
 起点课堂会员权益
起点课堂会员权益同样是AI工具,为什么国内放弃全局个性化?
ChatGPT与国内AI工具在个性化体验上的差异,究竟是技术瓶颈还是战略选择?本文深度剖析了从产品定位到技术实现的底层逻辑差异,揭示了ChatGPT的全局记忆与豆包/Kimi的场景化方案背后的商业考量与技术路径,并给出了在现有条件下实现个性化AI助手的实用技巧。

在使用ChatGPT时,用户可以设置下图个性化内容,当AI记住这些要求后,会跨对话永久生效。
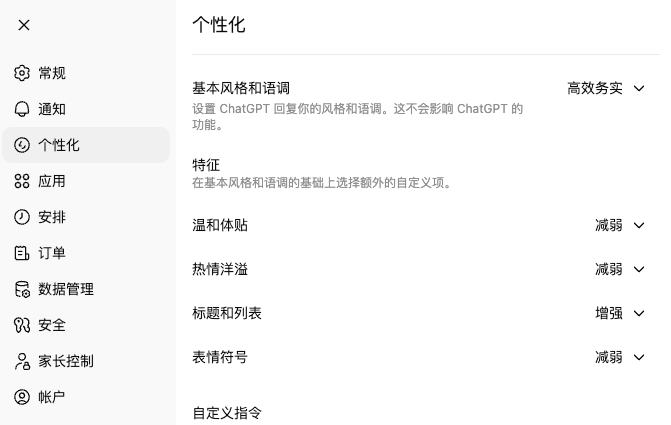
而打开豆包/Kimi/元宝等国内工具,个性化仅停留在更换形象/声音/主题等基础层面。这种体验差异究竟源于技术差距,还是产品策略的主动选择?本文从三个方面进行剖析,并给出实操建议和未来预判。
一、不同的设计理念和产品策略
ChatGPT的个性化建立在系统级持久化基础上,用户设置一次自定义指令后,所有新对话都会自动继承这些偏好。这种设计理念源于OpenAI对产品的定位——面向开发者和重度用户的生产力操作系统,让ChatGPT具备“数字员工”的属性,用户在某种程度上是在培养一个越来越了解自己的AI助手,与近期热门的 OpenClaw 有异曲同工之处。
豆包的个性化集中在三个层面:回答风格选择、界面主题调整、智能体创建。其中智能体功能确实提供了类似GPTs的能力,用户可以自定义角色描述、设定专属提示词、配置声音语调。但这些设置的全局生效范围有限,每个智能体更像是一个独立的对话实例,而非贯穿整个产品的个性化底层设置。Kimi的策略则是通过@指令、常用语模板、场景化角色来满足用户的即时需求。这种设计的好处是交互足够轻量,打开应用就能直接开始对话,不需要任何前置配置。
两种路径背后对应着不同的市场受众。ChatGPT面对的是全球用户,其中相当比例是开发者、程序员、内容创作者等对工具深度有要求的群体。这些用户愿意花时间配置自己的AI助手,因为长期使用能够显著提升效率。国内AI工具面对的是更为庞大的大众市场,用户打开应用的预期可能是“随便问问”或者“快速解决一个问题”,设置门槛的存在反而可能造成流失。
其次,ChatGPT 的核心商业模式是用户付费订阅。用户持续付费的核心动力,是更贴合个人需求、更高效的使用体验,全局个性化是提升付费用户留存的核心功能。国内 AI 工具的变现逻辑更加多元,除了 C 端订阅,还有 B 端行业解决方案、智能体生态商业化、场景化增值服务等多个方向。全局的个性化助手,和商业化布局的方向并不太契合,加上国内付费习惯和占比与国外仍有不少差距,暂时不会成为产品迭代的核心重点。
二、不一样的技术和成本方案
从技术实现角度,国内AI工具并非没有解决个性化问题的能力,而是选择了另一条技术路径来达到类似效果。
豆包的技术路线体现了字节跳动一贯的产品思维。豆包背后是字节强大的模型能力和多模态布局,在文本、语音、图像生成方面都有覆盖,个性化在豆包这里的实现方式是通过丰富的智能体生态来解决。用户可以创建多个针对不同场景的智能体,比如“文案助手”、“代码顾问”、“学习管家”,在不同任务下调用不同的智能体,本质上也是通过场景划分来实现个性化的方式。这种方案虽然没有ChatGPT那种全局记忆功能,但在实际使用中已经能够满足大部分需求。
Kimi最核心的技术优势是超长上下文理解能力,目前已经支持200万字的无损上下文。这意味着用户不需要AI记住自己的偏好,因为可以把任何背景信息、参考文档直接丢给Kimi处理。当其他产品还在强调记住用户是谁时,Kimi的解决思路是随时把上下文喂给AI。这种方案在某些场景下确实更加高效,特别是处理长文档、专业文献时,直接上传文件比预先配置设置更加直观。
值得注意的是,国内AI工具在即时可用性上的投入远超个性化功能。豆包的语音交互、内容创作等功能都被放在核心位置,这些功能的价值在于降低使用门槛,让用户不需要任何学习成本就能获得AI能力。而个性化设置本质上是有门槛的功能,需要用户理解提示词工程、了解模型特性,这本身就与大众化AI助手定位存在冲突。
同时,全局个性化设定在技术层面本质上是给每一次对话加上一段系统提示词,意味着大模型在后台需要把个人设定一并阅读并进行综合推理。几百万甚至上千万活跃用户每天产生海量的对话,都要额外消耗大量Token去处理个性化背景信息,会是一笔惊人的费用成本。在国内AI厂商普遍推行免费策略、大打价格战的今天,对算力成本的控制是重要指标。为了保证整体服务的响应速度和成本控制,当下也是符合商业逻辑的选择。
三、不容忽视的合规考量
除了产品/技术/成本因素外,个性化设置的缺失还与国内AI行业面临的特殊环境有关。ChatGPT的记忆功能允许AI跨对话积累用户信息,这背后是用户对数据存储的信任。在国内环境下,用户数据的收集、存储、使用受到更为严格的监管。如果AI工具要实现类似的持久化记忆功能,就需要承担更大的数据安全责任和合规风险。豆包、元宝、千问等作为大厂产品,在数据处理上天然更为谨慎。
另一个容易被忽视的问题是用户画像与内容安全的关联。当AI记住“用户是一位关注政治的评论员”或者“用户对某个争议话题有特定立场”时,这些画像信息会增加内容审核的复杂度。无状态的对话交互反而在监管层面更加可控。这种设计上的保守虽然是出于风险考量,但确实在一定程度上限制了产品的个性化深度。
四、当下就能用的实操方案
不用纠结功能的差异,合理利用现有的产品能力,也能搭建出贴合自己需求的个性化使用体系。
拿豆包举例,可考虑自建专属的个人智能体。在智能体创建页面,把自己的职业背景、核心使用场景、输出要求等内容,全部写入设定描述中,再将智能体置顶。后续主要对话都从这个智能体入口进入,相当于拥有了一个全局生效的个性化 AI 助手,不用每次重新说明要求。
如果嫌智能体麻烦,还有一个小技巧:根据不同的问题类型建立不同对话,并将常用设置为置顶(置顶这个小设计,各家也有所差异,其中豆包的设计更为灵活)。这样大模型结合上下文记忆能力也能快速、精准输出内容。
五、AI产品的迭代预判
从产品演进规律来看,引入更多个性化功能是大概率事件。
当前的市场格局决定了各家的首要任务是跑马圈地,但随着用户增长逐渐见顶,如何留住用户会成为新的核心问题。工具类应用的最终竞争往往走向谁更懂用户,国内主流 AI 工具大概率会在用户规模达到一定量级后,逐步强化个性化能力。
但这种个性化可能不会以ChatGPT的方式呈现,更可能采用隐性化策略,通过分析用户行为数据在后台静默完成,减少让用户手动配置。更符合国内用户的隐私观念,也能避免设置门槛带来的流失风险。豆包在多模态能力的持续投入、Kimi在长上下文能力的深耕,以及近期各家集成OpenClaw等能力,都是在为未来的个性化能力打基础。
结语
国内 AI 工具在全局个性化上的差异,背后是产品定位、技术架构、成本控制、合规环境的综合考量。
对大多数用户而言,不用刻意追求 ChatGPT 的配置体验,找到适配的工具特性,理解产品背后的逻辑差异,也能更大程度提升自己的使用效率。
AI技术和产品仍在快速迭代,今天的功能差异也未必是终局。
作者:实战产品说 公众号:实战产品说
本文由 @实战产品说 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


