
 起点课堂会员权益
起点课堂会员权益算法知识汇总:构成/学派/算法
如果你是产品经理,希望了解算法的基本知识,可以考虑阅读本文。

01 概述
机器学习(Machine Learning,ML)就是通过计算机程序对信息和数据进行重新组织,使用算法优化自身性能的系统。搜索引擎、内容推荐、信息流、在线广告等已经是机器学习算法的传统应用领域,与此同时,机器学习的应用领域还在不断扩展。
目前,很多产品、运营的工作都需要围绕机器学习算法系统开展,算法系统已经成为很多产品的核心竞争力。在这样的背景下,为了更好地迭代有算法逻辑的产品,了解机器学习算法的基本逻辑就显得非常必要。
机器学习首先是一个学习的过程,目前的机器学习已经实现了学习的基本逻辑,可以从过去的经验中抽象出一些规律,同时将这些规律应用在未来的场景下。
汤姆·米切尔(Tom M.Mitchell)在他的《机器学习》一书给了机器学习一个定义:
“对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序在从经验E学习。”
在这个定义中可以看到机器学习的几个关键点:任务(任务T)、性能指标(性能度量P)、历史数据(经验E)。
对于某类任务,不断从数据中学习,从而优化这个任务的性能指标,这是目前机器学习算法的核心逻辑。
02 构成
机器学习系统由数据、算法模型、模型评估、计算结果组成。
机器学习系统的出发点是数据,计算结果呈现给用户或系统之后,用户的行为数据会反馈数据,这些反馈数据又会重新输入模型中。这是机器学习的基本流程,如下图所示:
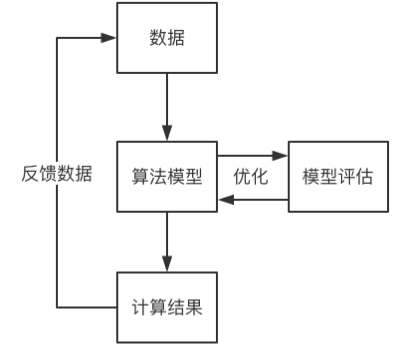
数据是机器学习系统的出发点。机器学习系统能够成立的前提,是有足够让系统做出决策的数据。
判断一个问题是否能用机器学习解决,就是看能否收集足量的相关数据。
比如,所有用户对内容的浏览行为数据,可以对某一个特定用户接下来的阅读偏好做判断。用户的每个浏览和点击行为数据,都意味着个人偏好的表达,同时其他相关用户的行为也可以作为这个用户行为推测的依据。构造算法系统需要从多个角度判断数据是否满足构建算法模型的需求。
在确定了数据可以构建机器模型来解决业务问题之后,就到了模型构建阶段。在算法模型的构建中,最关键步骤就是将问题抽象成机器学习能处理的标准问题。机器学习算法一般会对实际情况做一些模型假设,这些假设包含着一些待确定的参数,机器学习模型就是要找到符合实际情况的模型假设,并且通过算法的迭代确定出合理的参数。
在了解业务和算法的基础上,模型的构建过程会顺利很多,但是在缺少评估的情况下,模型也不可能顺利构建。模型评估一方面相当于质量检验,保证模型输出结果的质量,防止上线之后产生明显的体验问题。同时模型评估中发现的问题,也是模型优化的重要依据。
在模型评估完成之后,就可以在线上给用户输出机器学习模型的计算结果。这些计算结果最终会在用户的使用中得到验证。真实的线上数据会反映模型上线后的效果,这些线上数据也会成为后续机器学习模型迭代的数据,从而形成完整的信息闭环。
虽然不同的算法有着不同的实现方法,但是大部分机器学习算法基本都是由这些模块构成的。
03 五大学派和典型算法
佩德罗•多明戈斯(Pedro Domingos)在《终极算法》中将机器学习算法分为了五大学派,也基本涵盖了目前的主流机器学习算法。接下来会介绍这五个学派的典型算法。
1. 联结学派(The connectionists)
联结学派的主要思想是通过神经元之间的连接来推导知识。联结学派有点类似于大脑的逆向工程,希望通过训练人工神经网络以获取结果。它是目前最炙手可热的机器学习学派,神经网络和基于神经网络的深度学习都属于联结学派。
人工神经网络是一种非线性学习算法,和生物学的神经元类似,由多个节点组成。神经网络中每个节点的名字也沿用了生物学中的神经网络的概念,同样叫作神经元。生物神经元和算法神经元的结构如下图所示。
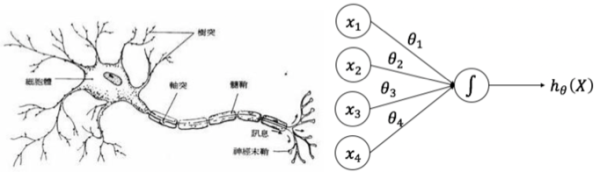
在生物的神经网络中,多个树突的末梢收集神经刺激电信号,将这些信号加工成新的电信号,通过轴突传递出去。
而人工神经网络也是这样的结构,多个参数在神经元中加工并输出到下一个节点。各个节点使用Sigmoid函数进行参数处理,如下所示:
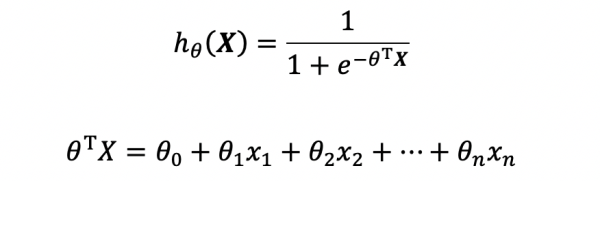

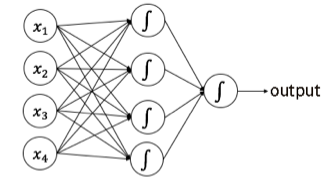
在一个多层的神经网络中,每个神经元都通过这样的模式,将数据不断传递下去,并最终输出计算的结果。如下图所示的是一个典型的人工神经网络。
具体的优化方法在这里不展开描述,有兴趣的读者可以查看相关资料。
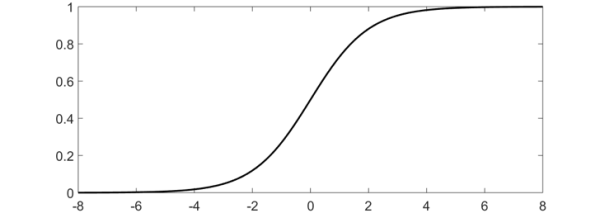
值得一提的是,Sigmoid函数是一个在算法领域很常见的函数,可以将无界的变量映射到(0,1)之间,这个函数的特性是很多算法策略都会用到——神经网络中,正是因为结点用了这个函数,才保证了可以兼容各种类型的数据。Sigmoid函数曲线如下所示:
基于这样的方法可以构造出不同类型的神经网络模型,神经网络模型因为可以兼容多种类型的数据,在现实中都有着广泛的应用,包括线上信息分发系统、图像识别、机器翻译等。
当然,这样的算法也有着明显的问题——模型可解释性差,模型对数据量的要求比较高。因此,神经网络算法适用于有着海量数据且对算法解释性要求不高的业务。
2. 符号学派(The symbolists)
符号学派通过训练可解释的规则来解决问题。符号主义者更侧重逻辑推理,用几个过去的数据训练出一套规则引擎,对未来进行预测和判断。决策树和以决策树为内核的很多机器学习算法都属于符号学派。
决策树算法是一种典型的分类方法,是数据挖掘中常用算法之一。在决策中利用归纳算法可以生成可读的决策规则,这个决策规则能够将可能出现的实例都进行分类和预测。
决策树算法非常接近人的决策过程,人的很多标准化工作,其实也可以理解为生成了一个决策树。
以产品经理面试为例来阐述决策树的模型框架,假设通过对话可以了解候选人的三个特征:决策能力评分、系统学习能力评分、合作能力评分,同时假设通过这三个特征即可判断候选人是否通过。那么这个决策流程可能如下图所示:

这是一个标准化的决策流程,而决策树其实就是通过利用历史数据构造对未来实例进行自动化决策的方法,核心是确定每个属性在决策树中的位置。
在整个决策树的生成过程中,从根部节点开始生成,每次向下分类都选择信息增益率最大的节点,不断迭代生成决策树。为了防止过拟合,也会采用一定的规则算法对决策树进行减枝,例如规定生成子节点的最小信息增益率,小于一定值不生成子节点。
决策树是多元分类器常用算法之一,很多机器学习算法都会用决策树的模型构建更高级的模型。相对其他的算法模型,决策树的决策流程更贴近决策实际情况,决策树形成的规则也可以帮助我们更深入地理解业务。
3. 进化学派(The evolutionaries)
进化学派,是以遗传学和进化生物学的理论基础,进行模型构建。核心方法是构造算法的评估标准和进化方法,在系统中不断迭代算法获得最佳解决方案。今年兴起的强化学习就是进化学派的代表。
近年来机器学习的浪潮进入大众视野,和AlphaGo战胜李世石和柯洁的新闻有很大地关系。很多人不知道的是——在战胜了柯洁之后,Deepmind公司推出了抛开人类经验的新版本人工智能AlphaGo Zero,这就是强化学习的典型应用。
强化学习是系统用试错的方式进行学习,通过不断和环境交互训练策略。在系统中,需要构建出可以和系统不断交互的环境,对系统的每一个动作进行评判,系统根据每个动作的奖惩信号(强化信号),不断调整最佳的动作策略。下面是一个典型的信息交互图。
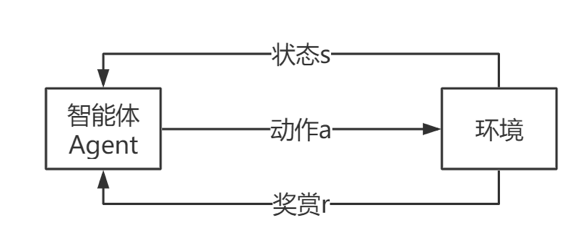
具体在围棋场景中,对弈中每一盘棋的胜负和局势变化都是系统的奖惩信号,每一步落子都是动作,虚拟对局中的围棋规则就是系统的环境。
这种算法目前在工业界已经有了很多应用,比如基于强化学习的推荐算法等。在实际背景下,算法面临的环境往往是不确定的,不像围棋中的规则总是固定的。为了应对这个问题,算法就需要将现实问题抽象为稳定的虚拟环境,也就是构成出仿真系统,这也是现实条件下,强化学习算法构建过程中最难的一步。
仿真系统也不是新鲜的概念,所有的航空航天器要上天都要测试空气动力学性能,就会用到风洞系统,风洞就是对飞行中各种情况的仿真。而算法系统需要构造的就是这样一个在线的风洞。

强化学习目前的缺点也很明显,算法高度依赖仿真系统的构建,应用场景有限,同时实现复杂且不可解释,还需要投入大量的资源。
但是强化学习的学习过程,很像生物的进化过程,人类本质也是在地球这个环境中,以生存和繁衍为目标进化出的高级智能。也许强化学习进一步发展后,能够真正推进机器学习进入更高的层次。
4. 贝叶斯学派(The Bayesian school of thought)
贝叶斯学派专注于研究概率推理和用贝叶斯定理解决问题。贝叶斯定理的核心是用先验概率来推测后验概率,也就是不断通过新的数据来更新原有的对于概率的估计。朴素贝叶斯算法就是贝叶斯学派的典型算法,典型的应用就是垃圾邮件过滤系统。
在介绍朴素贝叶斯算法之前,先简单介绍下贝叶斯定理。贝叶斯定理是计算两个随机事件条件概率转化方法的定理。比如对于随机事件A和B,贝叶斯定理的数学描述如下:

贝叶斯定理是构造朴素贝叶斯算法的基础。下面就在邮件过滤的背景下介绍这个算法:
我们如果已经有一批已知的垃圾邮件,就可以知道垃圾邮件的一些典型特征。接下来如果我们先验地知道一封邮件包含的特征和垃圾邮件类似,我们就可以做出推断,这封邮件有很大概率是垃圾邮件。
很多算法都会围绕贝叶斯定理展开,朴素贝叶斯是其中一个代表。贝叶斯算法也是少有的对小规模数据也可以应用的算法。掌握好贝叶斯定理这个工具,对做好数据和策略相关工作,有着重要的促进作用。
5. 类推学派(The analogizers)
类推学派的核心是最近邻的方法,通过相似性判断,用近邻的已知数据,预估未知的数据。一些传统的推荐算法,就是类推方法的典型应用。类推学派的一个典型算法就是隐语义模型(Latent Factor Model,LFM),这个算法的最佳实践也是在推荐系统中。
推荐算法的起点,就是用户的行为数据,如果用户和物品发生了越多的交互,则行为越强。推荐算法就是基于用户行为数据补全下面表格的空白。这个表格其实就是一个“用户×物品”矩阵。
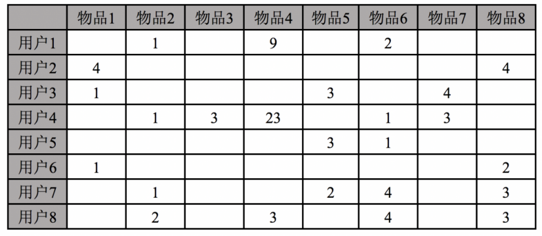
我们在选择物品或者内容的时候,是根据自己的偏好与物品或者内容是否匹配来决定的。
就拿服装而言,有的人在乎颜色,有的人在乎款式,有的人在乎调性,有的人在乎价格。人在选择的时候会考虑很多因素,每个因素都有一个心理预期的偏好范围。下表所示就是一个“用户×偏好”的矩阵。
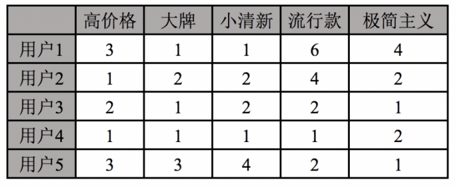
不同的物品或者内容与这些偏好的符合程度不一样。物品和这些偏好的符合程度也会形成一个“物品×偏好”的矩阵,如下表所示:
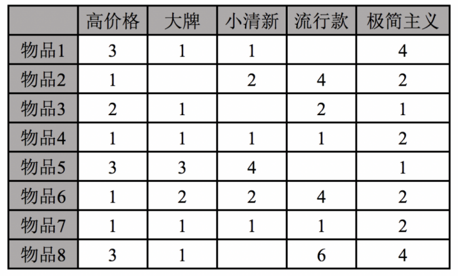
总而言之,我们需要利用“用户×物品”矩阵,去想办法构建出“用户×偏好”矩阵和“物品×偏好”矩阵。在得到这两个矩阵之后,就可以使用线性加权求和的方法来计算用户和物品的推荐分数。
LFM就是这样一种算法,通过随机梯度下降,构建出两个潜在因子矩阵,并用这个矩阵计算空缺物品的推荐值。如下所示,是上面数据形成的推荐结果。
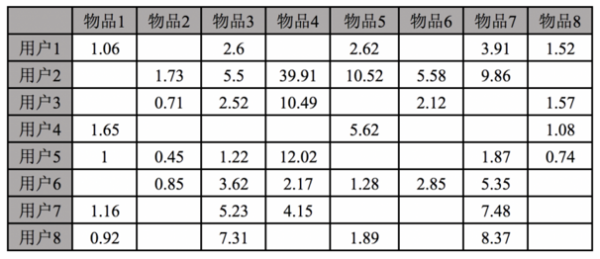
在原始数据中,用户7和用户8比较类似,如下表所示:

从推荐结果来看,用户7和用户8的推荐结果分数也比较类似,结果如下所示:

04 总结
本文介绍了基础的机器学习算法思路,同时也介绍了几种基本算法,算法介绍以思路为主,如果需要进一步学习,可以查询公开资料。
这几种算法比较基础,在这些算法的基础上,衍生出了多种多样的算法。在实际应用中,往往会将多种算法进行组合使用,从而发挥出更大的效果。
机器学习算法离不开模型假设,这些假设包含着一些待确定的参数。每一个假设都是对现实情况的抽象,每一个参数都是对模型的理想化处理,这些假设和参数让模型能够成立,也让模型和现实存在差异。
但这些“差异”的存在并不影响实际问题的解决,就像统计学大师乔治·博克斯说的那样,“所有的模型都是错误的,但是其中有些模型是有用的”。我们需要理解模型和现实之间差异形成的原因和影响范围,并据此判断模型的适用范围。
作为产品经理,理解模型的算法的基本原理非常必要。只有这样,才能将业务理解更好地融入到算法系统中,否则就很容易沦为算法的人工标注员和case收集者。
为了能介绍机器学习的知识,这篇文章不可避免地涉及了一些数学逻辑,也可能也会让很多产品经理感觉阅读困难,但这只是机器学习的冰山一角。我们始终要选择做对的事情,而非简单的事情。
产品经理需要站在科技和人文的交汇点,那么对最新的技术有基础的了解,就是产品经理的必由之路。
#专栏作家#
潘一鸣,公众号:产品逻辑之美,人人都是产品经理专栏作家。毕业于清华大学,畅销书《产品逻辑之美》作者;先后在多家互联网公司从事产品经理工作,有很多复杂系统的构建实践经验。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议










您好,文章很受益,有个疑问,类推算法中,用户和物品之间的加权推荐值,是如何计算出来的?
搜索 基于用户的协同过滤算法,与基于物品的协同过滤算法