
 起点课堂会员权益
起点课堂会员权益一文讲清楚Token
Token是大模型处理信息的核心单元,但你真的了解它吗?本文用小白也能听懂的语言,拆解Token从编码、解码到实际应用的完整流程,揭秘中英文Token换算差异的底层逻辑,更附赠Prompt优化实战技巧。看完这篇,你将对大模型如何'思考'有全新认知。

本文是《一文讲清楚XX》AI相关名词系列文章的第一篇《一文讲清楚Token》,我会用通俗易懂的语言为小白用户讲明白晦涩难懂的技术术语,看完后只想拍大腿,惊呼,原来如此!
讲Token之前,我们先了解下大模型基本运行原理。
大模型的基本运行原理
大模型本质上是输入数字然后输出数字的过程,大模型根本不理解人类的信息。在这个输入和输出过程中,有一个Tokenizer主要负责编码和解码的过程。
编码简单来说是指将文字转化为数字的过程,解码反之是数字转化为文字的过程。
用户输入问题后,大模型会先将问题进行切分,切分为一个个的Token,每一个Token会有一个Token ID,Token和Token ID是一对一的关系。通过编码之后,原本的一句话就变成一串Token ID列表。这就是编码。
然后,进入解码过程,由Tokenizer再将Token ID 翻译成Token ,这个过程不需要切分,因为大模型本身就是一个个Token进行输出的过程。
最终,就拿到了大模型的挨个输出的Token。以上就是Tokenizer编码和解码的过程。这也就是简化版的大模型运行过程。
简单来说:大模型的输入是一个个Token,输出也是一个个Token。
那么,Tokenizer是怎么实现的呢?
Tokenizer的实现
Tokenize的训练过程,和大模型训练相比它并不复杂。
市面上有很多实现算法,比如Google使用Unigram算法,Open AI和authropic使用BPE。
以BPE算法为例,一听算法是不是有点慌,先不要着急,简单来说,BPE算法训练过程就是在一堆文章中找出经常在一起使用的字,然后把经常在一起使用的字作为一个Token的过程。
比如,现在有一份训练材料,将训练材料中的字拆分为一个个单字的Token的词表,每个Token有一个Token ID。
算法扫描整段训练材料,把经常在一起的字合并,作为一个字加入词表,生成这个字相对应Token和Token ID。同时生成一条合并规则,放入合并规则库。
同时,合并之后的词也可以继续合并加入词表和合并规则。
以上就是Tokenizer的训练过程,核心组件包括词表和合并规则。
Tokenizer的使用
Tokenize包含编码和解码两个过程。
其中,编码包括切分和映射,切分阶段,将用户问题切分为一个个单字,再将合并规则拿过来,看有没有能够使用的合并规则。
把一句完整的用户问题切分为Token,将Token转化为Token ID,这是映射的过程。
解码就是做映射,将模型吐出来的 Token ID映射为 Token。解码就到此结束了。
Token与字数的换算过程
所以,Tokenizer不仅是一个翻译机(字与Token),还是一个压缩机,Tokenizer会把经常在一起的字合并为一个Token,这也就是Token数量一般大于汉字或单词的原因,也因此模型的训练和推理效率也就更高。
一个粗略的换算
英文:一个Token约等于0.75个单词
中文:一个Token约等于1.2到2个汉字
这意味着,同样一段内容,中文的Token数量比英文要少,也就是为什么在计费时,中文有时候“便宜”一些。
40万个Context Window 大约等于60~80万个汉字或30万个英文单词
如何查看使用了多少Token
不同模型使用不同的Tokenizer(分词器),同一个问题使用Token不同。
查看Token使用方式很多。
对于小白用户,首选各种GUI工具,比如GPT系列模型,可以通过官网工具进行查看,platform.openai.com。或者第三方网站,https://tiktokenizer.vercel.app/。
也可安装开源浏览器插件比如Token Counter Plus,Prompt Token Counter等。
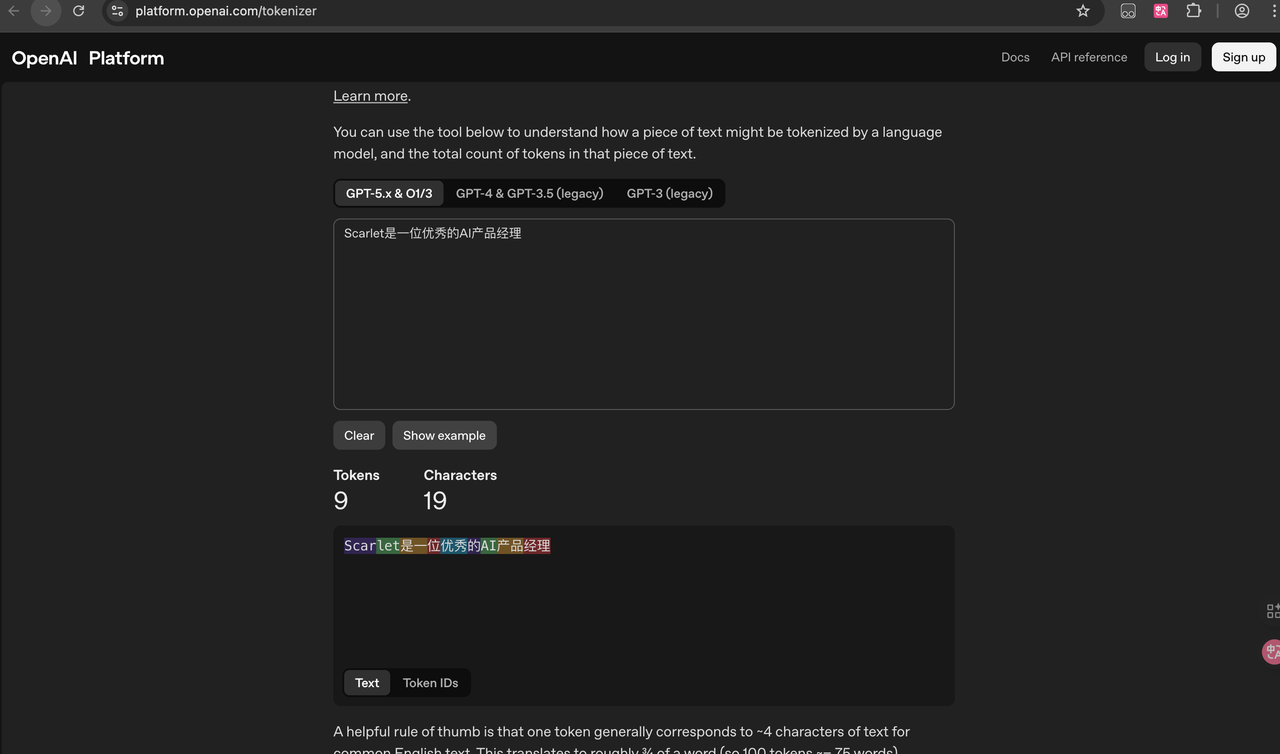
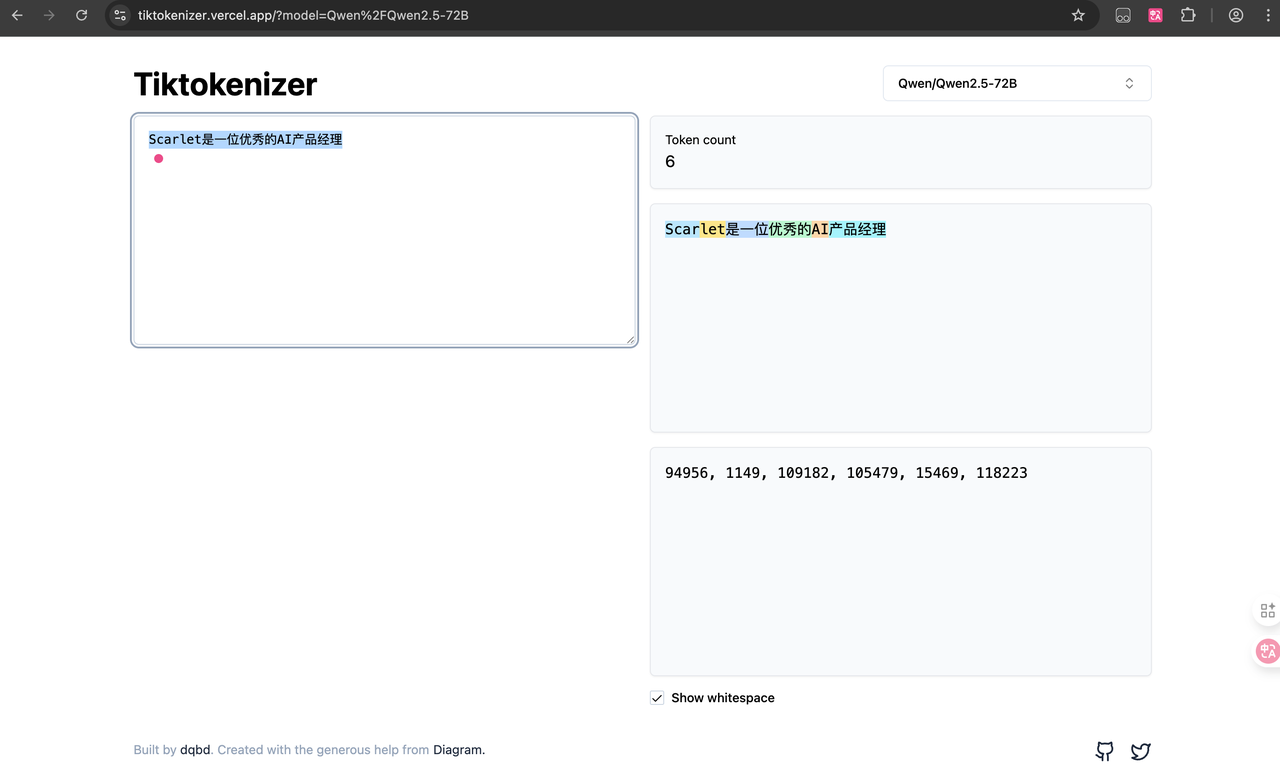
专业用户可以直接模型对应的库,比如使用OpenAI开源的tiktoken库。
对于Prompt的影响
原则:精打细算,每个Token都有成本,考虑用更少Token表达相同含义,避免Token浪费。
实践1:先说重点,再补充细节
原理:模型从前往后处理Token,重要信息靠前确保被“看到”。
实践2:复杂任务分步骤,比如复杂任务
原理:分步骤降低单次处理的认知难度
实践3:适当给例子
原理:1个好的示例≈100个描述性Token的效果。
本文由 @未来可期 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


