
 起点课堂会员权益
起点课堂会员权益推荐产品经理必知必会①:数据处理
策略产品经理如何对数据进行处理?这篇文章里,作者做了方法介绍以及相应的内容梳理,一起来看看吧。

在正式介绍推荐策略之前,我们需要了解推荐策略产品经理如何对数据进行处理,一切策略都离不开数据。重点在于:
- 理清公司已有数据;
- 了解公司有哪些数据表;
- 判断数据表内的数据质量如何。
一、常见的底层数据表
电商领域常见的7张离线Hive表:

切片表:按照时间分区,将每天的新数据放在一个独立的时间分区里,例如:7月1日与7月2日的不同。
增量表:汇总所有数据,新增数据直接在原始表内添加,不增加新分区,订单表与卖点数据均是增量表,因为其需要选择某个时段or历史所有数据,直接截取即可,如果存在不同分区,截取就会很麻烦。
二、数据表加工
ETL(extract-transform-load,抽取——转换——加载):从底层数据表抽取数据,然后再清洗加工,最终得到上层表,这一过程不断进行。
三、数据归一化与标准化
不同类型的数据需要转化为同一量纲才能进行比较,需要归一化/标准化,本质上是一种线性变换(缩放+平移)。(归一化≠标准化)
1. 归一化
Min-Max(最小最大值)归一化(最常用的方式):
x* = ( x − min ) / ( max − min )
归一化后的数值处于[0,1]之间,实际数据中存在无解释度的极大(小)值,故需要挑选合适的最大(小)值。
适用场景:数据分布集中。
均值归一化:
x* = ( x − mean ) / ( max − min )
归一化后的数值处于[-1,1]之间
适用场景:数据存在极值,但在业务视角这一极值是合理的。
Log对数函数归一化:
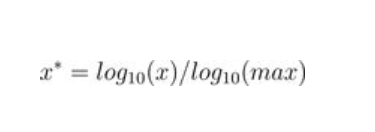
归一化后的数值处于[0,1]之间,非线性的归一化方式,缩小数据间的差距,使之分布均衡。
适用场景:样本数据跨度大,头部极值出现频率相对高。
2. 标准化
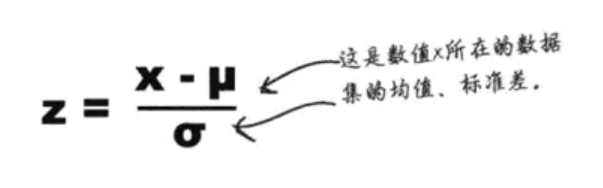
归一化/标准化可以消除不同数据之间量纲差异巨大带来的无可比拟性:
- 若异常值和噪声较多,使用标准化数据处理方式可以消除不同特征差异权重的影响,使之权重趋同(归一化保留了潜在权重关系)。
- KNN和K-Means等涉及距离的业务中,若各特征变量对最终距离影响一致,需要用标准化处理,其余应用根据业务需求进行。
以上介绍的数据处理方法在策略产品工作中会经常用到,一定要熟悉哦!
本文由 @策略产品经理规划 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


