
 起点课堂会员权益
起点课堂会员权益如何结合分析需求,设计数据埋点?
通过数据埋点,我们能够看到产品设计与功能在数据上的反馈,并通过分析其中的数据特征驱动业务发展。

做了快3年的产品经理,相比3年前刚入行的时,现在的企业对产品岗位的要求逐渐趋于理性化。产品经理不再是“靠着一个点子就能改变世界”的玄学职位,客观的数据与理性的分析越来越受到大家的重视。
但就我亲身感受而言,这种改变还不够剧烈:一方面体现在多数人还在“靠感觉、靠经验”做感性产品,而非理性产品;另一方面是已经意识到数据重要性的大部分产品同学,在这种大环境下,很难有机会接触到系统化的学习与锻炼机会。
鉴于此,这里想通过文章分享我对于数据分析的一些理解和感受。鉴于涉及内容太多,这里先说开头:关于数据埋点的那点事。
一、那什么是埋点呢?
一句话概括:埋点就是一小段上报事件的代码。简单来说,就是用户在产品中产生某个行为之后,设备或者服务器把这个行为以及有关的一切信息都记录下来。
二、为什么埋点很重要?
先一起设想个常见场景:
今天,你辛苦做的积分商城终于上线和亲爱的用户见面了。出于对自己工作的负责态度,你觉得很有必要看看效果,便决定:先看看今天有多少人用了这个功能吧!于是跑去研发同学那,腆着脸让研发帮你看看,于是……
“今天?你这个今天是怎么定义的?给个具体的时间吧”
“什么算是人?IMEI/IDFA吗?还是user_id?又或者其他标准?你先给个定义”
“这个‘多少’是个啥意思?UV还是PV?”
“大哥,怎么算用?点入口吗?还是进到落地页?又或者领了积分才算?”
“Oh,舍特,开发的时候没埋点”
……
从上面的场景中,我相信大家一定能切实体验到这种被研发灵魂拷问N连击的痛苦。因此,如果我们仅仅知道要采集哪些数据,仅仅掌握一些数据分析的技巧,但却不清楚这些数据是如何收集和统计到的,那么我们对于数据的应用不仅会处处受限,更会丧失对数据的敏感度。
从另一个角度来说,埋点也是数据分析的完整路径中必不可少的第一步。在一些大中型公司,这份工作往往会由独立的数据产品经理负责,但对于市场上的大部分中小型公司,产品经理就要亲自上阵,负责埋点的定义和管理了。
到这里,大家应该就会明白两个点:
- 什么是“埋点”?“埋点”是互联网产品收集数据的一种基础且被广泛应用的方法。
- 为什么要“收集数据”?因为我们要获取数据支撑后续的数据分析,并最终驱动业务发展。
三、怎么理清需要的埋点?
完成了对埋点的必要性说明,以及基本概念定义后,下面分两部分详细介绍一下具体的落地实施方法:
- 第一部分:确定并梳理清楚需要哪些埋点
- 第二部分:形成埋点文档记录并同步
第一部分:确定并梳理清楚需要哪些埋点
梳理埋点的思路和梳理产品方案的思路一致,我们首先要做的,是明确你的需求是什么,这是定性的层面;接着是明确能衡量需求的数据指标是什么,这是定量的层面;最后才是确定能通过哪些埋点收集到需要的数据,从而计算指标、衡量需求。逻辑关系如下图:
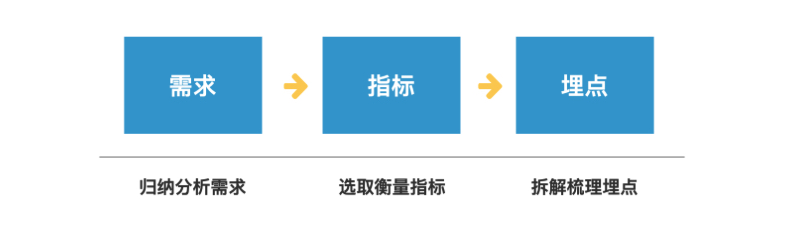
1.首先是归纳需求。埋点需求一般有两个来源:产品需求的衡量指标+业务部门的分析需求。通过这个步骤,我们可以知道收集数据的目的是什么。
2.接着是选取指标。明确了需求之后,我们就需要选取能够衡量需求效果的数据指标,比如页面转化率、功能留存率、访问人数、访问频次分布等等。
3.最后是梳理埋点。梳理埋点这一步最重要的是想清楚三个关键问题:
- 需要收集哪些数据以能够计算上一步选取的指标
- 触发数据收集的时机是什么时候
- 需要定义埋点的哪些必要属性(即需要收集哪些维度的数据)
归纳需求和选取指标这两步,单独拎出来是很大的一个内容,这里就不做展开了。这里的重点是帮大家搞懂埋点,因此着重说说最后一步的“梳理埋点”:
a.首先是确定收集哪些数据以计算需求指标
这里提一个小思路:把指标按照数学里的加减乘除混合运算,拆解成不能再拆的单位变量,那这个单位变量,就是我们要通过埋点收集的数据了,比如“访问页面的独立用户数”。
b.其次是数据收集的时机
这里举个小例子抛砖引玉:“访问页面的独立用户数”这个单位变量中,应该在什么时机收集页面的访问数据呢?答案是都可以,你可以定义为“点击页面入口”就算访问并开始收集,也可以定义“页面加载完毕”再收集,更可以定义为“页面加载完毕且停留页面内至少5秒钟”才收集。没有正确答案,只有最能够帮助你衡量需求效果的方案。
c.最后,还要设计出既全面又多维的属性和属性值,来帮助从多个维度描述一个埋点,以支撑后续各种角度的分析需求。
埋点属性是决定分析深度和广度的关键因素,关于如何设计出完善的埋点属性,这里借用最经典的一套思维模型就可以解决:4W1H,包括Who、When、Where、How、What,即:【某个用户在某个时间点、某个地方以某种方式完成了某个具体的事情】
关于埋点里的“事件”、“属性”和“属性值”,这里举个例子帮助大家理解:
比如你想分析“买衣服”这件事,于是决定要收集相关数据来完成分析。
那么,你要分析的“买衣服”就是一个事件;衣服的颜色、大小、款式和价格分别从四个维度描述了这件衣服,这四个维度就是“买衣服”这个事件的四个属性;
拿其中衣服大小的属性来说,有M号、L号、XL号等,这些尺码就是描述“买衣服”这个事件中,衣服大小属性的不同属性值。
大家在进行埋点设计时一定要弄清楚这种层级关系。
关于这几点的概念,大家如果百度一下,也能清晰知道:
事件指的是可以被记录到的操作和行为
属性就是对于一个对象进行刻画的维度
属性值是定义属性的特征或参数
通过以上五个角度对埋点进行拆解和梳理,并结合可能会产生的数据分析需求点,基本就能够设计出比较完善的埋点属性了。
第二部分:形成埋点文档记录并同步
关于数据需求文档(Data Requirements Document,简称DRD),有一种更通俗的叫法:埋点文档。埋点文档存在的意义,本质上和产品需求文档一样,一方面是利用文档本身的时效性和易追溯的特点,另一方面也是作为与研发沟通的工具,充分避免歧义,保证埋点质量。
一份合格的埋点文档,不仅详细定义了埋点事件,说明了每个埋点事件的触发时机、属性名称、属性值类型以及属性值来源、埋点方式等内容,也详细记录了录入时间、埋点状态、对应版本和埋点迭代记录、附加备注等便于管理的内容。
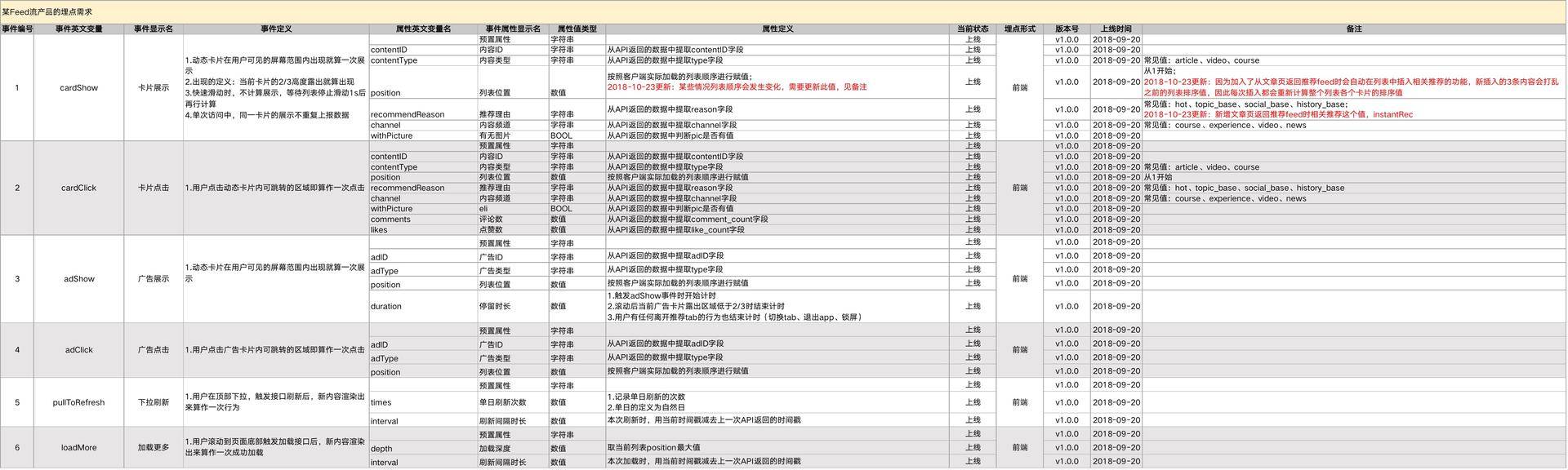
这里分享一款Feed流产品的数据采集案例,这里建议大家把这个案例中的埋点文档复原下来,形成自己的“埋点案例库”,以方便以后的学习和应用:
四、【案例分享】如何设计分享功能的埋点?
这里以最常见,也最基础的分享功能,按照前面的方法给大家分享一下我是如何完成一次埋点梳理的。为了方便大家理解,这里拿微信公众号文章的分享功能举例,总体思路如下:
- 理解数据采集的需求目的,并梳理分享的页面跳转逻辑。以理解分享的具体价值和需求场景,知道要去采集什么数据才能帮助评估。
- 完成指标的定义,并根据指标算法来梳理埋点事件。比如根据“分享率=分享量 / 访问量”,就可以定义出“分享页面”和“浏览页面”两个行为事件。
- 围绕4W1H完善埋点属性的设计,并撰写埋点文档。除了支撑数据指标的计算需求外,还要能够支撑实际工作中可能出现的分析需求。
第一步:通过梳理页面逻辑理解业务需求
对于微信公众号文章的分享功能,需求目的可以从几个层面去理解:
- 对于公众号的作者,通过了解文章的被分享次数和分享率,可以帮助从侧面评估文章质量以及传播性,从而帮助作者产出更优质更有传播性的文章;
- 对于公众号的读者,通过分享到不同渠道,完成表达自我、树立人设的同时,也能够借助社交推荐,形成基于公众号的社交互动;
- 对于微信平台,通过了解分享率,战略层面上可以通过公众号完成微信生态上的内部闭环和外部延伸,功能层面上可以帮助评估渠道优先级,优化分享体验。
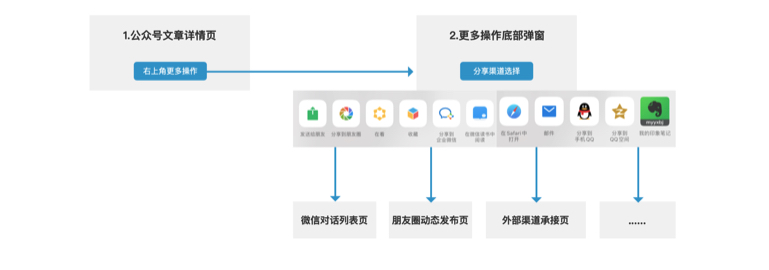
假设通过需求分析,确定了目的是为了帮助评估公众号文章的传播效果。在明确了具体的业务需求后,为了更好地理解需求和指标,为后续埋点设计建立基础,我们就需要梳理一下公众号文章分享功能的页面逻辑,如下图:
第二步:定义具体指标,并梳理埋点事件和其他分析需求
通过梳理完需求目的和主要页面流程之后,我们基本上就能对需求有一个比较深刻的理解了。这个时候再分别对数据指标进行定义时就会比较顺畅,如下表:

从上面对「微信公众号文章的分享率」这个指标的算术定义,可以发现是由两个单位数据指标组成:
- 成功分享「书影音档案」模块的UV
- 访问「书影音档案」模块的UV
因此不难发现,这里涉及到两个埋点事件:“分享页面”、“浏览页面”。但是否意味着,我们只需要记录分享人数和浏览人数这两个数据就够了呢?
事实是远远不够。因为在数据分析中,很多情况下我们会尝试从很多角度去拆解分析数据,产生更多分析需求以找到更多对业务的思考和优化。但这些数据如果没有及时统计到,在我们亡羊补牢前,都无法再获取到这些有价值的数据了。比如针对「分享率」这个指标,可能我们还会想知道:
- 什么时间分享的?分享了几次?
- 分享的是哪篇公众号文章?
- 用户选用的是哪种分享方式或渠道完成的分享?
- 分享是否成功?如果失败,失败的主要原因是什么?
*注:关于是否分享成功这个需求,由于外部渠道的多样性,我们假设成功回传数据并弹出“分享成功”的toast提示就算分享成功。
从上面的例子可以看出,在确定了主干数据指标后,还要有意识地提前思考潜在的数据分析需求点,这样不仅可以更全面地帮助理解“分享率”这个指标,支撑不同角度的数据分析需求,还可以帮助设计一个结构更灵活的埋点事件,避免后续的埋点堆砌甚至重构。
第三步:围绕4W1H标准设计埋点属性,产出埋点文档
通过前面的说明,我想大家都意识到了要收集更多维度的数据。那么问题就来了:既然需要多维度收集数据来支撑可能的分析需求,那我到底应该从哪些维度设计埋点呢?答案就是前面说到的“4W1H标准”。按照这个标准去思考,并试着结合可能的分析需求去设计对应的埋点属性。这里用“分享页面”举个例子:
Who:用户ID、昵称、性别、年龄、来源等
When:分享的时间、是不是首日分享、是不是首次分享等
Where:进行分享时的地理位置
How:设备型号、操作系统、系统版本、APP版本号、网络类型、分享的渠道、是否分享成功等
What:分享的公众号ID、分享的公众号文章ID等
通过以上步骤的梳理,我们基本得到了一个埋点的骨架,最后一步要做的,就是在数据需求文档中,把埋点信息进一步填充起来。这里拿分享页面的事件举个例子:
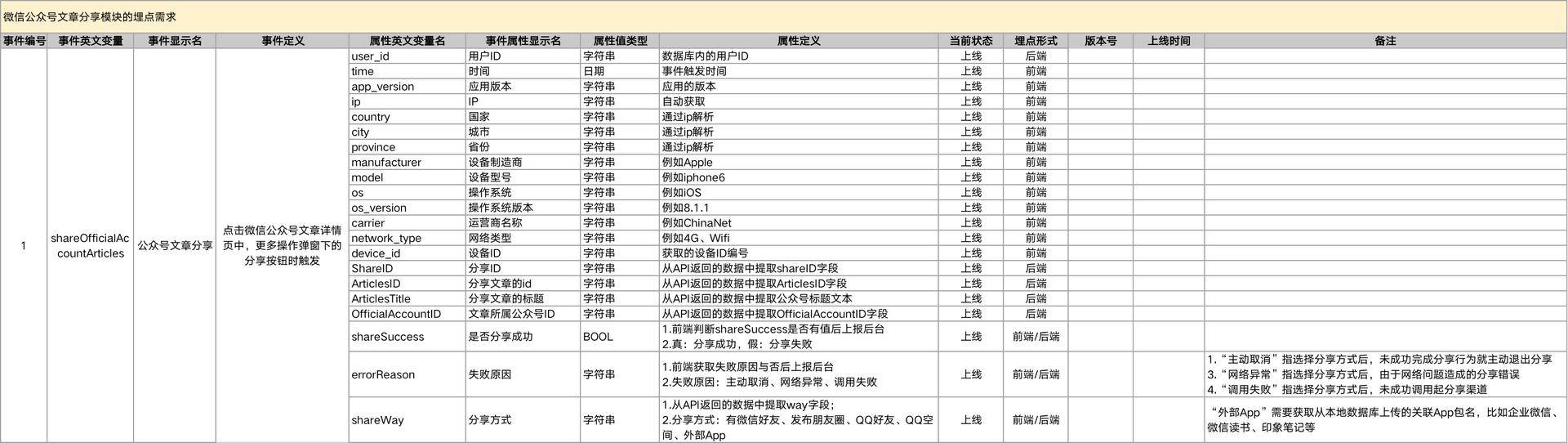
*注:如果对于所有的埋点事件,都有一部分相同的数据需要记录(比如上面的用户id、时间、ip、设备号、网络等等),就可以采用合并省略的方式,作为默认必埋的预置属性,记录到开发埋点规范里。
对于自有数据管理比较完善的团队,也会有自己统一记录埋点的方式,例如下面这种形式:

通过以上理论分享+案例实操的方式,和大家分享了我在日常工作中是如何结合实际分析需求设计数据埋点的。
当然,其中涉及的一些具体操作方式可能并不适用每一个团队,但其中的核心思维倒可以参考一二,毕竟对于同样结合了理性分析和感性思考的数据分析工作来说,有逻辑结构的思考方式往往才是最有用的借鉴点。
本文由 @鱼头 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。










第三方的可视化埋点,无埋点统计分析API其实已经涵盖了文中的埋点需求
讲的非常清楚了,有些细节问题,希望能加好友,再请教
讲的非常清楚了,有些细节问题,希望能加好友,再请教
写的很清楚很有深度了,有一些细节上的问题想请教一下,不知道是否可以加个好友请教一下?
我认为埋点应该是业务自己的产品经理在设计产品方案时,同步去考虑的一项工作,而是不是让另外一位“数据产品经理”先熟悉并分析业务的操作和场景,再帮助业务做埋点。
对头
对头,最可怕的是重新搭建一个app的埋点
产品同学自己设计的不好用
可以产品自己设计一套方案,再由数据产品经理把关和改进