
 起点课堂会员权益
起点课堂会员权益全域数据产品中,数据产品经理如何用AI低成本构建可定制的用户智能标签工作流?
在数据驱动的时代,如何高效构建用户智能标签成为产品经理关注的焦点。本文揭秘了一套融合AI技术的定制化标签工作流,从样本标记、规则构建到落地策略,层层拆解如何用大模型交叉验证解决无真值难题,将经验知识转化为可执行规则,最终实现标签体系的自动化部署。这套已在生产环境验证的解决方案,为复杂场景下的用户画像提供了全新思路。

最近负责全域数据产品。为了应对客户定制化需求,我们自建了一套相对完整的可定制化用户智能标签工作流程。这里分享出来,供大家参考。
AI辅助用户画像智能打标签,前期我们主要研究了两种产品方案:
- 传统流程 + AI辅助:在样本标记、特征规则构建、决策模型三个环节,用AI进行辅助。
- 结构化数据转上下文 + 蒸馏小模型:将标签生成完全托管给AI。
目前方案1已投入生产,方案2还在验证。这次先讲方案1。
一、样本标记:用AI交叉验证解决“无真值”难题
我们的标签基于已有的基础数据构建(应用数据、位置数据、设备数据)。但这些数据只能形成用户特征集,没法直接知道“这个用户到底是不是白领”——也就是没有准确的标注样本。
大多数用户画像产品都会遇到同样的困境:无法做准确度验证。我们的产品设计思路是:让AI帮我们做交叉样本标注。
具体做法很轻量:把用户数据整理成一段自然语言描述,扔给大模型,让它推测是否命中某个标签,并给出置信度。
举例:判断一个用户是不是“白领”。我们拼出一段描述:
“一个用户装了钉钉,每天高频打开;还装了腾讯会议;工作日每天9-18点在某某写字楼活动,晚上住在某某社区;使用华为Mate60手机……”
大模型读完这段描述,给出结论:“是白领,置信度0.92”。
我们用三个不同的大模型交叉验证,三个都认为是,就把它纳入正样本。
流程参考下图(给用户打身份标签):
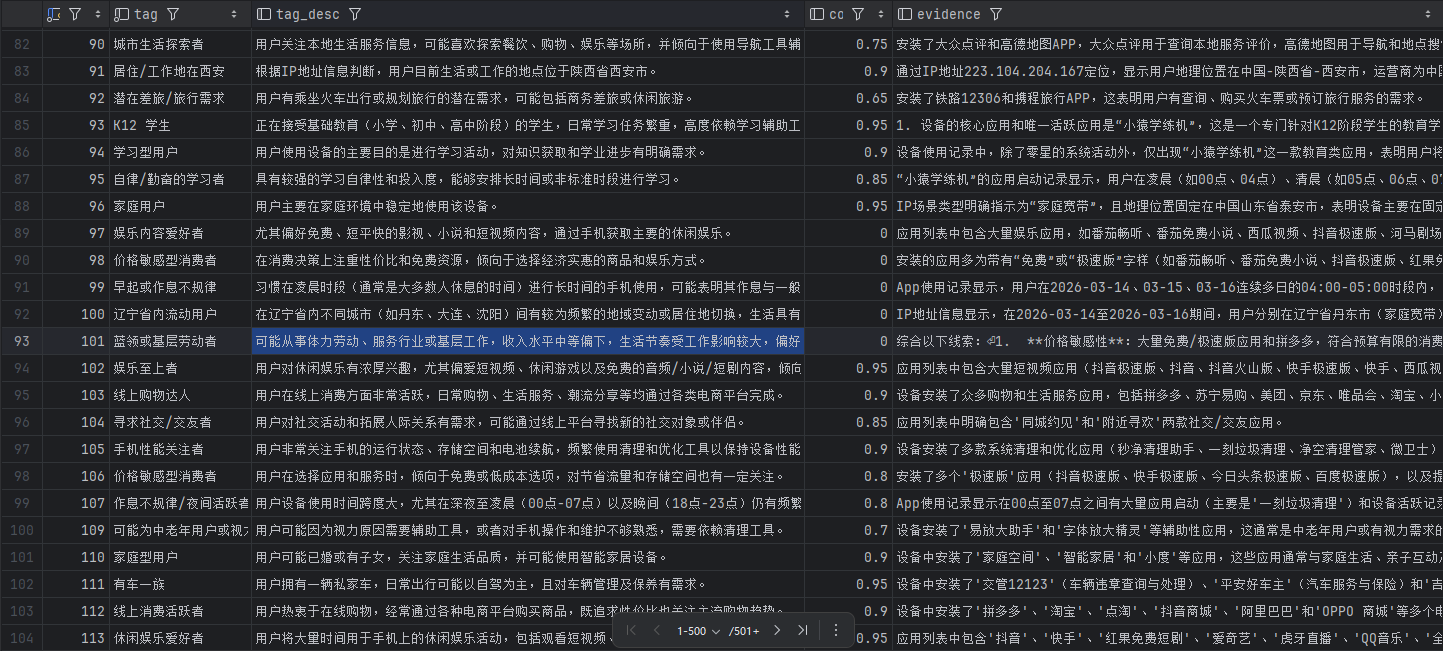
这里也可以引入人工质检,但实际发现:人工标注也是基于同样有限的信息做主观判断,并不比AI更准。所以直接采用了多模型交叉验证。
产品价值:低成本、可复现地解决标签样本标注问题,无需依赖外部真实标签。
二、特征规则构建:让AI把“经验”翻译成“可执行的规则”
第一轮我们把数据变成了自然语言描述让AI判断。
这一轮,我们反过来让AI把“判断依据”提取出来,形成结构化的标签规则。
参考下图:
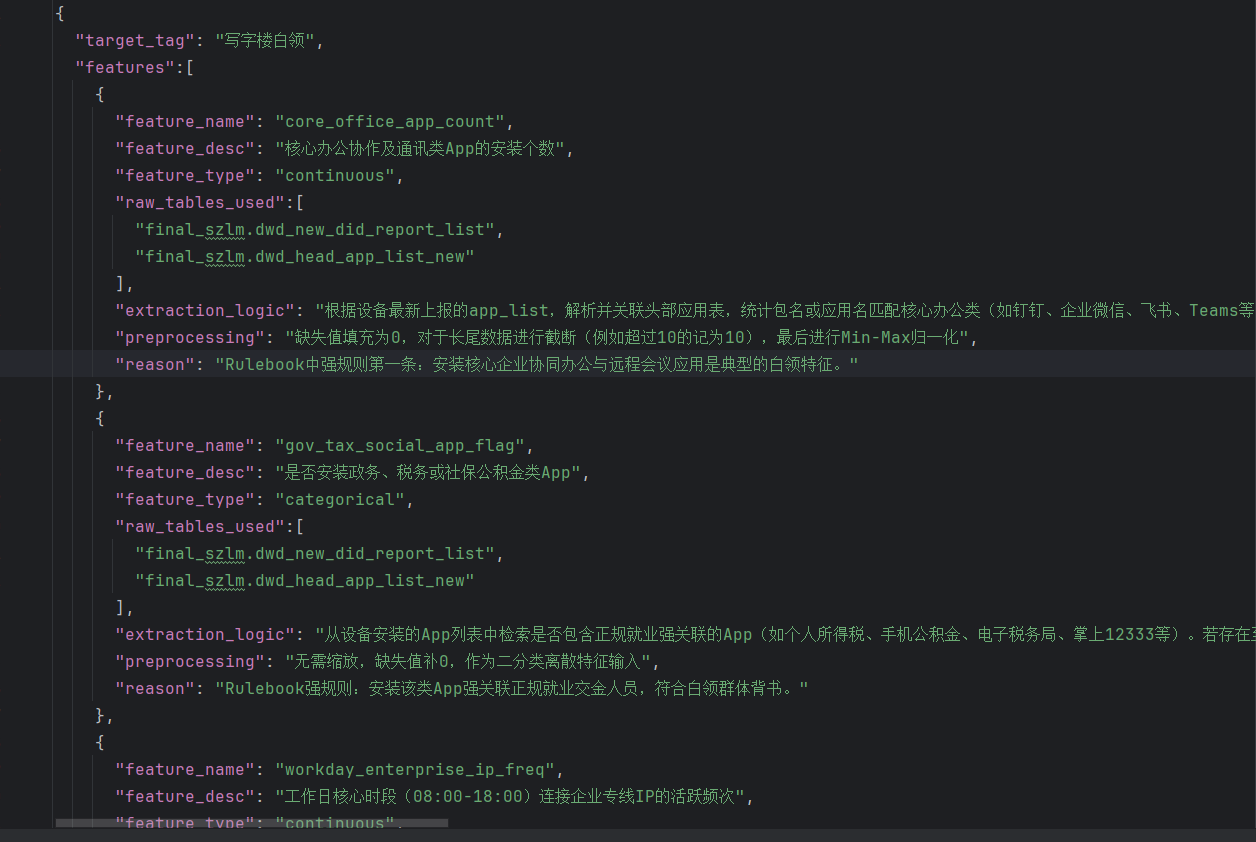
还是“白领”这个例子。AI会把之前的判断依据拆解成一条条具体规则,比如:
- 打开办公类APP频次 > 3次/天
- 工作日常驻地为写字楼
- 夜间常驻地为住宅社区
- 设备型号为旗舰机型
这些规则可以直接用于后续的自动化打标或模型训练。
产品价值:将大模型的经验类知识沉淀为可解释、可维护的业务规则,产品经理也能看懂和调整。
三、标签落地策略:三类标签分而治之
从产品角度,我们把标签分为三类,分别采用不同策略:
- 基础标签(如性别、年龄段):直接从已有数据映射,不做特殊处理。
- 统计标签(如“周活跃天数≥5天”):上面的规则直接写成判断逻辑,实时或离线打标,不需要模型。
- 模型标签(如“白领”、“高消费敏感型”):适合用机器学习模型来做,准确度最高。
对于模型标签,我们引入了一个自动化建模工具(Optuna),它能够自动拆分样本/测试集、选择算法、调参、对比效果,最终输出可直接部署的模型。
这样一来,产品经理只需要定义好“我需要哪些模型标签以及样本规则”,剩下的建模工作可以高度自动化完成。
产品价值:降低算法人力依赖,提升标签迭代效率。
完整流程回顾
如果我们信任大模型的样本标注能力,那么整个流程甚至可以简化为:
输入一个标签想法(比如“夜猫子用户”) → 自动生成描述模板 → 多模型交叉标注样本 → 提取特征规则 → 自动化建模 → 输出标签模型
我们对比过一些公开的用户画像数据集,这个方案的效果很理想。
至于方案2(完全托管AI生成标签),逻辑上更灵活,但还在验证中。等落地后再分享。
本文由 @Jo斯达 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


