
 起点课堂会员权益
起点课堂会员权益数字人的“灵魂”究竟在哪里?
数字人视觉已能以假乱真,交互却满是空洞感。盛大 AI 东京研究院推出的 Mio 框架,直击人格漂移、僵尸脸、无自主进化三大痛点,以交互智能和时空智能为核心,实现数字人从 “形似” 到 “神似” 的跨越,带来有灵魂的交互体验。

你有没有感觉到,当下的数字人交互总是差了点什么?明明视觉效果已经做到以假乱真,但跟它们对话时,总有种说不出的空洞感。就像在和一个精美的人偶说话,而不是一个真正的”人”。这种感觉并不是错觉。尽管科技公司已经在数字人视觉特效上投入了数十亿美元,创造出了令人惊叹的虚拟形象,但用户粘性依然很低,大多数人体验几次后就不再回来。问题到底出在哪里?我最近关注到盛大集团旗下的盛大AI东京研究院在 SIGGRAPH Asia 2025 上的首次公开亮相,他们推出的 Mio 框架让我看到了破解这个难题的可能性。
这次亮相不仅仅是一次技术展示。盛大AI东京研究院通过展台活动、学术讨论和顶尖教授闭门交流等形式,系统性地阐述了他们对数字人未来的理解。更重要的是,他们明确提出了”交互智能”和”时空智能”这两个核心研究方向。我认为这代表了整个行业的一次重要转向,从追求视觉逼真度转向追求真正有意义的交互体验。而这个转向背后,是盛大集团创始人陈天桥先生长期以来对脑科学与AI融合研究的战略投入。他在 TCCI 首届 AI 驱动科学研讨会上提出的”发现式智能”理念,强调了智能体认知基底的重要性,这正是 Mio 框架的理论基础。
数字人为什么缺乏”灵魂”
我一直在思考这个问题:为什么技术已经如此先进,数字人看起来已经那么真实,但我们在与它们交互时,还是能立刻感觉到不对劲?盛大AI东京研究院首席科学家郑波博士在研讨会上深入剖析了这个”灵魂缺失”的核心难题。他指出,这不是某个单一技术环节的问题,而是三个层面的系统性挑战共同作用的结果。
第一个挑战是长期记忆与人格一致性的缺失。现在的数字人大多基于通用大语言模型构建,但这些模型在长时间对话中很难保持稳定的人格设定。你可能会发现,跟同一个数字人聊天,它前面说的话和后面说的话完全矛盾,好像换了个人一样。这种现象被称为”人格漂移”。更糟糕的是,这些数字人经常会”失忆”,忘记之前对话中的重要信息,导致整个交流变得支离破碎。我觉得这就像是在跟一个患有严重健忘症的人对话,你不可能与这样的对象建立真正的关系。真正的”记忆”不仅仅是对过往事件的回溯,更是维持个性、习惯和世界观连贯性的基石。缺乏这一能力,数字人就无法形成可信赖的、持续的身份认同。
 盛大AI东京研究院首席科学家郑波博士深入剖析数字人“灵魂缺失”的核心难题,并确立了以“交互智能”和“时空智能”为核心的研究目标。
盛大AI东京研究院首席科学家郑波博士深入剖析数字人“灵魂缺失”的核心难题,并确立了以“交互智能”和“时空智能”为核心的研究目标。
第二个挑战是多模态情感表达的严重不足。在现实生活中,人与人的交流远不止语言本身。我们会通过面部表情、眼神、语调、肢体动作来传递丰富的情感信息。但现在的数字人普遍存在一个致命问题:当它们在倾听或思考时,面部表情僵硬得像个面具,完全没有自然的微表情和反应。这种现象被形象地称为”僵尸脸”。想象一下,你在跟一个人倾诉心事,对方虽然在说话回应你,但脸上毫无表情变化,眼神空洞,你会是什么感受?这就是当前数字人给用户带来的体验。真正的沉浸感来自于语音语调、面部表情、眼神乃至肢体动作的协同作用,它们共同构成了情感表达的完整层次。而目前的技术在这方面明显是薄弱的。
第三个挑战是缺乏自主进化的能力。大多数数字人本质上还是一个被动的”播放系统”,根据预设脚本或实时指令做出反应,而不能从交互中学习和成长。它们无法自主适应用户的偏好,无法修正错误的认知,也无法发展出新的行为模式。这种缺乏自我进化能力的状态,让数字人永远停留在”模仿”的层面,无法真正成为智能体。我认为,这是数字人与真正AI智能体之间最大的鸿沟。一个不能学习、不能成长的系统,怎么可能有”灵魂”?
这三大挑战共同作用,导致了当前数字人交互体验的浅层化和碎片化。用户很难与数字人建立真正的情感连接,因为这些数字人既没有连贯的”自我”,也没有丰富的情感表达,更无法随着交互而成长。如何系统性地攻克这些难题,不仅是技术上的挑战,更需要顶层的战略远见和长期的研究投入。
 香港大学教授、SIGGRAPH Asia 大会主席 Taku Komura, 在盛大AI东京研究院闭门研讨会上发表致辞。
香港大学教授、SIGGRAPH Asia 大会主席 Taku Komura, 在盛大AI东京研究院闭门研讨会上发表致辞。
行业共识正在形成
让我感到振奋的是,解决这些挑战的紧迫性已经成为整个行业的共识。2025年12月17日,在香港 SIGGRAPH Asia 大会期间,盛大AI东京研究院主办了一场高端闭门晚宴及专题研讨会。这场活动的时机很特别,恰好是在他们的 Mio 技术报告公开发布的第二天。我认为这个时间安排很有意义,因为它让与会专家能够基于最新的技术突破进行深度讨论。
这场研讨会汇聚了来自学术界和产业界的顶尖专家,阵容非常强大。包括香港大学教授、SIGGRAPH Asia 大会主席 Taku Komura,早稻田大学教授、日本数字人协会主席 Shigeo Morishima,以及来自东京科学大学、香港中文大学、香港科技大学的多位知名教授。这些专家都是各自领域的领军人物,他们的观点代表了行业最前沿的思考。特别值得一提的是 Shigeo Morishima 教授,他是第一个将真人自动化复刻到电影的先驱者,在数字人领域有着深厚的积累。
 来自港大、港中大、港科大及东京科学大学的顶尖学者在 Panel 环节深度探讨“交互智能”的未来。
来自港大、港中大、港科大及东京科学大学的顶尖学者在 Panel 环节深度探讨“交互智能”的未来。
在这场高水平的对话中,专家们达成了一个清晰而重要的共识:当前数字人发展的瓶颈已经从视觉表现力转向了认知和交互逻辑。换句话说,让数字人看起来像真人已经不再是主要问题,真正的挑战在于让它们能够像真人一样思考和交流。他们一致认为,未来数字人的核心竞争力将体现在”交互智能”上,具体来说,就是必须具备长期记忆、多模态情感表达和自主演进这三大关键能力。
我觉得这个共识的形成意义重大。它意味着整个行业的焦点正在发生根本性转变。过去几年,大家都在拼命提升数字人的视觉效果,追求更高的分辨率、更逼真的皮肤纹理、更自然的光影效果。但现在,最敏锐的头脑们意识到,这条路已经走到了尽头。再往前走,必须解决认知和交互的问题。这种转变不是某个公司或研究团队的一厢情愿,而是全球顶尖学者经过深入讨论后达成的一致看法。
更有意思的是,这个共识恰好与 Mio 框架的设计理念高度吻合。Mio 的三大核心模块——认知核心、多模态动画师和自主演进框架——正是针对这三大关键能力而设计的。这不是巧合,而是盛大AI东京研究院团队长期深耕这个领域、准确把握行业脉搏的结果。他们不是在闭门造车,而是在与全球最顶尖的研究者保持密切交流的基础上,系统性地推进技术创新。
Mio 框架:一个系统性的解决方案
基于对行业挑战的深刻理解和与顶尖学者的交流共识,盛大AI东京研究院正式推出了 Mio 框架,全称是 Multimodal Interactive Omni-Avatar。这个名字本身就透露出它的野心:打造一个多模态、交互式的全能数字人。我认为 Mio 的诞生标志着一个分水岭时刻,它代表了数字人技术从”形似”向”神似”的决定性跨越。
Mio 的设计理念非常清晰:将数字人从一个被动执行指令的”木偶”,转变为一个能够自主思考、感知并与世界互动的智能伙伴。这不仅仅是技术上的改进,更是一种哲学思想的转变。过去我们把数字人当作工具,现在我们要把它们当作伙伴。这种转变对技术架构提出了完全不同的要求。
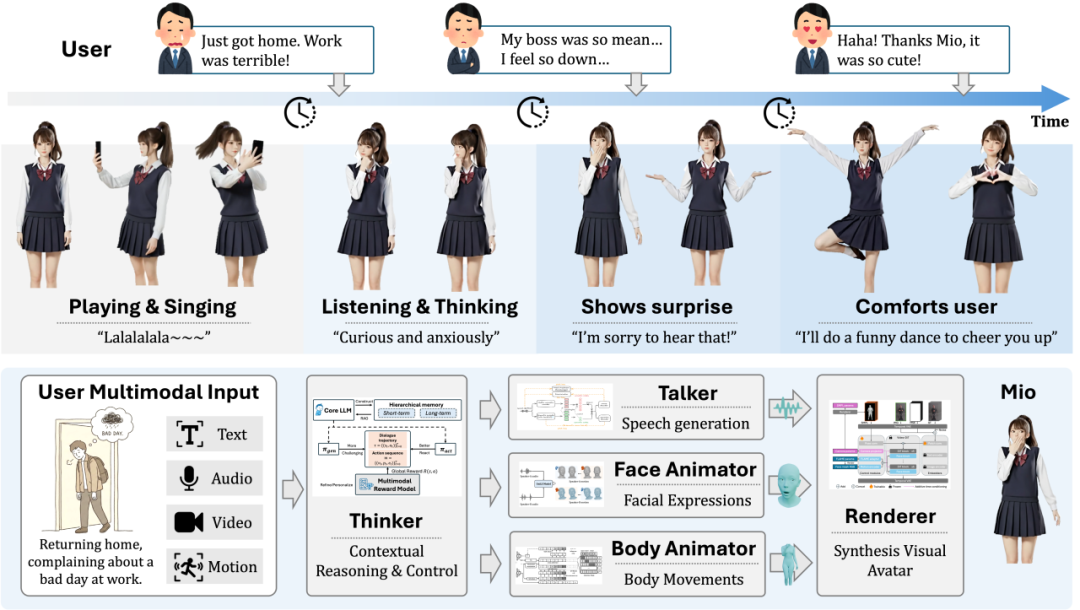
Mio 系统的端到端交互闭环演示——从感知用户情绪(User Input)到 Thinker 进行认知推理,再通过多模态模块(Face/Body/Speech)生成抚慰性的反馈动作。
Mio 框架由五个高度协同的核心模块构成,每个模块都针对数字人”灵魂缺失”的某个具体方面提供解决方案。我觉得这种模块化设计非常聪明,因为它既保证了整体架构的灵活性,又确保了各个模块之间的紧密协作。
第一个模块是认知核心,被称为 Thinker,它相当于数字人的”大脑”。为了克服标准大语言模型固有的”失忆症”和人格漂移问题,Thinker 采用了一种革命性的”介于叙事时间的知识图谱”技术。这个技术的巧妙之处在于,它为每条信息都标记了”故事时间”。什么意思呢?比如说,如果这个数字人扮演的是某个电影角色,它就绝对不会在对话中”剧透”还没发生的剧情。这听起来简单,但实际上需要非常精细的时间线管理和上下文理解能力。在 CharacterBox 基准测试中,Thinker 的人格保真度超越了 GPT-4o,这是目前最强大的大语言模型之一。更令人印象深刻的是,在防止剧透的测试中,它取得了超过 90% 的准确率,这几乎是完美的表现。
更重要的是,Thinker 还具备无需人工标注的自我进化机制。它采用了一种我觉得非常巧妙的”左右互搏”式自我训练循环。一个场景生成策略会不断设计出刁钻的互动场景,专门用来挑战和探测当前数字人的”人设”弱点。另一个互动扮演策略则扮演数字人本身,努力在这些场景中做出最符合人设的回应。最后,一个多模态奖励模型会根据用户的全局满意度反馈,智能地反推出每一次具体互动的”功劳”或”过错”,并给予精细化的奖励或惩罚。通过这个自我博弈的过程,数字人不断地在自我挑战中优化自己的行为,使其人格表现越来越稳定和真实,就像 AlphaGo 通过自我对弈变得越来越强一样。
第二个模块是语音引擎 Talker。它负责将 Thinker 生成的文本转化为生动的语音,研究团队为此开发了 Kodama-Tokenizer 和 Kodama-TTS。Kodama 的核心思想在于将语音信号解耦为”语义”和”声学”两种信息。前者决定”说了什么”,后者决定”听起来怎么样”。这种设计使得模型可以对不同信息进行针对性压缩和建模,最终以极低的比特率(仅 1kbps)实现高质量的语音重建。实验数据显示,Kodama 在语音重建和零样本 TTS 任务中,无论是在自然度还是发音准确率上,都展现出与当前最优模型相当甚至更好的性能。这意味着 Talker 生成的语音不仅清晰准确,而且富有表现力,能够传递出数字人的情感和个性。
第三个模块是面部动画师 Face Animator,它通过提出的 UniLS(Unified Speak-Listen)模型,彻底解决了数字人在”聆听”时的”僵尸脸”问题。UniLS 的巧妙之处在于它的两阶段训练策略。第一阶段是无音频预训练,模型在海量的、无音频的视频数据上学习各种内在的面部动态先验,比如自然的眨眼、微表情和头部晃动。第二阶段是音频驱动微调,在预训练好的模型基础上,引入对话双方的音频信号进行微调。通过交叉注意力机制,模型学会将内在的动态与外部的音频信号结合起来,从而生成既包含说话时的口型同步,也包含聆听时的生动反应。在用户研究中,超过 90% 的参与者认为 UniLS 的聆听反应优于业界领先的竞品,在客观指标上,聆听时的 F-FID 指标从竞品的 10.779 骤降至 4.304,这表明 UniLS 生成的聆听动作分布更接近真实人类的表现。
第四个模块是身体动画师 Body Animator。为了实现实时、可控、无限长的身体动作生成,它引入了 FloodDiffusion,一种专为流式生成设计的扩散模型。FloodDiffusion 的核心创新是下三角噪声调度。传统扩散模型在每个时间步对整个序列施加同样水平的噪声,导致计算量随序列长度线性增长。而 FloodDiffusion 创造了一种”级联”式的去噪模式,在任何时刻,只有一小段”活动窗口”内的动作在被积极去噪,而之前的动作已经”尘埃落定”,之后的动作则完全是噪声。这种设计保证了模型在生成时,计算量是恒定的,延迟有严格的上界,从而实现了真正的流式输出。更重要的是,它还支持时变文本条件,可以随时接收来自 Thinker 的新指令,并丝滑地过渡到新动作。在标准数据集上的评测显示,FloodDiffusion 的 FID 指标达到了 0.057,在保持实时性的同时,其运动质量与顶尖离线模型相媲美。
第五个模块是渲染引擎 Renderer。它负责将前面各个模块生成的参数化控制信号转化为高保真、身份一致的视频。研究团队提出了 AvatarDiT,一个基于视频扩散 Transformer 的渲染框架。AvatarDiT 采用了三阶段训练策略来解耦并学习身份、面部控制和多视角一致性这三大难题。实验结果表明,AvatarDiT 在多视角一致性和整体感知质量上均优于现有的最优方法,在主观评分中,它在所有维度上都获得了最接近真实视频的评分。
我特别欣赏 Mio 框架的一点是,它将这五个模块无缝融合,实现了从认知推理到实时多模态体现的完整闭环。这不只是把几个技术模块拼在一起,而是让它们真正协同工作,形成一个有机的整体。举个例子,当用户说了一句让数字人感到悲伤的话,Thinker 会理解这个情绪并做出相应的认知反应,Talker 会生成带有悲伤情绪的语音,Facial Animator 会让面部表情呈现出悲伤,Body Animator 会让肢体动作变得低落,最后 Renderer 会把这一切渲染成一个完整的、令人信服的悲伤反应。这整个过程是实时的、协调的、自然的。
交互智能的量化突破
谈了这么多技术细节,你可能会问:这些改进到底有多大效果?盛大AI东京研究院团队给出了一个可量化的答案。他们建立了一个新的评估基准来衡量”交互智能”,这个基准涵盖了语音、表情、动作、视觉风格和人格一致性等多个维度。在这个严格的测试中,Mio 的整体交互智能分数达到了 76.0,比之前的最优技术水平提升了整整 8.4 分。
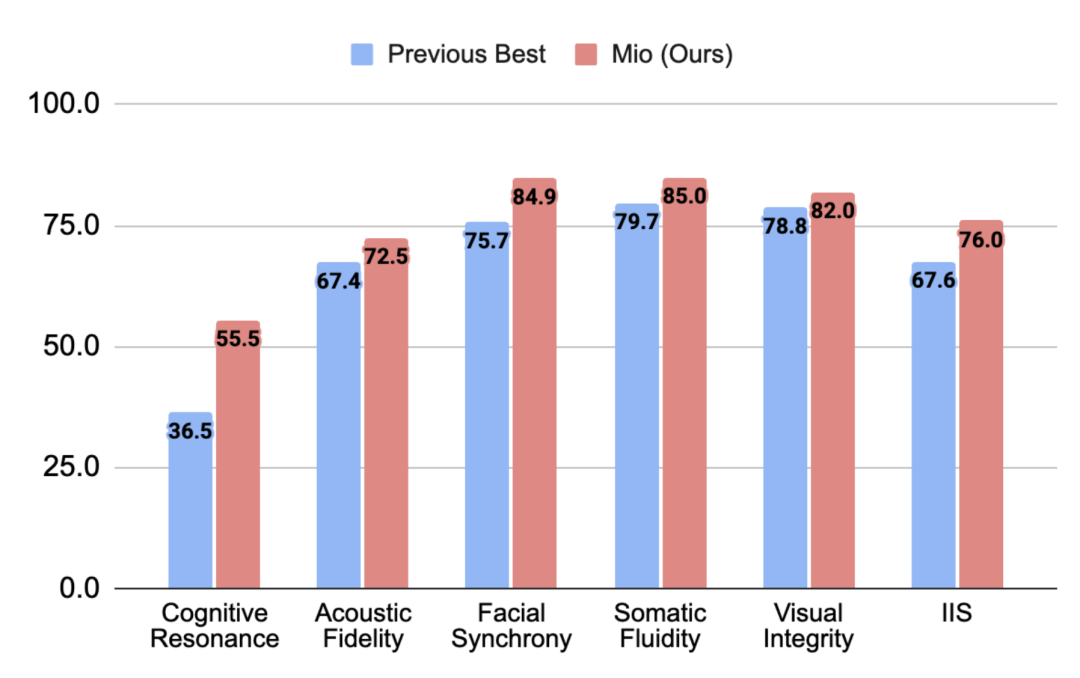 Mio (红色) 在认知共鸣、面部同步、肢体流畅度等各项指标上全面超越现有最优技术 (蓝色),IIS 总分达到 76.0。
Mio (红色) 在认知共鸣、面部同步、肢体流畅度等各项指标上全面超越现有最优技术 (蓝色),IIS 总分达到 76.0。
这个提升幅度意味着什么?在学术界和工业界,能够在成熟的基准测试上提升几个百分点就已经很了不起了,提升 8.4 分可以说是一个巨大的飞跃。更重要的是,这不是在某个单一指标上的提升,而是在认知共鸣、面部同步、肢体流畅度等各项指标上的全面超越。这说明 Mio 不是在某个方面特别强、其他方面特别弱的偏科型选手,而是一个全面发展的优等生。
我认为这个量化结果的意义不仅在于数字本身,更在于它证明了”交互智能”是可以被科学测量和持续改进的。过去,数字人的”灵魂感”往往被视为一个主观的、难以捉摸的概念。但现在,通过建立合理的评估体系,我们可以清晰地看到技术进步带来的实际效果。这为整个行业提供了一个明确的优化方向和衡量标准。
从展示的对比图表中可以看出,Mio 在各个维度上都明显优于现有的最优技术。特别是在面部表情和肢体动作的流畅度方面,提升尤为显著。这正是用户最容易感知到的方面,也是决定交互体验好坏的关键因素。当一个数字人的表情和动作足够自然流畅时,用户就更容易忽略它是虚拟的这个事实,从而产生真正的情感投入。
这对行业意味着什么
Mio 的诞生标志着数字人发展的一次范式转移。整个行业的关注焦点正在从静态的、孤立的外观逼真度,转向动态的、有意义的交互智能。我觉得这种转变是必然的,也是正确的。过去十年,我们见证了计算机图形学的飞速发展,数字人的视觉效果已经达到了令人惊叹的程度。但仅有好看的外表是不够的,就像一个人不能只靠长相吸引他人一样。
可以预见,”交互智能”将为多个领域带来革命性的变革。在虚拟陪伴领域,未来的数字人将不再是简单的聊天机器人,而是能够建立长期关系、提供情感支持的智能伙伴。想象一下,一个能够记住你所有喜好、理解你情绪变化、陪伴你成长的数字朋友,这将为那些孤独的老年人或需要心理支持的人群提供巨大价值。
在互动叙事领域,交互智能将彻底改变我们体验故事的方式。传统的游戏或影视作品中,NPC(非玩家角色)的行为都是预设好的,你只能沿着既定的剧本走。但有了真正的交互智能,每个 NPC 都可以成为一个有独立人格、能够自主反应的角色。你与他们的每次对话都可能影响剧情走向,创造出真正个性化的故事体验。这将把互动娱乐提升到一个全新的层次。
在沉浸式游戏领域,交互智能的应用潜力更是巨大。现在的游戏 NPC 往往让人出戏,因为它们的反应太机械、太可预测。但想象一下,如果游戏中的每个角色都像 Mio 这样,拥有连贯的记忆、丰富的情感表达和自主学习能力,游戏世界将变得多么真实和引人入胜。玩家将不再是在”玩”游戏,而是在与一个真实的虚拟世界互动。
我也看到了一些潜在的挑战和问题。当数字人变得如此真实和有”灵魂”时,人们可能会对它们产生真实的情感依赖。这是好事还是坏事?如何平衡虚拟关系和现实关系?如何确保这种技术不会被滥用?这些都是需要认真思考的伦理问题。但我相信,技术本身是中性的,关键在于我们如何使用它。
为了推动这一领域的共同进步,盛大 AI 东京研究院已将 Mio 项目的完整技术报告、预训练模型和评估基准公开发布。
这是 Mio 的最新 Demo——并非终点,但我们已经第一次清晰地看见,数字人“有灵魂”的曙光
本文由人人都是产品经理作者【深思圈】,微信公众号:【深思圈】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


