
 起点课堂会员权益
起点课堂会员权益确认!DeepSeek多模态AI已经开测
DeepSeek V4的视觉功能灰度测试引爆期待!这款多模态模型不仅突破传统OCR限制,更能精准识别真实图像中的物体细节。由北大博士领衔的团队打造的视觉语言模型,正在为AI交互开启全新维度。从饮品识别到场景理解,我们即将见证国产大模型的又一次飞跃。
DeepSeek的视觉功能,真的来了!!
DeepSeek研究员陈小康发帖放出一条消息——
Now, we see you.
随后,另一位研究员陈德里也跟了一条,确认V4视觉模式已经开始灰度测试。
怎么说,小鲸鱼的多模态拼图,要补齐了。
已经具备真实图像理解能力
之前上传图片,模型只能识别图片中的文字,做做OCR工作。
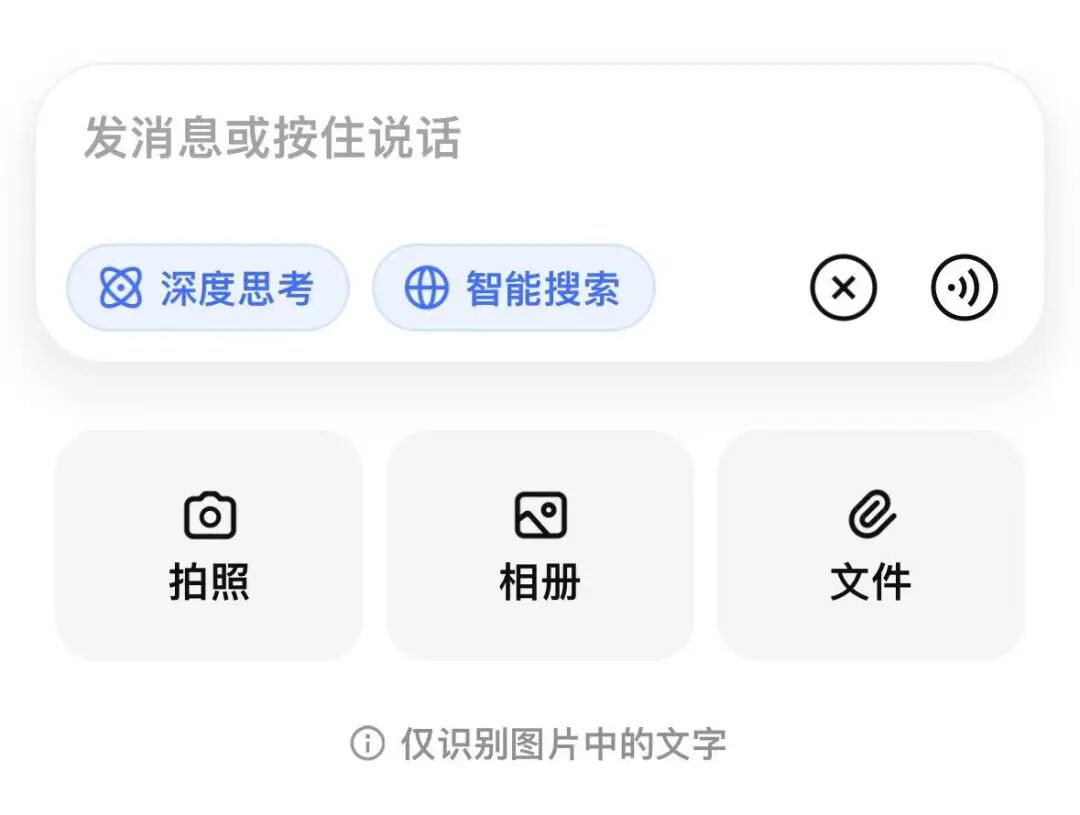
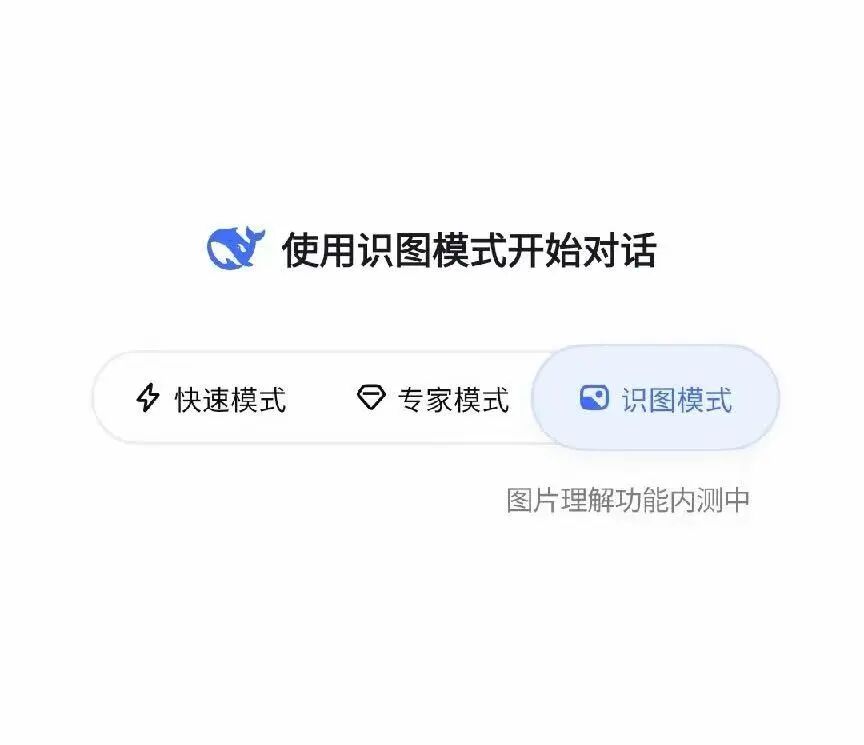
今天一个小更新之后,被灰度到的幸运鹅首页已经出现了识图模式,下面还有一行小字表示图片理解能力内测中。
从幸运鹅分享的截图来看,DeepSeek视觉测试版已经具备真实图像理解能力,识别出了图片里的饮品、杯型等信息,思考4秒输出了完整的描述。
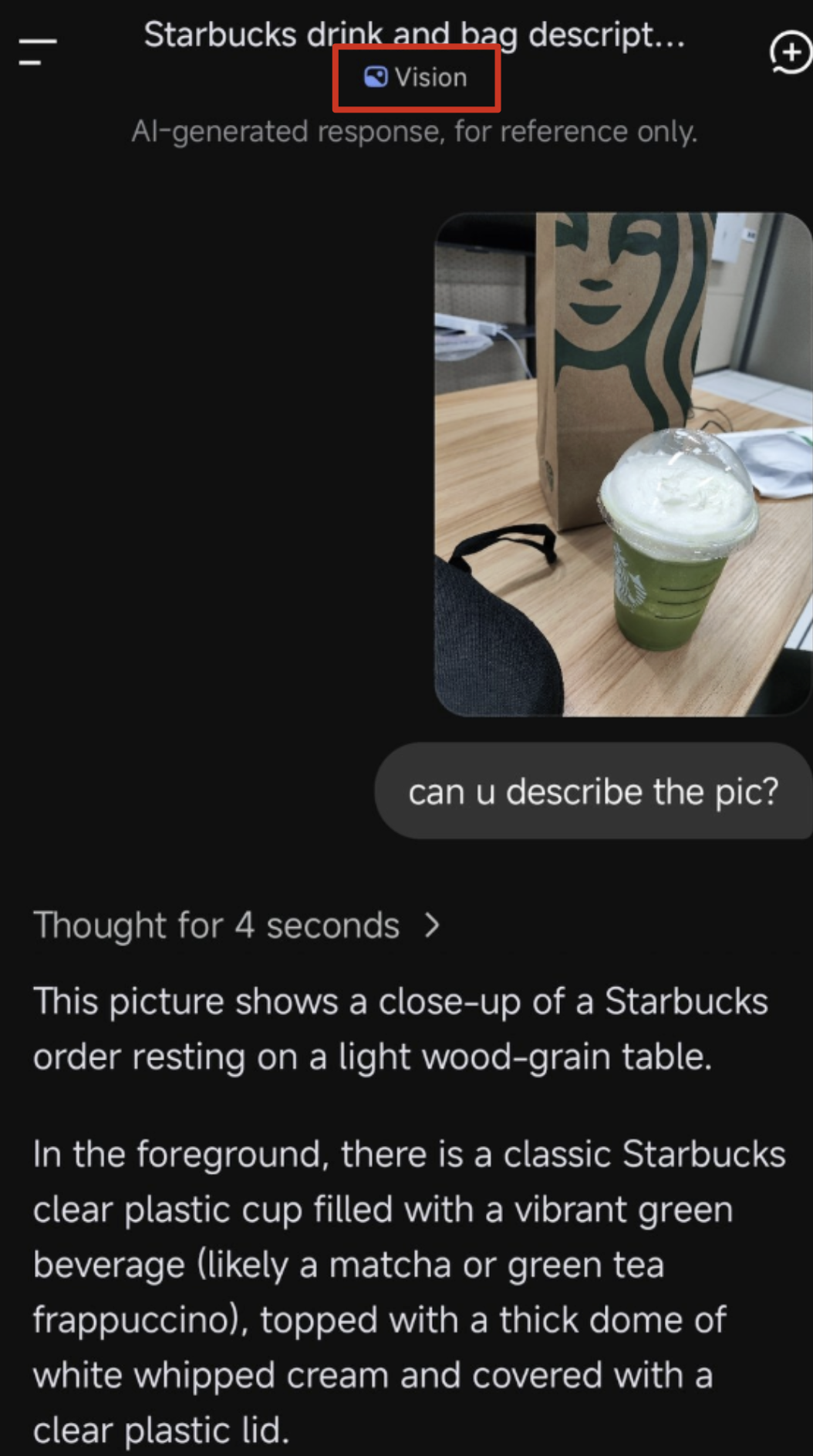
这是一张没有明显文字的图,明显与之前仅识别文字的模式不一样了。
V4,满血归来
放出消息的两位研究员,其中一位是陈小康,DeepSee多模态研究组负责人,北大博士毕业。
他是DeepSeek两个重磅多模态项目的核心作者:Janus系列统一多模态理解与生成模型;DeepSeek-VL2基于MoE架构的视觉语言模型。

简单说,DeepSeek的视觉能力,就是他带队搞出来的。
另一位陈德里主要负责语言模型、对齐机制、训练策略及模型泛化能力等核心方向。
在过去两年的时间里,DeepSeek发布的多项重要研究成果,无论是V2、V3还是R1,几乎都能看到他的名字,这次的V4也不例外。
价格打骨折之后,视觉功能又来了,请问还有什么惊喜是我们不知道的!!!
不得不说,DeepSeek V4,这次是真满血归来了。
参考链接:
[1]https://x.com/victor207755822
[2]https://x.com/PKUCXK/status/2049381471669080209
闻乐 发自 凹非寺量子位 | 公众号 QbitAI
本文由人人都是产品经理作者【量子位】,微信公众号:【量子位】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Deepseek官网截图






- 目前还没评论,等你发挥!


