
 起点课堂会员权益
起点课堂会员权益0-1搭建个性化推荐系统的设计思路
编辑导语:个性化推荐系统是互联网和电子商务发展的产物,它是建立在海量数据挖掘基础上的一种高级商务智能平台,向顾客提供个性化的信息服务和决策支持。今天,本文作者就结合自己的经历,为我们分享了从0到1搭建个性化推荐系统的设计思路。

1. 设计目的
- 商城已上线2周年,已有10万+在售物品。需要推荐系统,帮助用户从过量的物品中,快速发现优质物品,缩短用户路径,提高订单量。
- 目前商城订单量、用户数增长缓慢,所以需要推荐系统,作为新的增长点,带动业务增长。
- 通过全面采集用户、物品数据,并分析各类用户对各类物品的喜好,可以帮助商家快速了解平台内用户喜好,了解自己的物品特点,提高订单量。
2. 产品结构
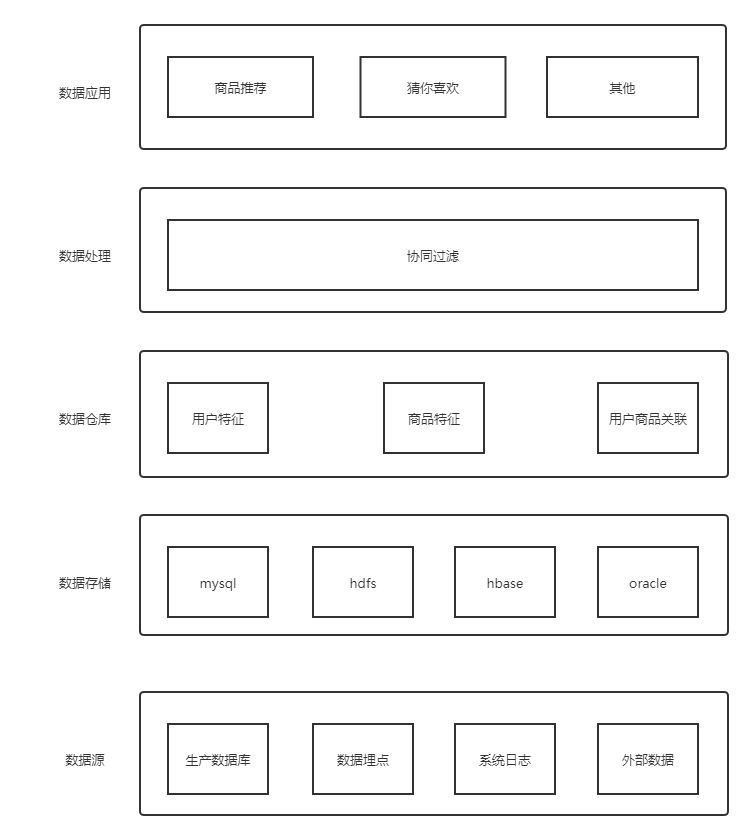
3. 推荐模型设计
3.1 基于物品的协同推荐
3.1.1 算法原理
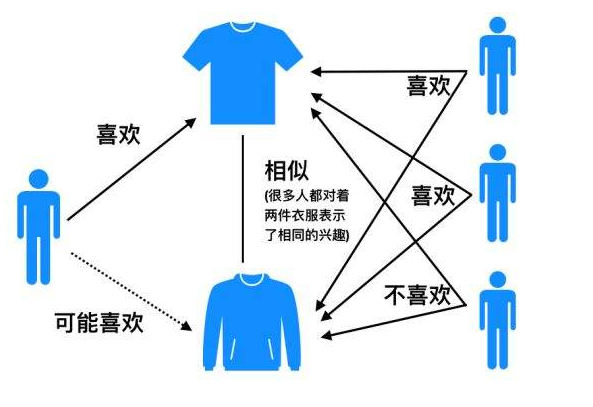
基于物品的协同推荐算法认为:当用户A喜欢物品a,且物品a和物品b相似,则认为用户A喜欢物品b。所以搭建该算法分为两步:
- 计算用户A对物品a的喜爱度
- 计算物品a和物品b的相似度
用户A对物品b的喜好矩阵=用户A对物品a的喜好矩阵+物品a和物品b的相似度。
3.1.2 明确用户的喜爱特征的权重
根据和业务专家的初步讨论,明确用户对物品的喜爱度,与以下行为有关:
- 浏览:用户进入物品详情页后,在详情页停留的时长超过5S;
- 收藏:用户点击收藏按钮,收藏了物品,且未取消收藏;
- 下单:用户购买过该物品,且未退货;
- 转发:用户转发过该物品。
根据上述维度,可构建判断矩阵:
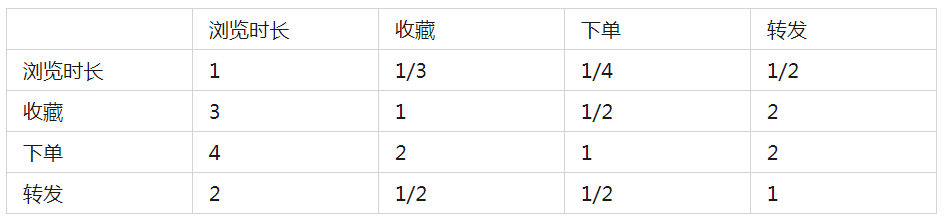
将上述矩阵进行归一化、计算权重后,最终计算的权重结果如下图所示:

浏览:0.1,收藏:0.29;下单:0.43;转发:0.18。一致性检验过程如下图所示:CR=0.02<0.1 一致性检验通过

最终确定标准化指标,如下表:
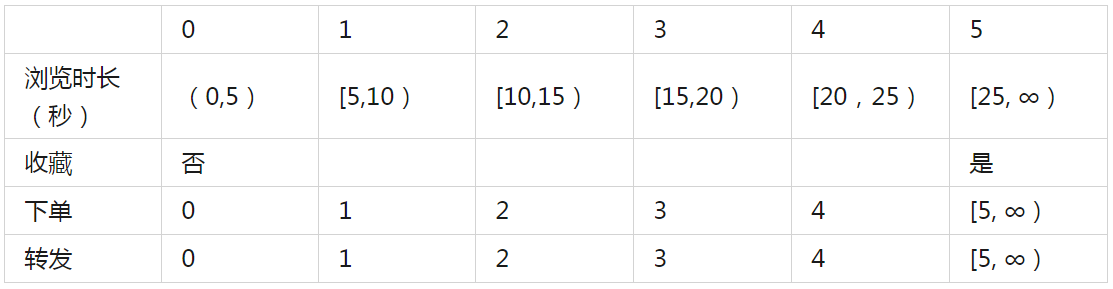
3.1.3 构建用户对物品的喜爱度矩阵
根据上述计算过程,可以计算用户对某物品的喜爱度。
例如用户1,对物品a:浏览了13S,未收藏,下单了1次,转发了2次,则用户1对物品a的喜爱度为:2*0.1+0*0.29+1*0.43+2*0.18,最终计算所有用户对物品的喜爱度矩阵:
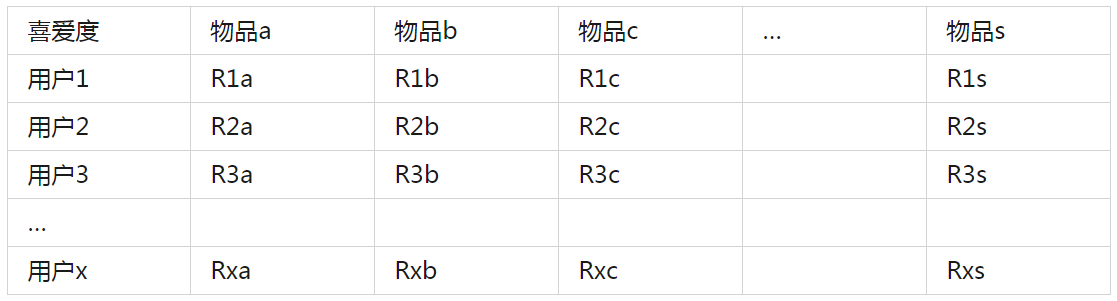
3.1.4 构建物品对物品的相似度矩阵S
按照喜爱度矩阵R,根据皮尔逊相关系数公式(两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商),可计算出多个物品之间的相似度:
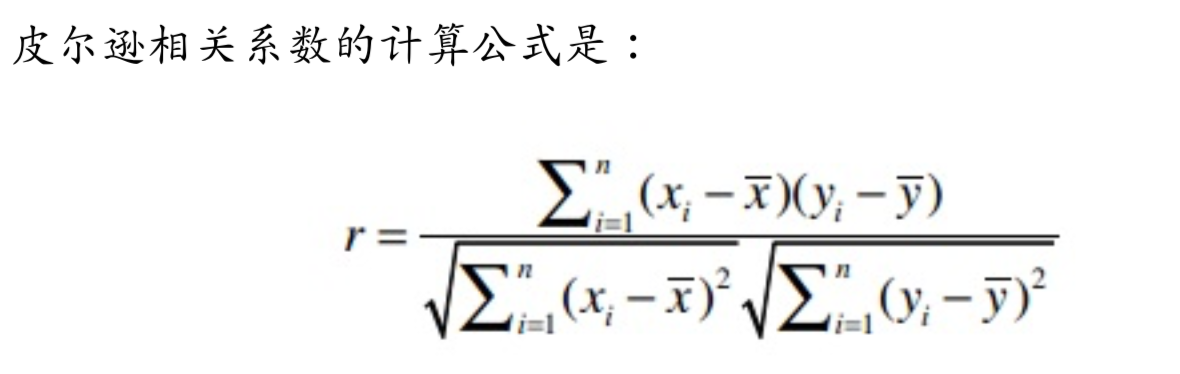
- Xi:用户i对物品X的喜爱度
- `X:所有用户对物品X的喜爱度的算数平均值
- Yi:用户i对物品Y的喜爱度
- `Y:所有用户对物品Y的喜爱度的算数平均值
- r: 物品x和物品y的相似度
最终可计算出相似度矩阵S,矩阵为对称矩阵:
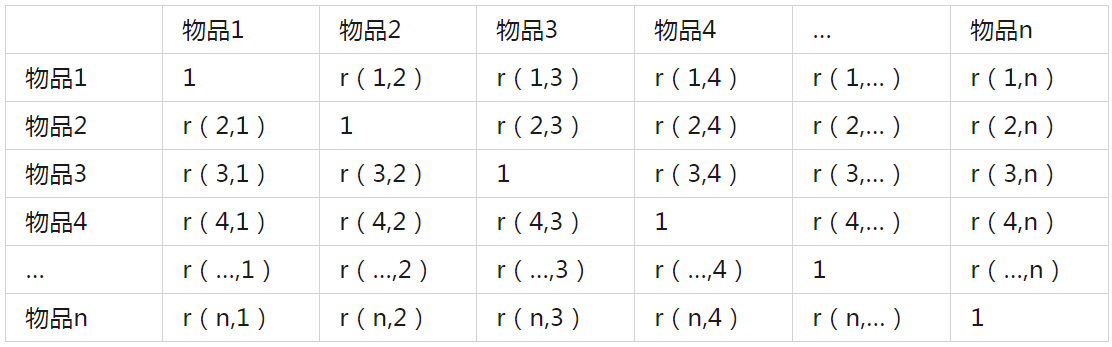
3.1.5 预测用户A对物品b的喜好
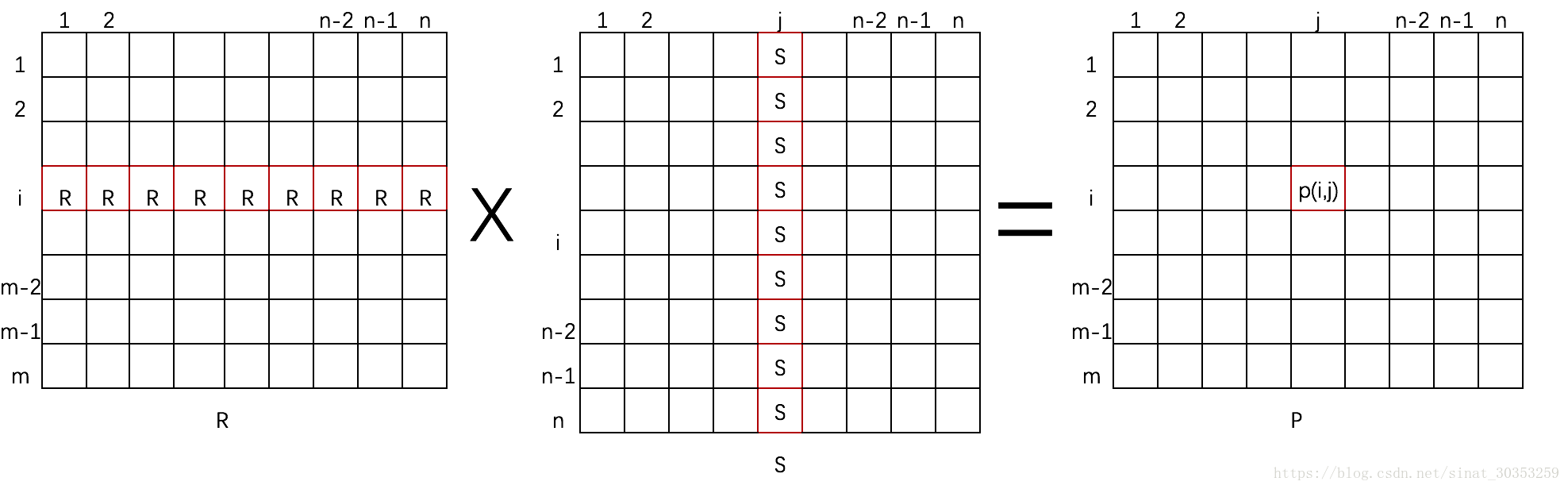
通过喜好矩阵R*相似度矩阵S,即用户i对所有物品的评分作为权重,和物品j中的物品相似度乘积加和,可得到用户i对物品j的评分预测P(i,j)。
3.2 基于用户的协同过滤
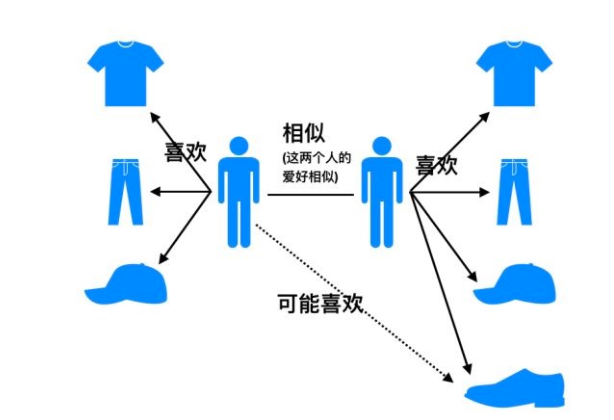
基于用户的协同推荐算法认为:当用户A喜欢物品a,且用户A和用户B相似,则认为用户B喜欢物品a。
所以搭建该算法分为两步:
- 计算用户A对物品a的喜爱度
- 计算用户A和用户B的相似度
用户B对物品a的喜好矩阵=用户A对物品a的喜好矩阵+用户A和用户B的相似度,计算过程和基于物品的协同过滤的极端过程基本一致。
4. 推荐效果验证
在推荐系统上线前的离线测试、 AB测试阶段,需要系统的验证推荐系统的效果。
推荐系统推荐给用户的东西有多少是用户真正喜欢的、带来了多大的转化率等等。验证推荐系统的效果常见的指标,包括:
- 准确度
- 召回率
- 覆盖率
- 多样性
4.1 准确率
准确率表示预测为正的样本中,真正的正样本的比例。
公式如下:
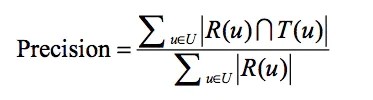
R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表。
最简单的例子:例如推荐系统给用户推荐了10件物品,用户进入物品详情页定义为判断真正的正样本的行为,用户进入了其中3件物品的详情页,则此时准确率=3/10=30%。
4.2 召回率
召回率表示的是真正的正样本中,被推荐的真正的正样本的比例。
公式如下:
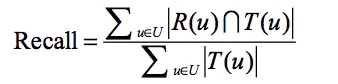
R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表。
最简单的例子:用户进入物品详情页定义为判断真正的正样本的行为,用户进入了20件物品的详情页,其中3件物品是从推荐列表中进入的,则此时准确率=3/20=15%。
4.3 覆盖率
覆盖率表示的是被推荐出来的样本,占总样本的比例。
公式如下:
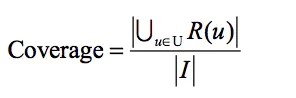
U是推荐系统中所有用户的集合,R(u)是给每个用户推荐的物品列表,I是所有推荐池的物品。最简单的例子:给用户推荐了10件商品,总共100件商品,则此时覆盖率=10/100=10%。
4.4 多样性
多样性表示被推荐的物品,两两之间的差异性。
公式如下:
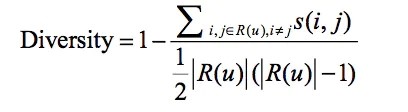
s(i, j)是推荐的物品i和j之间的相似度,u是被推荐的用户,R(u)是给用户推荐的物品列表。
4.5 其他指标
除了上述指标外,也有从其他业务维度验证推荐系统效果的指标。例如新颖性、惊喜度、信任性、实时性、健壮性,以及基于公司发展规划的商业指标等。
5. 总结
当公司业务/产品,发展到一定规模,积累了一定的数据量,为了进一步提升业务指标/用户体验,往往会考虑个性化推荐系统。
从0搭建mvp的个性化推荐系统,需要:
- 梳理数据源,维护底层数据质量、拓展数据维度;
- 基于对业务的深入理解,形成符合业务需求的推荐模型;
- 最终形成给用户的个性化推荐功能。
个性化推荐系统,最常见的就是基于用户/基于物品的协同过滤。构建协同过滤模型,需要:
- 计算用户-物品的喜爱度矩阵R;
- 计算用户-用户/物品-物品的相似度矩阵S;
- 两个矩阵相乘,得到用户-物品的喜爱度预测值。根据预测值进行推荐;
- 验证推荐效果,并持续调优。
另外,在从0搭建推荐系统,开需要考虑用户冷启动、物品冷启动等问题。
本文由 @16哥 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Pexels,基于 CC0 协议








同样是在权重下2小节没看懂,btw请问 PM需要对这些指标、权重、算法的理解深度到什么程度?
同样没看懂,可以出个讲解的文章吗
从权重那块开始,都没有看懂,方便加微信讲解下吗?