
 起点课堂会员权益
起点课堂会员权益大模型在金融领域落地会遇到哪些坑?
大模型的热度已经高了很久了,但在具体的行业业务落地的应用还是在进行时,会遇到不少的问题。这篇文章,作者分享了自己在金融领域的落地经验,希望能帮到大家。

一、我们做了哪些场景?
- 客服场景下的会话小结
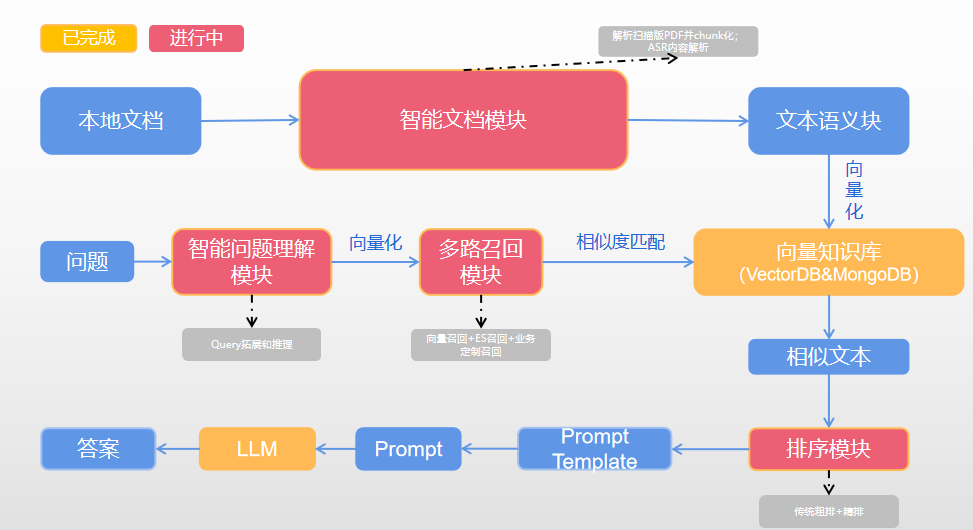
- 知识库的智能搜索:LLM+向量知识库+ES兜底
- 知识实时智能推荐
- 代码辅助
二、遇到了哪些坑
1. 会话小结
大模型应用准确率怎么提升?
大模型不像是传统的nlp,虽然大模型准确率起点高,但是不像nlp可以依靠业务的标注数据进行优化,那么大模型的云应用调用方(不做本地化和finetun情况下)在业务应用中如何进行模型效果的评价和业务使用效果的优化?就成了一道考题。
刚上线你会发现准确率在60%左右,业务想要继续提升,部分算法同学会说模型能力是调用别人的,无法进行数据回流迭代,我也没办法?这时候要摆烂还是继续想办法努力?
幻觉问题:gpt针对短对话的小结会进行自我创造(乱编),这个在业务上是很难被接受的。
实时场景的时延问题:调大模型的云应用尤其是gpt,每次请求到返回的时间问题无法优化。
对于坐席辅助的场景时延要求极高,会话小结是为了帮助人工自动写事件小结的,超过5s的小结基本就失去了帮助坐席减少话后时长的作用,但是即使在只调用一次gpt进行小结的情况下,平均时延也在10s左右
业务上评价会话小结的指标为:要素完备性、要素准确率、业务接受率。如对会话小结这几个方面要求较高(细分场景业务细则,专有名词),就需要在通用格式的会话小结中再加入业务要素的补充,则需要多次调用gpt的场景下,小结的时延会在30s左右。
超过30s后还要不要继续回调用?前端页面还要不要进行轮询?
连接调用不稳定会产生漏损:大模型调用会有失败的情况,就像大家用chatgpt的应用时遇到偶发的不响应的情况,这种情况在c端大家容忍度比较高,但是在b端,尤其是嵌入核心作业流程的场景下,业务对于偶发的漏损情况比较敏感,小结的漏损率会在5%左右。
2. 知识库应用
相比坐席辅助,知识库是一个对AI错误容忍率更低的场景,体现在下面的场景:
- 数据同步问题:业务人员批量新增、删除、更新知识的时候,后端调用大模型接口进行embedding或者tokenization的时候,如遇到大模型调用不稳定报错就会导致数据同步出现问题。
- 时延、并发问题:gpt模型的请求数有限制,针对高并发(知识库上千人使用),搜索时延要求高(1-2s)的情况下,会有比较大的压力,也会有偶发的大模型调用出错的问题。
三、探索解决方案
会话小结:
搭建“NLP+ChatGPT”的双层模型,确保业务效果的同时又能节省大模型的使用费用,针对大模型应用在过短对话时会出现“联想和想象”的问题,增加了NLP过滤(过滤掉无效对话)
针对大模型业务应用后准确率需要提升,但很难靠传统NLP标注的方法进行学习和训练后迭代的问题,联合业务进行了多轮探讨和尝试,用“业务要素完备率+关键要素准确率+业务接受度”进行评价,针对业务接受度差的部分,详细去看原因,并且提炼通用问题进行优化,再深入业务总结不同场景小结的业务要求规则并进行提炼,融入prompt,准确率从57%-82%,准确率的提升只用了2轮数据标注和反馈(每次100条),大大节省了传统 NLP项目大样本数据标注的工作

针对漏损的进行批量补跑;监测模型稳定性指标-小结平均时延、小结的漏损率
坐席辅助:
幻觉这个问题我们是用GPT+NLP双模型来减少乱编,比如客服与客户对话的AI摘要会预设业务关键要素,尽量都覆盖到,且涉及金额、数量或时间这类都会提取参数记录,需要走下个流程分支的会自动生成工单任务流转…
投诉类会有客诉评分,按历史接触的客诉倾向语义点及当通电话的音量语速等计算怒气值,客服的话术除了情绪安抚外更多是理解客户解决其问题
ToC不敢直接用,是做了人工中转,比如侧边栏根据对话命中意图或标签自动推荐最优话术,按相关度排序,人工可任选一键发送,也可通过API对接GPT提问后生成话术
知识库:
- 不稳定的情况利用Kafka进行依次消费,任务失败后进行告警并且重新跑
- 多个大模型的api并行处理,提高并发承载力
- 大模型+ES多重召回机制
此外我们在实践过程中也参考了行业资深大佬关于向量知识库应用的见解,很有用,引用如下:
首先,向量化就不是唯一解,也不是全场景最优解。
**第一,向量化匹配是有能力上限的。**搜索引擎实现语义搜索已经是好几年的事情了,为什么一直无法上线,自然有他的匹配精确度瓶颈问题。
第二,本质是匹配问题(即找到语义相似知识),NLP领域原本也有更优美,更高效的方案,只是这波热潮里,很多以前没接触过AI的朋友对之不熟悉罢了。
**第三,甚至不用AI技术,用精确MVSOL、用策略规则也是一种解法,其至是重要解法。**旧AI时代的产品同学会非常熟悉这种“用规则/策略/产品设计”来弥补AI能力赢弱的问题一一现在是因为行业早期,大家被LLM的能力错误迷惑,并且以往产品经理的声音还没发出来而已。
**其次,在引入外部知识这个事情上,如果是特别专业的领域,纯粹依赖向量、NLP、策略/规则在某些场景仍然不奏效。**因为模型首先需要掌握那个领域的专业知识,才能在这样一个基础能力的加持下,用向量化等手段来便捷地解决外部知识引入问题。
当在模型在基础知识中缺乏、或有错误地学习到某些背景知识,即使他有外部知识库加持也是无效的最后,不要管是不是90%会被解决,对于某个具体业务而言,没有90%,只有100%和0%;
用向量知识库的补丁策略,这个认知很有必要。
1、**把问答域细化,**给检索文本分类,打标签处理,以缩小召回目标域,提升相关性。
2、增加问答逻辑。如问题与上下文是否相关,上下文是否可以回答用户问题的判定逻辑,拒答逻辑。
3、不同种类问答的分流逻辑。打个比方,问百科,问医药,问金融,走不同的回答逻辑。
4、使用多重召回逻辑。基于向量,基于领域向量,基于es,基于编辑距离等,走投票策略。
5、**增加生成前判定,生成后判定逻辑。**前者判定适合是否该回答,是否该拒答,后者判定是否对自己回答有置信。
知识库的搜索体验优化:利用GIO进行行为数据观测,P@3、P@5位置的准确度评估
四、结束语
大模型的热度已经高了很久了,但我们和各位同行的老师聊,发现在金融行业业务落地的应用还是在进行时,尤其是要能产生业务价值的落地中还是会遇到各种问题,因此希望分享我们遇到的问题和探索的经验帮助也在做此类项目的朋友避坑,当然我们的方法不一定是最优解,如大家有更好的方法和应用方向,期望能够交流!
本文由 @甜甜圈 Tina 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


