
 起点课堂会员权益
起点课堂会员权益向量库、关键词检索、MySQL:别再混成一个东西
检索系统背后的技术选择常被误解为简单的二选一,但实际上MySQL、关键词检索和向量检索在三层架构中各司其职。本文将彻底拆解数据基座、检索层与应用层的协作逻辑,揭示倒排索引与向量索引如何通过不同维度的'翻译'实现高效搜索,帮助产品经理在技术选型时建立清晰的架构思维。

开头
上一篇我们聊了一个很多人会搞混的问题:
RAG、微调、提示词,到底谁管什么?
结论是它们不是替代关系,而是分工关系——RAG 管事实,微调管能力,提示词管轻量控制。
但聊完之后你会发现,一个新问题马上跟着来了:
RAG 里那个”检索”,到底是怎么工作的?
一说到检索,三个词就经常同时出现:MySQL、关键词检索、向量检索。
而且很多讨论里,它们会被直接放在一张对比表里:
“我们是用 MySQL 查,还是用向量库查?关键词检索还要不要?”
这个问题听上去很自然。
但它藏着一个前提错误——它把三个不在同一层的东西,拉到了同一张比较表里。
这篇文章不打算讲”谁更高级”,而是要做一件更基础的事:
把这三个经常被混着说的概念,拆到它们各自该在的位置上。
拆完之后你会发现,它们的关系比”谁替代谁”清晰得多。
一、先建一个整体画面
在讲任何细节之前,我想先给你一张全局图。
你可以把一个检索系统想象成三层:
┌─────────────────────────────────────────┐
│ 应用层(搜索/RAG/客服) │
│ “用户问了一个问题,我要找到答案” │
└────────────────────┬────────────────────┘
│ 查询
▼
┌─────────────────────────────────────────┐
│ 检索层(索引 + 匹配) │
│ │
│ ┌───────────────┐ ┌───────────────┐ │
│ │ 关键词检索 │ │ 向量检索 │ │
│ │ (倒排索引) │ │ (向量索引) │ │
│ │ 按词匹配 │ │ 按语义匹配 │ │
│ └───────┬───────┘ └───────┬───────┘ │
│ │ │ │
│ └────────┬─────────┘ │
│ │ 命中的文档 ID │
└────────────────────┬────────────────────┘
│ 拿 ID 回去取完整数据
▼
┌─────────────────────────────────────────┐
│ 数据层(数据库) │
│ │
│ MySQL / PostgreSQL 等 │
│ 存着完整的原始数据(所有字段) │
│ │
└─────────────────────────────────────────┘
这张图是这篇文章最核心的一张图,后面所有内容都围绕它展开。
先记住一个关键结论:
最底下的数据库是”数据基座”。中间的关键词检索和向量检索,本质上是把基座里的数据”翻译”成了不同的索引形式,让上层能更快、更准地找到想要的内容。
但无论中间走的是哪条路——关键词也好,向量也好——最终返回给你的,都是数据库里那条完整的原始数据。
接下来我们一层一层拆。
二、最底层:数据库是”数据基座”
MySQL 是一个关系型数据库。你可以把它理解成一个超大的、有结构的 Excel 表。
比如一个智能客服系统,知识库可能长这样:
┌──────────────────────────────────────────────────────────────────┐
│ knowledge_base 表 │
├──────┬────────────────────────┬──────────┬────────┬──────────────┤
│ id │ content │ category │ source │ updated_at │
├──────┼────────────────────────┼──────────┼────────┼──────────────┤
│ 1 │ Atomic全地域板适合中级… │ 滑雪板 │ 官网 │ 2024-12-01 │
│ 2 │ binding安装需要4号螺丝… │ 固定器 │ 手册 │ 2024-11-15 │
│ 3 │ 新手建议选择软硬度3-5… │ 滑雪靴 │ 社区 │ 2024-12-20 │
│ 4 │ Burton公园板适合玩跳台… │ 滑雪板 │ 官网 │ 2024-12-10 │
│ 5 │ 头盔选购要注意认证标准… │ 安全装备 │ 手册 │ 2024-11-20 │
│ … │ … │ … │ … │ … │
└──────┴────────────────────────┴──────────┴────────┴──────────────┘
MySQL 非常擅长做这些事:
- 按条件精确查:查 category = ‘滑雪板’ 的所有记录
- 范围过滤:查 updated_at 在最近 30 天内的记录
- 关系管理:这张表和用户表、订单表之间的关联
但如果用户问了一句:
“我是新手,想买个固定器,有什么推荐吗?”
MySQL 能做的大概就是:
SELECT * FROM knowledge_base
WHERE content LIKE ‘%新手%’
AND content LIKE ‘%固定器%’
逐行扫描,按字符硬匹配。
它不会知道”新手”和”初学者”是一回事。它也不会知道第 3 条虽然没提”固定器”,但里面关于”软硬度选择”的内容对新手选装备也很有参考价值。
这不是 MySQL 的缺陷。它本来就不是为”理解用户在问什么”而设计的。
它的角色是:
稳稳地把数据存好,等别人告诉它要取哪一行,它精确地把完整数据交出来。
这就是为什么我把它叫做”数据基座”——所有的原始信息都在它这里,但”怎么找到该取哪一行”这件事,需要交给上面的检索层来做。
三、中间层:检索层在做”翻译”
现在关键问题来了:
数据库里有几万甚至几十万条数据,用户随便说了一句话,系统怎么知道应该取哪几条?
靠 MySQL 自己不行——它只会逐条扫描、按字符硬匹配,既慢又傻。
所以需要在数据库之上,搭建一个检索层。
检索层做的事情本质上是:
提前把数据库里的内容”翻译”成更容易被搜索到的形式,建好索引,等查询来了直接查索引。
这种”翻译”有两种方式:
┌─────────────────────────────────────────────────┐
│ 原始数据(数据库) │
│ “Atomic全地域板适合中级以上玩家,全地形适用…” │
└──────────────┬──────────────────┬────────────────┘
│ │
┌──────▼──────┐ ┌─────▼───────┐
│ 翻译方式 A │ │ 翻译方式 B │
│ 拆成”词” │ │ 转成”向量” │
│ 建倒排索引 │ │ 建向量索引 │
└──────┬──────┘ └──────┬──────┘
│ │
┌──────▼──────┐ ┌─────▼───────┐
│ 关键词检索 │ │ 向量检索 │
│ 按词匹配 │ │ 按语义匹配 │
└─────────────┘ └─────────────┘
翻译方式 A——把文本拆成词,建倒排索引,这就是关键词检索。
翻译方式 B——把文本转成向量,建向量索引,这就是向量检索。
两种翻译方式各有擅长的场景。我们一个一个拆。
四、翻译方式 A:关键词检索
4.1 第一步:分词
关键词检索的起点是分词。
分词就是把一段完整的文本,拆成一个个独立的词(也叫 token)。
┌──────────────────────────────────┐
│ 原始文本 │
│ “Atomic全地域板适合中级以上玩家” │
└──────────────────┬───────────────┘
│ 分词
▼
┌──────────────────────────────────┐
│ 分词结果 │
│ [ atomic ] [ 全地域 ] [ 板 ] │
│ [ 适合 ] [ 中级 ] [ 以上 ] [ 玩家 ] │
└──────────────────────────────────┘
分词器的好坏直接影响后面所有环节。因为搜索引擎不是理解一整句话,而是围绕这些切出来的 token 做所有匹配工作。
不同语言的分词难度也不同:
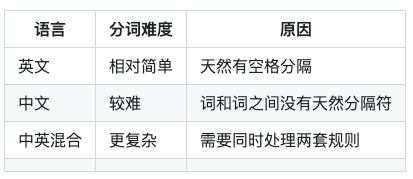
比如”滑雪板固定器”,分词器要能判断这应该切成”滑雪板 + 固定器”,而不是”滑雪 + 板固 + 定器”。
4.2 第二步:建倒排索引
分好词之后,系统要把这些词组织成一种特殊的数据结构——倒排索引。
正常情况下,数据的组织方式是:
正向:文档 → 包含哪些词
文档1 → [ atomic, 全地域, 板, 适合, 中级, 玩家 ]
文档2 → [ binding, 安装, 螺丝 ]
文档3 → [ 新手, 建议, 软硬度 ]
倒排索引把这个关系反过来:
倒排:词 → 出现在哪些文档里
atomic → [ 文档1 ]
全地域 → [ 文档1 ]
板 → [ 文档1, 文档4 ]
binding → [ 文档2 ]
安装 → [ 文档2 ]
新手 → [ 文档3 ]
软硬度 → [ 文档3 ]
为什么要倒过来?
因为用户搜索时,给你的是词,不是文档编号。
如果是正向索引,你要拿着这个词逐条去每个文档里找——跟 MySQL 的 LIKE 查询一样慢。
如果是倒排索引,你拿着”新手”这个词直接查表,瞬间就能知道它出现在哪些文档里。
用户搜索固定器.png
用户搜索:”新手 固定器”
│
┌─────────┴─────────┐
▼ ▼
查”新手” 查”固定器”
│ │
▼ ▼
命中:文档3 命中:文档2
│ │
└─────────┬─────────┘
▼
候选集:文档2、文档3
这就是倒排索引的价值:不用逐条扫描,直接通过词定位到文档。
4.3 第三步:BM25 打分排序
找到候选文档之后,系统不会随便排个顺序就返回。它会用一个打分算法来判断:这些候选里,谁跟用户的查询更相关?
最经典的打分算法就是 BM25。
BM25 考虑三个核心因素:
BM25 打分逻辑.png
┌─────────────────────────────────────────────────────┐
│ BM25 打分逻辑 │
│ │
│ ┌─────────────┐ │
│ │ ① 词频 TF │ 这个查询词在文档里出现了几次? │
│ │ │ 出现越多,通常越相关 │
│ └─────────────┘ │
│ │
│ ┌─────────────┐ │
│ │ ② 稀有度 IDF │ 这个词在所有文档里有多常见? │
│ │ │ 越稀有的词,区分能力越强,权重越高 │
│ └─────────────┘ │
│ │
│ ┌─────────────┐ │
│ │ ③ 文档长度 │ 同样出现一次,短文档里的命中 │
│ │ │ 通常比长文档里更”集中” │
│ └─────────────┘ │
└─────────────────────────────────────────────────────┘
举个例子帮你理解”稀有度”为什么重要:
假设用户搜的是”碳纤维双板”。
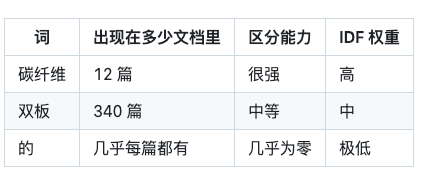
“碳纤维”这种词很稀有,一旦命中就说明大概率是相关的,所以 BM25 给它的权重高。而”的”这种词到处都有,命中了也不能说明什么,权重就极低。
BM25 综合这三个因素,给每个候选文档算出一个分数,然后按分数排序返回。
4.4 多个关键词时怎么处理
如果用户搜的不只一个词,比如”新手 滑雪板 固定器”,系统会分成三个词分别去查倒排索引:
“新手 滑雪板 固定器”
│
│ 分词
▼
┌─────┼──────────┐
▼ ▼ ▼
新手 滑雪板 固定器
│ │ │
▼ ▼ ▼
文档3 文档1,4 文档2
这时候有个关键决策:命中几个词才算”相关”?
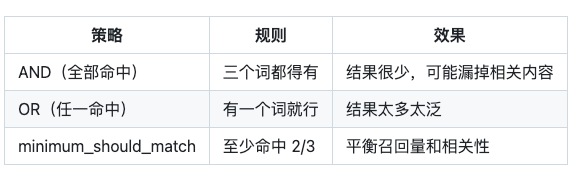
真实系统通常用的是第三种——minimum_should_match,比如要求”三个词至少命中两个”。
这样既不会因为太严格而什么都找不到,也不会因为太宽松而把一堆不相关的内容带进来。
4.5 关键词检索的完整流程
把上面这些串起来
┌───────────────────┐
│ 用户查询 │
│ “新手 固定器” │
└─────────┬─────────┘
│ ① 对查询分词
▼
┌───────────────────┐
│ [ 新手 ] [ 固定器 ] │
└─────────┬─────────┘
│ ② 查倒排索引
▼
┌───────────────────┐
│ 新手 → 文档3 │
│ 固定器 → 文档2 │
└─────────┬─────────┘
│ ③ 合并候选
▼
┌───────────────────┐
│ 候选集:文档2、文档3 │
└─────────┬─────────┘
│ ④ BM25 打分排序
▼
┌───────────────────┐
│ 文档3:0.82 分 │
│ 文档2:0.65 分 │
└─────────┬─────────┘
│ ⑤ 拿文档 ID 回数据库取完整数据
▼
┌───────────────────┐
│ 返回完整的行数据 │
│ 包括 content、 │
│ category、source 等│
└───────────────────┘
注意最后一步——拿着文档 ID 回数据库取完整数据。
关键词检索自己只存了”词和文档 ID 的对应关系”,真正的完整内容还是存在数据库里。检索层找到的是”哪几条相关”,数据层交出的才是”完整内容”。
五、翻译方式 B:向量检索
5.1 为什么还需要另一种翻译方式
关键词检索已经比 MySQL 的 LIKE 强了很多:更快、有分词、有打分排序。
但它有一个根本限制:只认字面,不认语义。
┌───────────────────────────────────────────────┐
│ 关键词检索搞不定的情况 │
│ │
│ 用户搜 “binding” │
│ 知识库里写的是 “固定器” │
│ → 字面完全不同,倒排索引查不到 │
│ │
│ 用户搜 “初学者怎么选板” │
│ 知识库里写的是 “新手建议选择软硬度3-5…” │
│ → “初学者”和”新手”字面不同,可能漏掉 │
│ │
│ 用户搜 “我怕摔,想要稳一点的” │
│ 知识库里写的是 “全地域板稳定性好,适合进阶学习” │
│ → 完全是意思层面的关联,关键词检索基本匹配不上 │
└───────────────────────────────────────────────┘
这些场景有一个共同特点:用户说的和知识库写的,意思一样但字不一样。
向量检索就是为了解决这个问题。
5.2 向量是什么
向量说白了就是一串数字。
向量检索的核心思路是:用一个训练好的模型(叫 embedding 模型),把文本转换成一串数字。语义接近的文本,转出来的数字会很相似。
┌─────────────────────────────────────────────────┐
│ 文本 → 向量 │
│ │
│ “固定器” │
│ → [ 0.21, -0.15, 0.87, 0.33, … ] (768维) │
│ │
│ “binding” │
│ → [ 0.19, -0.13, 0.85, 0.31, … ] (768维) │
│ │
│ “滑雪靴” │
│ → [ 0.65, 0.42, -0.12, 0.08, … ] (768维) │
│ │
│ ✅ “固定器”和”binding”的向量非常接近 │
│ ❌ “固定器”和”滑雪靴”的向量差距较大 │
└─────────────────────────────────────────────────┘
你不需要理解这些数字是怎么算出来的。你只要知道一件事:
意思越接近的文本,向量之间的”距离”越近。
这就像一个翻译器:它不关心字面写的是什么语言、用的是什么词,它只管把”意思”翻译成一个坐标点。意思相近的内容,坐标就挨得近。
5.3 向量检索怎么找内容
把所有知识库内容提前转成向量,存好。
查询来了,也转成向量。
然后在向量空间里找”离得最近的几个”。
向量空间(简化 2D 示意)
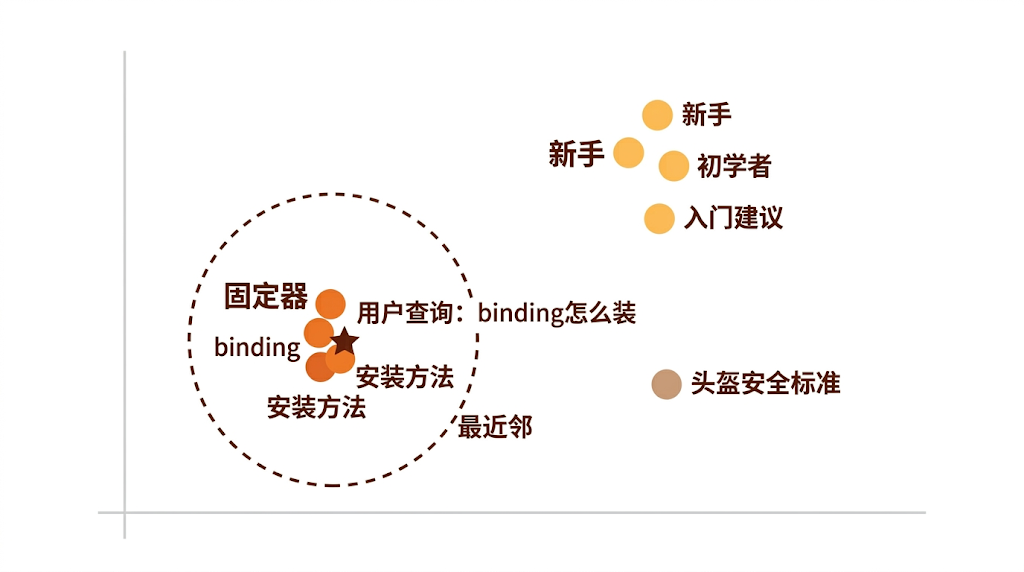
★ = 用户查询的向量位置
● = 各文档的向量位置
离 ★ 最近的是文档2 → 最相关
其次是文档3 → 也有一定相关性
文档5 离得最远 → 不太相关
向量检索就是做这件事:在高维空间里,找离查询向量最近的那些文档向量。
5.4 向量检索的完整流程
┌───────────────────────┐
│ 用户查询 │
│ “binding怎么装” │
└──────────┬────────────┘
│ ① 用 embedding 模型转成向量
▼
┌───────────────────────┐
│ 查询向量 │
│ [0.19, -0.13, 0.85…] │
└──────────┬────────────┘
│ ② 在向量索引中搜索最近邻
▼
┌───────────────────────┐
│ 最近邻结果 │
│ 文档2:距离 0.08 │
│ 文档3:距离 0.35 │
│ 文档4:距离 0.41 │
└──────────┬────────────┘
│ ③ 拿文档 ID 回数据库取完整数据
▼
┌───────────────────────┐
│ 返回完整的行数据 │
│ 包括 content、 │
│ category、source 等 │
└───────────────────────┘
注意,最后一步和关键词检索一模一样——拿着文档 ID 回数据库取完整数据。
向量索引里存的也不是完整的原始内容,而是向量和文档 ID 的对应关系。真正的数据,还是在数据库这个”基座”里。
5.5 向量检索不擅长什么
向量检索在语义匹配上很强,但它也有短板:
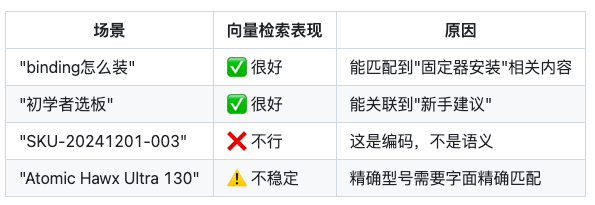
对于强结构、强精确的查询,向量检索反而可能把”语义上沾边但实际不对”的内容拉进来。
它不是”更高级的检索”,而是”擅长另一类问题的检索”。
六、两种翻译,一个基座
现在我们可以把整个图画完整了:
┌───────────────────────────────────────────────────┐
│ 数据库(数据基座) │
│ │
│ id │ content │ category │ source │ … │
│ 1 │ Atomic全地域板… │ 滑雪板 │ 官网 │ │
│ 2 │ binding安装… │ 固定器 │ 手册 │ │
│ 3 │ 新手建议选择… │ 滑雪靴 │ 社区 │ │
│ … │ … │ … │ … │ │
│ │
└───────────┬───────────────────────┬───────────────┘
│ │
┌──────▼──────┐ ┌──────▼──────┐
│ 翻译方式 A │ │ 翻译方式 B │
│ │ │ │
│ 对 content │ │ 对 content │
│ 做分词 │ │ 做 embedding│
│ 建倒排索引 │ │ 建向量索引 │
└──────┬──────┘ └──────┬──────┘
│ │
┌──────▼──────┐ ┌──────▼──────┐
│ 倒排索引 │ │ 向量索引 │
│ │ │ │
│ atomic→[1] │ │ id1→[0.2,…] │
│ 固定器→[2] │ │ id2→[0.5,…] │
│ 新手→[3] │ │ id3→[0.1,…] │
└──────┬──────┘ └──────┬──────┘
│ │
│ 查询:”binding怎么装” │
│ │
┌──────▼──────┐ ┌──────▼──────┐
│ 关键词匹配 │ │ 向量相似度 │
│ 命中:文档2 │ │ 最近:文档2 │
│ (字面命中 │ │ (语义命中 │
│ binding) │ │ binding≈固定器)│
└──────┬──────┘ └──────┬──────┘
│ │
└───────────┬───────────┘
│
▼
┌──────────────────┐
│ 合并候选文档 ID │
│ 去重 │
└────────┬─────────┘
│
▼ 拿 ID 回数据库取完整数据
┌──────────────────┐
│ 返回完整行数据 │
│ id=2 │
│ content=… │
│ category=固定器 │
│ source=手册 │
└──────────────────┘
两条路径,最终都回到了同一个地方:数据库。
这就是为什么说数据库是”基座”——关键词检索也好,向量检索也好,本质上都是在基座之上建的”索引翻译层”。它们的职责是帮上层更快更准地定位到相关内容,但内容本身,始终存在数据库里。
补充:实际系统中的常见做法
上面的流程为了讲清楚”三层各管什么”,画的是一个标准的分层模型。但在实际的客服 RAG 系统里,你会看到一种更常见的做法:入库前先把长文档拆成小段(chunk),然后每个 chunk 的文本直接和向量一起存进向量库。
比如一条很长的知识库内容,会被拆成这样:
原始文档:
“Atomic全地域板适合中级以上玩家,全地形适用。板长建议身高减10-15cm。
硬度偏硬,适合有一定基础的滑手。价格区间3000-5000元……”
拆成 chunks 后存入向量库:
chunk_1: “Atomic全地域板适合中级以上玩家,全地形适用” → 向量 [0.21, -0.15, …]
chunk_2: “板长建议身高减10-15cm,硬度偏硬” → 向量 [0.18, 0.33, …]
chunk_3: “适合有一定基础的滑手,价格区间3000-5000元” → 向量 [0.45, -0.08, …]
这样检索命中后,向量库直接就能返回相关的文本片段,不需要再绕回数据库取。这也是为什么很多 RAG 教程里,你看到的是”向量库直接返回内容”而不是”返回 ID 再回查”。
但如果你还需要完整的原始记录(比如要拿 category、source、updated_at 这些字段),仍然需要通过 ID 回数据库查。
两种方式不矛盾——区别只在于”入库时拆没拆、文本存没存进向量库”。三层的分工关系不变。
七、真实系统里:混合检索
理解了两种翻译方式之后,一个自然的问题是:
真实业务里,到底用哪种?
答案是:通常两种一起用。
这就是混合检索(Hybrid Search)。
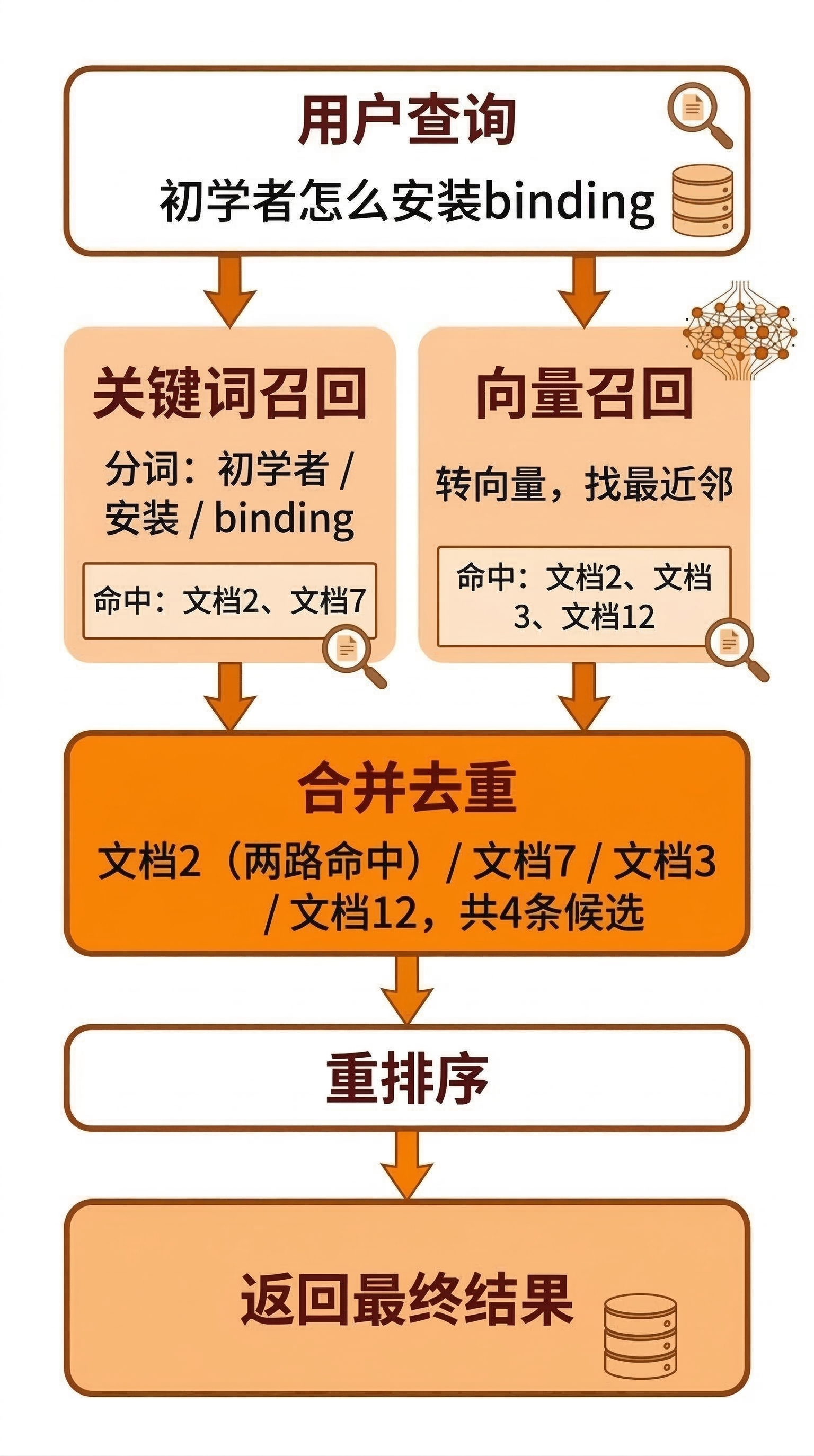
关键词检索负责捞到字面命中的内容——用户明确说了”binding”,那含有”binding”这个词的文档一定要进来。
向量检索负责补上语义相关但字面没命中的内容——知识库里那篇写”初学者建议选择软硬度3-5″的内容,虽然没提”binding”和”安装”,但语义上跟这个问题有关系。
合并取的是并集,不是交集。
如果只保留两边都命中的内容,向量检索”补充关键词漏召回”的价值就完全没有了。
混合检索的好处用一张表总结:
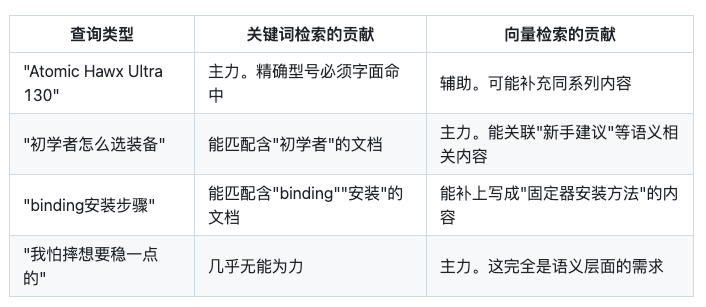
八、完整链路:从用户提问到拿到答案
到这里,我们可以把整个链路串一遍了。
以一个智能客服 RAG 系统为例,用户问了一句”初学者怎么安装固定器”,系统从头到尾做了什么:
┌────────────────────────────────────────────────────┐
│ ① 数据准备阶段(提前做好的) │
│ │
│ 数据库存好所有知识库内容 │
│ ↓ │
│ 对长文档做分段(chunking)→ 拆成适合检索的小段 │
│ ↓ │
│ 对每个分段做分词 → 建好倒排索引 │
│ 对每个分段做 embedding → 建好向量索引 │
└────────────────────────────────────────────────────┘
以上只需要做一次(数据更新时重新做)
─────────────────────────────────
以下每次查询都会走
┌────────────────────────────────────────────────────┐
│ ② 查询阶段 │
│ │
│ 用户提问:”初学者怎么安装固定器” │
│ ↓ │
│ 关键词检索:分词 → 查倒排索引 → BM25 打分 → 召回候选 │
│ 向量检索:embedding → 查向量索引 → 相似度打分 → 召回候选 │
│ ↓ │
│ 两路候选合并去重 │
│ ↓ │
│ 排序(决定哪些内容最相关) │
│ ↓ │
│ 拿排在前面的文档 ID,回数据库取完整数据 │
│ (如果向量库里已经存了 chunk 文本,也可以直接返回) │
│ ↓ │
│ 把相关内容喂给大模型,生成最终回答 │
└────────────────────────────────────────────────────┘
每个组件各管一段:
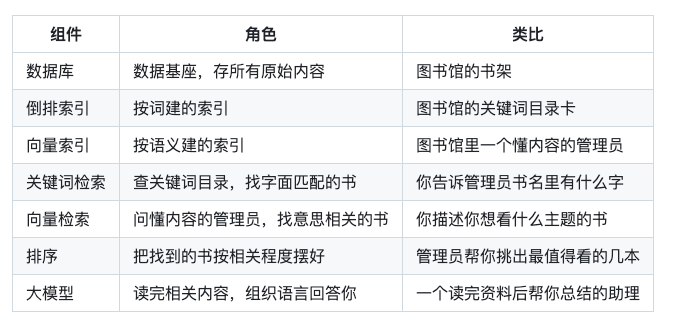
九、回到开头那个问题
现在回头看最开始那个常见问题:
“我们是用 MySQL 查,还是用向量库查?关键词检索还要不要?”
预览文章你会发现这个问题本身就问错了。
它混淆了三件不同的事:
┌─────────────────────────────────────────────────┐
│ │
│ MySQL → 数据存在哪、怎么管 │
│ (存储层) │
│ │
│ 关键词检索 → 按字面怎么找到相关内容 │
│ (BM25+倒排索引) (检索方式 A) │
│ │
│ 向量检索 → 按语义怎么找到相关内容 │
│ (embedding+ANN) (检索方式 B) │
│ │
│ 它们不在同一层,不是互相替代的选项 │
│ 而是系统里各管各的角色 │
│ │
└─────────────────────────────────────────────────┘
数据库是基座。关键词检索和向量检索是基座之上两种不同的”翻译”方式。它们帮上层应用更好地检索到基座里的数据——但最终返回的,都是数据库里那条完整的行数据。
不是谁替代谁,是谁在系统里负责哪一层。
结尾
当你再听到有人把向量库、关键词检索、MySQL 放在同一张”谁更好”的对比表里时,不用急着选边。
先问一句:
我们现在讨论的,到底是存储问题、检索问题,还是召回策略问题?
如果是存储问题,聊数据库选型。
如果是检索问题,聊关键词和向量各自的适用场景。
如果是召回策略问题,聊混合检索怎么设计、怎么融合、怎么排序。
把层分开,讨论才不会乱。
本文由 @ChenXiaowu 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


