
 起点课堂会员权益
起点课堂会员权益
一张图说明AI智能体的底层框架逻辑
 B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..
B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..智能体(Agent)已经成为我们生活中不可或缺的“小帮手”,从手机里的语音助手到各种自动化工具,它们通过感知环境、分析信息、做出决策并执行任务,极大地提升了我们的生活和工作效率。然而,智能体的底层框架逻辑究竟是怎样的?它如何实现从接收数据到输出结果的全过程?

AI智能体是什么,有很多解释,我们用一个简单的逻辑说明一下,
智能体 = 能干事的“小帮手”
想象你有一个小助手,它能帮你完成任务,而且自己会动脑子!它可能是:
- a、
 机器人(比如扫地机器人,看到垃圾就吸走)。
机器人(比如扫地机器人,看到垃圾就吸走)。 - b、
 手机里的软件(比如天气预报App,自动告诉你明天要不要带伞)。
手机里的软件(比如天气预报App,自动告诉你明天要不要带伞)。 - c、
 游戏里的角色(比如《我的世界》的村民,自己种地、买卖东西)。
游戏里的角色(比如《我的世界》的村民,自己种地、买卖东西)。
智能体能够感知环境、分析信息、做出决策并执行任务。它可以是虚拟助手、聊天机器人、自动化工具,甚至是物理机器人。智能体的核心特点是自主性和智能化,能够根据目标独立完成复杂任务。

智能体能够通过接收文字、图片、语音、视频和各种外部传感器接收数据。无论是文字、图片、语音、视频或者温度、压力、角度等都是一种数据,这些数据最终转化为计算器所能够理解的信息。
然后再进一步对数据进行分析,理解这些数据的含义
进一步的,根据算法、策略规则对这些分析后的信息制定策略、决策
最终通过执行机构比如回复消息,去控制设备,去控制APP下订单等方式做出反馈。
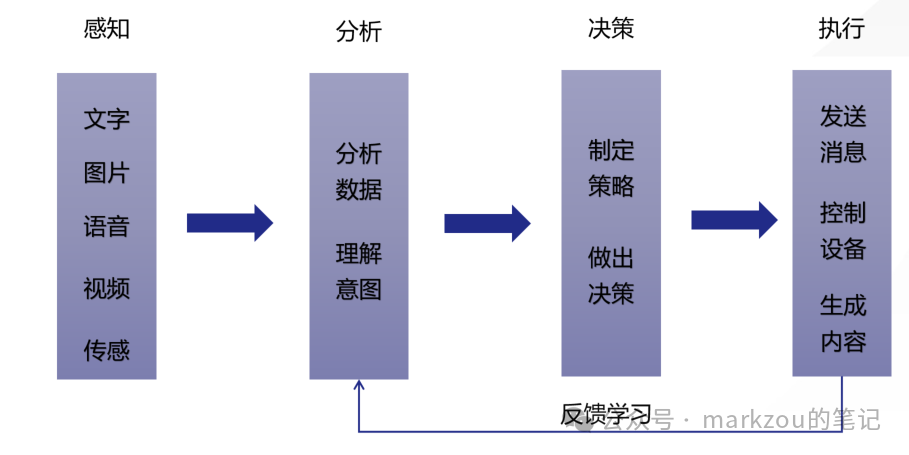
总结起来,智能体就是一个能够感知,分析决策,执行反馈的帮手。
那是否有一张图可以把智能体的逻辑讲清楚的呢,其实是可以的。如下图就将智能体的整体结构给说明白了。
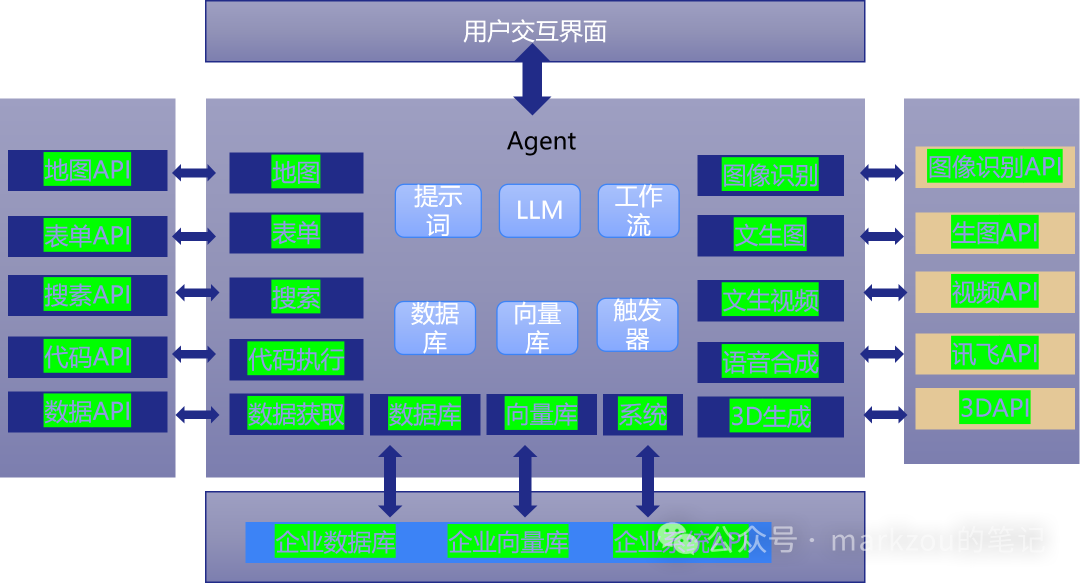
普通人与智能体的交互其实就是一个对话界面,这个界面可能直接就是一个对话框,或者是一个数字人的分身,总之就是能够进行对话的,无论这个对话是文字,语音,还是视频,还是上传文件等方式。
然后用户给智能体的信息,会由智能体进行识别,另外再加上智能体已经预先设置的提示词(智能体Agent的人设),再加上一些内容知识库。
这些内容用大模型进行分析,如果有必要去调地图、表单、搜索引擎等就会通过API方式去调用,并进一步利用大模型分析,最终再利用生图、生视频、语音合成、3D内容合成等将语言大模型的内容进一步输出为需要的内容类型给到用户。
整个过程就是用户输入的内容+人设+知识库+三方数据给到大模型,大模型进行分析,再进一步转化为用户需要内容,最后输出给用户。输入的是文字,输出要语音,图片,视频等,就可以说是多模态。
多模态可以简单理解为输入的内容形式和输出的内容形式不一样,就是跨界了。
当然这是我们的一个简单概述,实际里面的逻辑会比较复杂,后期将对智能体及大模型原理逐步展开,并介绍市面上的各种大模型工具,探讨他们如何帮助我们提升效率和效益。
本文由人人都是产品经理作者【markzou】,微信公众号:【markzou的笔记】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!









