
 起点课堂会员权益
起点课堂会员权益数据飞轮到底是什么?
数据飞轮的驱动力从来不是技术栈复杂度,而是数据结构对齐度。本文从第一性原理拆解飞轮的三个要素(特征对齐×闭环数据×反馈管道)、三个阶段、加速临界点,以及最隐蔽的断裂点——分析层到执行层。大多数企业的飞轮转不起来,不是技术不够先进,是数据齿轮没有咬合。

所有关于“数据飞轮”的误解,都源于一个根本性偏差:人们以为飞轮是一个技术问题,实质上它是一个数据结构问题。你买了最贵的数据库,搭了最全的数据管道,接了最先进的AI模型,飞轮照样转不起来。因为飞轮的驱动力从来不是技术栈的复杂度,而是数据结构的对齐度。
这篇文章要做的事情很简单:把数据飞轮从技术神话拉回第一性原理,拆解它真正运转的齿轮、咬合的方式、加速的临界点,以及——最关键的——为什么大多数企业的飞轮在某个隐蔽的环节悄无声息地断裂了。
一、飞轮不是技术问题,是数据对齐问题
先问一个最基本的问题:什么叫”飞轮转起来了”?
大多数人脑海中的画面是:数据越积越多,模型越来越准,效果越来越好,数据又越来越多——一个正反馈循环。这个画面没错,但它描述的是结果,不是机制。就像你看到一辆车在跑,你不能因此就以为引擎是轮胎。
飞轮真正运转的机制是这样的:一条数据进来,它携带了某些特征,经过处理后产生了某个结果。如果你能把”特征”和”结果”对齐存储,你就能做一件事——统计发现”什么样的特征组合,对应什么样的结果”。发现了这个规律之后,下一轮生成就可以用这个规律来调参数。调完参数生成的新内容又产生新数据,新数据回流进来修正规律,规律越来越准,参数越来越优,飞轮越转越快。
这个闭环里,核心引擎不是数据库,不是大数据平台,不是AI模型——是“特征与结果对齐存储”这个数据结构。
什么叫数据结构对齐?说直白一点:每一条数据必须能同时回答两个问题。第一个问题:它有什么特征?第二个问题:它产生了什么结果?只有特征和结果在同一个数据结构里对齐存储,你才能做聚合统计,才能发现规律。
听起来简单得不像话。但你去看绝大多数企业的数据现状,特征和结果是分开存的。内容特征存在内容管理系统里,市场反馈存在运营报表里,用户行为存在埋点系统里,交易数据存在ERP里。这些数据各自完整,但它们之间没有对齐。你知道某条内容长什么样,但你不知道它产生了什么效果;你知道某个效果数据,但你不知道对应的内容有什么特征。
数据存了,但没对齐——这等于飞轮的齿轮没有咬合。齿轮不咬合,你施加再大的力,轮子也不会转。
这就是为什么飞轮不是技术问题。技术栈解决的是”数据怎么存、怎么传、怎么算”的问题,但数据结构对齐解决的是”数据能不能被用来发现规律”的问题。前者是基础设施,后者是飞轮引擎。你可以在最先进的云平台上跑最复杂的模型,但如果你的数据结构没有对齐,你跑出来的东西跟飞轮没有半毛钱关系。
反过来,你用Excel存数据,只要每行都同时记录了特征和结果,你就能开始做飞轮。一个SQL聚合就能发现规律,一个手工调整参数就能完成一轮飞轮旋转。飞轮的门槛不是技术门槛,是认知门槛——你有没有把特征和结果对齐存储。
二、飞轮的三个要素:特征对齐 × 闭环数据 × 反馈管道
理解了飞轮的本质是数据结构对齐之后,需要进一步拆解:一个能转起来的飞轮,到底需要哪些部件?
飞轮的共性引擎由三个要素构成:特征对齐、闭环数据、反馈管道。三个缺一个,飞轮都转不起来。
2.1 特征对齐:每条数据必须能回答”我是什么”和”我带来了什么”
特征对齐是飞轮的第一个要素,也是最容易在实操中被忽略的一个。
以内容生成领域为例。一条内容数据,如果只存了标题、正文、发布时间,那它只有”身份信息”,没有”特征信息”。要进入飞轮,它必须被打上结构化标签:开场类型是什么?反转次数是多少?节奏曲线是怎样的?情绪转折点在哪里?这些维度才是飞轮能用来统计分析的特征。同时,这条内容还必须记录结果指标:点击率多少?完播率多少?转化率多少?
特征和结果必须在同一条数据记录里对齐存在,不是存在两张表里通过某个ID关联——是在写入的那一刻就对齐。因为飞轮要做的是高频聚合统计,如果每次统计都要先做表关联,效率和可靠性都会大打折扣。
在交易闭环领域,特征对齐的含义更进一步:它不仅是单条数据的特征与结果对齐,更是多类业务对象之间的关联对齐。商品、供应方、分销方、消费者、内容、交易——六类对象必须互相关联,形成闭环数据模型。对象之间不关联,数据就是孤岛;孤岛上的数据再多,飞轮也转不起来。
还有一个容易被忽视的点:非结构化数据的结构化转化。对话记录、用户评价、运营复盘——这些数据天然是非结构化的,但如果不能被转成结构化字段,就无法进入飞轮的统计分析。一个用户评价里写了”节奏太慢”,这条信息必须被转成”节奏评分: 低”这样的结构化字段,才能参与统计。特征对齐的本质,是让每一条数据从“可以被阅读”变成“可以被计算”。
2.2 闭环数据:从生成到反馈必须形成完整回路
第二个要素是闭环数据。光有特征对齐还不够,还需要确保数据从生成端到反馈端形成完整回路。
闭环的意思不是“数据从A流到B”,而是“数据从A出发,经过B的处理,又回到A来修正A的下一轮决策”。如果数据只从A流到B,那叫数据流,不叫闭环。闭环的核心在于回流——反馈数据必须回到生成端,去修正生成参数。
很多企业在这个环节出了问题。数据采集做到了,分析也做了,但分析结果没有回流到生成端。分析发现”某类特征组合效果更好”,但生成端根本不知道这个结论,或者知道了也不按这个结论执行。这就像你请了人帮你分析路况,他告诉你”前面左转更快”,但你方向盘不听他的,你还是直行。
闭环数据的另一个要求是时效性。反馈数据回流得越快,飞轮转得越快。飞轮不怕慢,怕的是回路断了。回路一断,前面所有的积累都变成死数据。
2.3 反馈管道:数据回流必须是自动的,不能靠人
第三个要素是反馈管道。这是飞轮的命脉。
如果数据回流靠人手动录入,飞轮永远转不起来。不是转得慢,是转不起来。因为人手动录入意味着:延迟高、遗漏多、格式不统一、成本不可控。一个月手动录几十条数据还行,几百条就开始出错,几千条就彻底崩溃。
反馈管道要解决的问题是:从数据产生到数据进入飞轮分析层,这个过程必须是自动的、可靠的、低延迟的。真正的难度在于:管道两端的数据结构必须对齐。采集端采集的数据格式,必须和存储端的特征字段一一对应。反馈管道是飞轮的命脉,但命脉的通畅取决于两端的数据结构对齐——又回到了第一节的核心论点。
三个要素不是并列关系,是乘法关系。任何一个为零,飞轮的驱动力就为零。
飞轮的驱动力 = 特征对齐度 × 闭环完整度 × 管道自动化率。任何一个变量趋近于零,整个乘积就趋近于零。
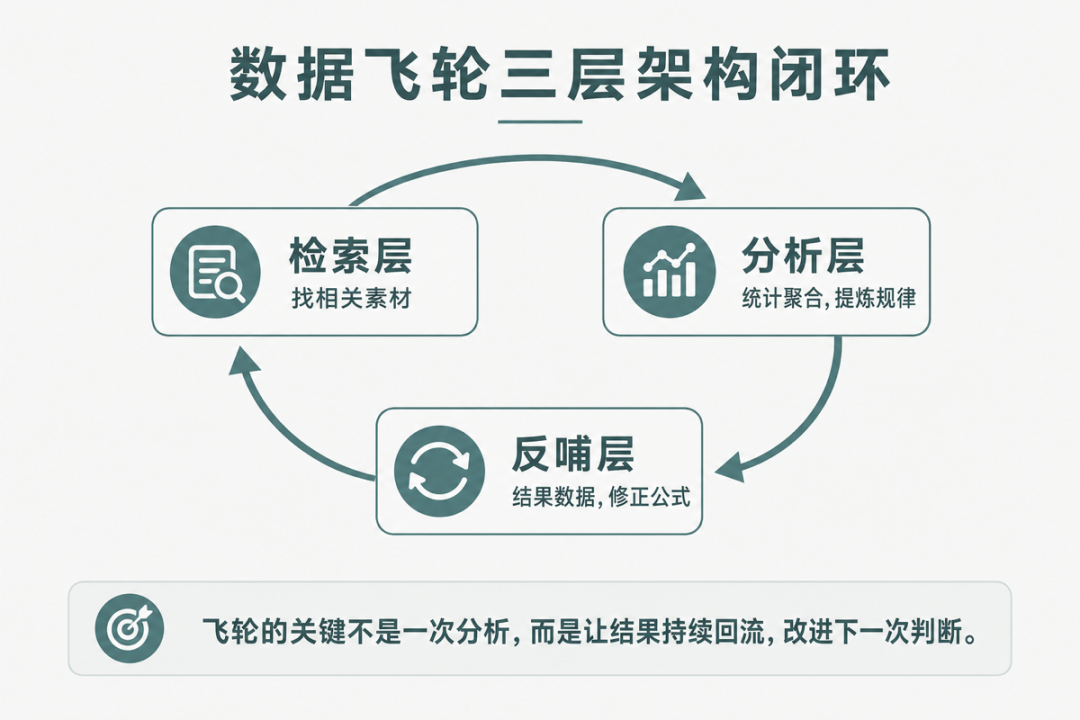
三、飞轮的三个阶段:从粗规律到确定解
飞轮不是一上来就能高速旋转的,它有三个明确的阶段,每个阶段的运转方式完全不同。
3.1 第一阶段:小数据量——粗规律,人凭经验+数据共同决策
飞轮刚启动时,数据量很小。你能发现的规律是粗的——单维度统计就能看出一些趋势。这个阶段,数据告诉你方向,人凭经验做微调。
这个阶段最重要的不是追求精准,而是把飞轮的三个要素跑通——特征对齐的结构先搭好,闭环回路的管道先接上,反馈数据的采集先启动。哪怕数据量小、规律粗,只要飞轮在转,数据就在积累,规律就在变准。
很多人在这个阶段犯的错误是:觉得数据量太小,统计分析没有意义,于是不搭数据结构、不接反馈管道,等数据量大了再说。这是致命的。因为当数据量真的大了的时候,你会发现历史数据没有对齐存储——你想回头补,成本极高,还不如从头来过。飞轮第一阶段的核心任务不是发现精准规律,而是建立数据结构对齐的基础设施。
3.2 第二阶段:中数据量——多维度交叉分析,公式可指导参数
当数据量积累到一定程度,飞轮进入第二阶段。这个阶段的标志是:单维度统计不够用了,你需要做多维度交叉分析。
单维度统计告诉你”特征A的内容表现好”,但它没告诉你”在什么条件下特征A才表现好”。多维度交叉分析告诉你”在条件X下,特征A+特征B+参数C=最优结果”。这个规律可以直接指导参数调整。飞轮的转速明显加快,因为每一轮反馈都在修正参数。
飞轮第二阶段的核心变化是:从单维度统计进入交叉分析。这个变化不是渐进的,是跃迁的——它就是飞轮加速的临界点。
3.3 第三阶段:大数据量——精准公式,飞轮自动化运转
当数据量足够大、交叉分析足够充分时,飞轮进入第三阶段。统计公式已经非常精准,接近确定解:给定一组特征和条件,公式能高概率地预测出最优参数。飞轮可以自动化运转了。数据回流→交叉分析→参数修正→生成——全程不需要人干预。
飞轮第三阶段的本质是:数据驱动的参数修正已经足够可靠,人的角色从“决策者”变成了“监督者”。
四、飞轮加速的临界点:不是数据量增大,是进入交叉分析
这一节要回答一个关键问题:飞轮真正加速的临界点在哪里?
大多数人的直觉答案是:数据量足够大的时候。这个答案不够精确。数据量增大是必要条件,但不是临界点。飞轮真正加速的临界点,是从单维度统计进入交叉分析的那一刻。
4.1 为什么单维度统计无法让飞轮加速
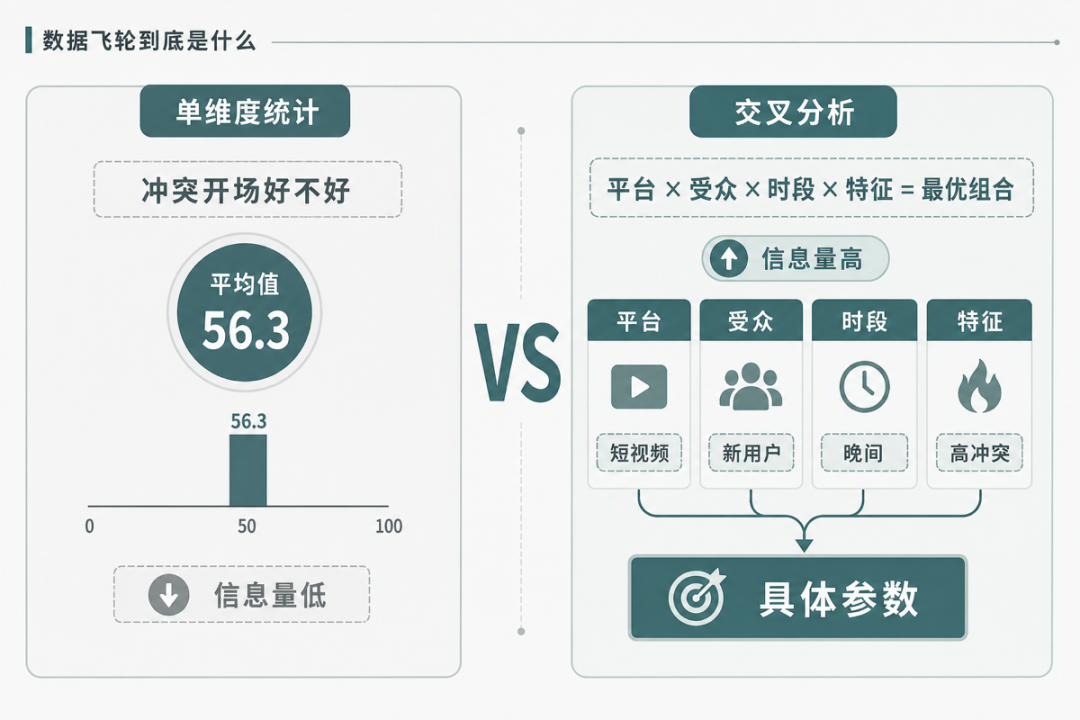
单维度统计能告诉你”特征A的内容平均表现比特征B好”。这个信息有用,但不够用。因为它回答不了:”在什么条件下,特征A才比特征B好?”
现实世界的结果几乎从不是由单一特征决定的。一条内容的表现好坏,取决于开场类型、反转次数、节奏曲线、情绪转折点等多个特征的组合。单维度统计把这些因素拆开来单独看,每个因素都看不出什么显著规律——因为效果好的内容可能同时有”好的开场”和”好的节奏”,但你单独统计”开场类型”时,好开场和坏开场的表现差异不大。
单维度统计的世界里,每个维度看起来都不重要,但组合起来却决定一切。这就是为什么单维度统计无法让飞轮加速——它看不到组合效应。
4.2 交叉分析为什么是临界点
交叉分析做的事情是:把多个维度组合起来看。”在条件X下+特征A+特征B+参数C=什么结果?”这个问题的答案,才是飞轮能用来调参数的规律。
交叉分析是飞轮加速的临界点,原因有三:
第一,交叉分析能看到组合效应。单维度统计看不到的规律,交叉分析能看到。飞轮能发现的规律从”粗的方向”变成了”精准的参数组合”。
第二,交叉分析能指导具体参数。从”方向”到”参数值”,是飞轮从”辅助决策”到”驱动决策”的跃迁。
第三,交叉分析只有在数据量足够大时才有效。数据量小的时候,交叉分析的子样本太少,统计结果不可靠。这就是为什么数据量增大是必要条件——它为交叉分析提供了统计可靠性的基础。
临界点的判断标准是:对于你关心的每一个特征组合,是否有足够的样本量来做出统计可靠的判断。如果你有N个特征维度,每个维度有M个可能的取值,那么特征组合的总数是M^N量级。你的数据量必须远大于这个数。维度越多、取值越细,阈值越高。这就是为什么特征设计很重要——不是维度越多越好,而是维度要足够有效、取值要足够精简。
五、为什么大多数企业的飞轮转不起来
大多数企业的飞轮转不起来,不是因为技术不够先进,不是因为数据量不够大。是因为飞轮在三个地方断裂了。
5.1 第一处断裂:数据结构没对齐
最常见的断裂点。企业的数据存了很多,但特征和结果没对齐。你想做交叉分析,发现特征数据和结果数据根本对不上。数据存了但没对齐,就像你有了一堆齿轮但齿距不匹配——齿轮再多,也咬合不上。
这个断裂点的修复成本极高,因为它是历史遗留问题。过去存数据的时候没有考虑特征对齐,现在要回头改数据模型、迁移历史数据、改造所有数据写入流程。很多企业评估完改造成本之后就放弃了。
5.2 第二处断裂:反馈管道靠人
数据结构对齐了,闭环回路也设计了,但反馈数据的回流靠人手动操作。运营人员每天手动导出报表、手动录入分析系统、手动更新参数表。数据量一大就崩溃。
反馈管道靠人,飞轮的转速就被人限制了。人的处理速度有上限,注意力有上限,耐心也有上限。
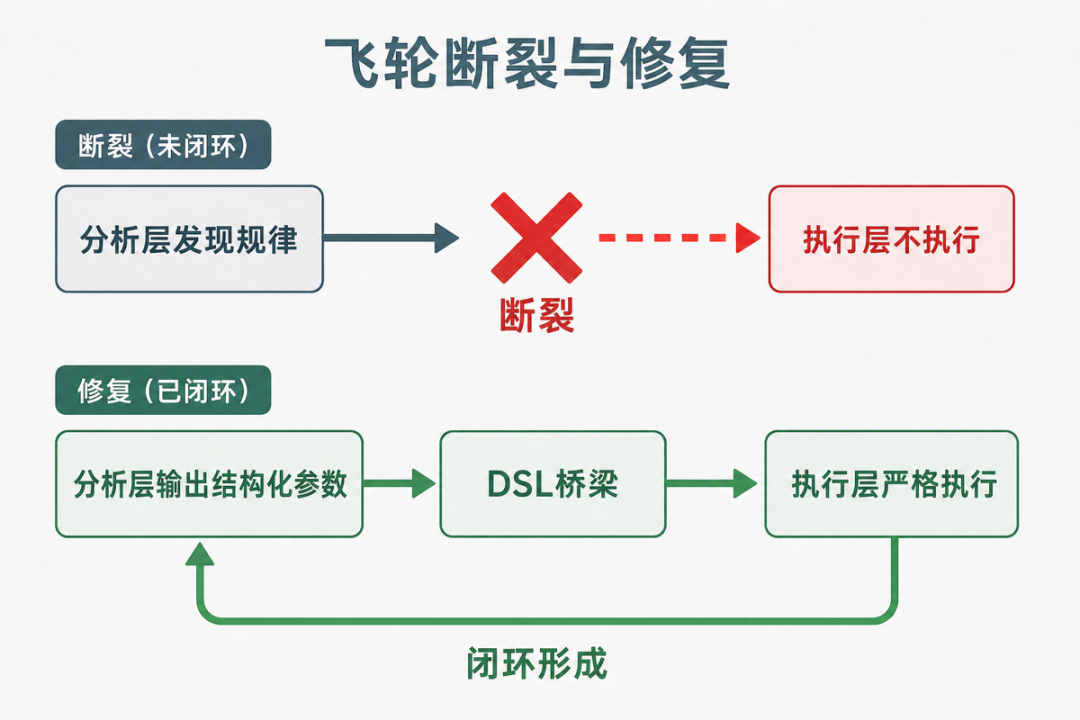
5.3 第三处断裂:从分析层到执行层
这是最隐蔽也最致命的断裂点。分析做了,规律发现了,报告写了,但执行层没有按照分析结果来调整参数。
分析层输出的东西是统计规律:”在条件X下,特征A+特征B+参数C=最优结果。”但执行层需要的是具体的生成指令:”请按照特征A、特征B、参数C来生成。”这两种表述之间存在一个”翻译”问题。
如果翻译靠人来做,就会出现:理解偏差(人对”强反转”的理解和分析层定义的不一样)、执行不一致(人做不到每次严格按参数来)、无法规模化(靠人手动调参数,批量生成不可能)。
从分析层到执行层的断裂,本质上是“语言”的不匹配。分析层说的是统计语言,执行层需要的是结构化指令。两种语言之间需要一个翻译器,而这个翻译器不能是人。
下一节深入拆解这个断裂点。
六、飞轮最隐蔽的断裂:从分析层到执行层
6.1 断裂的本质:分析能发现规律,但生成不执行规律
分析层运转正常,规律发现了——”某组特征组合在某个条件下产生最优结果”。这个规律被写进了报告,送到了执行团队。然后呢?执行团队看了报告,觉得有道理,然后在下一次生成时……还是按自己的经验来。
不是他们不认同分析结论,而是分析结论对他们来说太抽象了。分析报告说”高情绪密度+中频反转+渐进式节奏=最优完播率”,但执行人员面对的是具体操作:开场怎么写?反转放在第几秒?节奏怎么控制?
分析层输出的是“什么规律有效”,执行层需要的是“怎么按这个规律来做”。这两者之间的鸿沟,就是断裂发生的地方。
6.2 为什么自然语言描述解决不了这个问题
有人说:那我们把分析结论写成自然语言指令,让执行者按照指令来不就行了?
试一下。你把”悬念式开场+两次反转+快慢交替节奏+中段情绪高潮”写给一个AI,让它生成内容。AI会生成一个”大致符合”描述的内容——但悬念的具体形式是它自己选的,反转的时机和力度是它自己定的,哪里快哪里慢是它自己判断的。
问题在于:自然语言描述的是“方向”,不是“参数”。方向是模糊的,参数是精确的。模糊的方向给执行者留下了太大的自由发挥空间。这就像你用手指比划给木匠看你要什么样的椅子——你得到了一把”大致像”的椅子,但不是你要的那把。
6.3 解决方案:结构化参数注入
要修复这个断裂,需要把分析结论转化为结构化参数,然后直接注入生成层。
“悬念式开场”不是一个参数,但”开场类型=悬念式”是一个参数。”两次反转”不是一个参数,但”反转次数=2″是一个参数。”快慢交替节奏”不是一个参数,但”节奏曲线=[快,慢,快,慢]”是一个参数。
当分析结论被拆解成结构化参数后,生成层不是”读了报告然后理解规律”,而是”接收了一组参数然后严格执行”。参数说什么就生成什么,没有自由发挥的空间。
分析层的输出不是一份报告,而是一组参数;执行层的输入不是一份描述,而是一组约束。参数和约束用同一种结构化语言表达,飞轮的回路就闭合了。
6.4 参数的两个层级:不可变维度与可变维度
不是所有参数都应该由飞轮来修正。参数分为两类:
不可变维度——骨架。这些维度定义了内容的基本结构,是经验法则的下限保证。它们不轻易改,也不应该由飞轮的数据来改。骨架的作用是保证即使飞轮的参数修正出了偏差,生成的内容至少不会跑偏到不可接受的程度。
可变维度——参数。这些是飞轮要修正的对象——在骨架之上的微调参数。它们的调整不会改变内容的基本结构,但会显著影响表现。
不可变维度是经验法则的下限保证,可变维度是飞轮要优化的上限突破。骨架保证不犯错,参数追求更优。飞轮只动参数不动骨架。
6.5 飞轮通过参数注入实现自动化
参数体系建立之后,飞轮的运转流程变成:人写初始参数→生成→分发→采集数据→分析发现更优参数组合→参数自动修正→下一轮用新参数→飞轮加速。
关键在于:参数是数据驱动修正的,不是人拍脑袋改的。人只做两件事:设定初始参数和骨架;监控飞轮健康度,处理异常。这就是飞轮从分析层到执行层断裂的终极修复方案——不是靠更好的分析,不是靠更强的AI,而是靠一个结构化的参数注入机制。
没有这个机制,飞轮在分析层到执行层之间永远断着;有了这个机制,飞轮的回路才真正闭合。
七、数据治理和健康度指标——飞轮的安全带
飞轮转起来之后,不是就万事大吉了。任何高速运转的系统都需要安全机制。数据治理和健康度指标就是飞轮的安全带——不系安全带,飞轮转得越快,出事的时候伤得越重。
7.1 数据治理:飞轮的底盘
如果对齐的数据本身有问题——特征标签打错了、结果指标采集有偏差、非结构化数据转结构化时丢失了信息——那么飞轮的统计分析就会得出错误的规律,错误的规律导致错误的参数修正,错误的参数导致更差的结果,更差的结果回流回来又”验证”了错误的规律。
这是一个负反馈循环——飞轮不仅不会加速,还会减速,甚至反向旋转。数据质量是飞轮的底线,底线破了,飞轮就变成了”用错误数据证明错误规律”的灾难机器。
数据治理需要关注:特征标签的一致性(同一个维度在不同记录里定义必须一致)、结果指标的准确性(不同渠道的采集逻辑必须统一)、数据对齐的完整性(有没有只有特征没有结果的”半对齐”数据)、非结构化转结构化的保真度。
7.2 健康度指标:飞轮的仪表盘
飞轮的健康度指标至少应包含以下几个:
- 特征覆盖率——多少比例的数据有完整的结构化特征标签?应持续上升至接近100%。
- 闭环完整率——多少比例的生成内容有对应的反馈数据回流?低则说明管道断裂。
- 参数修正频率与幅度——频率太低说明飞轮慢;幅度越来越小说明在收敛(好事);幅度一直很大说明不收敛,可能是数据噪音或特征设计有问题。
- 分析结论的统计显著性——不显著说明数据量还不够,飞轮还没到加速临界点。
- 生成质量波动率——波动率大说明参数修正不可靠,需要回退。
7.3 异常处理:飞轮的应急机制
当某个健康度指标超出正常范围时,飞轮应自动进入异常处理模式。特征覆盖率突然下降,暂停飞轮、修复数据源。参数修正幅度突变,人工介入评估。
异常处理的原则是:宁可停飞轮,不可带病运转。飞轮带病运转的后果是用错误数据驱动错误参数,比不转还糟糕。人的角色在飞轮运转中始终存在,但性质变了:飞轮正常时,人是监督者;飞轮异常时,人是维修者。人不是飞轮的引擎,人是飞轮的保险。
八、飞轮的落地路径:先跑起来再优化
飞轮落地的核心原则是:先跑起来再优化。不要等数据结构完美了再启动,不要等技术栈搭好了再做分析,不要等数据量足够大了才做交叉分析。
8.1 第一阶段:用最简工具跑通闭环
目标是跑通闭环——特征对齐的结构搭好,闭环回路的管道接上,反馈数据的采集启动。Excel都行。关键动作:设计特征维度表、建立结果指标采集、把特征和结果对齐存储、做单维度统计。这个阶段的成功标准不是发现了精准规律,而是飞轮在转——数据在产生、在回流、在对齐、在被分析。
8.2 第二阶段:进入交叉分析
目标是从单维度统计升级到交叉分析。关键动作:设计交叉分析框架、建立参数体系(区分骨架和参数)、搭建参数注入机制、启动参数自动修正。成功标准是:交叉分析能发现可指导参数的规律,参数注入机制让分析结论自动进入生成层,飞轮回路真正闭合。
8.3 第三阶段:飞轮自动化
目标是飞轮自动化运转。关键动作:建立健康度指标体系、完善异常处理机制、逐步扩大飞轮覆盖范围。成功标准是:飞轮自动化运转,参数持续收敛,生成质量持续提升,人的干预最小化。
九、总结:飞轮的真相
数据飞轮不是一套技术栈,不是一个大模型,不是一个数据中台。数据飞轮是一个由数据结构对齐驱动的闭环系统——特征对齐让数据可计算,闭环数据让回路可闭合,反馈管道让数据可回流,交叉分析让规律可发现,参数注入让规律可执行。
飞轮的驱动力不是技术复杂度,是数据结构对齐度。你用Excel做分析,只要数据结构对齐了,飞轮就能转。你用最先进的AI平台做分析,如果数据结构没对齐,飞轮就是一堆空转的齿轮。
飞轮加速的临界点不是数据量增大,是从单维度统计进入交叉分析。只有交叉分析才能看到组合效应,才能指导具体参数。
飞轮最隐蔽的断裂点是从分析层到执行层。分析层发现了规律,但如果没有结构化的参数注入机制,规律传不到执行层,飞轮白转了。修复这个断裂的方法不是更好的分析,是让分析层的输出和执行层的输入用同一种结构化语言来表达。
飞轮的安全带是数据治理和健康度指标。数据质量是飞轮的底线——底线破了,飞轮就变成了用错误数据证明错误规律的灾难机器。
最后一句:
飞轮的本质,从来不是让你拥有更多的数据,而是让每一条数据都能回答“什么特征导致了什么结果”。当你的每一条数据都能回答这个问题时,你不需要最先进的技术,不需要最大的数据量——你的飞轮已经在转了,而且会越转越快。先跑起来。用Excel都行。但每行必须有特征、有结果。这就是飞轮的第一步,也是最重要的一步。
本文由 @冲量AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


