
 起点课堂会员权益
起点课堂会员权益构建用户画像中所用到的AI算法
本文从三个部分——标签的层级、生产、权重方面,分析了构建用户画像中所用到的AI算法。

谈及用户画像,我想产品和运营的朋友们都不会陌生,用户画像是用户研究的重要输出,它能帮助我们更好的进行业务决策以及产品设计。用户画像落实到产品设计,本质上是将数据组合成数据特征,从而形成用户的数据模型。
构建用户画像的主流方法有4种:
- 基于数据统计
- 基于规则定义
- 基于聚类
- 基于主题模型
前两者是基于已有数据的构建方法,其缺陷是无法处理数据缺失或不在规则范围内的用户。而解决这一类问题,也正是机器学习存在的意义,它让计算机像人一样去学习处理问题,并给出答案。
本文将从构建用户画像的角度和大家分享能够运用在其中的一些AI算法,希望能给大家提供一些价值。
用户画像偏向于定性,而产品设计是将需求从定性转换为定量的过程,用户画像在量化过后我们也称之为用户标签。
一、标签的层级
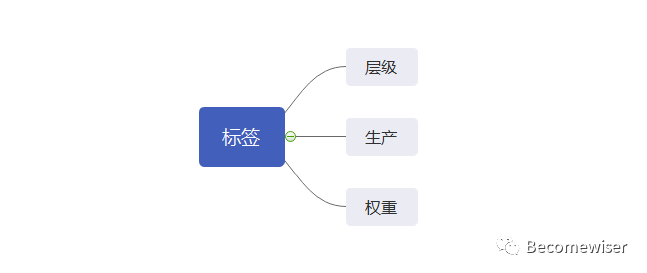
构建用户标签我拆分了三个步骤,分别是层级、生产以及权重。理解标签的层级能够帮助我们设计产品架构,并且熟悉标签生产的方法。
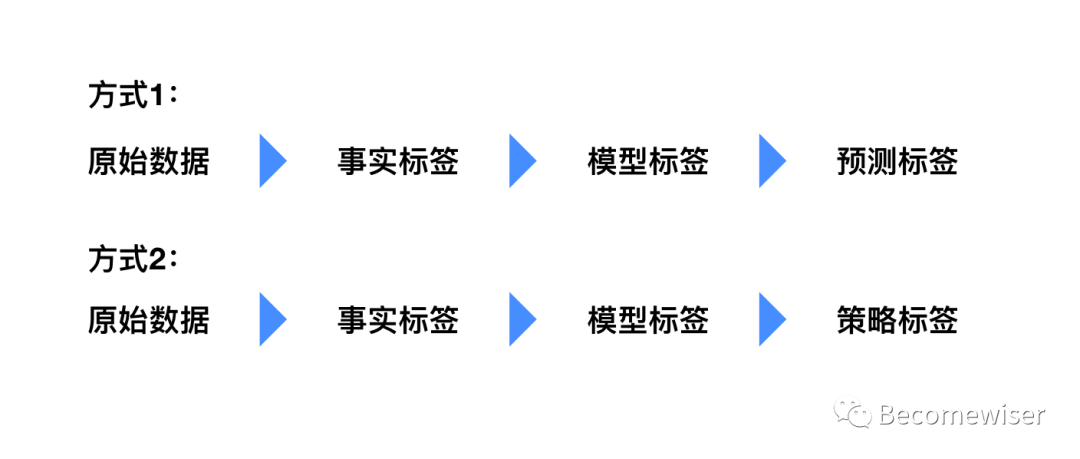
标签的层级有两种划分方式,方式1是较为常见的做法,而方式2查阅于京东的数据分析师凌靖的文章,结合两种方式之后形成了下图图3。
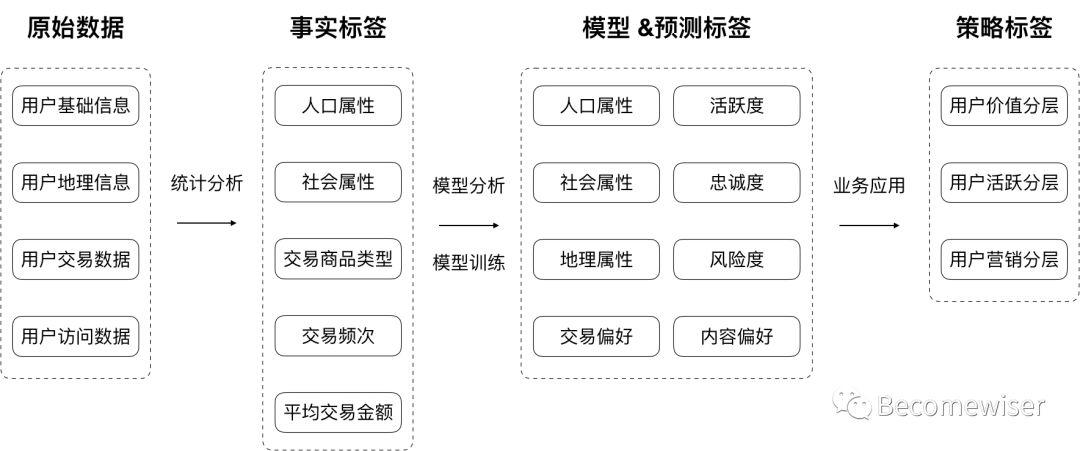
标签的每一个层级,可以将其理解为对上一层标签的再次提炼。对照着图3,我们试着理解这4个层级:
1. 原始数据
来源于用户的基础信息、交易数据、访问数据,如:用户的注册手机号码、用户的历史订单、用户的访问轨迹等。
2. 事实标签
是对原始数据进行统计分析后的初步提炼结果。
3. 模型标签及预测标签
3-1 模型标签
由一个或多个事实标签组合而成,是基于模型训练的结果。以模型标签“交易偏好”为例,它是由交易商品类型、交易场景、交易来源这几个事实标签组合而成的。
3-2 预测标签
以已有的模型标签数据作为特征,经过机器学习生产的标签。由于预测标签会映射成为模型标签,所以在图3中将2者放置于同一个层级。
4. 策略标签
策略标签,则是用户标签构建的最终目的,根据目的提炼用户,并对用户进行定向的营销。
标签的层级,指导着产品经理构建用户画像的每个步骤。前两个层级,我们需要对缺失的数据建立数据源,对数据进行清洗、修复以及特征构建等;后两个层级,我们需要使用合适的方式生产标签。
二、标签的生产
在第一章中我们理解了标签的层级,这一张主要讲述标签的生产过程,用户画像的构建方式不同,生产方式也不同。
1. 基于规则定义的标签生产方式
顾名思义,这种生产方式是根据固定的规则,通过数据查询的结果生产标签。这里的重点在于如何制定规则。
从数据的变化频次来看,可以将标签划分为静态标签以及动态标签。静态标签变化的频次低,或者一旦确认不做改变。而动态标签变化频繁,它会衰减也可能会消失。
以静态标签和动态标签为思路向下顺延,我们可以划分为基础属性以及偏好行为两大类,如下图图4所示:
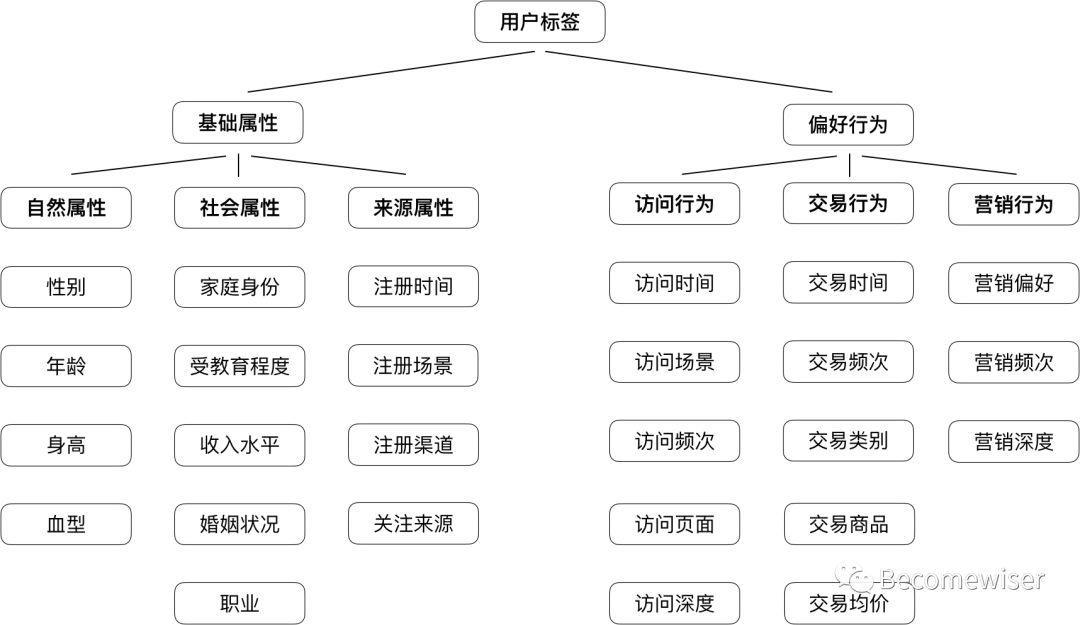
这是一张比较普适的图,在实际应用的过程中产品经理可以根据业务去定义更多的类型。将类型划分清楚,用户标签的生产工具已经初具雏形。
在设置规则时产品经理应该适当抽象,过于精细会增加研发的周期,上线后的数据查询也会有较大的压力。其次也可能因为筛选条件过多,查询的数据样本不足,导致空耗资源。
适当抽象考验产品经理对需求、资源以及应用的平衡能力,以用户访问行为为例,在初期不建议放开全量查询,可以优先将频次高、强度高的查询需求抽象成规则,如商品详情、平台活动、渠道投放等。
基于规则定义和基于数据统计这两种用户标签构建方式在产品设计中的逻辑是相对简单的,就不花更多的篇幅解释了。
2. 基于主题模型的标签生产方式
主题模型,最开始运用于内容领域,目的是找到用户的偏好,它将内容划分为了3个层级:分类、主题、关键词。
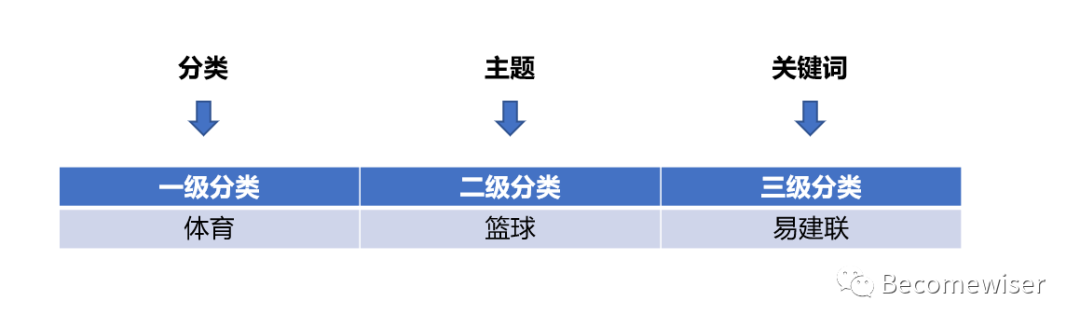
在用户标签中我们可以参照分类算法将用户进行分类、聚类,使用关键词的算法挖掘用户的偏好,从而生产标签。
2-1 线性支持向量机
线性支持向量机(Linear Support Vector Machine)是一种二分类算法,适用于“是与否”,“有或无”的问题,它隶属于机器学习中的有监督学习(Supervised Learning)。
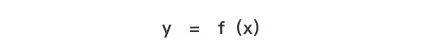
有监督学习,类似我们从小接触的函数公式,即根据输入(x),和公式f(x)得到输出(y),假设x是数据的特征,那么经过函数的运算后我们能够得到分类结果。
以人口属性为例,非社交应用用户填写自己性别的主动性较低。当我们想了解用户的性别组成,却只有10%用户填写了性别,而另外90%的用户的性别是未知的。
在机器学习中,我们会将明确性别的用户作为数据样本,提取他们的数据特征训练模型。以明确性别的用户的数据特征设为x,性别为y,训练出f(x)的函数之后,我们将其他未知性别的用户特征代入到公式f(x)中,从而去预测他们的性别。
函数是是由模型训练而成的,线性支持向量机是怎么训练的呢?
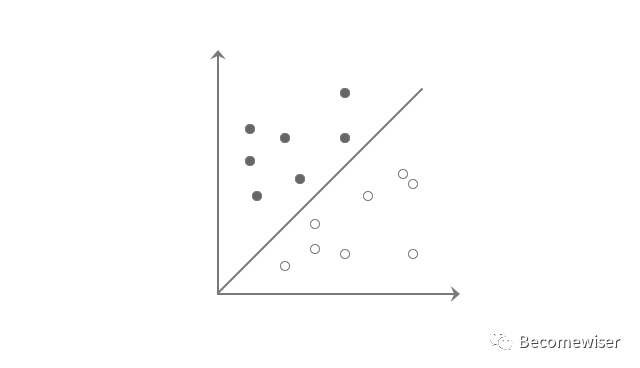
在图7中,我们发现有一条直线将象限中的数据分成了两部分,而支持向量机则是找到一条划分效果最好的直线。划分效果越好,新数据分类错误的可能性也越低,而这两个类别在支持向量机中我们也叫正样本和负样本。
回到线性支持向量机的定义:“对于给定的数据集,能在样本空间中找到一条划分直线,从而将两个不同类别的样本分开,并且这条直线距离最接近的训练数据点最远。”
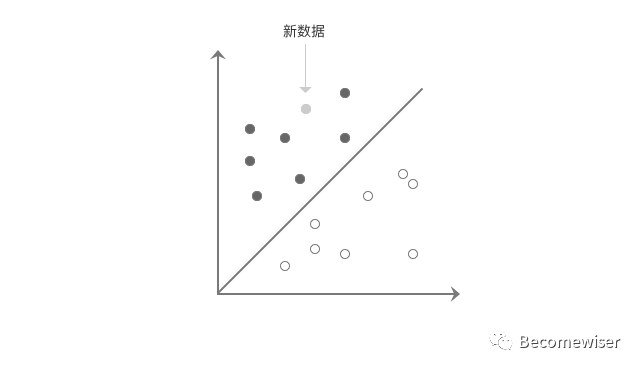
图8以购买过男性/女性短袖作为男性用户和女性用户的特征,黑点表示为已知的男性用户,白点为已知的女性用户。
当遇到新的未知性别的用户,但是我们发现其有购买过男性短袖这一行为,而这一用户的数据落在了男性部分,所以我们预测这个用户是男性。
当然在实际过程中,数据的特征绝对不仅是简单的二维特征,在这里只是方便大家理解。线性支持向量机在三维求解的是一个分类效果最好的平面,而在高维则是线性函数。
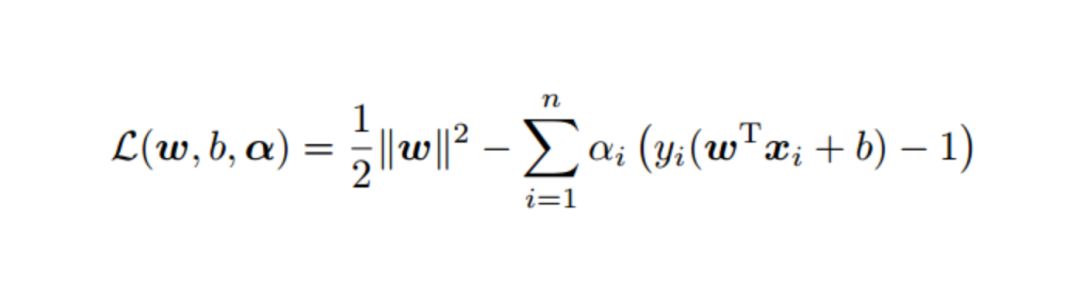
线性支持向量机的目标函数求解的过程比较复杂,在小规模数据集中线性支持向量机的表现是较好的,但是由于受到了数据量的限制,我们会运用训练更加简单并且能实时计算的算法——逻辑回归。
2-2 逻辑回归
逻辑回归(Logistic Regression)是和线性支持向量机非常相似,它们都是有监督学习方法,在不考虑核函数时都是线性的分类方法。其不同点在于,线性支持向量机是基于距离分类,而逻辑回归是基于可能性分类。
理解逻辑回归之前,我们先复习一下最简单的一元线性回归。一元线性回归的公式是:y=kx+b。
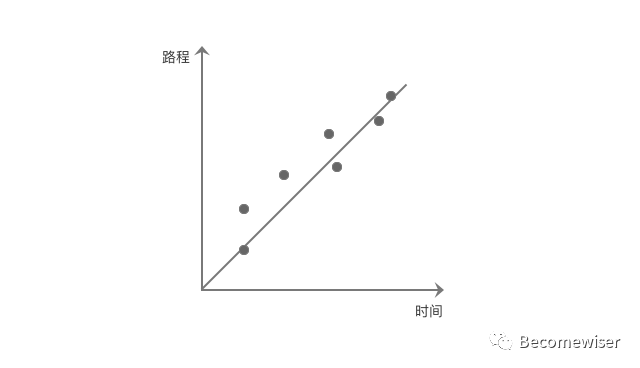
我们假定图10中的直线,代表着人在匀速状态下路程与速度的关系。但在实际情况下人的速度不是恒定的,我们没有办法使不同时间的速度都穿过这条直线。退而求其次,我们去找一条最接近这些速度数据的支线。
看到图10的函数图例,大家会发现线性回归和线性支持向量机非常的相像,线性回归与逻辑回归有什么关系?逻辑回归又是怎样的一种分类方式?
逻辑回归在线性回归的基础上套用了sigmoid函数,它将回归函数的结果映射在sigmoid函数之中,这个函数的特点是其值域分布在[0,1]之间,1和0对应了二分类的“是与否”,随着x值的变化,y值会不断的趋近于0或1,这种趋近我们称之为可能性。
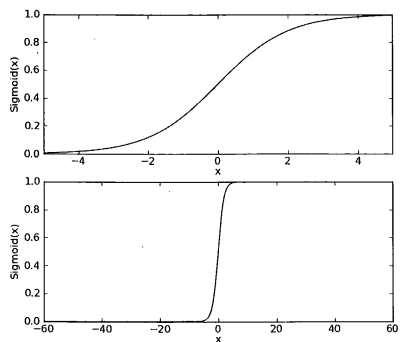
在线性支持向量机中只有两种值:正样本和负样本,而逻辑回归除了分类还能够表达分类的概率。
2-3 文本挖掘算法:TF-IDF
TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency),在用户画像的构建中我们会将其运用于生产用户的偏好标签。
TF表述的核心思想是,在1条文本中反复出现的词更重要。而IDF的思想是,在所有文本都出现的词是不重要的,IDF用于修正TF所表示的计算结果。

上文描述TF-IDF能够用于生产用户的偏好标签,其中的原理是什么呢?
我们将一名用户类比为一篇文章,用户浏览的商品标题在分词汇总后作为其中的词库,平台的用户总数即为文本总数,出现该词语的文本数作为有同样浏览行为的用户。这样转置过后,就能够进行计算了。

以用户A为例,用户A拥有3条浏览记录,分词后总计17个词。
设:平台的用户总数=10000人,用户浏览过的商品标题带有“黑色”1词的用户有500人,底数为2。
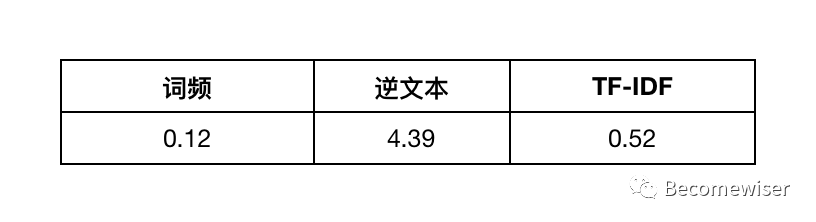
以底数为2,可计算“黑色”这个标签对用户的权重是0.52,有了权重我们能够将其运用于寻找相似用户。
三、标签的权重

标签权重的计算公式来源于赵洪田撰写的文章《用户标签之标签权重算法》,权重公式的解读如下:
1. 行为类型权重
指的是对于同一类标签,由于其行为的轻重不同所以权重不同。
如:用户对于某商品有过生成订单的行为,根据订单未支付、已支付未退款、已支付已退款三种订单状态,制定不同的权重。
2. 时间衰减因子
时间衰减因子体现了标签的热度随着时间逐渐冷却的过程,它来源于牛顿冷却定律。
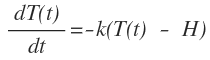
定律描述的是物体的冷却速度与其当前温度和室温之间的温差成正比。运用于新闻领域,一条新闻可能在今天它的“温度”是最高的,但是随着时间,这条新闻会逐渐的变成和普通新闻一样的“温度”。
经过对牛顿冷却定律的推导,我们得出了以下公式:
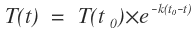
将公式翻译成中文:当前温度=原始温度 X exp(-冷却系数 X 间隔时间)
运用于标签的翻译:当前权重=原始权重 X exp(-冷却系数 X 间隔时间)
如:将用户发生行为的当日该偏好的权重设置为1,10天后设置为0.2,也就是经过9天后权重会衰减是0.2,将已知变量代入到图13的公式中,经过指数的运算得到冷却系数,从而得到时间衰减因子。
对于不同的标签,时间的衰减因子系数是不同的,有的标签甚至是不受时间所影响,在计算时可以不必考虑衰减因子。
公式中的TF-IDF、行为频次,前者已经描述过,后者也比较好理解在这里也不再赘述。标签的权重可以用于查找相似用户,进行个性化推荐,如果有有兴趣的朋友可以阅读我的上一篇文章《如何理解个性化推荐中的数学原理》。
写在最后
近期恰好设计了用户标签的提取工具,撰写本文原意是想回顾项目、查漏补缺。过程中阅读了一些人工智能的书籍,给了自己很多的启发,于是也将所了解的一些算法添加进来,如果有理解不正确的地方也请朋友们不吝指教。
这篇文章涉及的算法部分主要参考了:《产品经理进阶:100个案例搞懂人工智能》,这是一本很好的工具书,提供了特别好的知识框架让我体系化的认识人工智能,在此也为朋友们极力推荐这本书。
重点参考资料
1、林中翘—《产品经理进阶:100个案例搞懂人工智能》
2、吴军—《数学之美》
3、CWS_chen—《用户画像原理、技术选型及架构实现》 https://blog.csdn.net/SecondLieutenant/article/details/81153565
4、凌靖—《用户画像》 https://zhuanlan.zhihu.com/p/34385914
5、Jack Cui—机器学习实战教程(八):支持向量机原理篇之手撕线性SVM https://cuijiahua.com/blog/2017/11/ml_8_svm_1.html
6、伏草唯存—逻辑回归模型算法研究和案例分析 https://cloud.tencent.com/developer/article/1330810
7、hffzkl—基于牛顿冷却定律的时间衰减函数模型 https://blog.51cto.com/9269309/1865554
8、赵宏田—《用户标签之权重算法》
9、刘星辰—《基于文本挖掘的用户画像系统的设计与实现》
10、Coding Fish—《SVM原理及推导》 https://www.jianshu.com/p/05693f2091b7
彩蛋:
第10项,SVM的推导过程笔者还没有完全推导成功,愿意讲课的朋友请你吃饭呀~
本文由 @WISE 原创发布于人人都是产品经理 ,未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议









基于聚类和基于主题模型,这两种划分方法的原则一致吗?基于主题模型里面又说了可以使用聚类进行标签生产,这是为什么?我理解聚类(无监督)应该和分类(有监督)对应。。分类算法是否属于基于规则定义中的一种?困惑。。。
很棒啊 标签的分层曾有类似的想法
谢谢你。