析场景,提前和研发对齐了两个评判维度:检索准确率和证据链完整度。哪个方案在这两个维度上赢就选哪个。
结果:Graph RAG在核心场景的检索准确率比Advanced RAG提升了6.3%,证据链完整度达到96%,Advanced RAG是82%。
数据出来之后研发自己就认可了。最终的落地方案也不是全部替换,而是分场景使用:根因分析这种需要关系推理的场景用Graph RAG,知识问答这种匹配型场景继续用Advanced RAG。这个分场景策略比我最初”全部换成Graph RAG”的想法更务实,是研发提出来的。
接入Graph RAG之后,证据链溯源卡片的信息质量有了本质提升。不再是”基于相关文档生成”的模糊溯源,而是”从3号机台硫化温度 → 帘布褶皱缺陷 → 供应商配件批次”这种有明确传导链路的精准溯源。工程师点开卡片看到的不是一堆相似文档,而是一条清晰的因果链。
信任不是靠AI说”相信我”建立的,是靠用户自己验证过几次之后自然形成的。
怎么确保改完没改坏
工业客户有一个铁律:不能变差比能变好更重要。
如果你的优化上线之后,之前好用的功能反而退化了,客户的信任会崩得比之前更快。所以每次改动上线之前,必须做回归测试。
但AI产品的评测跟传统软件的测试不一样。传统软件测的是确定性:输入A,输出B,对不对一目了然。AI产品的输出是概率性的,同一个问题问两次可能给不同的答案,怎么评?
我搭的评测体系分三个层面来解决这个问题。
第一层:golden case怎么设计。
30+个case,按两个维度组织。
横轴是场景:根因分析、知识问答、数据追溯三个核心模块。纵轴是难度:简单(单因单果、信息完整)、中等(多因素、需要跨系统查数据)、复杂(多因耦合、信息模糊、需要多轮对话)。
每个case包含四个要素:
- 输入:用户的query,模拟真实的提问方式,不是精心组织的标准问题
- 标准答案:和一线工程师共同标注的期望输出
- 评分维度:不只看对不对,分四个维度打分
- 预期输出格式:结构化的格式要求
四个评分维度是评测体系最关键的设计:
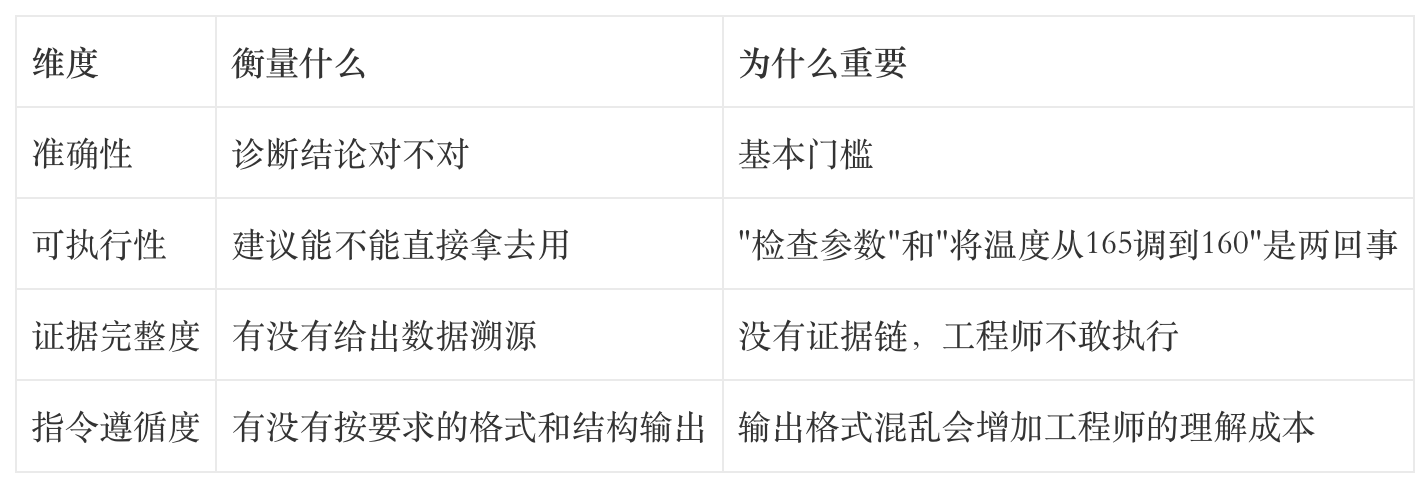
前两个维度大部分AI团队都在做。后两个是我加的,因为工业场景下对但不能执行和对但没有证据跟错了没有本质区别。
第二层:怎么跑评测。
每轮迭代上线前,全量跑一遍30+ golden case。用Langfuse做全链路追踪,从意图路由 → 工具调用 → RAG检索 → LLM生成,每一步都记录输入输出和耗时。
如果某个case的得分比上一轮低了,不需要猜是哪里出了问题。打开Langfuse的链路日志,直接看是路由分发错了、SQL查错了、RAG没召回正确文档、还是LLM生成时出现了幻觉。
评测不是跑一个总分出来就完了,是要能定位到退化发生在哪个环节。这和指标因果链的归因逻辑是一样的。
第三层:评测怎么驱动迭代。
golden case不是一成不变的。每次在实际使用中发现了新的bad case,会被纳入评测集。边界case越积越多,评测的覆盖面越来越广。
3周内跑了6轮评测优化,每一轮都是:跑评测 → 找到得分最低的case → 分析链路日志定位根因 → 针对性修复 → 再跑评测验证。
这套体系在实际中拦截了2次回退风险。有一次改了意图澄清策略之后,某类复杂query的路由准确率下降了,golden case跑出来直接暴露了问题,在发布前就修掉了。如果没有这套评测,这个退化会直接到客户手里。
结果
意图澄清优化上线后,平均对话轮次减少了30%。用户更快看到分析结果,漏斗上游的流失问题明显缓解。
证据链溯源上线后,工程师开始主动点击溯源卡片去验证AI的建议。验证几次发现靠谱之后,采纳意愿明显提升。
最终采纳率从40%回升到了50%以上,比下降之前的46%还高了一截。
五、回过头看:我在这个过程中到底建了什么
前面讲的采纳率下降是一个具体case。但跑完这一轮之后,我回头看整个过程,发现真正有价值的不是”修好了某个功能”,而是在这个过程中长出来的一套可复用的东西。
七层指标因果链
采纳率从46%掉到40%的时候,我能快速定位到问题,靠的不是直觉,而是一套已经搭好的指标体系。
这套体系有七层,从上到下分别是:
- L1 商业层:客户续不续约。厂长看的就是ROI,我投了钱,不良率有没有降,效率有没有提。
- L2 业务效果层:不良率是不是真的在降,问题解决时长是不是从2小时缩短到了15分钟,同类问题是不是不再重复出现。
- L3 产品采纳层:工程师每周用不用,AI的建议他信不信,分析结果他愿不愿意沉淀成经验。采纳率就在这一层。
- L4 AI能力层:诊断准不准、建议能不能直接执行、知识检索命中率高不高。
- L5 平台编排层:意图路由分发对不对、SQL生成正不正确、工具调用成不成功。
- L6 基座能力层:RAG检索质量、模型推理质量、Rerank排序效果。
- L7 数据语义层:数据源接没接全、字段映射准不准、数据字典覆不覆盖。
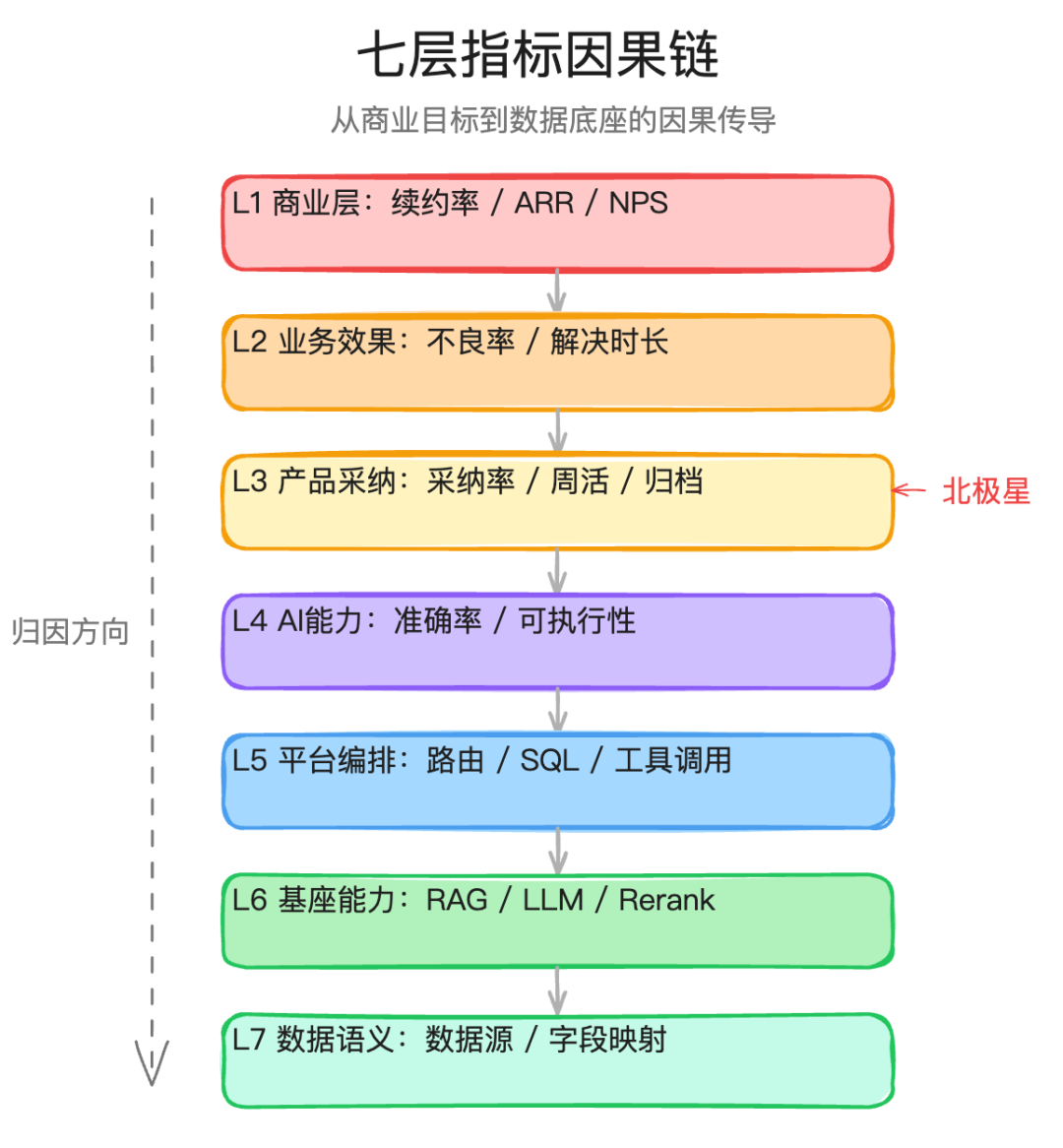
这七层之间是因果关系,不是并列关系。L1续约取决于L2业务效果,L2取决于L3用户采纳,L3取决于L4 AI能力,一路往下传导。
这套体系最大的价值不是监控,是归因。
指标掉了,不用猜,沿着因果链往下钻。采纳率掉了,先查L4 AI能力层有没有变化。如果L4没变,说明不是AI变差了,可能是L3层自身的交互体验问题。如果L4也掉了,继续往下查L5路由是不是分发错了。
每一层都有明确的指标和阈值,每一层出了问题都知道该往哪里找原因。
坦白说,这套体系不是我一开始就设计好的。是在解决一个又一个具体问题的过程中,被逼着逐步搭出来的。第一次遇到采纳率下降不知道查哪里的时候,我就知道必须建一套结构,否则每次都在盲人摸象。
采纳率的因果公式
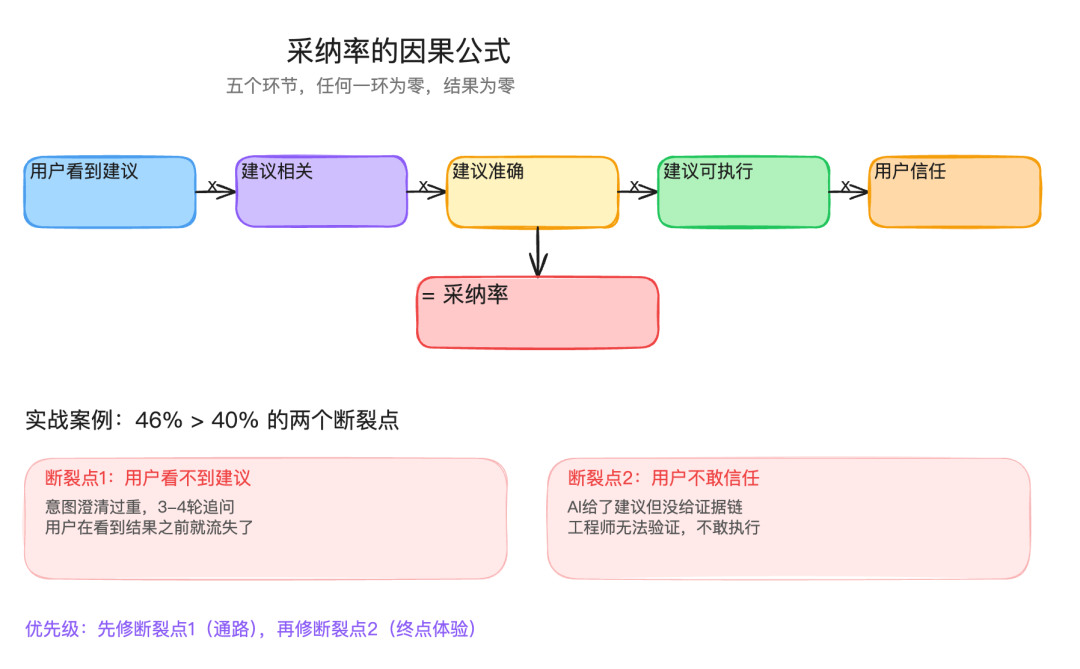
把采纳率这个指标再拆细一层,它其实是一连串条件概率的乘积:
采纳率 = 用户看到了建议 x 建议跟问题相关 x 建议是准确的 x 建议能直接执行 x 用户愿意信任
五个环节,任何一环为零,最终结果就是零。
这个公式的实战意义在于:当采纳率掉了,不要笼统地说”AI效果不好”。沿着这五个环节逐个检查,找到第一个断裂的地方,精准修复。
前面的case就是这个公式的一次完整应用。用户看到了建议吗?没有,第3轮就走了,路被堵住了。看到的用户觉得建议准确吗?觉得准,但不敢执行,因为没有证据链。两个断裂点,分别修复。
评测体系不是锦上添花
很多AI团队把评测当成上线前跑一遍的流程。在工业场景里不是这样。评测体系是你和客户之间信任的底线。
工程师愿意继续用你的产品,一个隐含的前提是:今天好用的功能明天还好用。如果用户发现上周能回答的问题这周回答不了了,或者之前给的建议挺靠谱这次突然离谱了,信任的崩塌是断崖式的。
所以golden case不是用来跑分的,是用来守底线的。每轮迭代的全量回归测试,本质上是在向客户做一个隐形承诺:我们不会变差。
知识飞轮:从不信到离不开
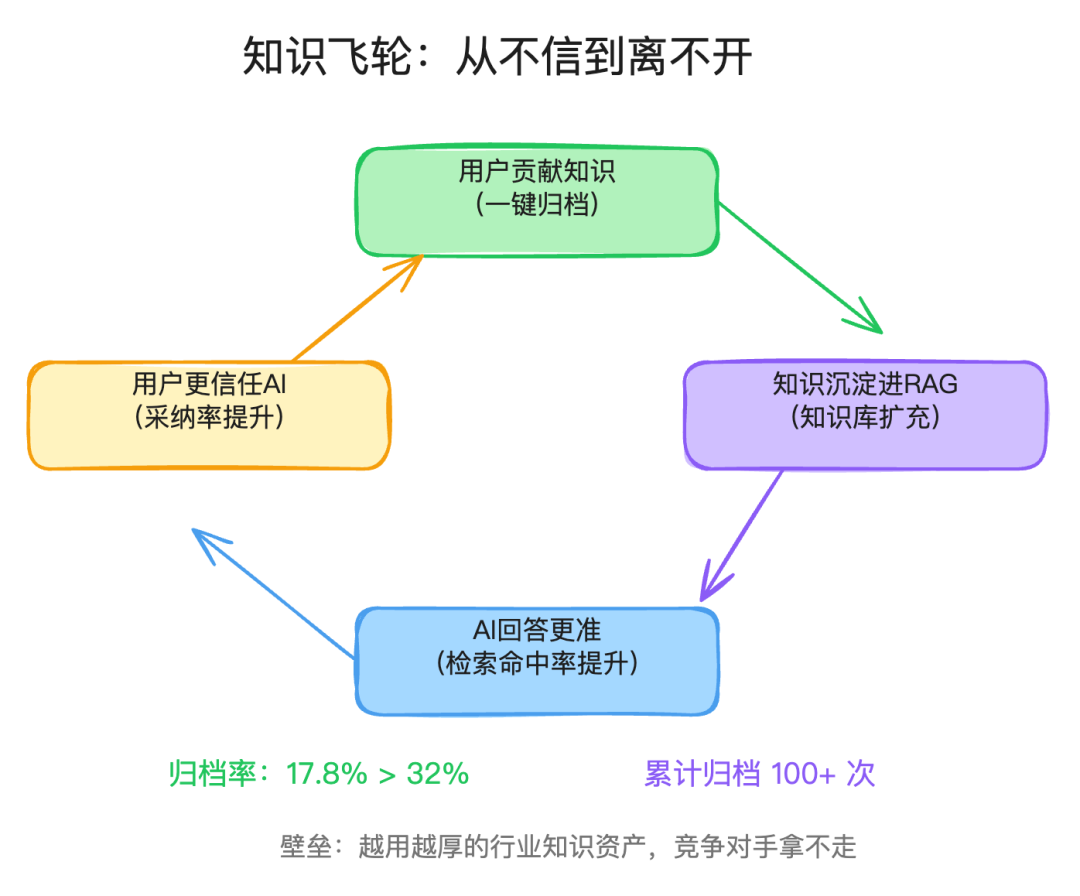
三个子率里,归档率一开始只有20%,是最低的。
归档率低的根因不是技术问题,是产品设计问题。工程师觉得归档操作太麻烦,而且归档了也看不到什么回报。贡献了经验,然后呢?
我做了两件事。
第一,降低贡献摩擦。设计了一键归档功能,配合Case Accumulation Agent自动分类打标。工程师不需要手动整理格式、选分类,点一下就完成了。
第二,让贡献可见。上线了贡献排行榜,归档的知识被其他人引用时会通知原作者。你贡献的经验帮助了同事解决问题,这件事你看得到。
两周内归档率从17.8%升到了32%,累计超过100次归档。
但归档本身不是目的。归档的知识会回流进RAG知识库,下次有类似问题的时候,AI可以检索到这些经验来辅助诊断。AI的回答因此变得更准、更贴合实际,工程师用了几次发现确实靠谱,就更愿意继续贡献。
这是一个正循环:用户贡献知识 → AI更准 → 用户更信任 → 更愿意贡献。
这个飞轮一旦转起来,产品的壁垒就不只是技术了,而是不断积累的行业知识资产。这些知识沉淀在系统里,越用越厚,竞争对手拿不走。
六、工业AI的信任,是经营出来的
回到开头的那个场景。
采纳率从46%掉到40%的时候,如果我没有盯着这个指标,团队看到PV涨了13%,大概率会觉得一切正常,继续往前跑。等到客户续约的时候才发现工程师早就不用了,那时候再补救就来不及了。
后来采纳率回升到了50%以上。客户二期签约了120万的正式合同。复杂问题的解决时长从4小时压缩到了15分钟。知识飞轮累计超过100次归档,正循环跑起来了。
这些结果不是某一次技术突破带来的,是一套体系持续运转的产物。
做工业AI这一年,我最深的一个体会是:技术能力是入场券,信任才是留下来的理由。
很多AI团队花了大量时间把准确率从70%打到85%,然后困惑为什么用户还是不用。因为准确率是你视角的指标,不是用户视角的指标。用户不关心你的模型有多强,他关心的是:这个建议我能不能拿去用、出了问题谁负责、上次靠谱这次还靠不靠谱。
这些问题不是靠提升模型性能能回答的。它需要你把信任拆成可度量的指标,逐层定位断点,用评测守住底线,用飞轮让信任持续积累。
工业AI的信任不是一次建立的,是一天一天经营出来的。
本文由 @思敏 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









非常棒的一篇分享,让我对ai在实际场景中的应用与调优有了更多的了解😊