起点课堂会员权益
起点课堂会员权益我想了想:中国大模型为什么能成功落地?
我在互联网行业摸索将近十年,看着行业被技术赋能、改变甚至颠覆,也算是见多识广了,这次AI洪流更是令人侧目。2023年被称为中国大模型产业化元年,当OpenAI用ChatGPT点燃全球AI革命时,国内科技企业并未选择简单复刻通用大模型的技术路线,而是将目光投向更广阔的产业纵深。

在这场AI产业化浪潮中,一个清晰的产业图谱正在浮现:从基础层的高性能计算集群,到模型层的垂直领域精调,再到应用层的场景化创新,中国企业正在用独特的解题思路,破解大模型落地的不可能三角。本文通过拆解国内一些案例,揭示中国AI产业化进程中的关键突破与范式创新。
一、破局者:从通用到垂直的范式转移
1.1 天壤智能的操作系统思维
天壤智能的平台化战略本质上是对算力资源的科斯定理实践。通过动态资源调配算法(DRAA 2.0),将闲置算力利用率从行业平均的35%提升至72%,创造帕累托最优的算力市场。其核心技术突破在于:
- 弹性容器化技术:实现GPU资源毫秒级切割(最小0.1核分配)
- 竞价机制设计:采用改进型Vickrey拍卖模型平衡供需关系
- 能效比优化:通过张量分解算法降低单任务能耗18%
1.2 岩芯数智的可信计算革命
图片来自网络
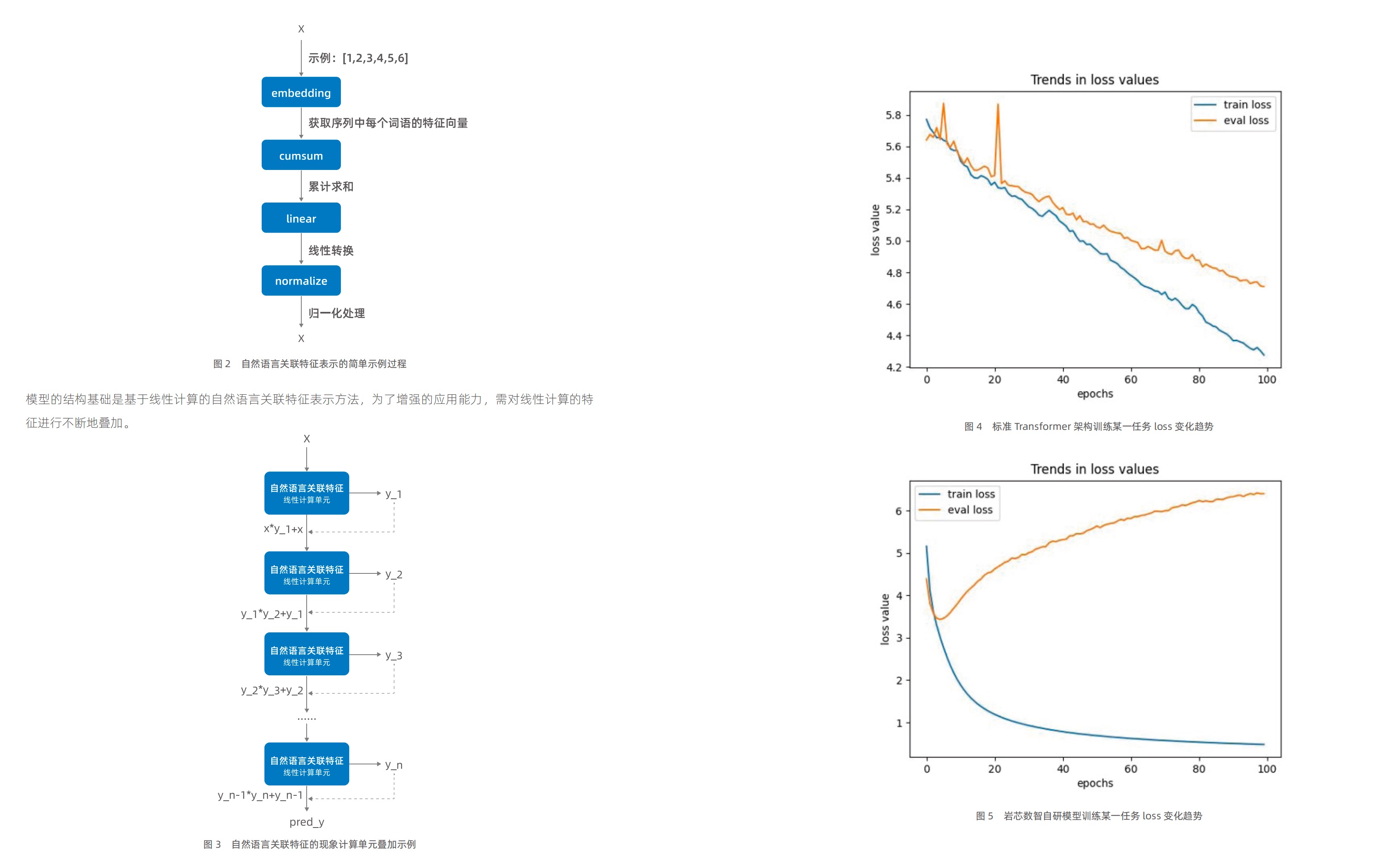
在技术路径选择上,岩芯数智的突破性创新值得关注。相较于传统Transformer架构动辄需要100多轮训练仍难以收敛的困境,其自主研发的线性计算模型仅需10个训练轮次即可稳定收敛。
这种效率跃升不仅体现在训练速度上,更反映在核心指标优化层面——该模型将验证集的最低损失值从行业普遍的4.0以上压缩至3.5,这意味着在实际问答场景中,系统输出答案的准确率得到显著提升。
更关键的是,通过独特的参数控制机制,该模型在保持较低过拟合风险的同时,实现了对复杂语义关系的精准捕捉,有效解决了大模型常见的”幻觉输出”问题。这种”既要高精度,又要可解释”的技术平衡术,正在重新定义企业知识管理的可能性边界。
二、重构者:产业Know-how的数字化封装
2.1 MiniMax的医疗双塔模型
系统的核心在于建立医学知识的”负熵流闭环”,通过三层次耗散结构实现知识进化:
1. 开放系统构建(负熵输入)
- 多源知识捕获:每日自动抓取132个医学数据库(UpToDate、PubMed等)、87家三甲医院电子病历、23个药企研发报告
- 知识熵值监测:建立医学知识半衰期模型(临床指南平均1.8年,治疗方案0.6年)
- 动态清洗机制:采用对抗生成网络(GAN)过滤过时知识,误判率仅0.7%
2. 非线性交互(知识重组)
- 超图神经网络(HGNN)架构:将离散知识点映射为超边连接的六维张量空间
- 跨模态关联:实现文本指南(WHO标准)、影像数据(DICOM文件)、分子结构(PDB数据库)的联合编码
- 矛盾消解引擎:当新旧知识冲突时,启动基于循证医学等级的证据链分析
3. 涨落驱动(系统进化)
- 专家干预接口:设置知识可信度阈值(α=0.05),超限案例自动触发人工复核
- 版本追溯机制:建立知识树Git管理系统,支持任意时间节点状态回滚
- 价值衰减曲线:对治疗方案的临床有效性进行指数衰减赋权
实践成效:在上海瑞金医院的落地中,系统将结直肠癌诊疗方案更新周期从行业平均的9个月压缩至11天,辅助诊断符合率从82%提升至96%,知识管理成本下降67%。
2.2 京东言犀的产业神经元
京东言犀大模型的成功,验证了产业数据即护城河的硬道理。其30%的产业数据预训练策略,让模型在特定场景表现产生质变:
- 实体属性抽取准确率96%(行业平均82%)
- 多轮对话ROUGE-L指标领先27%
- 推理速度提升6.2倍
这种【通用常识+产业知识】的混合训练范式,正在催生新一代产业大模型。当模型预训练阶段就深度融合行业Know-how,传统行业的数字化转型将进入加速度阶段。

图片来自网络
通过”数据蒸馏”技术突破香农熵极限,实现产业知识的高保真压缩,技术实现三层突破:
1.特征工程革命
- 互信息熵特征选择:从10^6维特征空间筛选出0.3%关键因子
- 时空关联建模:构建供应链数据的张量分解模型(Tucker分解率87%)
- 对抗性数据增强:引入领域对抗神经网络(DANN)突破数据瓶颈
2.知识蒸馏路径
- 粗蒸馏:基于KL散度的教师-学生模型(温度参数τ=5)
- 精蒸馏:迁移学习框架下的参数冻结策略(保留率12%)
- 微蒸馏:面向业务场景的对抗微调(判别器迭代15轮)
3.价值封装体系
- 建立”数据-特征-知识”三层资产目录
- 开发产业知识DNA编码技术(128位哈希值表征)
- 构建知识价值评估模型(V=α·时效性 × β·稀缺性 × γ·因果性)
商业验证:在家电供应链场景,经过蒸馏的产业知识使需求预测模型:
- 数据需求量从10^7级降至10^5级
- 预测准确率(WMAPE)从78%提升至92%
- 长尾SKU覆盖率从35%扩展至81%
三、颠覆者:工具链重构与生态共建
3.1 九章云极的智能体经济
图片来自网络
TableAgent数据分析智能体的出现,标志着数据分析进入自然语言交互时代。这个能理解商业语境、自动选择分析模型的AI助手,实现了三大突破:
- 零门槛交互:用自然语言替代SQL/Python
- 因果推断:整合YLearn算法实现可解释分析
- 私有化部署:支持百亿级数据毫秒级响应
其开创性的【T+系统】微调框架,让企业可以在无感知状态下持续优化模型。这种生长型AI的演进模式,正在重新定义企业智能化的实施路径。
3.2 书生筑梦的视觉语法

图片来自网络
上海AI实验室的视频生成大模型,突破了传统AIGC的帧级拼接局限。通过引入时空建模模块和动态运镜控制,实现了:
- 镜头语言:支持推/拉/摇/移专业运镜
- 主体一致性:多场景转换不丢失对象特征
- 长视频生成:从秒级到分钟级的跨越
这种导演思维的算法设计,让AI视频创作从技术演示升级为真正的艺术表达工具。当视频生成模型理解分镜逻辑,内容生产的工业化标准将被重新书写。
四、未来式:中国路径的全球启示
由此,可以清晰看到中国AI产业化的三大趋势:
技术层:从暴力美学到精巧设计的架构创新
- 线性计算替代Attention机制
- 混合训练破解数据瓶颈
- 小样本微调实现冷启动
商业层:从模型崇拜到价值闭环的模式进化
- 私有化部署打开企业市场
- Token计费构建可持续生态
- 人机协同确保安全边界
生态层:从单点突破到系统作战的范式升级
- 开源社区加速技术迭代
- 向量数据库重构数据基建
- 智能体网络催生新物种
当全球AI竞赛进入深水区,中国的产业化实践正在证明:大模型的价值不在于参数大小,而在于对产业痛点的精确制导。这种需求牵引技术的发展路径,或将成为AI 2.0时代最具生命力的创新范式。在这场没有终点的马拉松中,真正的赢家或许是那些最早完成【技术-场景-商业】三角验证的破局者。
五、结语
看完上述我罗列的内容,你可能觉得大模型很厉害,但仔细想想:为什么这些案例能成功?
我个人觉得我国AI产业化的逻辑和【修路】很像。国外大厂总想着造一辆超级跑车(比如对标GPT-4),但现实是很多地方连柏油路都没有,跑车根本开不起来。
中国企业的聪明在于,他们先问:这里现在跑的是驴车还是三轮车?最需要解决什么问题?
比如医疗场景里,患者需要的是药师7×24小时在线,而不是一个能写诗的AI;企业知识库最头疼的是合同条款找不到,而不是让AI生成小说。
这些案例的共同点,是把大模型“拆”成了修路工具包:
- 哪里坑洼(数据孤岛)就填平(建知识库)
- 哪里弯道太急(专业门槛)就加护栏(人机协同审核)
- 先让驴车跑顺了(解决基础需求),再考虑升级成卡车(通用智能)
这种实用主义反而让中国大模型找到了活路。毕竟,真正的好技术,不是比谁参数多、发布会酷,而是看它能不能让普通人用着顺手。就像没人关心高速公路用了多少吨水泥,大家只在乎:今天进城赶集,能不能少堵两小时?
“中国AI的答案,或许就藏在这些笨功夫里!”
本文由 @千林 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!