
 起点课堂会员权益
起点课堂会员权益当AI实现多任务学习,它究竟能做什么?
本文介绍了AI多任务学习的定义、特征、优势和应用场景,表达AI多任务学习的发展需要向人类看齐。

提到AI领域的多任务学习,很多人可能一下子就想到通用人工智能那里了。通俗意义上的理解:就像《超能陆战队》里的大白这样一种护理机器人,既能进行医疗诊断,又能读懂人的情绪,还能像陪伴机器人一样完成各种复杂任务。
不过大白毕竟只是科幻电影当中的产物,现有的AI技术大多还处于单体智能的阶段,也就是一个机器智能只能完成一项简单任务。
工业机器人中做喷漆的就只能用来喷漆;做搬运的只能用来搬运;识别人脸的智能摄像头只能进行人脸。一旦人类戴上口罩,那就要重新调整算法。
当然,让单个智能体实现多种任务也是当前AI领域研究的热点。
最近,在强化学习和多任务学习算法上成绩最好的是DeepMind公司的一款名为Agent57的智能体——该智能体在街机学习环境(ALE)数据集所有57个雅达利游戏中实现了超越人类的表现。当然,多任务学习不止用在游戏策略上。
相对于现阶段的AI,我们人类才是能够进行多任务学习的高手。我们既不需要学习成千上万的数据样本就可以认识某类事物,我们又不用针对每一类事物都从头学起,而是可以触类旁通地掌握相似的东西。
AI在单体智能上面确实可以轻松碾压人类,比如可以识别成千上万的人脸;但AI在多任务学习上面就要向人类的这种通用能力看齐了。
一、什么是多任务学习
多任务学习(Multi-Task Learning,MTL),简单来说:就是一种让机器模仿人类学习行为的一种方法。
人类的学习方式本身就是泛化的,也就是可以从学习一种任务的知识迁移到其他的相关的任务上,而且不同的任务的知识技能可以相互帮助提升。
多任务学习涉及多个相关的任务同时并行学习,梯度同时反向传播,利用包含在相关任务训练信号中的特定领域的信息来改进泛化能力。
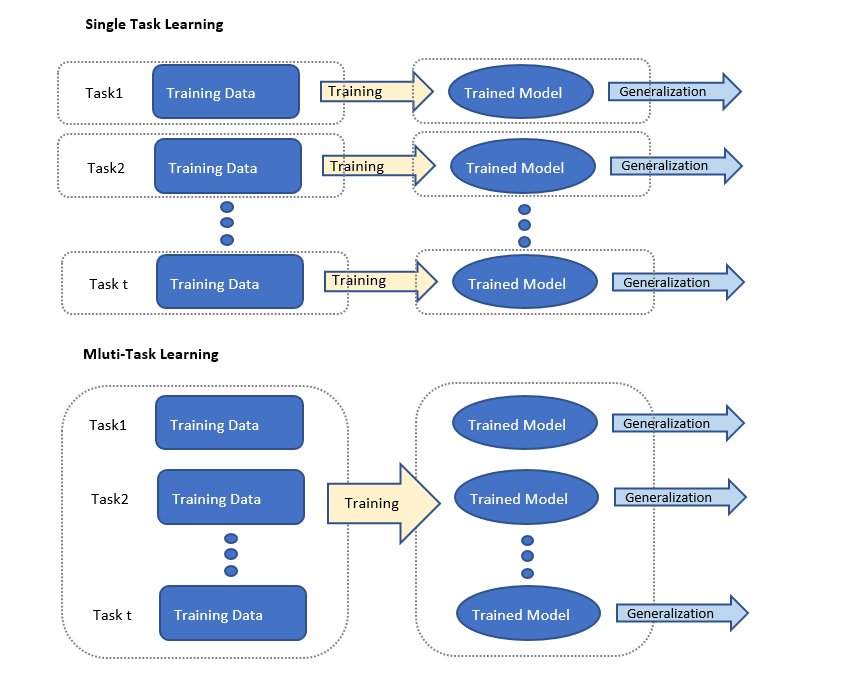
(单任务学习和多任务学习的模型对比示意)
做一个形象的类比:我们知道人类不如虎豹擅跑,不如猿猴擅爬,也不如鲸豚擅游;但是人类是唯独可以同时做到奔跑、攀援和游泳的。用在人工智能和人类智能上,我们通常认为AI更擅于在单一任务上表现优异并超越人类专家,如AlphaGo一样;而人类则可能在各种任务上都能胜任。
MTL正是要让人工智能来实现人类的这种能力:通过在多个任务的学习中,共享有用的信息来帮助每个任务的学习都得到提升的一个更为准确的学习模型。
这里需要注意的是多任务学习和迁移学习的区别:迁移学习的目标是将知识从一个任务迁移到另一个任务,其目的是使用一个或多个任务来帮助另一个目标任务提高,而 MTL 则是希望多个任务之间彼此能相互帮助提升。
二、了解MTL
1. MTL的两个特征
1)是任务具有相关性。
任务的相关性是说几种任务的完成模式是存在一定的关联性的,比如,在人脸识别中,除了对人脸特征的识别,还可以进行性别、年龄的估算识别,或者,在不同的几类游戏中识别出共通的一些规则,这种相关性会被编码进 MTL 模型的设计当中。
2)是任务有不同的分类。
MTL的任务分类主要包括监督学习任务、无监督学习任务、半监督学习任务、主动学习任务、强化学习任务、在线学习任务和多视角学习任务,因此不同的学习任务对应于不同的MTL设置。
共享表示和特征泛化.
2. 理解MTL优势的两个关键
1)为什么在一个神经网络上同时训练多个任务的学习效果可能会更好?
我们知道,深度学习网络是具有多个隐层的神经网络,逐层将输入数据转化成非线性的、更抽象的特征表示。
而各层的模型参数不是人为设定的,而是给定学习器的参数后在训练过程中学到的——这给了多任务学习施展拳脚的空间,具备足够的能力在训练过程中学习多个任务的共同特征。
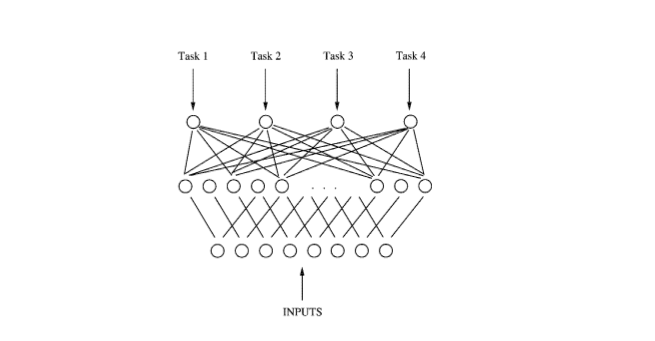
例如在上面的MTL的网络中,后向传播并行地作用于4个输出。由于4个输出共享底部的隐层,这些隐层中用于某个任务的特征表示也可以被其他任务利用,促使多个任务共同学习。多个任务并行训练并共享不同任务已学到的特征表示,这样多任务信息就有助于共享隐层学到更好的内部表示,这成为多任务学习的关键。
2)那么MTL是如何产生效果的?
MTL的方法中引入了归纳偏置(inductive bias)。
归纳偏置有两个效果,一个是互相促进,可以把多任务模型之间的关系看作是互相先验知识,也称归纳迁移(inductive transfer)。
有了对模型的先验假设,可以更好的提升模型的效果;另外一个效果是约束作用,借助多任务间的噪声平衡以及表征偏置来实现更好的泛化性能。
首先,MTL的引入可以使得深度学习减少对大数据量的依赖。少量样本的任务可以从大样本量的任务中学习一些共享表示,以缓解任务数据的稀疏问题。
其次,多任务直接的相互促进,体现在:
- 多个模型特性互相弥补,比如在网页分析模型中,改善点击率预估模型也同时能促进转化模型学习更深层的特征;
- 注意力机制,MTL可以帮助训练模型专注在重要特征上面,不同的任务将为这种重要特征提供额外证据;
- 任务特征的“窃听”,也就是MTL可以允许不同任务之间相互“窃听”对方的特征,直接通过“提示”训练模型来预测最重要的特征。
再次,多任务的相互约束可以提高模型的泛化性。
一方面:多任务的噪声平衡。多任务模型的不同噪声模式可以让多个任务模型学到一般化的表征,避免单个任务的过度拟合,联合学习能够通过平均噪声模式获得更好的表征;
另一方面:表征偏置。MTL的表征偏好会造成模型偏差;但这将有助于模型在将来泛化到新任务。在任务同源的前提下,可以通过学习足够大的假设空间,在未来某些新任务中得到更好的泛化表现。
3. 行业场景落地,MTL如何解决现实问题
由于MTL具有减少大数据样本依赖和提高模型泛化表现的优势,MTL正被广泛应用到各类卷积神经网络的模型训练当中。
首先,多任务学习可以学到多个任务的共享表示,这个共享表示具有较强的抽象能力,能够适应多个不同但相关的目标,通常可以使主任务获得更好的泛化能力。
其次,由于使用共享表示,多个任务同时进行预测时,减少了数据来源的数量以及整体模型参数的规模,使预测更加高效。
1)MTL在诸如目标识别、检测、分割等场景为主的计算机视觉的应用:
脸部特征点检测:因为脸部特征可能会受到遮挡和姿势变化等问题的影响,通过MTL能够提高检测健壮性,而不是把检测任务视为单一和独立的问题。
多任务学习希望把优化脸部特征点检测和一些不同但细微相关的任务结合起来,比如头部姿势估计和脸部属性推断。
脸部特征点检测不是一个独立的问题,它的预测会被一些不同但细微相关的因素影响。比如一个正在笑的孩子会张开嘴,有效地发现和利用这个相关的脸部属性将帮助更准确地检测嘴角。
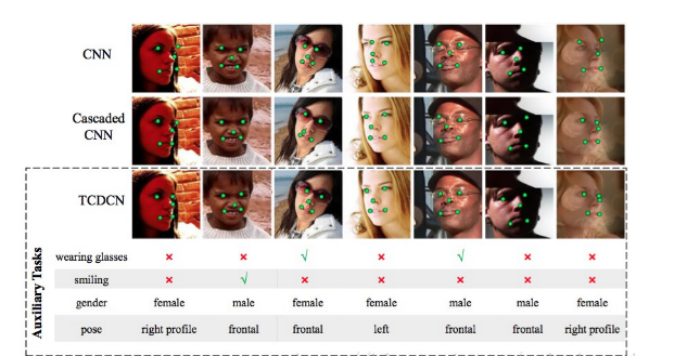
如上图人脸特征点检测(TCDCN)模型,除了检测特征点任务,还有识别眼镜、笑脸、性别和姿态这四个辅助任务;通过与其它网络的对比,可以看出辅助任务使主任务的检测更准确。
MTL在不同领域有不同应用,其模型各不相同,解决的应用问题也不尽相同,但在各自的领域都存在着一些特点。
除上面介绍的计算机视觉领域,还有像生物信息学、健康信息学、语音、自然语言处理、网络垃圾邮件过滤、网页检索和普适计算在内的很多领域,都可以使用 MTL 来提升各自的应用的效果和性能。
比如:在生物信息学和健康信息学中,MTL被应用于识别治疗靶点反应的特征作用机制,通过多个群体的关联性分析来检测因果遗传标记;以及通过稀疏贝叶斯模型的自动相关性特征,来预测阿尔茨海默病的神经成像测量的认知结果。
2)在语音处理上的应用
2015年,有研究者在国际声学、语音与信号处理会议(ICASSP)上分享了一篇《基于多任务学习的深度神经网络语音合成》的论文,提出一种多任务叠层深层神经网络。
它由多个神经网络组成——前一个神经网络将其最上层的输出作为下一个神经网络的输入,用于语音合成,每个神经网络有两个输出单元,共享两个任务之间的隐藏层,一个用于主任务,另一个用于辅助任务,从而更好地提升语音合成的准确度。
3)在网络Web应用程序中
MTL可以用于不同任务共享一个特征表示,学习web搜索中的排名提升;MTL可以通过可扩展分层多任务学习算法,用于找到广告中转换最大化的层次结构和结构稀疏性等问题。
总体上来说,在这些MTL的应用领域中,特征选择方法和深度特征转换方法得到研究者的普遍应用。
因为前者可以降低数据维数并提供更好的可解释性;而后者通过学习强大的特征表示可以获得良好的性能。
MTL正在越来越多的领域作为一种提高神经网络学习能力的手段被广泛应用——这其实正是AI在众多行业实际应用中的常态化场景。
我们可以最终溯源反思一下:人类之所以能够具有多任务学习的灵活应用的能力,恰恰是因为所处环境正是处在多特征、多噪声的状况之下。这样必然要求我们人类必须能够触类旁通地进行先验的学习能力的迁移。
而如果人工智能仅仅停留在单体智能上面,为每一类知识或任务都建立一套单独的模型,最后可能仍然只是一套“人工智障”的机械系统,闹出“白马非马”这类的笑话来。
当AI未来真正既能在融会贯通的方面像人类一样熟练,又能克服人类认知带宽和一些认知偏见,那通向AGI的前路才可能迎来一丝曙光。
当然这条路还相当遥远。
作者:藏狐;公众号:脑极体
本文由 @脑极体 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


