
 起点课堂会员权益
起点课堂会员权益可用性研究中要测试多少个用户?

答案是 5 个,无一例外。使用更多测试者的论点大多数时候是不对的,不过有些却需要更多。
如果你想要一个单一的数字,答案很简单:在可用性研究中测试 5 个用户。在可用性研究中,测试 5 个人可以让你发现绝大部分的可用性问题,这和你测试更多用户得到的结果并没有太大的差异。
从 1989 开始推广“折扣可用性工程”以来,这个答案一直是这样的。无论你测试官网、内部网、PC应用程序,还是测试移动应用,都是这样。测试 5 个用户,你几乎总能得到最大投入产出比。
然而,与人为因素有关的问题,当然也会有例外:
- 定量研究(针对统计数字,而不是洞察力):测试至少 20 个用户以获得统计学上显著的数字;严格的置信区间需要更多的用户。
- 卡片分类:每个测试组至少有 15 个用户。
- 目测:如果要获得稳定的数据,要测试 39 个用户才行。
不过,你没必要担心上面那三种情况,因为你的绝大多数用户研究都是定性的,也就是说,旨在收集洞察力驱动产品设计,而不是在 PPT 上给人留下深刻印象的数字。
5 人测试的主要争论点是简单的投资回报:随着参与测试用户的增加(同时成本也在增加),但到了一定数量后回报的增速递减。在同一个研究中测试超过 5 个人没有什么额外的好处;ROI 像一个大石头一样极具下降。
如果你有足够的预算?哎呀!快去把它花在额外的研究上,而不是在每项研究中更多的用户上。
遗憾的是,大多数公司坚持做更大的测试。在 UX 会议期间,我调查了 217 名参与者公司的情况,他们每次进行测试用户数量的均值是 11 ——是推荐数的两倍以上。显然,我需要更好地解释 5 人可用性测试的好处。
更多测试参与者的参数
“一个大网站有数百万用户。”
即使你在做统计分析,那也不影响样本大小。一项民意调查需要相同数量的受访者来找出谁将当选匹兹堡市长或法国总统。统计抽样中的方差是由样本大小决定的,而不是抽取样本的全部人口的大小(总体)。
在用户测试中,我们专注于一个网站的功能,看看哪些设计元素好用或难用。设计元素的质量评价不依赖于多少人使用它。(相反,关于是否修复设计缺陷的决定当然应该考虑多少人使用:可能不值得去努力改善较少用户使用的功能;较好地应该把钱和精力放到数百万用户使用的功能上。)
“一个大的网站有几百个特征。”
这是一个用于做几个不同测试的争论——每个测试集中在一个较小的功能上,而不是在每个测试中测试更多的用户。在用户感到疲倦前,你就该停下测试更多的任务了。
的确,对于一个功能较多的产品,你需要更多的用户进行测试,但是需要将这些用户分散到许多个测试中,每一个都集中在一个较小的功能点上。
“我们有几个不同的目标受众。”
实际上,这是测试更多用户的一个正当理由,因为需要每个目标组的典型用户。然而,实际上,只有当用户以完全不同的方式(译者注:用户群体和目的等的不同)使用产品时,这才成立。我们项目中的一些例子包括:
- 一个以医生和病人为目标的医疗网站
- 一个以买家和卖家为主的拍卖网站
当用户和任务不同的时候,基本上你就可以为每个目标群体做新的测试了。当然,你要为每个组测试 5 个用户。通常,你可以为每组测试 3-4 个用户,因为用户体验会在两组之间有所重叠。
比如说,一个以新投资者、有一定经验的投资者以及资深投资者为目标用户的金融网站,每组测试 3 人共 9 个用户就可以了,而不需要测试 15 个用户。
“这个产品(网站、App 等)赚了很多钱,即使是细小的可用性问题也是难以忍受的。”
有钱的公司当然会通过投资回报率来决定如何开展可用性测试,即使在每一次优化相关的测试上花费太多,也会因为在产品中大量资金的流动而做出更多的让步(译者注:因为优化就有可能意味着带来负向的资金变动,得不偿失,所以不如不改)。
然而,在设计可用性测试和实施的过程中,也会考虑测试本身的投资回报率,当然会选择投入和产出比较大的方案,来提高整体的收益了。
最基本的一点是:
只要是不断的迭代产品,在设计和测试其他版本过程中,任何一个版本实施可用性测试都是可以的。没有固定的东西会在下次优化,如果有很多优化项,只需要规划版本。
相比较一次测试更多用户,多版本每次解决不同问题的方式,这么做最终的结果将带来更高的质量(伴有更高的商业价值)。
83个案例研究
下图总结了尼尔森-诺尔曼集团最近实施的 83 个可用性咨询项目。每个点是一个可用性研究,它显示了测试的用户数(横轴),以及收集到的可用性问题(纵轴)。(图中仅包含常规的定性研究;我们还运行有竞争力的研究和基准测量,以及并未在这里显示的其他类型的研究。)
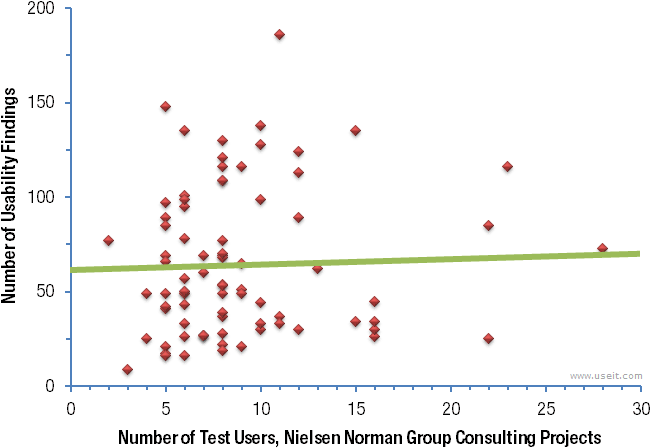
有一个相关性,真的很小。在众多的项目中,测试更多的用户并没有引起更多的洞察力。
既然相信这些研究结果显示了小规模测试的优越性,为什么我们还要做更多的用户测试呢?原因有三个:
- 一些客户希望对内部信誉进行更大规模的研究。当一个研究的赞助商向不了解可用性的管理者提出调查结果时,测试更多的用户,这些结果更容易接受。(如果管理层相信自己的员工,就可以节省很多钱啊。)
- 一些设计项目有多个目标用户群,预期(或至少怀疑)行为的差异大到足以证明测试更多用户的花费是可行的。
- 最后,事实上,这些使用更多用户测试的咨询项目是合理的,这也是为什么我们经常做大约 8 个用户的研究。投资回报率是投入和产出之间的比率。当聘请顾问时,真正的投入往往比实际的要高出很多,因为企业必须花费时间来寻找顾问并进行谈判。随着投资的增加,你希望获得更大的收益。
最后一点也解释了为什么“多少用户”的真正答案有时会远远小于5。如果有一个较低投入的敏捷 UX 过程,在每一项研究中的投入都可以忽略不计,以至于成本效益被优化得很好。(在每一项研究中获益较少的情况下,获得更多的投资回报似乎是违反直觉的,但这种节省是因为每项研究的投入越少,就可以进行更多的研究,那么产出就会不断积累。)
对于实际投入很低的项目,最好的方式是只测试 2 个用户。对于其他一些项目,8 个用户——有时会更多——可能会更好。然而,对于大多数项目,你应该不断尝试和验证:有 5 个用户的可用性测试。
#专栏作家#
郑几块,人人都是产品经理专栏作家,前新浪微博产品经理。
本文系作者@郑几块 独家翻译授权,未经本站许可,不得转载
题图来自 pexels,基于CC0协议






- 目前还没评论,等你发挥!


