
 起点课堂会员权益
起点课堂会员权益RAG 全攻略:传统RAG / Graph RAG/Agentic RAG 详解,一文读懂 RAG
RAG(检索增强生成)为AI模型赋予专属知识库与精准搜索引擎,使其回答更准确、具时效性。本文深入解析其三大核心形态及应用,助您全面了解RAG的原理与实践。

RAG 核心认知:是什么、有哪些形态
什么是RAG
简单说,RAG(检索增强生成)就是给 AI 模型装了一个 “专属知识库 + 精准搜索引擎”。AI 在回答问题时,只基于你提供的真实知识(比如公司文档、专业资料、实时数据)生成答案,既避免瞎编,又能精准对接具体需求。让模型生成的内容更准确、更具时效性、更可追溯。
RAG 三大核心形态:传统 RAG、Graph RAG、Agentic RAG
传统RAG
简单总结一下,就是将大模型需要的各种知识先进行向量化存储到数据库里面,然后用户询问的时候从数据库找相近的知识,检索出来之后进行重排序(rerank),获取最终的检索结果,将检索结果作为背景知识给到 LLM 生成大模型,获得基于你的背景知识的回复。
Graph RAG
Graph RAG(图谱增强生成)的核心是 “知识图谱”—— 把分散的信息变成一张 “关系网”,比如 “张三 – 操作 – M001 设备 – 生产 – P2025 批次物料 – 被用于 – F 工序”,每个关键信息都是 “节点”,它们之间的关联是 “连线”。这种结构让 AI 能看懂信息背后的逻辑,它能顺着关系网找到完整的因果链,而不是只给一堆无关的片段。
一方面能做 “链接预测”,比如根据历史数据判断 “经过 M001 设备且核心指标 X 偏高的物料,大概率会导致 F 工序瑕疵”,实现从 “事后分析” 到 “事前预警” 的升级;另一方面能优化智能检索,就算提问模糊(比如 “压力设备的参数问题”),它也能理解 “压力设备” 和 “冲压机” 的概念相似性,返回更全面的结果。
Agentic RAG
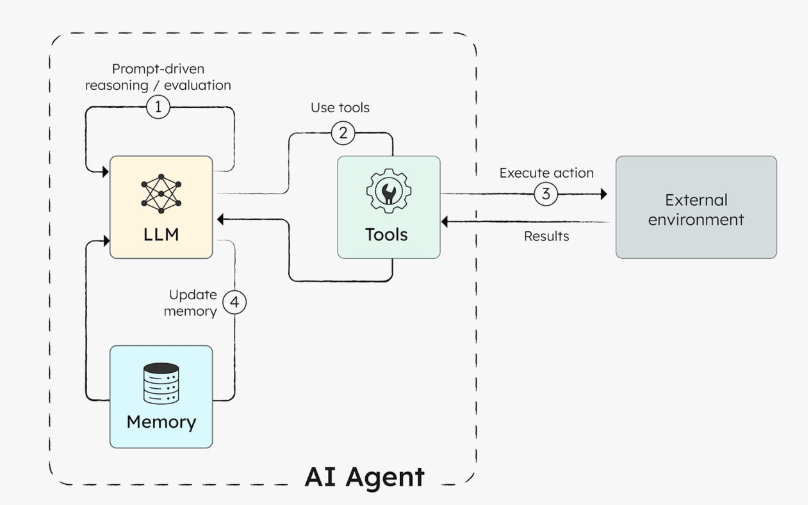
如果说传统 RAG 是 “被动检索 + 总结”,Agentic RAG 就是 “主动思考 + 解决问题”。它给 AI 加了一个 “自主智能体”,就像让 AI 有了自己的思维:能自己拆解复杂问题、动态调整找答案的方式、调用各种工具(比如地图、数据库、计算器),还能从经验中学习。
Agentic RAG 的强大离不开多智能体的分工协作。有人负责做计划,有人专门找资料,有人检查答案准确性,有人调用工具执行任务,还有人协调整体工作,就像一个高效的小团队。比如问它 “三个月内规划一场兼顾老人和孩子的欧洲游,预算 10 万”,它不会只给一堆旅游攻略,而是会先拆分成 “选目的地、查交通、订酒店、算预算” 等小任务,再逐个找信息、调用工具核实(比如用地图查路线、用预订平台看实时房源),最后整合出详细行程,还能记住你的反馈(比如 “某个景点人太多”),下次优化方案。
上下文工程:RAG 的底层逻辑支撑
RAG 其实是上下文工程(Context Engineering) 的具体落地形式。上下文工程的核心是通过设计、构建和管理输入给 AI 的 “上下文信息”,引导 AI 生成高质量答案。
它的流程比传统 RAG 更全面:会整合用户角色、实时数据、历史对话等多维度信息,先优化查询意图、筛选关键内容,再通过 “多模态上下文处理器” 把音视频等非文本数据转成文本,最后按最优结构组装成提示词交给 AI。简单说,上下文工程是 “方法论”,RAG 是 “具体工具”——RAG 解决了 “让 AI 用指定知识回答” 的核心问题,而上下文工程则把这个问题拓展到 “如何让 AI 结合所有相关信息,更精准地回答”,比如处理多模态数据、适配不同用户角色需求等。
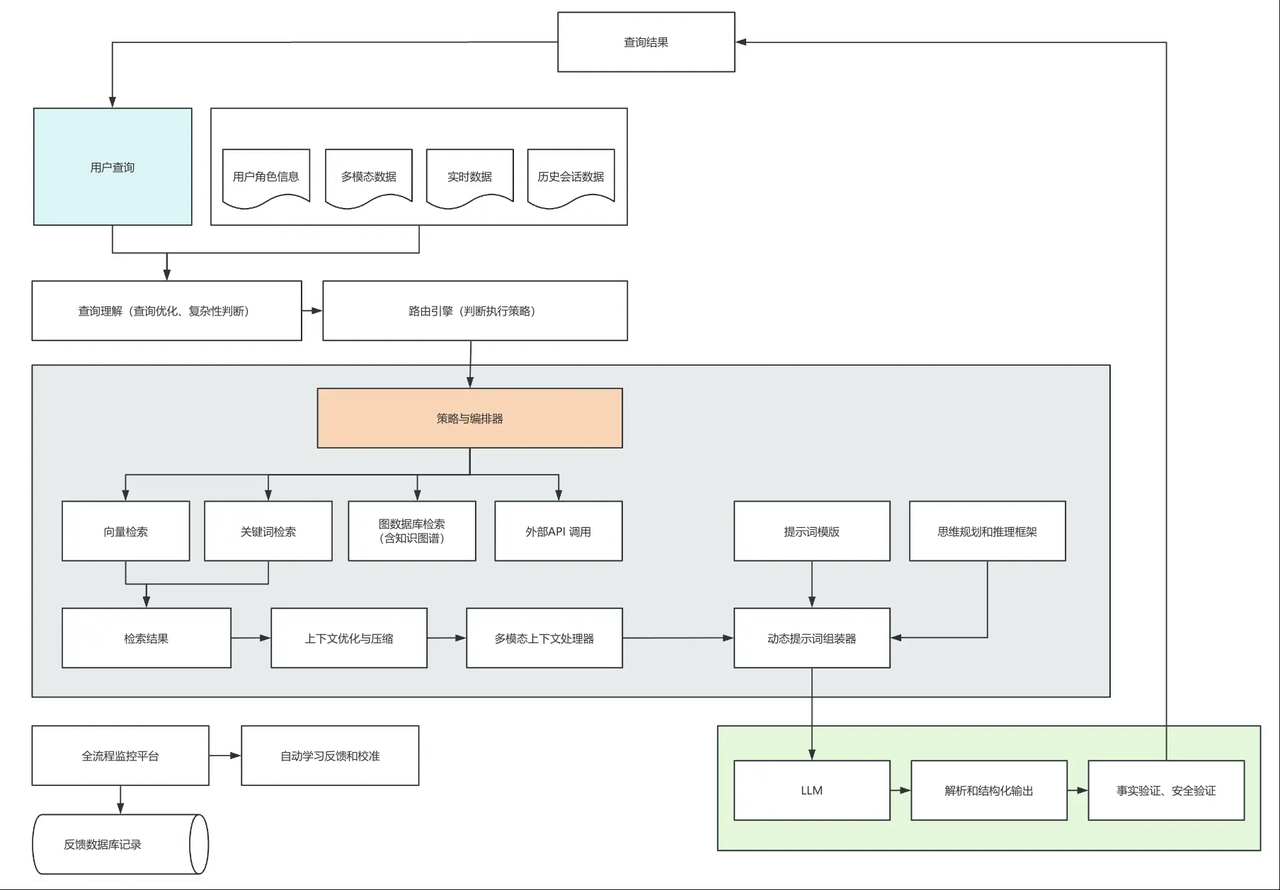
传统 RAG:简单直接的 “检索 – 总结” 流程
数据准备:给 AI 整理 “知识库”
1)文档切分:长文档(比如一本产品手册)不能直接用,得拆成小片段(专业叫 “Chunk”)。常见的拆法有 5 种,每种都有适用场景和细节注意:
- 固定大小切分:按字数 / 段落拆(比如每 200 字一块),会留部分重叠内容避免拆断语义,优点是简单易实现,缺点是可能在句子中途切分,破坏语义;
- 语义切分:按意思拆,通过计算 “余弦相似度” 判断 —— 如果两段内容的相似度高就合并,相似度大幅下降就拆分,能保留完整语义,但阈值判断需要根据文档调整;
- 递归切分:先按章节 / 段落拆,若片段还是太长就继续细分,兼顾语义完整性和大小限制,但实现成本稍高;
- 按结构切分:跟着文档的标题、章节走(比如 “介绍”“注意事项” 各成一块),保持文档逻辑,但需注意部分片段可能超过 AI 的 Token 限制,可搭配递归切分使用;
- 让 AI 帮忙切分:直接让大模型按语义逻辑拆,准确率最高,但计算成本也最高。
2)查询优化(前置关键步骤):这一步能大幅提升检索精准度,不是必需但强烈推荐。AI 会先对用户的提问做 “意图识别”(比如判断用户是要 “事实查询” 还是 “寻求建议”)、“查询改写 / 扩展”(比如把 “面试前准备” 扩展为 “面试前 5-30 分钟的候选人简历查阅、问题准备”)、“分类”,确保后续检索能精准命中相关信息。
3)向量化编码:把每个小片段变成 “能比较相似度的数字串”(专业叫 “向量”)。比如 “C 语言编程” 和 “写 C 程序代码” 的数字串很像,“天气怎么样” 和它们的数字串差别很大;
4)存储:把这些数字串 + 对应的原始片段,存到专门的 “向量数据库” 里(比如 Pinecone、PostgreSQL(需插件)、DynamoDB),这些数据库能快速计算 “向量距离”,比传统数据库效率高得多。
检索技术:精准找到 “相关资料”
当你提出问题时,AI 会做四件事:
1)把你的问题也变成向量;
2)用“多路检索” 找信息:一方面做关键词匹配(直接找含 “价格”“售后” 等关键词的片段),另一方面做语义匹配(理解 “问成本” 和 “问价格” 是一个意思),再把两种结果融合,既精准又不遗漏;
3)重排序(Rerank):让 AI 给找到的片段打分,挑出最相关的几个(比如 Top5),避免把无关信息混进来;
4)结构化查询(Text2SQL):如果答案在数据库里(比如 “销售部 Q3 销售额是多少”“上个月新注册用户数”),AI 会把自然语言自动转成 SQL 查询,理解查询的表格、时间范围(比如 “Q3”)和计算方式(求和、计数),直接从数据库提取精准数据。
增强 + 生成:让 AI “有据可依” 地回答
把 “你的问题 + 最相关的片段” 一起交给大模型,AI 不会再凭空编造,而是基于这些真实资料,用自然语言整理出答案,还能告诉你答案来自哪份资料的哪个部分,方便验证。 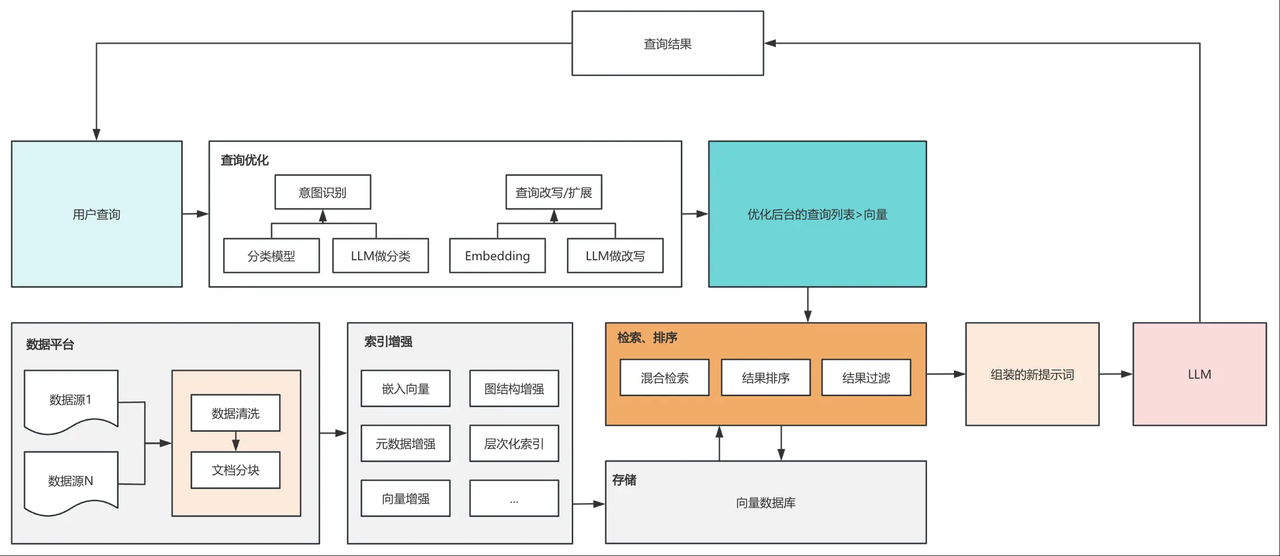
Graph RAG:搭建 “关系网” 的核心流程
Graph RAG 的关键是先建 “知识图谱”,再做检索,流程比传统 RAG 多了 “图谱搭建” 一步:
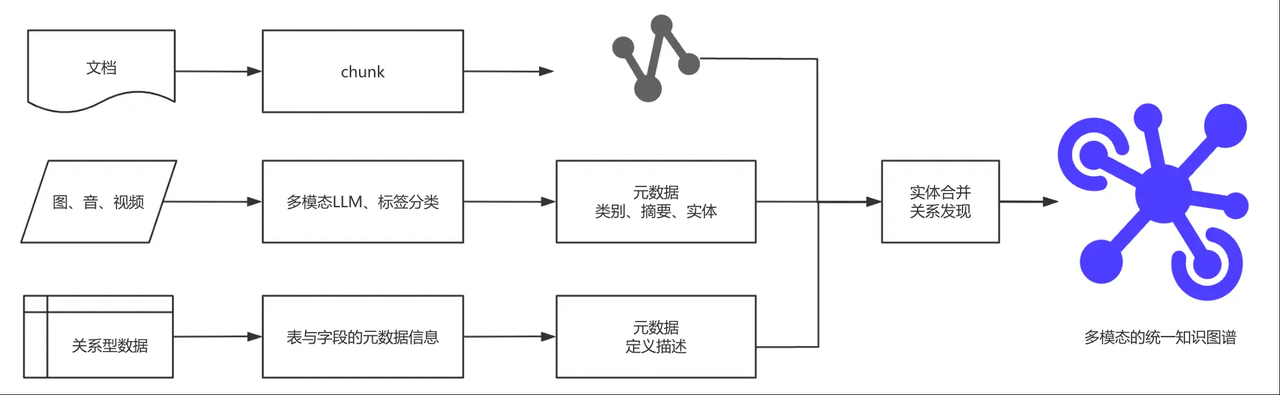
知识图谱搭建:给信息 “牵线搭桥”
第一步:梳理数据源,比如工厂的设备维修报告、生产日志、工艺文件、音视频元数据、关系型数据库表等,覆盖所有可能的信息来源;
第二步:定义 “节点”(实体)和 “连线”(关系)。比如工厂场景里,“人(张三)、设备(M001)、物料(P2025 批次)、工序(A 工序)” 是节点,“张三 – 操作 – M001 设备”“M001 设备 – 生产 – P2025 批次” 是关系;
第三步:自动提取关系。让大模型从海量文档中找出 “实体 + 关系” 的三元组(比如从 “技术员张三更换了 M001 号冲压机的轴承” 中,提取出 “张三 – 执行 – 更换操作”“M001 冲压机 – 被更换 – 轴承”),不用人工逐条处理,降低搭建门槛;
第四步:存入图数据库。图数据库是 Graph RAG 的核心载体,传统数据库(比如 MySQL)擅长存规整数据,但处理 “关系查询” 很慢,而图数据库天生为 “关系” 而生,查询速度能达到秒级。
- Neo4j:社区完善、资料丰富,适合入门和中小型项目;
- NebulaGraph(星云图):国产分布式数据库,性能强,适合超大规模图数据;
- TigerGraph:企业级高性能数据库,适合复杂业务场景。
Graph RAG 的检索与生成
当你问 “A 工序异常为什么影响 F 工序质量” 时,AI 会:
- 从问题中识别核心节点(A 工序、F 工序)和意图(查询因果关系,含 12 小时时间限制);
- 在图数据库中顺着关系网做 “多跳推理”,找到完整路径(A 工序 – 生产 – 物料 – 中转 12 小时 – 被用于 – F 工序);
- 把这条路径及相关信息(比如物料的核心指标异常、操作员工信息)整理成 “情境子图”;
- 把子图 “序列化”(翻译成 AI 能看懂的文本),比如 “核心路径:工序 A 生产了物料批次P20250817,该物料中转 12 小时后被用于工序 F;相关属性:物料 P20250817 的核心指标 X=5.8(标准 < 5.0)”;
- 交给大模型生成带逻辑链的答案,比如 “A 工序设备参数波动导致物料指标偏高,中转 12 小时后被 F 工序领用,最终引发质量问题”。
Agentic RAG:自主解决问题的动态流程
Agentic RAG 的工作不是固定步骤,而是一个 “感知 – 思考 – 行动 – 学习” 的循环:
- 理解需求:读懂你的核心诉求,比如 “规划家庭欧洲游” 需要兼顾老人孩子、控制预算;
- 拆解任务:把复杂问题拆成小任务,比如 “选适合的城市、查交通、订酒店、算预算”;
- 动态检索:针对每个小任务选最合适的方式找信息,比如查景点是否适合推婴儿车、对比酒店价格;
- 调用工具:用外部工具核实信息,比如用地图查路线、用预订平台看实时房源、用汇率工具算预算;
- 整合验证:把所有信息汇总,检查关键信息(比如签证要求、景点开放时间)是否准确;
- 生成答案 + 学习:给出最终方案(比如详细行程表),还会记住你的反馈(比如 “某个景点人多”),下次优化。
三种 RAG 的核心对比

传统 RAG 与 Graph RAG 的混合使用策略
两种 RAG 不是 “非此即彼”,混合使用能兼顾效率和深度,主流有两种策略:
策略一:串联(广度初筛→深度挖掘)
适合线索隐藏在大量文本中的复杂问题(类似于深度挖掘分析的问题):
- 向量检索:先用传统 RAG 快速从文本中,召回一批最相关的文档(比如 5 篇历史瑕疵报告),相当于找到最大片相关的内容;
- 实体链接:从这些文档中自动提取核心实体词;
- 图谱挖掘:把这些实体词作为 “线索”,用 Graph RAG 在知识图谱中深度挖掘,找到跨文档的关联路径,并将内容进行串联;
- 综合生成:结合原始文本证据和关系链条,生成既有细节又有逻辑的报告。
策略二:并联(双专家会诊)
适合需要同时获取 “事实信息” 和 “关系逻辑” 的问题(比如 “M001 设备的安全操作规程是什么,它生产的物料曾引发哪些质量问题”),更适合于整理分析的问题:
- 同步执行:用户提问后,同时发给传统 RAG 和 Graph RAG;
- 各自返回结果:传统 RAG 返回 “安全操作规程” 的文本片段,Graph RAG 返回 “设备 M001 – 生产 – 物料 P2025 – 关联 – 瑕疵 Z” 的情境子图;
- 结果融合:用 AI 判断两份结果的相关性和重要性,比如 “操作规程是核心事实,质量问题是关联逻辑”,将两者有机整合;
- 最终生成:给出既包含具体操作步骤,又说明潜在风险的完整答案。
使用 RAG 必须注意的 6 个关键点
知识库建设:按 “金字塔梯度” 筛选优质资产
知识库不是 “越多越好”,要按 “知识资产金字塔” 筛选,避免无用信息干扰:
- 核心资产:公司最核心的知识(比如咨询公司的核心方法论、工厂的核心工艺),要求回答准确、全面、权威;
- 独家资产:公司专属规则(比如规章制度、绩效标准),即使和通用知识重合,也必须以公司规则为准;
- 普通资产:和通用知识差异不大的内容(比如 “地球是圆的”),建议删除,避免混淆;
- 不良资产:自相矛盾、过时、无用的信息(比如旧版产品参数、失效政策),必须彻底剥离。
同时要避开 6 大误区:
- 专业术语晦涩:不对术语做解释,AI 和用户都无法理解;
- 信息提取困难:文献复杂导致 AI 抓不到核心要点;
- 内容自相矛盾:不同来源的信息冲突,AI无法抉择;
- 过时内容未清理;
- 无关信息冗余;
- 与世界知识冲突:私有知识库和通用知识说法不一(比如公司内部 “绩效” 定义和通用定义不同),导致 AI 回答不稳定。
局限规避:7 个具体风险场景及应对
RAG 不是万能的,要提前规避以下局限:
- 局限 1:知识库无答案时 “胡编乱造”→ 应对:设置 “无相关信息” 判断机制,让 AI 直接回复 “暂无相关答案”,不强行生成;
- 局限 2:正确答案因排名低被 “错杀”→ 应对:优化重排序算法,扩大初始召回范围(比如从 Top5 改为 Top10),再二次筛选;
- 局限 3:信息 “拼接” 不当导致逻辑断裂→ 应对:优先用语义切分或 LLM 切分,避免拆分完整语义;
- 局限 4:正确答案被 “噪声” 淹没→ 应对:按金字塔梯度清理知识库,移除冗余信息;
- 局限 5:未按要求输出特定格式→ 应对:在提示词中明确格式要求(比如 “用表格展示”),设置格式校验;
- 局限 6:回答精确度不达预期→ 应对:针对不同问题类型设置精度模板(比如事实查询要简洁,根因分析要详细);
- 局限 7:答案不完整→ 应对:检索时覆盖多维度信息(比如跨文档、跨数据源),设置 “关键信息缺失” 提醒。
落地决策:按四步框架判断是否引入
第一步:诊断业务痛点(满足 3 个以上可引入)
- 用户经常反馈 “AI 回答不准确” 吗?
- 有大量重复提问的问题吗?
- 用户需要查阅大量资料才能回答吗?
- 客服或员工经常说 “这个信息我不确定” 吗?
- 企业有大量知识沉淀但没被充分利用吗?
- 用户需要的答案是有 “标准答案” 的吗?
第二步:明确期望与约束
- 期望:要解决的具体问题(比如 “降低客服成本”)、成功标准(准确率 80% 以上、响应速度 < 500ms)、投资回报周期(比如 6 个月);
- 约束:技术团队能力、是否有现成大模型服务、知识库质量、预算限制。
第三步:小范围试点(降低风险)
- 选小而独立的业务(比如 “售后 FAQ 自动回复” 而非 “全部客服问题”);
- 定义成功指标(AI 回答准确率、用户满意度、成本消耗);
- 设定 3 个月试点周期,每月评估进展,可随时调整。
第四步:迭代优化(逐步扩大范围)
- Month1-3:售后 FAQ(10% 流量);
- Month4-6:扩展到产品咨询(50% 流量);
- Month7-9:全量 FAQ 自动回复 + 人工质量监督;
- Month10+:考虑扩展到其他业务(比如根因分析、数据查询)。
测试避坑:三大核心注意点
第一坑:测试集覆盖度不足
- 内容覆盖:按用户真实情境分类(比如 “面试准备” 按 “HR 视角”“候选人视角”),而非知识库分类;
- 形式覆盖:包含事实查询、寻求建议、问题解决、评估分析等不同问法;
- 表达习惯覆盖:纳入倒装、简略等不同表达方式(比如 “退货怎么操作” 和 “怎么操作退货”)。
第二坑:衡量维度模糊
- 准确性:分三类标准 ——“必须正确”(踩分点,比如 “退货需 7 天内申请”)、“绝对错误”(比如 “退货需 30 天内申请”)、“模糊地带”(可容忍的小偏差);
- 相关性:明确标准(比如 “超过 30% 内容无关即判定为不合格”);
- 充分性:避免 AI 回答过于冗长,设置 “核心信息不遗漏” 的判断标准。
第三坑:忽略关键指标
- 一致性:同一问题多次提问,答案需相对一致(比如 “退货流程” 不能每次回答都不一样);
- 上下文记忆:多轮对话时,AI 需记住前文内容(比如用户先问 “退货流程”,再问 “退货地址”,AI 不能忘记 “退货” 主题)。
技术选型:按场景选工具
- 向量数据库:中小型项目选 Neo4j,超大规模选 NebulaGraph,企业级复杂场景选 TigerGraph;
- 切分方式:简单场景用固定大小切分,专业场景用语义切分或 LLM 切分;
- 混合策略:复杂问题用串联策略,需要同时获取事实和关系用并联策略。
长期优化:建立反馈机制
- 用户反馈:允许用户给答案打分(“准确”“不准确”),标注错误点;
- 自动学习:把用户反馈的正确信息补充到知识库,优化检索算法和切分策略;
- 全流程监控:监控检索准确率、生成质量、响应速度,定期校准。
RAG真实应用案例
企业客服系统(传统 RAG)
场景:电商平台每天收到数万个重复问题(比如 “怎么退货”“发货要多久”),传统客服手册太厚,新员工上手慢;
用 RAG 后的变化:AI 自动从售后政策文档中检索相关片段,生成统一、准确的回答,90% 的常见问题能自动处理,人工客服只负责复杂问题;
工厂质检根因分析(Graph RAG)
场景:一线质检员发现成品有瑕疵,需要跨多个系统(生产系统、设备维修记录、物料台账)找原因,过去要花半天甚至一天;
用 Graph RAG 后的变化:AI 通过知识图谱找到 “设备参数异常 – 物料指标偏高 – 工序领用 – 瑕疵产生” 的完整链条,几分钟内给出根因报告;
智能旅游规划(Agentic RAG)
场景:用户想规划 “3 天亲子游,预算 5000 元,兼顾自然景观和亲子项目”,需要查景点、交通、酒店、门票,过程繁琐;
用 Agentic RAG 后的变化:AI 自主拆解任务,查适合孩子的景点、对比高性价比酒店、核实门票预约政策,生成带每日安排、预算明细的行程,还能根据用户反馈调整;
教育智能答疑(传统 RAG)
场景:学生问物理题 “浮力公式怎么应用”,传统 AI 可能答非所问;
用 RAG 后的变化:AI 从教学文档、同类例题中检索相关内容,生成解题步骤,还标注答案来自教材哪一章节、哪道例题;
效果:答案准确率大幅提升,学生能追溯知识点,学习体验更好。
总结
RAG 的核心价值,是让 AI 从 “瞎编乱造” 变成 “有据可依”。而 Graph RAG 和 Agentic RAG 则是在这个基础上,让 AI 从 “找信息” 升级到 “懂逻辑”“会思考”。
选择哪种 RAG、是否混合使用,关键看你的业务需求:简单查询用传统 RAG,复杂关系分析用 Graph RAG,复杂任务规划用 Agentic RAG。
落地 RAG 的关键不在于 “技术多先进”,而在于 “是否匹配业务场景”—— 先按四步决策框架判断需求,用小范围试点验证效果,再按金字塔梯度建设知识库,避开测试和局限的坑,就能让 RAG 在客服、工厂、教育、金融等多个领域发挥巨大价值,既提升效率,又降低成本,真正让 AI 服务于实际业务。
本文由 @一葉 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









Agentic RAG和Agent有啥区别?
你可以理解成普通的agent rag是给了模型一本书和笔记,它可以通过传统的rag以及graph rag翻书翻笔记找到知识,而agentic rag的不同点是它可以自主规划→检索→评估→反思→迭代(二次检索),虽然都是通过智能体调用工具,但是一个是只会一个用法,一个会改变方法,区别还挺大的
agent的核心是检索生成,agentic的核心是agent的规划→执行→改变的过程
文章很好,对我帮助很大,读了一半都想收藏了,没想到收藏图标在下面。