
 起点课堂会员权益
起点课堂会员权益A/B测试算法大揭秘第三篇:如何分析试验数据(下)
希望通过我们的几篇文章,能够帮助你更好的了解A/B测试和置信区间,一起实现用A/B测试驱动产品优化。
P-value定义
P-value(以下简称P值),又称“显著性水平”,它是指在原假设为真的条件下,样本数据拒绝原假设事件发生的概率,可以用来评估假设检验中最关键的第一类错误的概率。
今年3月,美国统计协会(ASA)在其官网上发布了《关于统计显著性和P值的声明》,进一步阐释了P值的概念和用处:
- P值可以表达的是数据与一个给定模型(也就是原假设下的模型)不匹配的程度;
- P值并不能衡量某条假设为真的概率,或是数据仅由随机因素产生的概率;
- 科学结论、商业决策或政策制定不应该仅依赖于P值是否超过一个给定的阈值;
- 合理的推断过程需要完整的报告和透明度;
- P值或统计显著性并不衡量影响的大小或结果的重要性;
- P值就其本身而言,并不是一个非常好的对模型或假设所含证据大小的衡量。
P-value的计算——T检验
P值的计算公式取决于假设检验的具体方式,常用的假设检验方法有Z检验、T检验和卡方检验等,不同的方法有不同的适用条件和检验目标。
A/B测试中是用对照版本和试验版本两个样本的数据来对这两个总体是否存在差异进行检验,所以适合使用T检验方法中的独立双样本检验 (independent two-samples ttest)。通过T分布理论来计算相关的概率水平,也就是P-value的值。
T检验的计算公式,首先通过来公式计算出统计检验量Z值,公式中的相关组成因素就是:两个版本的各自均值、方差(标准差),以及样本的大小,从而推算出统计量的Z值是多少。
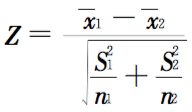
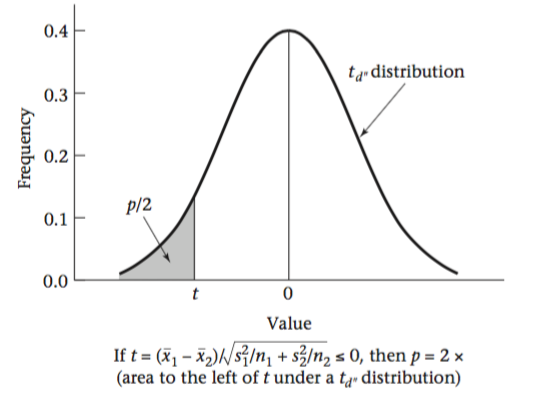
然后通过t分布(大样本情况下近似正态分布)的公式计算得出和Z值对应的P值,阴影部分的面积就是P-value的值。
P值算出来之后,我们就可以根据P值按照前面介绍的假设检验决策规则来判断这两个样本均值的差异是否显著了。
P-value中的常见错误
A.统计显著=效果显著=效果的商业价值?
这个式子的意思是:P值只代表了样本数据与原假设之间有多不一致,并不能代表你所发现的效应(或差异)的大小。
尽管研究者们在很多情况下都希望计算出零假设为真的概率或是数据由随机因素产生的概率,很可惜这两者都不是P值的事。P值只解释数据与假设之间的关系,它并不解释假设本身。即,不论P-value的值有多小,也只能告诉你两个版本间是否存在差异效果,并不能得知差异效果究竟有多大,更不能告诉我们这效果是否具有实际价值。
例如,我们通过A/B测试对一个资源耗费10倍以上的推荐算法进行优化,得到p值=0.001,说明这次的试验结果是显著的。而试验的效果,只对收入提升了万分之一。
当资源耗费增大了10倍或更多时,收入只得到了非常微小的提升,那么从整体看来这个优化带来的商业效果其实是非常不显著的。因此不能从P值来判定改动所带来的商业效果。
B.一旦P≤α,就立刻得出结论?
这是P值一种比较经典的错误使用方式:持续观察和检验p值(multiple testing) ,一旦p值小于α判定标准(即统计显著),就停止试验得出结论。事实上,这样的会导致很高的第一类错误发生率。
以Airbnb的某一个A/B测试为例,当试验开始运行后,持续每天都观察试验数据的情况和p值,并绘制出以下图表。可以发现,当试验运行到第7天时,p-value的值第一次小于α判定标准,实验结果显示显著。但是过了一段时间之后,p值并没有稳定下来,甚至一度增大到实验结果显示不显著。也就是说,单纯凭借p-value值来判定实验结果的显著与否,是不太可靠的。尤其是在试验刚开始的前7-10天之内,单纯依靠p-value值来得出版本差异的判定,出错的概率是非常大的。
以上就是关于P-value的介绍。如果在阅读的过程中,你对P值有了更加深入的了解,那就是我们在这篇文章上的最大成功。最后想说的是,P值并不是数据分析的终点,所有决策的过程都应该多个因素综合考量,而不是“一锤子买卖”。在A/B测试中,同时应用了许多其他合适可行的方法,是它们的共同作用帮助我们判断出了最优的试验版本。下一篇,我们就来讲讲A/B测试中用户最关注的部分——置信区间。
作者:吆喝科技,微信公众号(appadhoc)。
本文由 @吆喝科技 原创发布于人人都是产品经理。未经许可,禁止转载。









测试用例