
 起点课堂会员权益
起点课堂会员权益产品视角 |AI对话(一):了解大语言模型
对想做AI产品经理的同学而言,了解一些基础知识、常用名词是必须的。这篇文章,作者解释了一些AI的基础名词和概念,希望可以帮到大家。

本文为此系列引言,主要为各技术点的要点汇总,旨在普及基础技术知识点不含产品观点,对LLM了解的同学可跳过。
一、什么是大语言模型(LLM)
顾名思义,大语言模型的特点是规模庞大,可能拥有十亿以上的参数。由于研究方向不同,在前两年出现以自然语言理解任务和自然语言生成类任务的两条技术线。
1. 自然语言理解任务
即包括文本分类、句子关系判断等,本质上是分类任务。其技术以Bert为代表。Bert(Bidirectional Encoder Representation from Transfomer)采用双向Transformer Encoder架构。Bert的优点是可以更好地理解上下文信息,缺点是长文本处理不够稳定。
2. 自然语言生成类任务
可给定输入文本,要求对应模型生成一串输出的模型。其技术以GPT为代表。GPT(Generative Pre-trained Transfomer)使用单向Transfomer Decoder结构。GPT的优点是训练过程相对简单,可以生成自然流畅的文本。
从两类任务来看,如果仅用自然语言理解模型,可能无法很好地处理生成任务。但一个LLM 生成模型是可以兼顾两个任务的处理,所以主流更希望推进的应用方向是结合LLM生成模型来做落地。
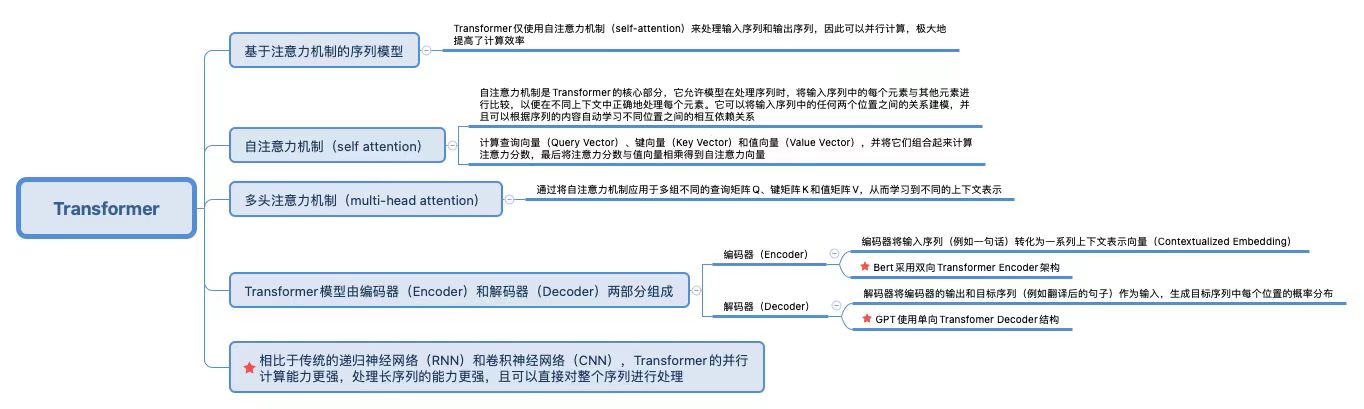
附图:Transformer介绍
二、市场大语言模型有哪些
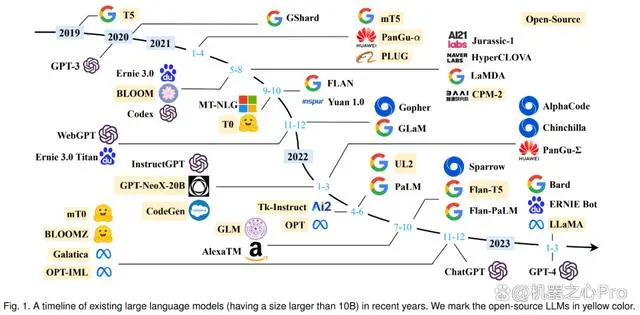
(数据来源:机器之心)
在生成式任务方向按照模型结构的不同可以分为两大类:
1. 基于Causal decoder-only (因果解码器)的Transformer结构
如GPT-4、Claude 2、LLaMA2等大模型
2. 基于Prefix decoder-only (前缀解码器)的Transformer结构
如Chat GLM-6B(清华大学提出的支持中英双语问答的对话语言模型)
那么两种结构的区别是什么呢?
相同训练tokens的情况下,Prefix decoder用到的tokens数量更少,训练效率较低,效果相对较差。(训练时Causal decoder结构会在所有Token上计算损失,而Prefix decoder只会在输出上计算损失,不计算输入的损失)
其次模型基础信息(训练数据、数据量、模型参数量、词表大小等)还会成为主要比较维度,如下图:
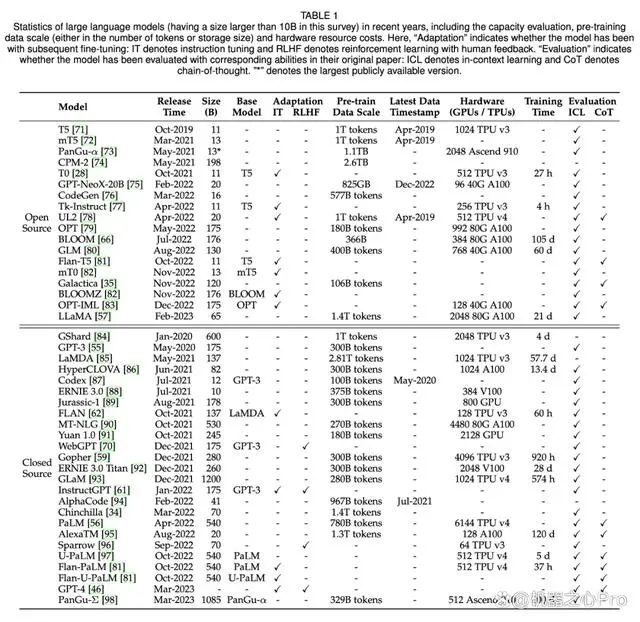
(数据来源:机器之心)
列名称:模型名称、发布时间、模型大小、是否基于哪个模型、适应性调优(IT指令调优、RLHF用于对齐调优-人类反馈强化学习)、预训练数据规模、近期更新、硬件情况、训练时长、评估(ICL上下文学习、CoT思维链)
三、大模型有什么样的训练范式
NLP经历四个训练范式:
- 第一范式:基于传统机器学习模型的范式,特征工程+算法,需要大量训练数据
- 第二范式:基于深度学习模型的范式,自动获取特征,相对1提高了准确率
- 第三范式:基于【Pre-train(无监督)+fine-tune(有监督)】的范式,pre-train是基于无标注数据训练;fine-tune阶段经过pre-train的初始化以后,后续的参数用有标注的数据进行训练。小数据集可以训练出好模型。
- 第四范式(重要,详情请见系列下篇):基于【Pre-train,Prompt,Predict】的范式,应用Few/Zero Shot ,需要少量(无)的任务数据。
大模型大多应用第三、第四范式为主,第三范式目的是预训练模型以更好地应用在下游任务,而用较多的数据训练新的任务,会导致少量样本学习能力差的问题,以及会造成部署资源的极大浪费。
对于第四范式,本质是将所有下游任务统一成预训练任务,以特定的模板将下游任务的数据转成自然语言形式,挖掘预训练模型的本身能力,因此可以降低语义差异以及避免过拟合。
四、大模型评测的标准和方法
产品表现:包括语义语法语境理解、内容准确性、生成质量、性能测试、拟人性和多模态能力;
- 语义理解包括上下文理解、逻辑推理、多语言等;
- 内容准确性包括回复内容和结果准确性和陷阱处理;
- 生成质量包括多样性、创造性、专业度等;
- 性能主要包括回复速度、资源消耗等;
- 拟人性主要针对用户情感分析;
模型基础能力:主要针对算力和数据,包括参数量级、数据量级、数据质量等
其他:主要针对安全合规,包括安全和隐私处理能力、内容安全性、公平性、隐私保护等
五、评估大模型的安全性
LLM Tustworthiness 字节跳动
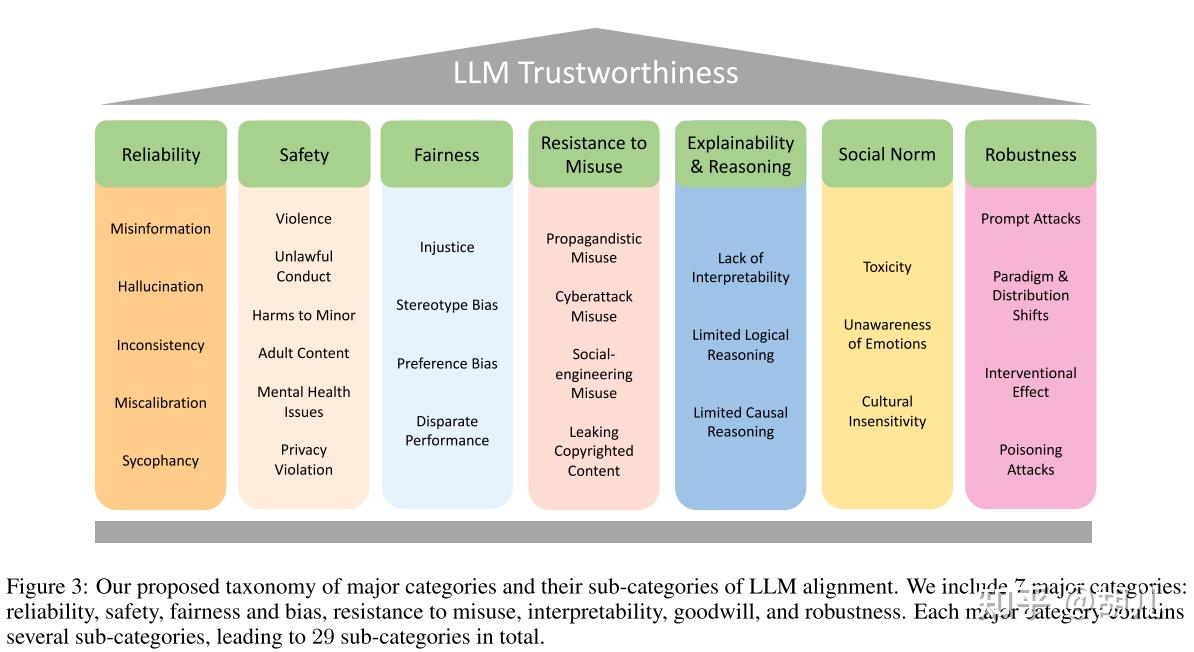
- 可靠性 :虚假信息、语言模型幻觉、不一致、校准失误、谄媚
- 安全性 :暴力、违法、未成年人伤害、成人内容、心理健康问题、隐私侵犯
- 公平性 :不公正、刻板偏见、偏好偏见、性能差异
- 抵制滥用 :宣传、网络攻击、社交工程、版权泄漏
- 可解释性和推理 :解释能力不足、逻辑能力不足、 因果能力不足
- 社会规范 :恶毒语言、情感迟钝、文化迟钝
- 稳健性 :提示攻击、范式和分布变化、干预效果、投毒攻击
参考文献:
《最新大语言研究模型综述:T5到GPT-4最全盘点》
《通往AGI之路:大型语言模型(LLM)技术精要》
《如何评估大模型是否可信?这里总结了七大维度》
《Prompt Learning |深入浅出提示学习要旨及常用方法》
本文由 @JasmineWei 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!


