
 起点课堂会员权益
起点课堂会员权益AI产品经理必懂的硬知识(一):应用领域篇
文章主要针对AI目前在各个比较热门领域的应用现状展开了梳理与分析,包含:计算机视觉、语音交互、自然语言处理和典型AI场景四个方面,与大家分享。

大家好,我是方舟,接下来我会出一个硬核知识系列,共三篇《AI产品经理必懂的硬知识》,从应用领域、常见概念与算法、自我进阶三个方面去阐述,这个系列算是榨干了我多个笔记。第一篇咱们就来谈谈目前各个主流应用领域的现状吧。有读者反应我的文章过于“干货”,实在太长,要分好几次看完,列个提纲吧。
一、计算机视觉(CV)
二、语音交互
(1)语音识别(ASR)
(2)语音合成(TTS)
三、自然语言处理(NLP)
四、典型AI场景
(1)智能机器人
(2)无人驾驶
(3)人脸识别(非手机端)
(4)视觉设计(手机端)
(5)自动文字编辑
一、计算机视觉(CV)
计算机视觉是一门研究如何使机器“看”的科学,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉的应用,是使用计算机及相关设备对生物视觉的一种模拟,对采集的图片或视频进行处理从而获得相应场景的三维信息,让计算机具有对周围世界的空间物体进行传感、抽象、判断的能力。
计算机视觉在现实场景中应用价值主要体现在可以利用计算机对图像和视频的识别能力,替代部分人力工作,节省人力成本并提升工作效率。传统的计算机视觉基本遵循图像预处理、提取特征、建模、输出的流程,不过利用深度学习,很多问题可以直接采用端到端,从输入到输出一气呵成。
1. 研究内容
- 实际应用中采集到的图像的质量通常都没有实验室数据那么理想,光照条件不理想,采集图像模糊等都是实际应用中常见的问题。所以首先需要校正成像过程中,系统引进的光度学和几何学的畸变,抑制和去除成像过程中引进的噪声,这些统称为图像的恢复。
- 对输入的原始图像进行预处理,这一过程利用了大量的图像处理技术和算法,如:图像滤波、图像增强、边缘检测等,以便从图像中抽取诸如角点、边缘、线条、边界以及色彩等关于场景的基本特征;这一过程还包含了各种图像变换(如:校正)、图像纹理检测、图像运动检测等。
- 根据抽取的特征信息把反映三维客体的各个图象基元,如:轮廓、线条、纹理、边缘、边界、物体的各个面等从图象中分离出来,并且建立起各个基元之间的拓朴学上的和几何学上的关系——称之基元的分割和关系的确定。
- 计算机根据事先存贮在数据库中的预知识模型,识别出各个基元或某些基元组合所代表的客观世界中的某些实体——称之为模型匹配,以及根据图象中各基元之间的关系,在预知识的指导下得出图象所代表的实际景物的含义,得出图象的解释或描述。
2. 瓶颈
- 目前在实际应用中采集到的数据还是不够理想,光照条件、物体表面光泽、摄像机和空间位置变化都会影响数据质量,虽然可以利用算法弥补,但是很多情况下信息缺失无法利用算法来解决。
- 在一幅或多幅平面图像中提取深度信息或表面倾斜信息并不是件容易的事,尤其是在灰度失真、几何失真还有干扰的情况下求取多幅图像之间的对应特征更是一个难点。除了得到物体的三维信息外,在现实世界里,物体间相互遮挡,自身各部位间的遮挡使得图像分拆更加复杂。
- 预知识设置的不同也使得同样的图像也会产生不同的识别结果,预知识在视觉系统中起着相当重要的作用。在预知识库中存放着各种实际可能遇到的物体的知识模型,和实际景物中各种物体之间的约束关系。计算机的作用是根据被分析的图象中的各基元及其关系,利用预知识作为指导,通过匹配、搜索和推理等手段,最终得到对图象的描述。在整个过程中预知识时刻提供处理的样板和证据,每一步的处理结果随时同预知识进行对比,所以预知识设置会对图像识别结果产生极大影响。
由于笔者本人是专门做AI CV这个方向产品的,因此未来的文章中关于CV的知识以及CV实际项目都会涉及很多。在之后的文章里针对视觉识别,特别是视觉识别里面的明星应用人脸识别,我会很深入的去探讨。其中人脸识别中所涉及的很多AI产品实现细节的拆解,从成像、预处理、算力估算到检测、多目标、跟踪、分割、识别、算法精度测试模块,如果弄懂弄透,再将这一块体系延伸到车辆、动物等其他视觉类项目,基本原理都是类似的,可谓一通百通。
二、语音交互
语音交互也是非常热门的方向之一,其实语音交互整个流程里包含语音识别、自然语言处理和语音合成。自然语言处理很多时候是作为单独的一个领域来研究的,所以这里暂且不展开,本文也将单独介绍自然语言处理,所以此处只介绍语音识别和语音合成。
语音交互的最佳应用场景便是眼睛不方便看,或者手不方便操作的时候。“不方便看”比较典型的场景便是智能车载,“不方便操作”比较典型的场景便是智能音箱,这也是目前比较火的两个细分方向。
一个完整的语音交互基本遵循下图的流程:
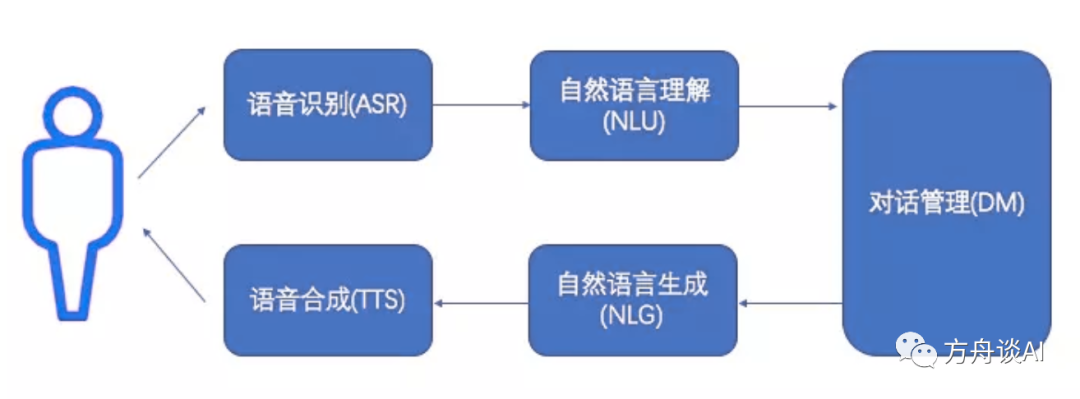
经典语音交互用例
1. 语音识别(ASR)
(1)研究内容
语音识别的输入是声音,属于计算机无法直接处理的模拟信号,所以需要将声音转化成计算机能处理的文字信息。传统的识别方式需要通过编码将其转变为数字信号,并提取其中的特征进行处理。
传统方式的声学模型一般采用隐马尔可夫模型(HMM),处理流程是语音输入——编码(特征提取)——解码——输出。
还有一种“端到端”的识别方式,一般采用深度神经网络(DNN),这种方式的声学模型的输入通常可以使用更原始的信号特征(减少了编码阶段的工作),输出也不再必须经过音素等底层元素,可以直接是字母或者汉字。
在计算资源与模型的训练数据充足的情况下,“端到端”方式往往能达到更好的效果。目前的语音识别技术主要是通过DNN实现的。语音识别的效果一般用“识别率”,即识别文字与标准文字相匹配的字数与标准文字总字数的比例来衡量。目前中文通用语音连续识别的识别率最高可以达到97%。
(2)衍生研究内容
- 麦克风阵列:在家庭、会议室、户外、商场等各种环境下,语音识别会有噪音、混响、人声干扰、回声等各种问题。在这种需求背景下可以采用麦克风阵列来解决。麦克风阵列由一定数目的声学传感器(一般是麦克风)组成,用来对声场的空间特性进行采样并处理的系统,可以实现语音增强、声源定位、去混响、声源信号提取/分离。麦克风阵列又分为:2麦克风阵列、4麦克风阵列、6麦克风阵列、6+1麦克风阵列。随着麦克风数量的增多,拾音的距离,噪声抑制,声源定位的角度,以及价格都会不同,所以要贴合实际应用场景来找到最佳方案。
- 远场语音识别:解决远场语音识别需要结合前后端共同完成。前端使用麦克风阵列硬件,解决噪声、混响、回声等带来的问题,后端则利用近场远场的声学规律不同构建适合远场环境的声学模型,前后端共同解决远场识别的问题。
- 语音唤醒:通过关键词唤醒语音设备,通常都是3个音节以上的关键词。例如:嘿Siri、和亚马逊echo的Alexa。语音唤醒基本是在本地进行的,必须在设备终端运行,不能切入云平台。因为一个7×24小时监听的设备要保护用户隐私,只能做本地处理,而不能将音频流联网进行云端处理。语音唤醒对唤醒响应时间、功耗、唤醒效果都有要求。
- 语音激活检测:判断外界是否有有效语音,在低信噪比的远场尤为重要。
2. 语音合成(TTS)
(1)研究内容
是将文字转化为语音(朗读出来)的过程,目前有两种实现方法,分别是:拼接法和参数法。
- 拼接法是把事先录制的大量语音切碎成基本单元存储起来,再根据需要选取拼接而成。这种方法输出语音质量较高,但是数据库要求过大。
- 参数法是通过语音提取参数再转化为波形,从而输出语音。这种方法的数据库要求小,但是声音不可避免会有机械感。
DeepMind早前发布了一个机器学习语音生成模型WaveNet,直接生成原始音频波形,可以对任意声音建模,不依赖任何发音理论模型,能够在文本转语音和常规的音频生成上得到出色的结果。
(2)瓶颈
个性化TTS数据需求量大,在用户预期比较高的时候难满足。需要AI产品经理选择用户预期不苛刻的场景,或者在设计时管理好用户预期。
三、自然语言处理(NLP)
1. 研究内容
自然语言处理是一门让计算机理解、分析以及生成自然语言的学科,是理解和处理文字的过程,相当于人类的大脑。NLP是目前AI发展的核心瓶颈。整个NLP包括了句法语义分析、信息抽取、文本挖掘、机器翻译、信息检索、问答系统、对话系统等范畴。
NLP大概的研究过程是:研制出可以表示语言能力的模型——提出各种方法来不断提高语言模型的能力——根据语言模型来设计各种应用系统——不断地完善语言模型。自然语言理解和自然语言生成都属于自然语言理解的概念范畴。
自然语言理解(NLU)模块,着重解决的问题是单句的语义理解,对用户的问题在句子级别进行分类,明确意图识别(Intent Classification);同时在词级别找出用户问题中的关键实体,进行实体槽填充(Slot Filling)。
一个简单的例子,用户问“我想吃冰激凌”,NLU模块就可以识别出用户的意图是“寻找甜品店或超市”,而关键实体是“冰激淋”。有了意图和关键实体,就方便了后面对话管理模块进行后端数据库的查询或是有缺失信息而来继续多轮对话补全其它缺失的实体槽。
自然语言生成(NLG)模块是机器与用户交互的最后一公里路,目前自然语言生成大部分使用的方法仍然是基于规则的模板填充,有点像实体槽提取的反向操作,将最终查询的结果嵌入到模板中生成回复。手动生成模板之余,也有用深度学习的生成模型通过数据自主学习生成带有实体槽的模板。
2. 应用场景
自然语言处理作为CUI(Conversational User Interface,对话式交互)中非常重要的一部分,只要是CUI的应用场景都需要自然语言处理发挥作用。除此之外,机器翻译、文本分类也都是自然语言处理的重要应用领域。但是自然语言处理的应用也是被吐槽最多的,经典的就是“智能客户不仅没增加效率,还降低了效率”,相比CV,NLP这一块带给人的直观震撼目前来看确实要小很多。
3. 瓶颈
(1)词语实体边界界定
自然语言是多轮的,一个句子不能孤立的看,要么有上下文,要么有前后轮对话,而正确划分、界定不同词语实体是正确理解语言的基础。目前的深度学习技术,在建模多轮和上下文的时候,难度远远超过了如语音识别、图像识别的一输入一输出的问题。所以语音识别或图像识别做的好的企业,不一定能做好自然语言处理。
(2)词义消歧
词义消歧包括多义词消歧和指代消歧。多义词是自然语言中非常普遍的现象,指代消歧是指正确理解代词所代表的⼈或事物。例如:在复杂交谈环境中,“他”到底指代谁。词义消歧还需要对文本上下文、交谈环境和背景信息等有正确的理解,目前还无法对此进行清晰的建模。
(3)个性化识别
自然语言处理要面对个性化问题,自然语言常常会出现模棱两可的句子,而且同样一句话,不同的人使用时可能会有不同的说法和不同的表达。这种个性化、多样化的问题非常难以解决。
(4)NLP技术体系
这里也总结了整个自然语言处理的技术体系,如下所示:
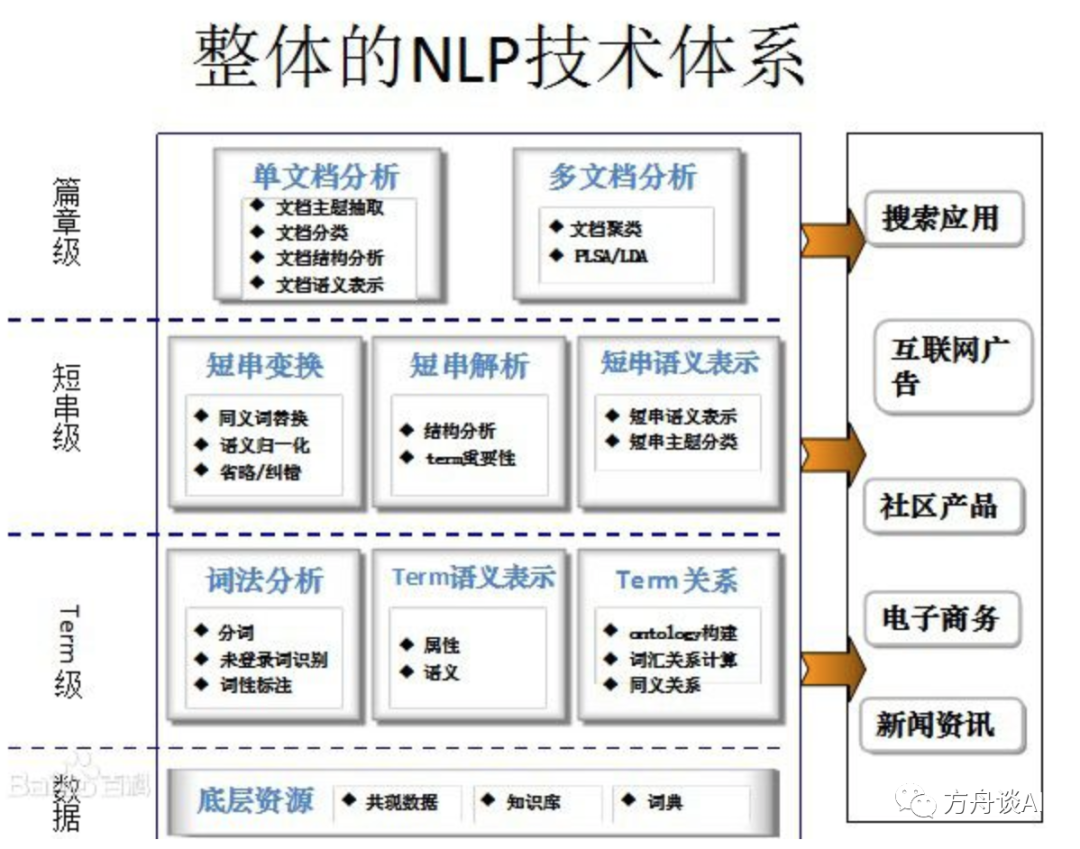
NLP技术体系
(5)产品体验
自然语言识别:讯飞输入法(PC软件和手机APP),讯飞语记(手机APP),百度输入法PC软件和手机APP)
远场语音识别(智能音箱):亚马逊Echo,谷歌Home,苹果HomePod
机器翻译:google翻译
多轮对话机器人:苹果siri,微软小冰,百度度秘,小i,小黄鸡,图灵机器人
(6)推荐阅读材料
- 初学者如何查阅自然语言处理(NLP)领域学术资料:http://blog.sina.com.cn/s/blog_574a437f01019poo.html
- 语音识别技术原理:https://www.zhihu.com/question/20398418
- 科大讯飞新一代语音识别系统大揭秘:http://news.imobile.com.cn/articles/2015/1231/163325.shtml
- 自然语言处理(NLP)的基本原理及应用:http://blog.csdn.net/inter_peng/article/details/53440621
- siri工作原理详解、siri技术解析:http://www.infoq.com/cn/articles/zjl-siri/
- CSDN自然语言处理博客文章:http://so.csdn.net/so/search/s.do?q=%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86&t=blog&o=&s=&l=
四、典型AI场景
刚才说到了,目前AI的研究主流三大领域:计算机视觉、语音交互和自然语言处理,相当于是人工职能的视觉、听觉和大脑。最后我再分别讲一下目前市场很火热的几个场景,这些细分场景也是基于上述三大领域的交叉来实现的,包括智能机器人、人脸识别、移动端图片处理、自动编辑等。
1. 智能机器人
以分拣机器人为例,分拣机器人(Sorting robot),是一种具备了传感器、物镜和电子光学系统的机器人,可以快速进行货物分拣。电商平台的蓬勃发展,自动分拣机器人已得了广泛的应用。亚马逊,阿里巴巴和京东均已将智能分拣机器人应用在货物分拣工作中,极大节省人工成本,号称一小时可以完成18000单的分拣工作。延伸阅读如下:
- 工业机器人分拣技术的实现:https://wenku.baidu.com/view/a2da4ed17f1922791688e8cf.html
- 快递分拣无人化有哪些关键技术?:http://baijiahao.baidu.com/s?id=1572495116614945&wfr=spider&for=pc
- 物流机器人市场发展迅速,分拣机器人的工作原理介绍:http://www.xianjichina.com/news/details_45519.html
2. 自动驾驶
自动驾驶汽车(Autonomous vehicles;Self-piloting automobile )又称无人驾驶汽车、电脑驾驶汽车、或轮式移动机器人,是一种通过电脑系统实现无人驾驶的智能汽车。自动驾驶汽车依靠人工智能、视觉计算、雷达、监控装置和全球定位系统协同合作,让电脑可以在没有任何人类主动的操作下,自动安全地操作机动车辆。
2017年7月6日,百度AI开发者大会现场连线视频中“李彦宏乘坐无人驾驶汽车上北京五环”的消息刷爆了朋友圈,近期一条自动驾驶大巴深圳上路的新闻刷爆朋友圈,由海梁科技携手深圳巴士集团、深圳福田区政府、安凯客车、东风襄旅、速腾聚创、中兴通讯、南方科技大学、北京理工大学、北京联合大学联合打造的自动驾驶客运巴士——阿尔法巴(Alphabus)正式在深圳福田保税区的开放道路进行线路的信息采集和试运行。让这个焦虑的世界又多了一批焦虑的人–公交车司机。
沃尔沃根据自动化水平的高低区分了四个无人驾驶的阶段:驾驶辅助、部分自动化、高度自动化、完全自动化:
- 驾驶辅助系统(DAS):目的是为驾驶者提供协助,包括提供重要或有益的驾驶相关信息,以及在形势开始变得危急的时候发出明确而简洁的警告。如“车道偏离警告”(LDW)系统等。
- 部分自动化系统:在驾驶者收到警告却未能及时采取相应行动时能够自动进行干预的系统,如“自动紧急制动”(AEB)系统和“应急车道辅助”(ELA)系统等。
- 高度自动化系统:能够在或长或短的时间段内代替驾驶者承担操控车辆的职责,但是仍需驾驶者对驾驶活动进行监控的系统。
- 完全自动化系统:可无人驾驶车辆、允许车内所有乘员从事其他活动且无需进行监控的系统。这种自动化水平允许乘客从事计算机工作、休息和睡眠以及其他娱乐等活动。
这个领域的相关公司国外是家喻户晓的特斯拉,国内做无人驾驶最不错的是百度。百度无人驾驶车项目于2013年起步,由百度研究院主导研发,其技术核心是“百度汽车大脑”,包括高精度地图、定位、感知、智能决策与控制四大模块。
其中,百度自主采集和制作的高精度地图记录完整的三维道路信息,能在厘米级精度实现车辆定位。同时,百度无人驾驶车依托国际领先的交通场景物体识别技术和环境感知技术,实现高精度车辆探测识别、跟踪、距离和速度估计、路面分割、车道线检测,为自动驾驶的智能决策提供依据。
特斯拉(Tesla),是一家美国电动车及能源公司,产销电动车、太阳能板、及储能设备。Tesla 的计划是通过不断迭代辅助驾驶技术,使之最后升级成为无人驾驶。停留在辅助驾驶阶段时,需要驾驶员。驾驶员有完全控制权,可以反制或取消辅助驾驶的行为,完全对安全负责。
Google 无人驾驶是一步到位的,基本原则就是不需要人类干预,没有驾照的人也可以单独上车,上车就睡,乘客不承担责任。乐视网汽车频道于2010年8月20日正式上线,依托乐视网视频方面的优势,将丰富、精彩、实用的汽车内容以视频的形式呈现给广大的网友,内容涵盖新车报道、行业新闻、试乘试驾、维修保养、原创汽车视频、车模风采、消费维权、汽车赛事等栏目·精彩的视频让网友轻松享受汽车行业的视听盛宴。不幸的是无人驾驶和智慧出行是趋势,但是2017年并不是其爆发点,庞大的乐视帝国因为供血无人汽车崩盘了。
延伸阅读包括:
- 自动驾驶汽车涉及哪些技术?:https://www.zhihu.com/question/24506695
- 什么是汽车自动驾驶,如何通俗易懂地理解其功能及原理?:https://www.zhihu.com/question/54647152
- 干货!激光雷达技术和自动驾驶技术原理分析:http://www.21ic.com/app/auto/201705/721051.htm
- 自动驾驶技术原理介绍和未来的趋势如何:http://www.elecfans.com/xinkeji/595666_2.html
- Google 无人驾驶介绍Ted视频,有中文字幕:https://www.ted.com/talks/chris_urmson_how_a_driverless_car_sees_the_road
- 黄仁勋访谈 Elon Musk 提到Tesla 辅助驾驶原理https://youtu.be/uxFeUOstyKI
- 人工智能在自动驾驶技术中的的应用:https://wenku.baidu.com/view/277ffb5cbb1aa8114431b90d6c85ec3a87c28baa.html
3. 人脸识别技术(非手机端)
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部的一系列相关技术,通常也叫做人像识别、面部识别。2017年被全面应用在手机解锁中。人脸识别系统主要包括四个组成部分,分别为:人脸图像采集及检测、人脸图像预处理、人脸图像特征提取以及匹配与识别。
人脸识别技术产品已广泛应用于金融、司法、军队、公安、边检、政府、航天、电力、工厂、教育、医疗及众多企事业单位等领域。随着技术的进一步成熟和社会认同度的提高,人脸识别技术将应用在更多的领域。而这个行业涌现出了像湖南视觉伟业、北京旷视科技、北京商汤科技等一批优秀的企业。
延伸阅读包括:
人脸识别系统原理:
- http://blog.csdn.net/zergskj/article/details/43374003
- 人脸识别系统的原理与发展:https://wenku.baidu.com/view/0c56a7bf3186bceb19e8bbf9.html
- 人脸识别主要算法原理:http://blog.csdn.net/liulina603/article/details/7925170
- 简话人工智能 | 2分钟看懂人脸识别的原理:http://baijiahao.baidu.com/s?id=1568919427558010&wfr=spider&for=pc
- 人脸识别技术公司十大排名:http://www.elecfans.com/consume/571535.html?1509154910
4. 视觉设计(手机端)
自拍类APP越来越多,结合人脸识别技术,可以在人的面部或头部添加耳朵,鼻子,王冠等道具,识别锁定人的面部或肢体,保证道具可以自动随着人的移动而移动。
Instagram可以实现自动识别一张图中设计元素,赋予另外一张图作为滤镜,可以设计出效果超赞的设计效果,把一张普普通的风景照变成梵高风格的油画。
国内包括视觉设计类AI的APP遍布我们的手机之中,美拍、SNOW相机、Faceu激萌,B612、羞兔、IN、美咖相机、LINE camera等手机APP支持人脸自动识别,猫耳朵、兔耳朵、狐狸耳朵、猪耳朵随你挑。
延伸阅读包括:
- A Neural Algorithm of Artistic Style:https://arxiv.org/abs/1508.06576
- 自己搭建一个ostagram:https://zhuanlan.zhihu.com/p/22704865
5. 文字自动编辑
机器人写稿已经不是什么新鲜事了,早两年国外还出过专门的资讯APP,内容全部由机器抓取并生成短消息,主要集中在体育、财经等领域。很多海外的传统媒体都已经运用上了机器人写作,因为人工智能可以监测网络热词,所以比起对热点时间的敏感度,机器人的反应更灵敏,响应速度更快。
机器人知道什么会成为热点,也能第一时间把热点传递给受众。在媒体行业,AI写稿是未来的一个趋势,特别是类似财报、体育快讯、股市消息等结构化、标准化的以数据为主信息,人工处理反而不如AI精准、高效。
这里推荐试用的产品包括腾讯的Dreamwriter、百度的写作大脑、新华社的“快笔小新”、今日头条的“xiaomingbot”。
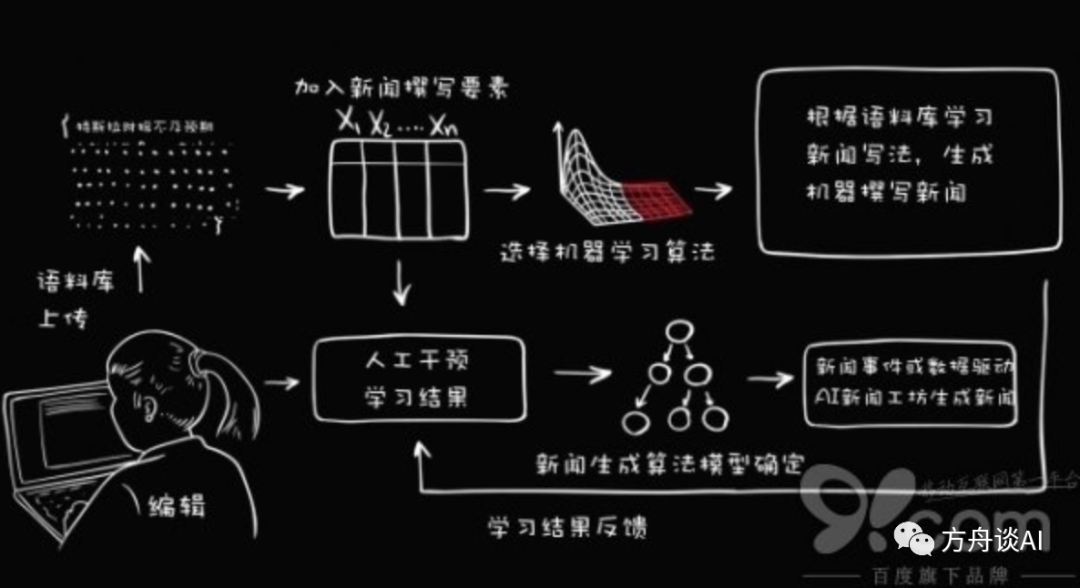
以百度产品为例的文字自动编辑流程
延伸阅读包括:
- 纽约时报的“新媒体运营总监”,是一个叫Blossom的机器人:http://www.leiphone.com/news/201508/Ze9HOBijDnwIQIPE.html
- EditorAI:用人工智能技术辅助记者编辑写稿:http://news.91.com/mip/s5947c56e593b.html
- 人工智能帮你写论文,总有一款适合你!http://www.sohu.com/a/119470301_107743
以上,就是我目前总结的AI在各个领域的大体应用现状,基本是比较全了,之后围绕着各个技术点和产品设计,还将继续深入的抽丝剥茧分享下去,敬请期待。
作者:方舟谈AI,AI产品经理,公众号&知乎:方舟谈AI
本文由 @方舟谈AI 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。










大佬可否加微信请教下
很全乎,谢谢亲。期待后续。
总结的不错,辛苦了,已打赏
感谢 这篇比较泛 后面会越来越细