
 起点课堂会员权益
起点课堂会员权益33款可用来抓数据的开源爬虫软件工具

要玩大数据,没有数据怎么玩?这里推荐一些33款开源爬虫软件给大家。
爬虫,即网络爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
世界上已经成型的爬虫软件多达上百种,本文对较为知名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非大型、复杂的搜索引擎,因为很多兄弟只是想爬取数据,而非运营一个搜索引擎。
Java爬虫
1. Arachnid
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器能够分析包含HTML内容的输入流.通过实现Arachnid的子类就能够开发一个简单的Web spiders并能够在Web站上的每个页面被解析之后增加几行代码调用。 Arachnid的下载包中包含两个spider应用程序例子用于演示如何使用该框架。
特点:微型爬虫框架,含有一个小型HTML解析器
许可证:GPL
2、crawlzilla
crawlzilla 是一个帮你轻松建立搜索引擎的自由软件,有了它,你就不用依靠商业公司的搜索引擎,也不用再烦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能分析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有中文分词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个方便好用易安裝的搜索平台。
授权协议: Apache License 2
开发语言: Java JavaScript SHELL
操作系统: Linux
特点:安装简易,拥有中文分词功能
3、Ex-Crawler
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部分,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库存储网页信息。
- 授权协议: GPLv3
- 开发语言: Java
- 操作系统: 跨平台
特点:由守护进程执行,使用数据库存储网页信息
4、Heritrix
Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:https://github.com/internetarchive/heritrix3
- 授权协议: Apache
- 开发语言: Java
- 操作系统: 跨平台
特点:严格遵照robots文件的排除指示和META robots标签
5、heyDr

heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3协议。
用户可以通过heyDr构建自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据准备。
- 授权协议: GPLv3
- 开发语言: Java
- 操作系统: 跨平台
特点:轻量级开源多线程垂直检索爬虫框架
6、ItSucks
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面
7、jcrawl
jcrawl是一款小巧性能优良的的web爬虫,它可以从网页抓取各种类型的文件,基于用户定义的符号,比如email,qq.
- 授权协议: Apache
- 开发语言: Java
- 操作系统: 跨平台
特点:轻量、性能优良,可以从网页抓取各种类型的文件
8、JSpider
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL一定要加上协议名称,如:http://,否则会报错。如果省掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用什么插件,结果存储方式等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider非常容易扩展,可以利用它开发强大的网页抓取与数据分析工具。要做到这些,需要对JSpider的原理有深入的了 解,然后根据自己的需求开发插件,撰写配置文件。
- 授权协议: LGPL
- 开发语言: Java
- 操作系统: 跨平台
特点:功能强大,容易扩展
9、Leopdo
用JAVA编写的web 搜索和爬虫,包括全文和分类垂直搜索,以及分词系统
- 授权协议: Apache
- 开发语言: Java
- 操作系统: 跨平台
特点:包括全文和分类垂直搜索,以及分词系统
10、MetaSeeker
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方法,如果按照部署在哪里分,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前很流行)等做,可以速度做得很快,一般综合搜索引擎的爬虫这样做。但是,如果对方讨厌爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗用的带宽也是挺贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或者比价服务或者推荐引擎,相对容易很多,这类爬虫不是什么页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价格信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以部署很多,而且可以很有侵略性,对方很难封锁。
MetaSeeker中的网络爬虫就属于后者。
MetaSeeker工具包利用Mozilla平台的能力,只要是Firefox看到的东西,它都能提取。
MetaSeeker工具包是免费使用的,下载地址:www.gooseeker.com/cn/node/download/front
特点:网页抓取、信息提取、数据抽取工具包,操作简单
11、Playfish
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还很不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各类论坛,贴吧,以及各类CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方法:
- 下载右边的.war包导入到eclipse中,
- 使用WebContent/sql下的wcc.sql文件建立一个范例数据库,
- 修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。
- 然后运行SystemCore,运行时候会在控制台,无参数会执行默认的example.xml的配置文件,带参数时候名称为配置文件名。
系统自带了3个例子,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz论坛的内容。
- 授权协议: MIT
- 开发语言: Java
- 操作系统: 跨平台
特点:通过XML配置文件实现高度可定制性与可扩展性
12、Spiderman
Spiderman 是一个基于微内核+插件式架构的网络蜘蛛,它的目标是通过简单的方法就能将复杂的目标网页信息抓取并解析为自己所需要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath怎么获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
- 授权协议: Apache
- 开发语言: Java
- 操作系统: 跨平台
特点:灵活、扩展性强,微内核+插件式架构,通过简单的配置就可以完成数据抓取,无需编写一句代码
13、webmagic
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。

webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
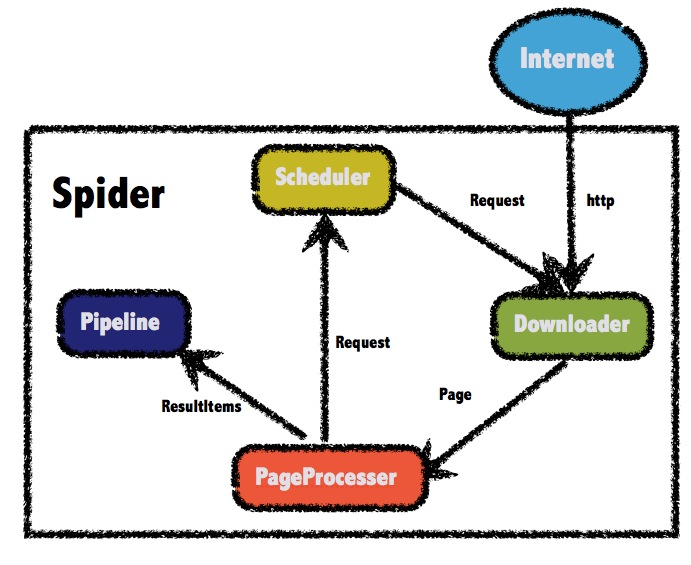
webmagic包含强大的页面抽取功能,开发者可以便捷的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:http://webmagic.io/docs/
查看源代码:http://git.oschina.net/flashsword20/webmagic
- 授权协议: Apache
- 开发语言: Java
- 操作系统: 跨平台
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献
14、Web-Harvest
Web-Harvest是一个Java开源Web数据抽取工具。它能够收集指定的Web页面并从这些页面中提取有用的数据。Web-Harvest主要是运用了像XSLT,XQuery,正则表达式等这些技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这些技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑怎么处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
- 授权协议: BSD
- 开发语言: Java
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面
15、WebSPHINX
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以自动浏览与处理Web页面的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
授权协议:Apache
开发语言:Java
特点:由两部分组成:爬虫工作平台和WebSPHINX类包
16、YaCy
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是构建基于p2p Web索引网络的一个新方法.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
- 授权协议: GPL
- 开发语言: Java Perl
- 操作系统: 跨平台
特点:基于P2P的分布式Web搜索引擎
Python爬虫
17、QuickRecon
QuickRecon是一个简单的信息收集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats寻找人际关系等。QuickRecon使用python编写,支持linux和 windows操作系统。
- 授权协议: GPLv3
- 开发语言: Python
- 操作系统: Windows Linux
特点:具有查找子域名名称、收集电子邮件地址并寻找人际关系等功能
18、PyRailgun
这是一个非常简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
- 授权协议: MIT
- 开发语言: Python
- 操作系统: 跨平台 Windows Linux OS X
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:https://github.com/princehaku/pyrailgun#readme
19、Scrapy
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便~
- 授权协议: BSD
- 开发语言: Python
- 操作系统: 跨平台
github源代码:https://github.com/scrapy/scrapy
特点:基于Twisted的异步处理框架,文档齐全
C++爬虫
20、hispider
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
- 基于unix/linux系统的开发
- 异步DNS解析
- URL排重
- 支持HTTP 压缩编码传输 gzip/deflate
- 字符集判断自动转换成UTF-8编码
- 文档压缩存储
- 支持多下载节点分布式下载
- 支持网站定向下载(需要配置 hispiderd.ini whitelist )
- 可通过 http://127.0.0.1:3721/ 查看下载情况统计,下载任务控制(可停止和恢复任务)
- 依赖基本通信库libevbase 和 libsbase (安装的时候需要先安装这个两个库)、
工作流程:
- 从中心节点取URL(包括URL对应的任务号, IP和port,也可能需要自己解析)
- 连接服务器发送请求
- 等待数据头判断是否需要的数据(目前主要取text类型的数据)
- 等待完成数据(有length头的直接等待说明长度的数据否则等待比较大的数字然后设置超时)
- 数据完成或者超时, zlib压缩数据返回给中心服务器,数据可能包括自己解析DNS信息, 压缩后数据长度+压缩后数据, 如果出错就直接返回任务号以及相关信息
- 中心服务器收到带有任务号的数据, 查看是否包括数据, 如果没有数据直接置任务号对应的状态为错误, 如果有数据提取数据种link 然后存储数据到文档文件.
- 完成后返回一个新的任务.
授权协议: BSD
开发语言: C/C++
操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载
21、larbin
larbin是一种开源的网络爬虫/网络蜘蛛,由法国的年轻人 Sébastien Ailleret独立开发。larbin目的是能够跟踪页面的url进行扩展的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于如何parse的事情则由用户自己完成。另外,如何存储到数据库以及建立索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每天获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它建立url 列表群,例如针对所有的网页进行 url retrive后,进行xml的联结的获取。或者是 mp3,或者定制larbin,可以作为搜索引擎的信息的来源。
- 授权协议: GPL
- 开发语言: C/C++
- 操作系统: Linux
特点:高性能的爬虫软件,只负责抓取不负责解析
22、Methabot
Methabot 是一个经过速度优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
- 授权协议: 未知
- 开发语言: C/C++
- 操作系统: Windows Linux
特点:过速度优化、可抓取WEB、FTP及本地文件系统
源代码:http://www.oschina.net/code/tag/methabot
C#爬虫
23、NWebCrawler
NWebCrawler是一款开源,C#开发网络爬虫程序。
特性:
- 可配置:线程数,等待时间,连接超时,允许MIME类型和优先级,下载文件夹。
- 统计信息:URL数量,总下载文件,总下载字节数,CPU利用率和可用内存。
- Preferential crawler:用户可以设置优先级的MIME类型。
- Robust: 10+ URL normalization rules, crawler trap avoiding rules.
授权协议: GPLv2
开发语言: C#
操作系统: Windows
项目主页:http://www.open-open.com/lib/view/home/1350117470448
特点:统计信息、执行过程可视化
24、Sinawler
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系搜集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研发等的数据支持,但请勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数量的限制、获取微博数量的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和表演当前作品,制作派生作品。 你不可将当前作品用于商业目的。
5.x版本已经发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节请求频率的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现在测试的结果看,已经能够满足自用。
本程序的特点:
- 6个后台工作线程,最大限度挖掘爬虫性能潜力!
- 界面上提供参数设置,灵活方便
- 抛弃app.config配置文件,自己实现配置信息的加密存储,保护数据库帐号信息
- 自动调整请求频率,防止超限,也避免过慢,降低效率
- 任意对爬虫控制,可随时暂停、继续、停止爬虫
- 良好的用户体验
授权协议: GPLv3
开发语言: C# .NET
操作系统: Windows
25、spidernet
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望提交你的代码.
- 授权协议: MIT
- 开发语言: C#
- 操作系统: Windows
github源代码:https://github.com/nsnail/spidernet
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite存储数据
26、Web Crawler
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接数组开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回来的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
- 开发语言: Java
- 操作系统: 跨平台
- 授权协议: LGPL
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源
27、网络矿工
网站数据采集软件 网络矿工采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中唯一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
- 授权协议: BSD
- 开发语言: C# .NET
- 操作系统: Windows
特点:功能丰富,毫不逊色于商业软件
PHP爬虫
28、OpenWebSpider
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
- 授权协议: 未知
- 开发语言: PHP
- 操作系统: 跨平台
特点:开源多线程网络爬虫,有许多有趣的功能
29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引建立一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并能够索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它打造针对某一领域的垂直搜索引擎是最好的选择。
演示:http://www.phpdig.net/navigation.php?action=demo
- 授权协议: GPL
- 开发语言: PHP
- 操作系统: 跨平台
特点:具有采集网页内容、提交表单功能
30、ThinkUp
ThinkUp 是一个可以采集推特,facebook等社交网络数据的社会媒体视角引擎。通过采集个人的社交网络账号中的数据,对其存档以及处理的交互分析工具,并将数据图形化以便更直观的查看。
- 授权协议: GPL
- 开发语言: PHP
- 操作系统: 跨平台
github源码:https://github.com/ThinkUpLLC/ThinkUp
特点:采集推特、脸谱等社交网络数据的社会媒体视角引擎,可进行交互分析并将结果以可视化形式展现
31、微购
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了淘宝、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML就会做程序模板,免费开放下载,是广大淘客站长的首选。
授权协议: GPL
开发语言: PHP
操作系统: 跨平台
ErLang爬虫
32、Ebot
Ebot 是一个用 ErLang 语言开发的可伸缩的分布式网页爬虫,URLs 被保存在数据库中可通过 RESTful 的 HTTP 请求来查询。
- 授权协议: GPLv3
- 开发语言: ErLang
- 操作系统: 跨平台
github源代码:https://github.com/matteoredaelli/ebot
项目主页: http://www.redaelli.org/matteo/blog/projects/ebot
特点:可伸缩的分布式网页爬虫
Ruby爬虫
33、Spidr
Spidr 是一个Ruby 的网页爬虫库,可以将整个网站、多个网站、某个链接完全抓取到本地。
- 开发语言: Ruby
- 授权协议:MIT
特点:可将一个或多个网站、某个链接完全抓取到本地
本文由36大数据收集整理
原文地址:http://www.36dsj.com/archives/34383








给楼主补充一个,瑞雪采集云的开发平台。我用过这个企业级工具,非常好用。
用过python的爬虫框架scrapy,简单易学,非常好用,在此推荐给大家。使用scrapy的另一个好处是python里面有很多强大的文本挖掘、机器学习库,爬下资料的后续处理非常方便。
公司叫我产品研究爬虫,然而看了并没有什么用 🙂
😀
这也叫是干货?我看过
http://www.8kvv.com 上面干货很多特别全,建议看看 😎 😎 😎
爬虫工具?
试下这个,互联网工具推荐:
多用下载 http://www.duoyongxiazai.com
收藏了 ,很全面。
然而并会用。。
先收藏了,谢谢分享 🙄