
 起点课堂会员权益
起点课堂会员权益一个有价值、有趣的新产品方向:AI评测工具(含5个案例)
随着AI技术的快速发展,市场上涌现出了众多AI产品和服务,但如何评估这些产品的性能和效果成为了一个关键问题。本文将探讨“AI评测工具”这一新兴且有价值的产品方向,并通过5个具体案例,展示AI评测工具在不同场景中的应用,供大家参考。

通过一些案例共性,我们可以提炼出「AI评测工具」这个需求场景/产品形态,感觉比较有代表性,也很有意思,大家可以关注下。
下面是具体的5个案例,评测对象范围,涉及:AI文档类产品、大模型速度、Prompt生成及评测、Prompt版本管理及表现评测,甚至还有最后的“AGI评测”。
案例1:「文档解析产品评测工具TextIn」
里面说,对文档解析类AI产品的测评工具需求,越来越多
- 需求非常多样,不同用户偏重不同:年报、财报、论文、政策文件、企业内部文件,或教科书、试卷、公式等等。
- 而评估各款产品,目前是非常痛苦的:测试效果,要么是端到端的,很难真正定位到解析表现;要么是肉眼判断,耗时费力,还只能观测一小部分样本。
所以需要有对应的工具,帮用户筛选适合自己场景的AI产品,节省“选择”和“测试”的时间。
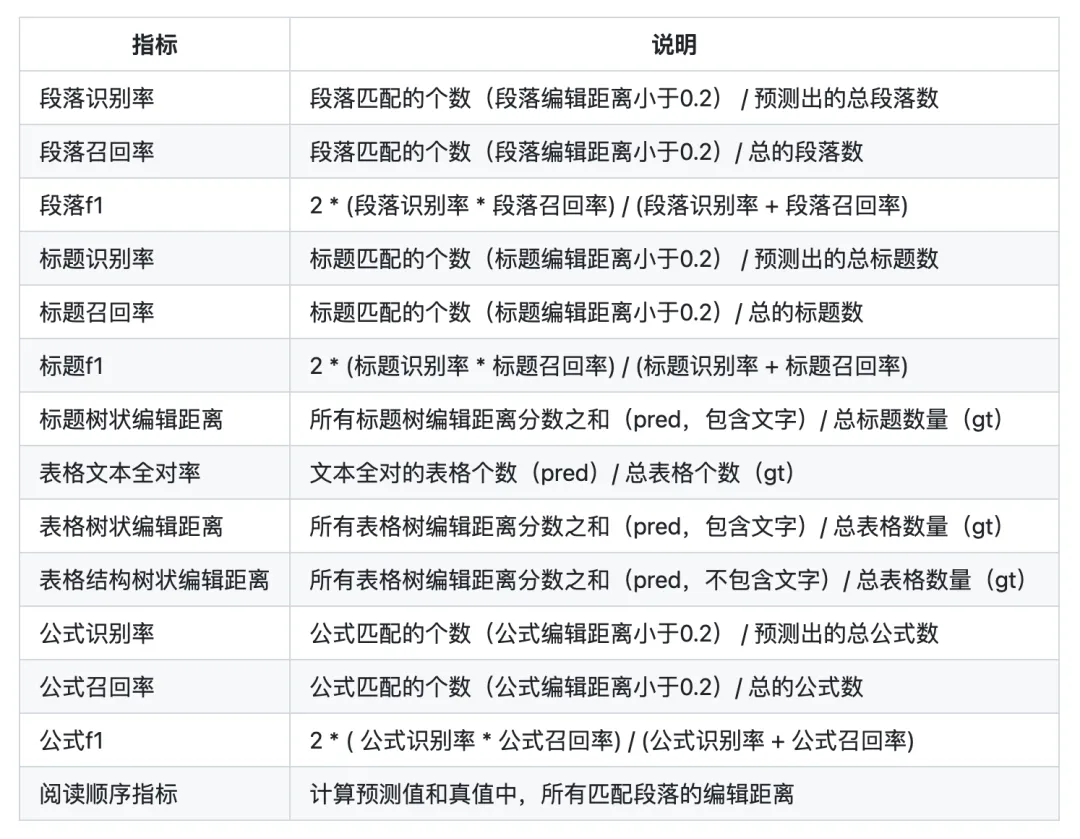
比如TextIn这个工具,评价指标分5个维度,针对表格、段落、标题、阅读顺序、公式进行定量测评,结果有“表格和雷达图”两种样式。具体指标项如下——
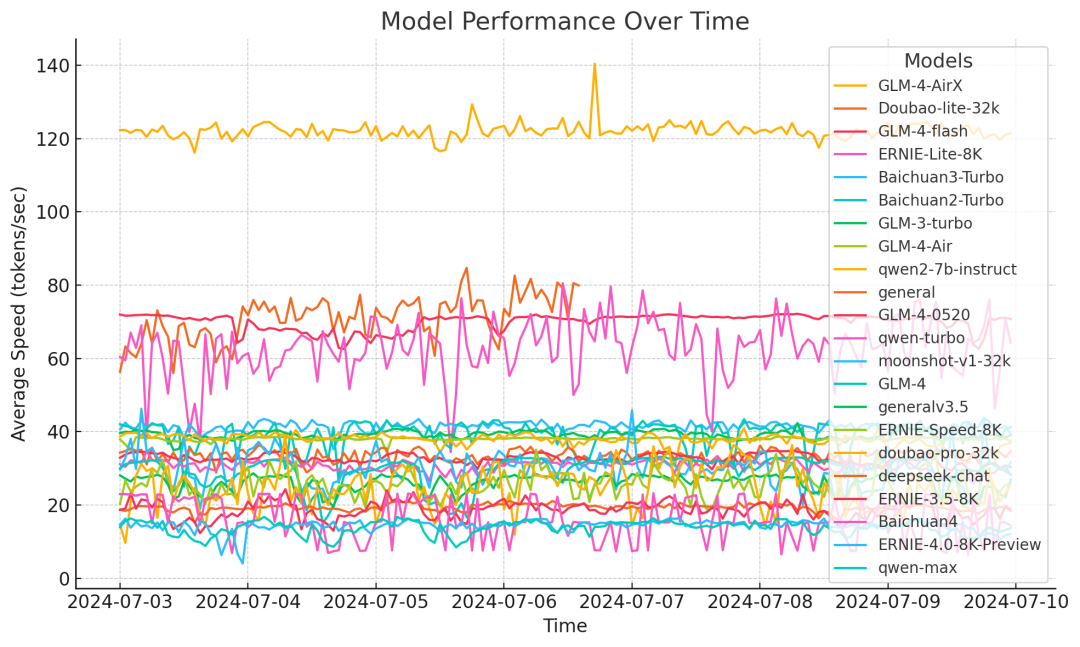
案例2:大模型速度评测——《大模型真实速度一览》
案例3:Claude 「prompt 生成器」功能 :一键生成、测试和评估prompt
由 Claude 3.5 Sonnet 提供支持,用户可描述任务、然后让 Claude 生成高质量的 prompt
- 可修改、并一键运行所有测试用例
- 可对更好的响应进行评分,以跟踪哪个 prompt 表现最佳。
案例4:Prompt 版本管理网站评测
本质也是类似的需求——能管理Prompt的历史版本,能展现Prompt在多模型下的表现。
测试发现Athina比较好(官网 https://athina.ai/ ,需能上外网)。支持自定义 API key,并支持 Prompt 的版本提交。
Prompt开发好后,可用Dify测试同一个 Prompt在“多模型下的效果”。
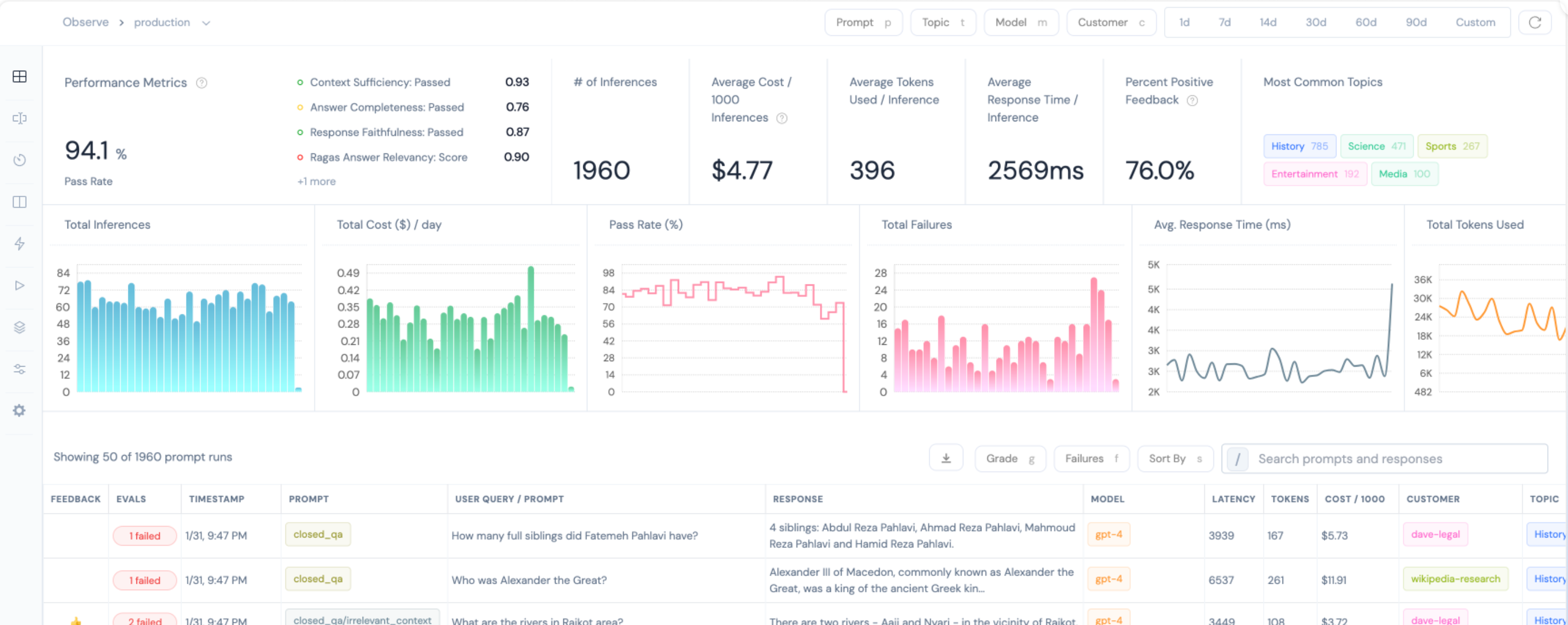
案例5:在文章《Zapier创始人:大多数人对AGI的定义都是错误的!》中,竟然还涉及对AGI的评测
“刚刚启动了ARC Prizes。这是一个百万美元以上的非营利性公共挑战,旨在完成François的ARC AGI评估,开源解决方案和进展。据我所知,ARC AGI是世界上唯一一个真正存在的AGI评估,它测量了AGI的正确定义。”
1)AGI发展停滞的最大原因是:AI行业的主流定义——AGI是一个能够完成大多数有经济效益工作的系统——是错误的。
衡量错误的东西,带给了我们AGI快要成功的错觉,导致AI研究人员和整个世界“过度投资于利用大规模语言模型范式,而不是探索急需的新思想”。
2)AGI的正确定义是:一个能够高效地获取新技能,并利用这种能力解决开放性问题的系统。
由此可见,仅仅扩大语言模型规模不能解决问题,还需要类似于Transformers的基本组件。此外,两个实现AGI的思路分别是:程序合成和神经架构搜索。
3)AGI ARC评估的重点在于,它是通用智能的一个最小再现版本。所以,ARC Prize背后的设置动机是:ARC的解决方案可能来自局外人,因为他们没有被当前语言模型和规模的思维方式所洗脑。
大家可以想想,自己所在的AI细分领域,是否存在这种“AI评测工具”的产品机会呢?
专栏作家
hanniman,微信公众号:hanniman,人人都是产品经理专栏作家,前图灵机器人-人才战略官/AI产品经理,前腾讯产品经理,10年AI经验,13年互联网背景;作品有《AI产品经理的实操手册》、200页PPT《人工智能产品经理的新起点》。
本文原创发布于人人都是产品经理,未经许可,不得转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


