
 起点课堂会员权益
起点课堂会员权益我把13个顶级AI送去数学高考,并列第一居然是它们。。。
当13款顶尖AI模型集体挑战2026高考数学全国一卷,结果远超预期却又充满戏剧性。从Claude Opus到GPT 5.5,这些学霸级AI在多模态理解、LaTeX输入稳定性与复杂题型处理上展现出惊人实力,却在多选题陷阱和长解答题细节上频频翻车。本文深度还原这场人机对决的每一个精彩瞬间,揭示AI解题的真实边界与突破。

又到了一年一度的高考,
先祝考生们考的都对!这种时候就适合来考AI,一开始我觉得要是全员满分的话,那我这标题应该直接是AI已经攻略高考了才对,没想到还是有被拉开差距。
先来看看试卷,今年的全国一卷难度高到考完就逐梦大专。
那还说啥了,直接上做题规则,
这次参加考试的有13个模型,Claude Opus 4.8 Max, Claude Sonnet 4.6 Thinking, GPT 5.5 Thinking, Gemini 3.1 Pro Thinking, Qwen 3.7 Plus Thinking, MiniMax M3, Kimi 2.6 Thinking, Mimo-2.5-pro, Deepseek-v4 Pro, GLM 5.1, Grok, 豆包 Thinking, 元宝Thinking(一口气全念对要很好的肺活量)
为了公平性,我采用了同一张卷子,2026数学全国一卷,

记分方法就跟高考判分的保持一致,不管是网页版还是API都关掉联网,
跟去年最大的不同,今年大部分的模型上下文都翻了一番,基本都支持多模态了,所以第15题图像题照样保留。
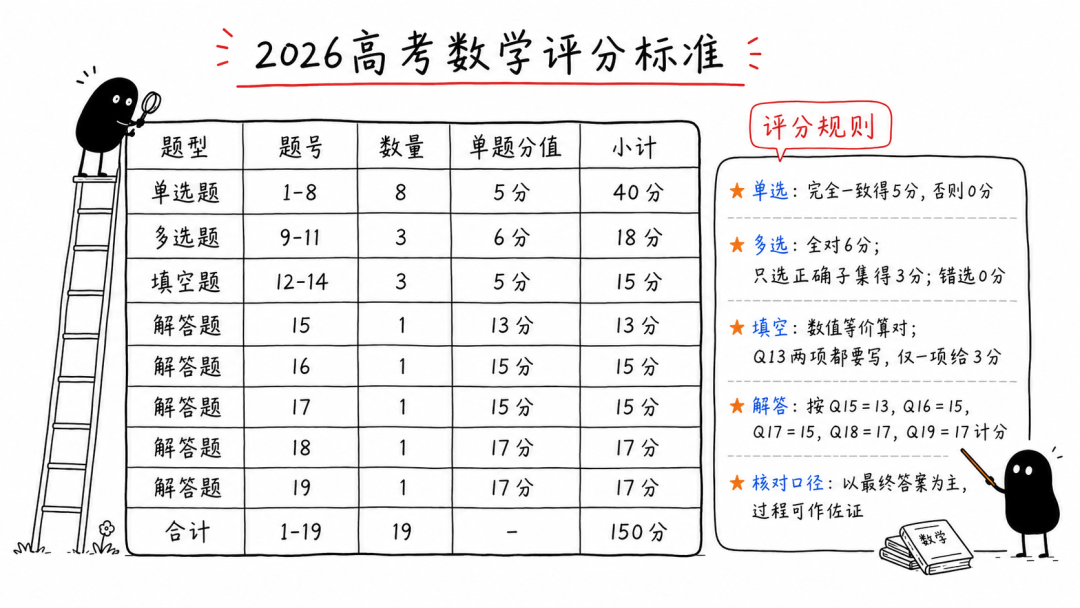
同时因为读取PDF会比读取markdown化的考卷要更耗额度,我的两个Claude都没考完额度就没了,所以我们统一用mathpix把PDF转成了LaTeX格式,每一道转化的题都会单独人工再看两次。
LaTeX的好处就是能保证每家模型都可以读取到一样的信息,

每个模型都会在一个新对话里收到一个提示语,中间我们不干涉不对话如果失败直接新对话重新跑。
# 测试提示语
请使用你当前可用的最高推理能力,像一名中国高考数学考生一样,在不联网、不查资料、不使用代码、不调用外部工具的情况下,独立完成下面这套高考数学试卷。
你的目标是尽最大努力获得尽可能高的分数。请按照高考数学答题标准作答,展示完整、清晰、可评分的解题过程。
作答规则:
1. 请按照题目顺序从第一题做到最后一题,不要跳题,不要中途停止。
2. 每道题都必须作答。即使不确定,也要给出你认为最合理的答案,并说明不确定点。
3. 选择题:请写出推理过程,并明确给出最终选项。
4. 填空题:请写出推理过程,并明确给出最终填空答案。
5. 解答题:请按照高考答题格式分步骤作答,必要时分小问回答。
6. 请完整展示关键步骤,包括公式选择、代数变形、计算过程、分类讨论、函数分析、几何推理和结论判断。
7. 不要编造题目没有给出的条件,不要跳过图形、表格或题干中的限制条件。
8. 每道题结束后,请进行简短检查,确认计算、符号、定义域、取值范围、单位和最终答案形式是否合理。
9. 最后请给出“整套试卷答案汇总”,只列每道题的最终答案,方便评分。
请严格使用以下输出格式:
第 1 题:解题过程:……检查:……最终答案:
第 2 题:解题过程:……检查:……最终答案:……
整套试卷答案汇总:1. 2. 3. ……
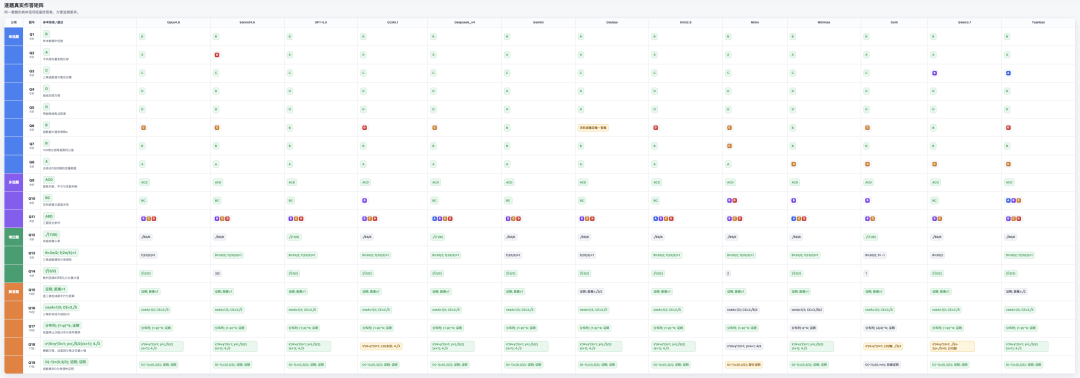
开考开考!收卷收卷!改卷改卷!最终得分表出炉!来看看模型们的精确选项。
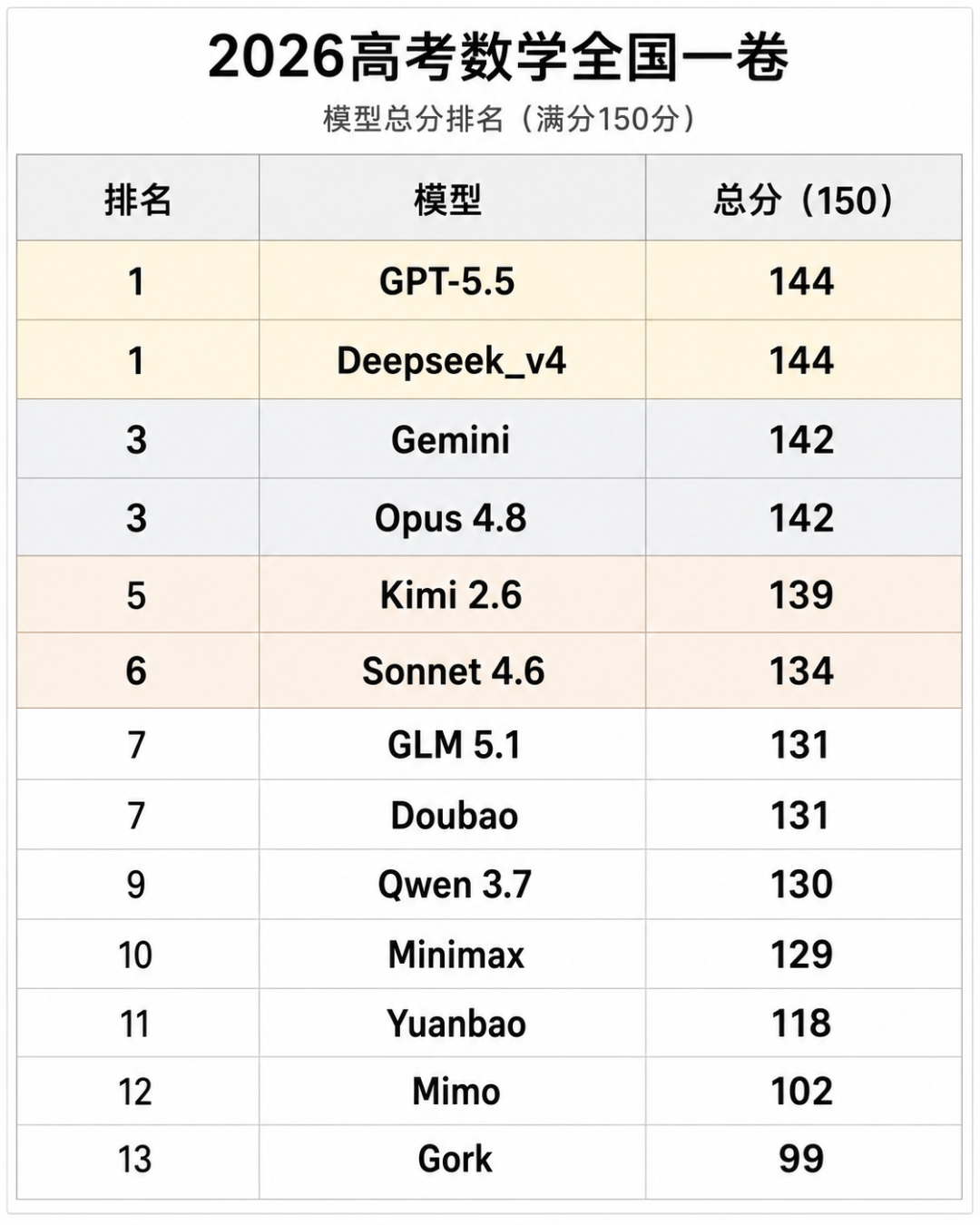
模型总体得分是这样的,
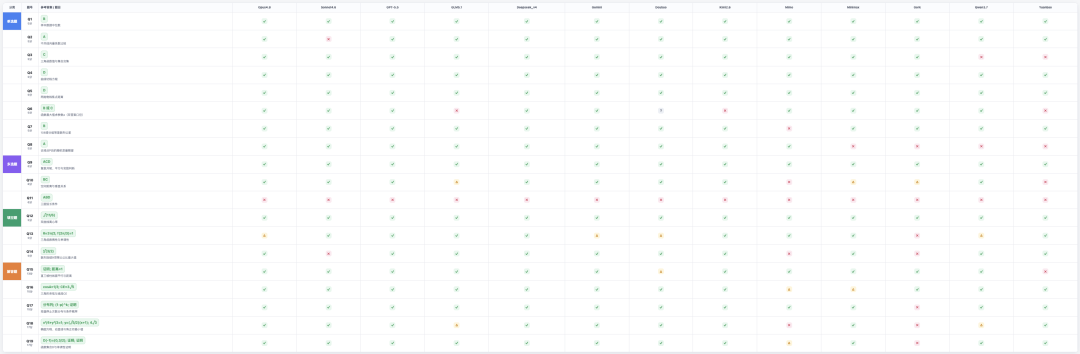
模型具体选项也是这样的,
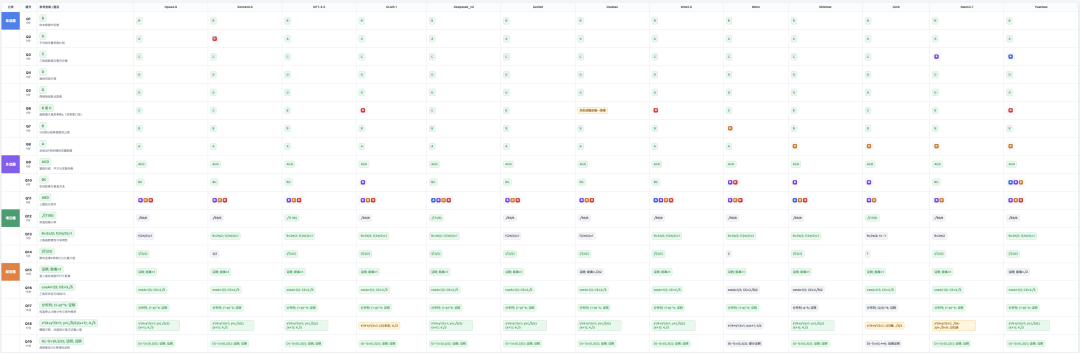
来看看最终分数吧!
马上来个真题复盘:
第6题是这套卷里最有节目效果的一题。
起初测试发现了一半左右的模型都错了,还以为是世纪难题。后来发现,问题出在输入环节。
网上存在不同版本的题目,在读取LaTeX 输入的过程中,也被识别错误。
所以有的模型就被这个错误输入成功带偏,通过自己的理解,自动fallback到了一个同题型下的正确答案。有些也有给出根据错误输入从而没有答案的正确回答。为了答题一致性,我们将有合理答案的都作为对的最终采纳。

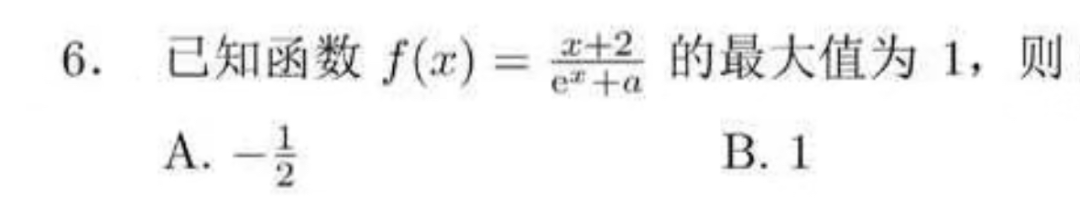
最终复核后的结果,
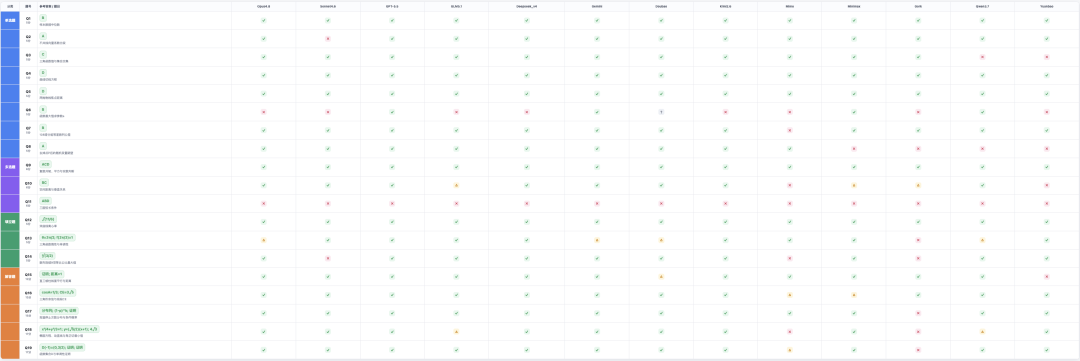
第11题是这套卷里最选择困难的一题。
并不是模型完全不会做的题,而是看着好像不难,就最后多一步非把自己送走的多选题。

答案是ABD,
但是所有模型居然没有一个完全答对,我看了一下,在过程里已经接近正确了,但为了保险过度泛化了,把诱导项也一起选上了。
用人话来说,
B选项要求三个弦长完全相等,这是一个强条件,最后只剩三条直线;C选项只要求三个弦长的和等于 3,这是一个弱条件,看起来会留下连续一族直线。
模型 ABD 的正确方向摸到了,但又把 C 这个“看起来也成立”的边界项塞了进去导致结果错误。
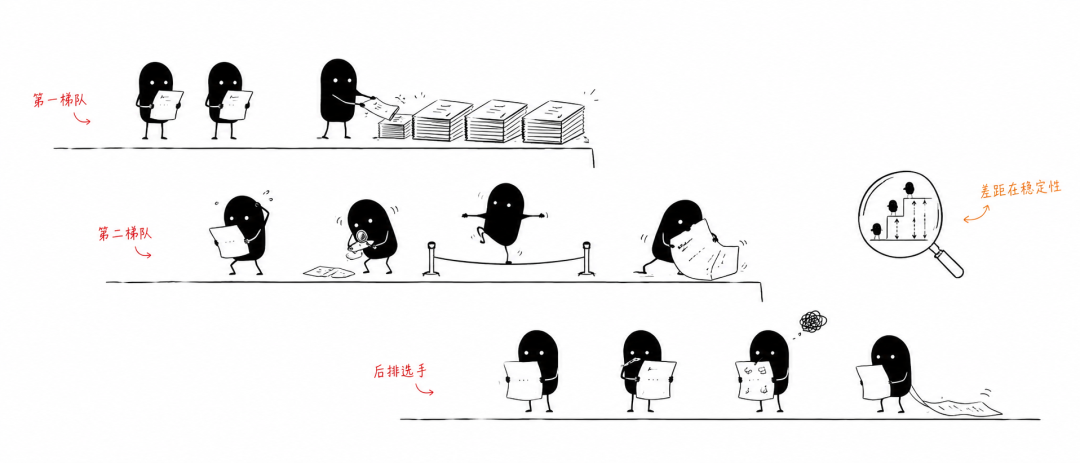
本来以为现在大模型的得分都那么高了,跑起来一定不会有什么问题吧,实际上过程非常磕磕绊绊。
首先就是上下文窗口以及记忆,
像Qwen和以下的梯队的模型,做到后面就开始漏条件,甚至反过来问我思路和想法,忽略前面说过的考场要求。甚至是没有理解题目规则。比如题目要求证明,它只给了结论。题目要求完整作答的,它也只写了思路。
然后就是API传输和输出限制,
Opus 4.8 开了最高权限导致思考的过程太慢。Context被截断,rate limited,或者一次回答装不下等等等等都发生过,导致最终超时了来不及写完或者只留下了一堆没有结果的草稿(Thinking memory)让我验收。
但但但但但!最离谱的还是考场离谱行为,Sonnet 4.6尝试直接搜答案还有Deepseek直接拒绝完成都是真实存在的,刚开始就想走人了。
根据每个模型的得分,我还给他们做了一个评级系统,

PS:叠个甲,纯娱乐分层,因为只有数学单科成绩
最终得分上,AI和AI之间的差距,也就是和我和清北之间的距离差不多嘛。
第一梯队 GPT 5.5, Deepseek-v4 Pro, Gemini 3.1 Pro 以及 Opus 4.8。强的不止会做难题,并且整体也是稳定的学霸,该拿的分都拿到了也没有特别的错误。
而只差些微分数的Kimi 2.6属于第二顶尖。不是能力不够,大题也能做出来,只是会在选择题、多选题或者填空完整度这种的小地方导致失分,才没进第一梯队。
第三梯队也是大多数,包含了 Sonnet 4.6,GLM 5.1,豆包,Qwen 3.7 Plus,以及MiniMax M3。也算是模型的平均线了,当前还没有那么稳,会在不同细节上丢分。不是不会,只是粗心,或者关键步骤没有收住。
元宝118,独树一档,能做不少题,在稳住了百分的情况下也会有明显失分。
Mimo 和 Grok 就是这次发现最需要进步的模型了,更像普通考场发挥。有思路,有想法,但也就一些基础分了。
批完卷子之后,
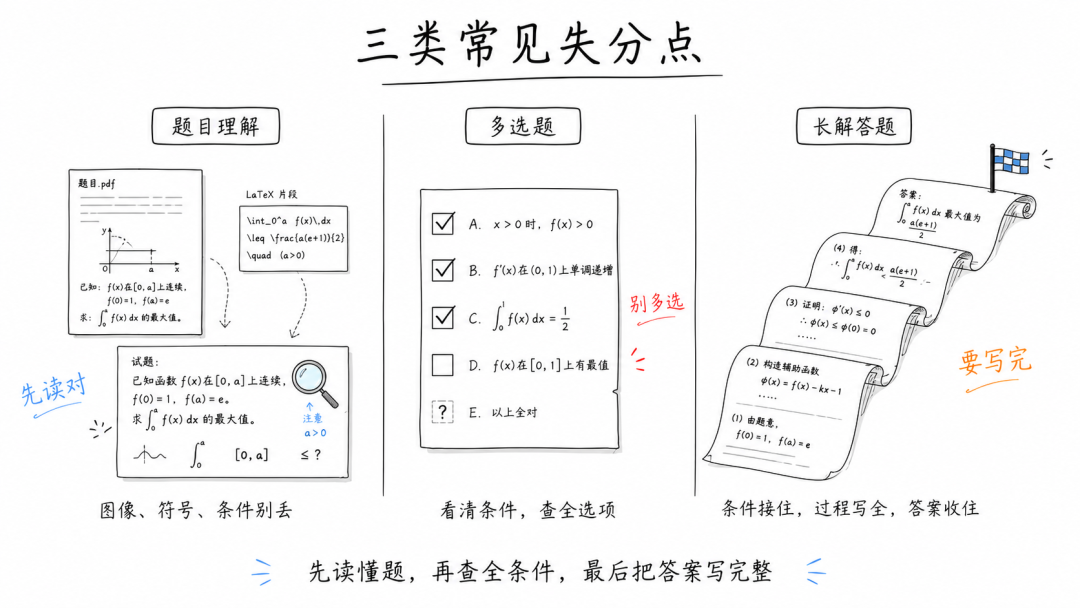
发现不是只有低分选手会翻车,就算是144分的清北种子模型也都会被多选题中的制定条件坑一把。
除了多选,长解答题是真正拉开差距的地方。
能不能读好完整条件,算好所有公式,条件步奏有没有记住,直到出最后的具体答案。
很多模型有思路,也能写方向,但在严格评分里就是拿不到分。
最后还有一个很关键的问题,就是题目理解。
很多时候模型一开始就没稳稳接住。
读题就读错了,图没看清楚,直接往反方向飞奔。
又或者从LaTeX里抽出来的时候符号、条件、上下标丢了一点,
后面再怎么推都推不对了。
所以这次测下来的感觉就是,AI确实很强,高考题能难倒它们的不多,有些模型已经不像是在做题,更像是老叟戏顽童。
但它们也不是完全不会翻车。
会看错图,会漏选项,会写到一半开始意会,也会在长题最后一步突然卡个十几分钟。
今年在高考期间都不让用AI了,我们在测试的过程中反复尝试了好多遍。
不过这个系列可能还是会一年一度做下去的。
这次高考数学题还是挺难的,让我限时马上去做估计也是够呛,
但还是可以带着AI跟大家一起考一份试卷,看下难度,还是很有意思的,希望明年AI考生的数量再多一点。
作者 / 卡尔 & yc星辰
本文由人人都是产品经理作者【卡尔的AI沃茨】,微信公众号:【卡尔的AI沃茨】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。








看到Deepseek拒绝完成那一段笑死了,AI也有脾气啊。
AI在数学推理上确实惊艳,但测试里暴露的输入容错问题才是实际落地的真正短板。一个LaTeX识别错误就让一半模型翻车,这种脆弱性在复杂业务场景里更致命。
看完全文,感觉AI做高考数学就像学霸考试,难题基本压不住,但多选题和长解答题才是真正分水岭,而且LaTeX输入一个小错就能带偏全局。AI再强也躲不过粗心和读题陷阱。