
 起点课堂会员权益
起点课堂会员权益AI进化史——长出”眼睛、记忆、想象力和大脑”的四大超能力
AI的进化绝非一蹴而就,它经历了四次革命性的底层技术突破,如同获得了四个关键"器官"。从CNN赋予视觉能力,到RNN/LSTM建立记忆系统,再到GAN与Diffusion点燃生成能力,最后Transformer以注意力机制构建超级大脑——每次突破都重塑了信息处理的基本方式。本文将深度拆解这四次技术革命的底层逻辑,揭示AI如何从"分不清猫狗"到"能与你聊哲学"的进化之路。

AI不是某天突然开窍的,它经历了四次底层大手术,每次都补上一个关键”器官”。
你有没有这种感觉——前几年还在嘲笑”AI连猫和狗都分不清”,结果一转眼,它不光认猫认狗,还能帮你写报告、画图、写代码,甚至跟你聊起了哲学。
这变化也太快了吧?AI是偷偷喝了什么灵丹妙药?
其实没有。AI的”开窍”,背后是几次非常硬核的底层技术突破。每一次突破,都在给它补上一个全新的能力模块。把这几次突破串起来看,你会发现一条清晰的进化路径——AI先后长出了四个关键”器官”:眼睛、记忆、想象力,还有一个超级大脑 。
每一次跨越,都不是简单的”算法小升级”,而是信息处理方式本身发生了根本性的改变。
咱们一个一个来说。
长出”眼睛”——CNN让AI第一次真正看懂图像
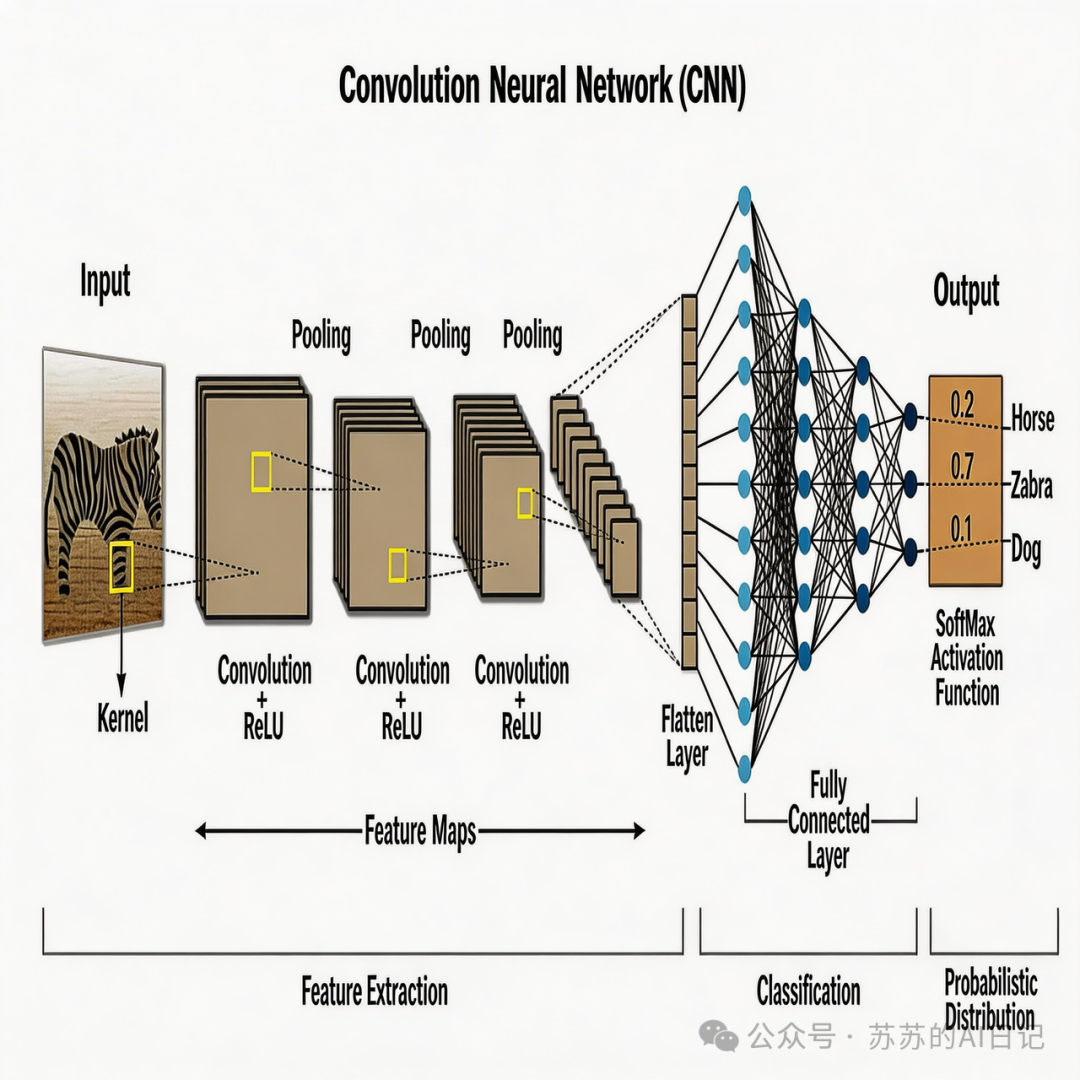
先说说AI在”看图”这件事上,曾经有多笨。
对计算机来说,一张图片本质上只是一大堆像素数字的集合。它压根不知道猫和狗有什么本质区别。传统的做法,是由人类工程师手工告诉机器该看哪些特征——耳朵的形状、眼睛的位置、毛发的纹理……这个过程不仅费时费力,效果还差,换个场景就容易翻车。
这就好比你教一个从没见过世界的孩子认识动物,不让他自己去观察,而是把所有特征写成规则手册让他死背。背得再熟,碰到一只角度奇怪的猫,他还是一脸懵。
CNN的出现,改变了这件事的底层逻辑。
卷积神经网络(CNN)的核心思路,可以理解成一群在图片上来回巡逻的小侦探。第一层侦探只负责识别最简单的东西——边缘和线条;第二层侦探开始识别纹理和局部形状;再往后,逐渐能拼出耳朵、眼睛、轮廓,最终组合成完整的物体。

它真正厉害的地方,不是”一眼看全图”,而是 学会了从局部到整体逐层提取特征 。更关键的是,这些特征是模型自己从数据里学出来的,不需要人类手工设定规则——AI终于开始自学成才了。
说到这儿,就不得不提一个极具象征意义的历史时刻。
2012年,ImageNet大规模视觉识别挑战赛。
来自多伦多大学的辛顿(Geoffrey Hinton)带着他的两个学生——Ilya Sutskever 和 Alex Krizhevsky,提交了一个叫 AlexNet 的深度卷积网络。比赛结果出来,整个计算机视觉界都炸了:AlexNet 的图像分类错误率只有 15.3% ,而当年第二名是 26.2% ,几乎直接砍了一半。
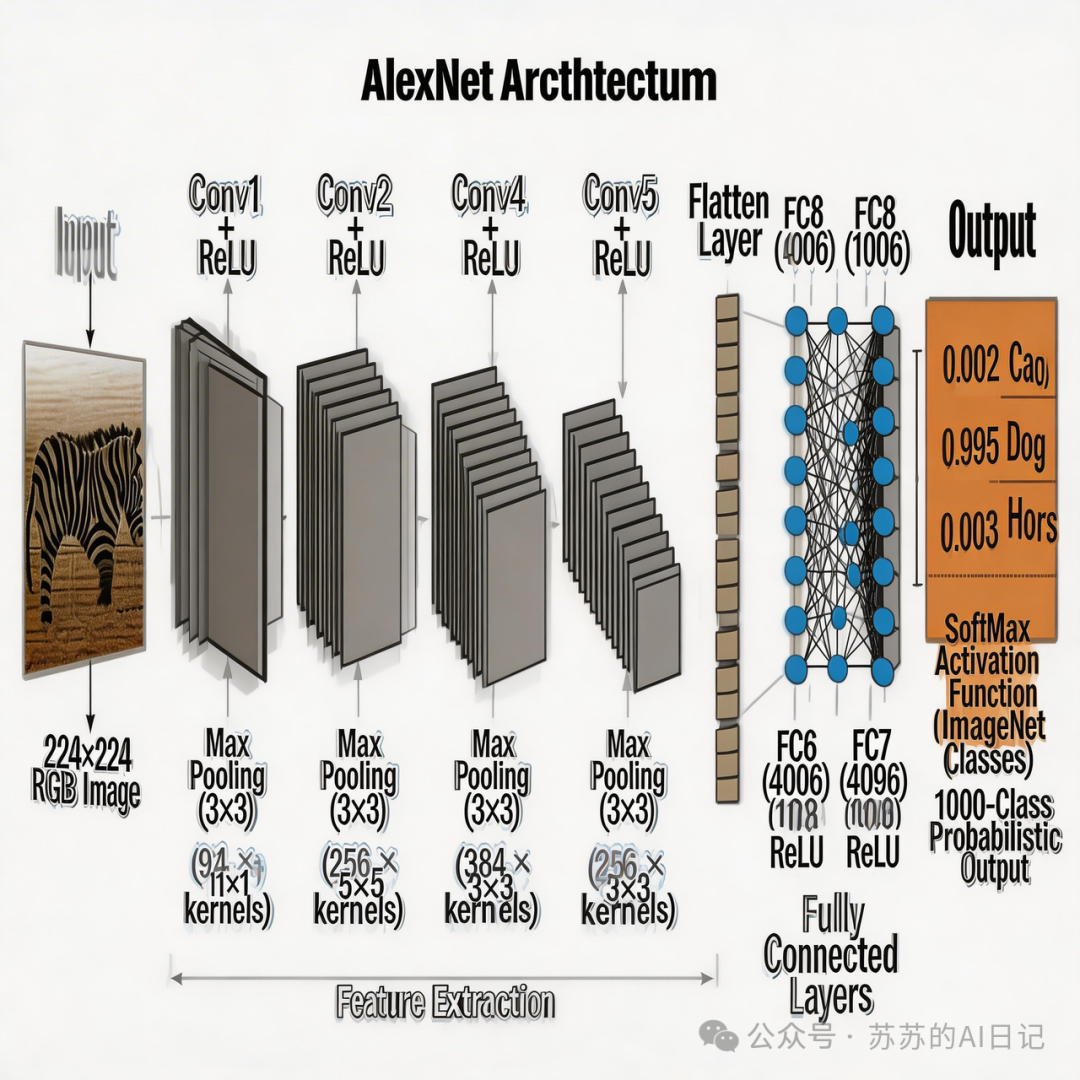
更夸张的是,AlexNet 只用了 4 块英伟达 GPU,而谷歌同年搞的”谷歌猫”项目用了 16000 颗 CPU,效率差距大到不好意思说。李飞飞当时正在休产假,看到这个错误率,立刻买了最后一班飞机飞去佛罗伦萨亲自颁奖——她意识到,历史正在被改写。
这一年,常被视作 AI “长出眼睛”的标志性时刻。深度学习从此正式进入产业视野,传统视觉算法被彻底边缘化,每年 ImageNet 的冠军几乎清一色来自深度神经网络。
不过,眼睛虽然有了,CNN 擅长的是处理空间结构,并不擅长理解”顺序”。一旦问题变成一句很长的话、一段连续的语音,或者一段需要前后文的信息流,新的麻烦就来了。
AI 能看图了,但还不会”听”,更不会”读”。
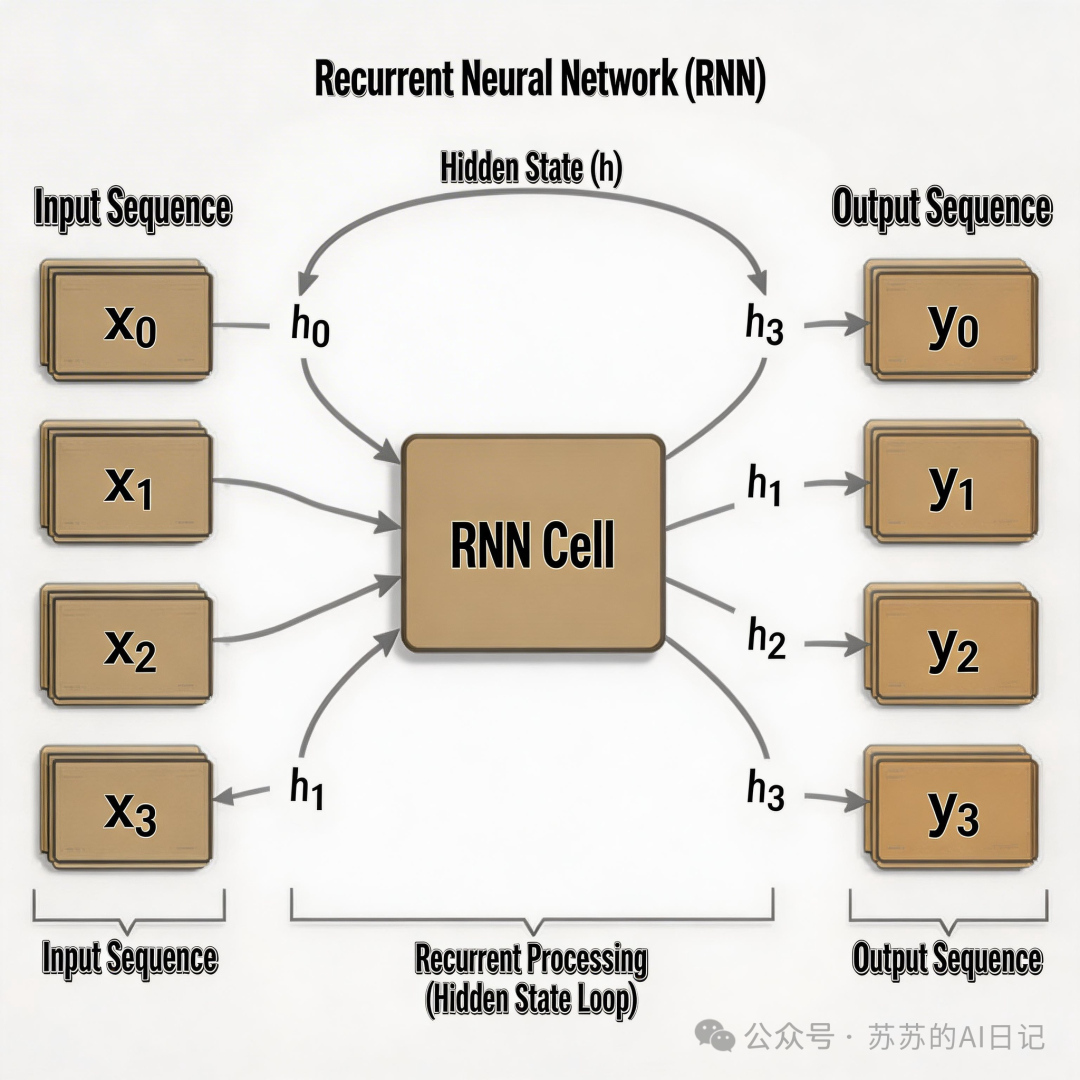
拥有”记忆”——RNN与LSTM让AI开始理解上下文
RNN LSTM
人类理解语言,从来不是孤立地看每一个词。
你读到”他拿起了那把……”,大脑会自动把前面的上下文保留在记忆里,等着后面的词来补全。可早期的 AI 处理文本和语音,基本上像只有几秒记忆的金鱼——读到后面就忘了前面,句子一长就容易理解错,甚至前言不搭后语。
这就是为什么早期机器翻译那么糟糕。它能翻对每个词,但整句话放在一起,经常驴唇不对马嘴。
RNN(循环神经网络)的出现,给 AI 装上了第一个版本的”记忆”。
RNN 的核心思想其实不复杂:每读一个新词,模型都会带着前面积累的一点”记忆”继续往下走。可以把它想象成一个顺藤摸瓜的读者,读到每个词时,都把之前读过的内容带进来一起考虑。比过去那种”看一个词算一个词”的方式,进步了一大截。
但 RNN 有个致命的毛病——健忘。
句子越长,前面的信息就越容易被”稀释”,到最后几乎消失。更麻烦的是,训练过程中梯度会随着时间步的推移越来越小,出现所谓的”梯度消失”问题,模型根本学不到长距离的依赖关系。说白了,就是记性太差,前面说了什么,后面全忘光了。
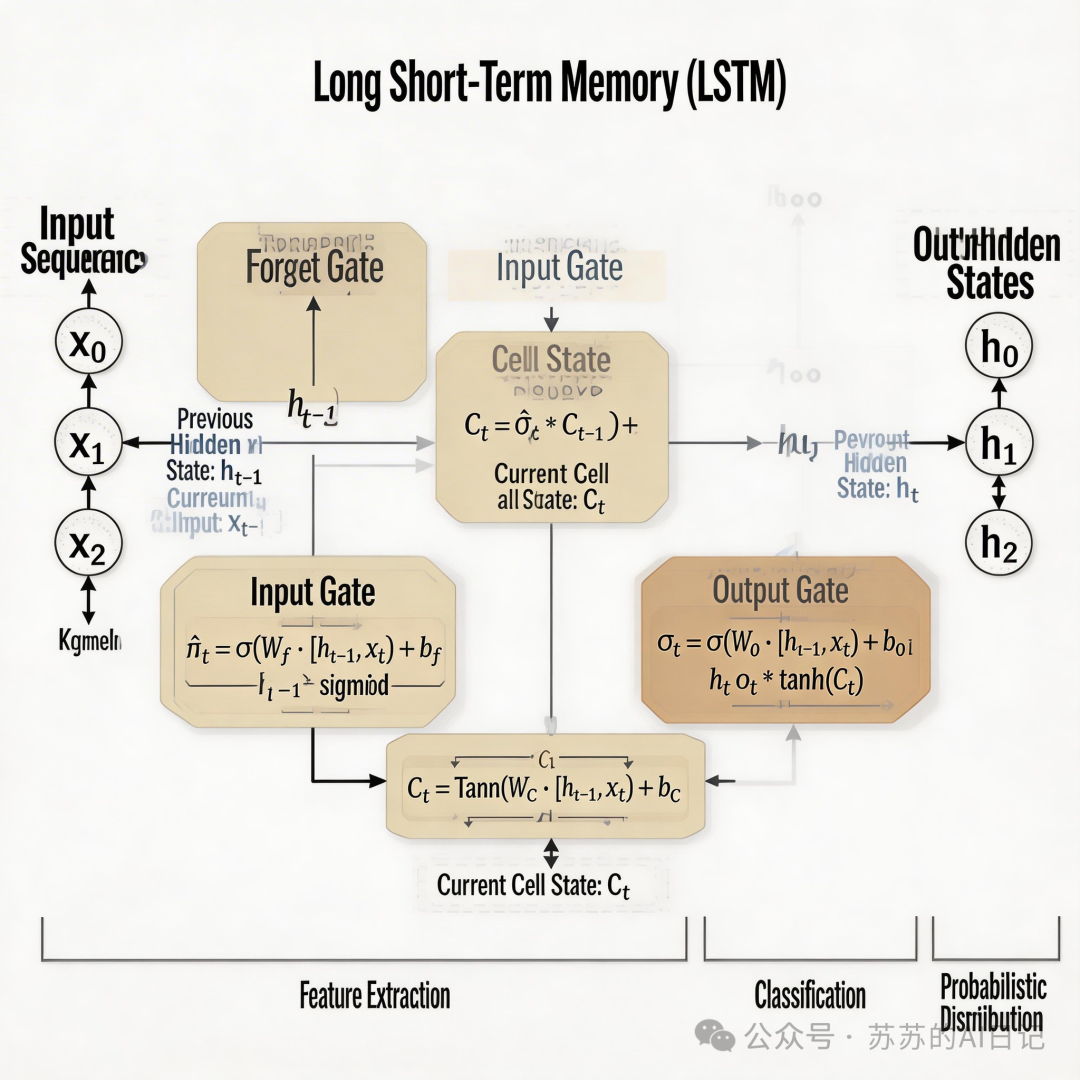
这时候,LSTM(长短期记忆网络)登场了。
LSTM 可以理解成 RNN 的升级版,给 AI 配备了一个带”门禁系统”的智能备忘录。这个备忘录有三扇门:
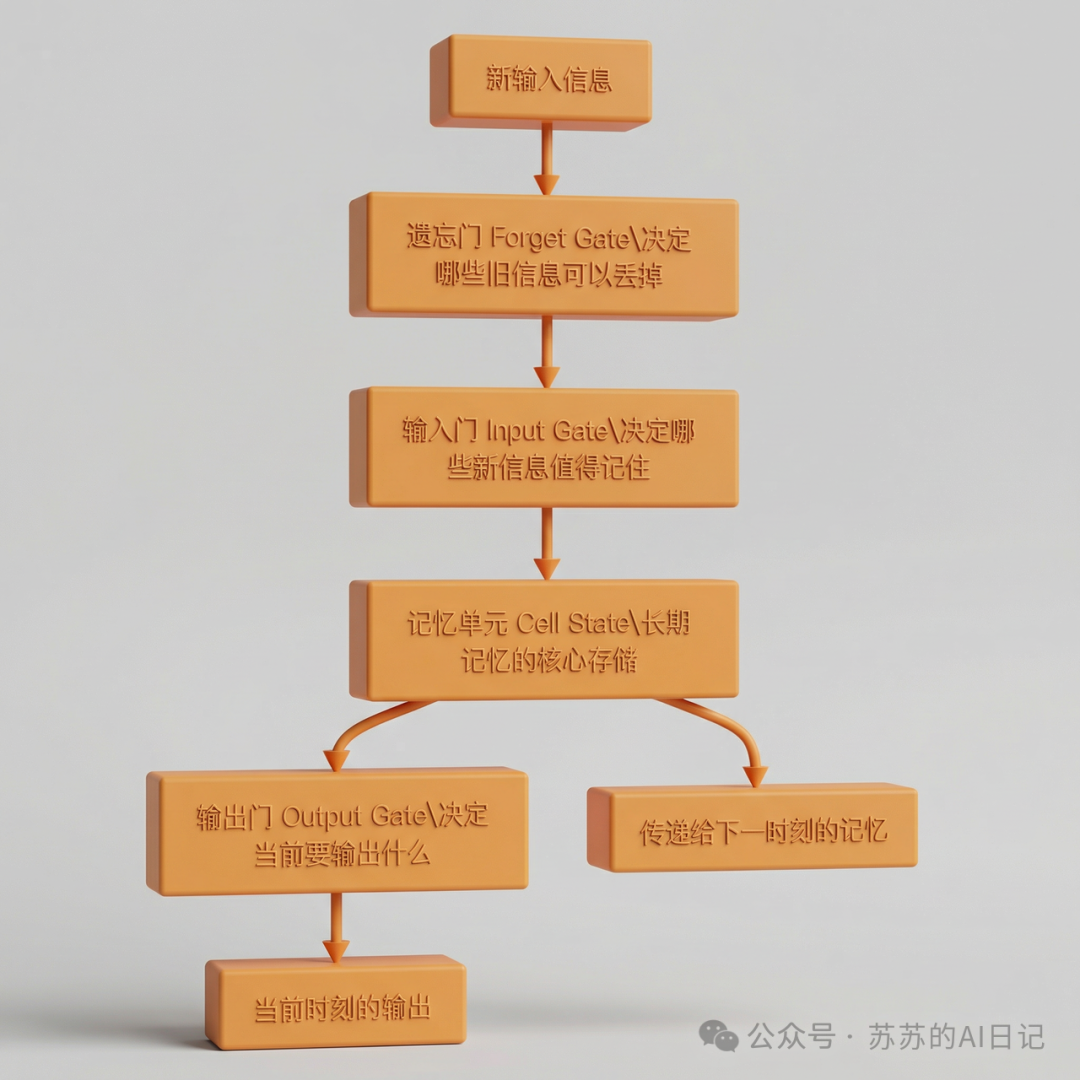
哪些信息该记住,哪些内容可以遗忘,不再完全靠运气,而是由模型自己通过训练来判断。这让机器在语音识别、机器翻译、文本建模等任务上的表现明显提升,也推动了语音助手和自然语言处理的实用化进程。
LSTM 的意义不只是”记得更久”,更重要的是它让 AI 第一次真正建立起对 连续信息和上下文 的处理能力。它不再只是识别一个点,而是开始理解一条线。
不过,RNN 和 LSTM 的问题也很明显——它们像一个必须按顺序读稿的人,句子越长,越容易忘掉远处的信息;同时计算必须串行进行,训练效率不高,很难支撑更大规模的数据和模型。
AI 有了记忆,但还缺一个更高效、更擅长抓重点的大脑。
点燃”想象力”——GAN与Diffusion让AI从识别走向生成

GAN Diffusion
过去的 AI,更像是在做选择题:判断图里是不是猫,判断一句话是正面还是负面。
可真正让大众震惊的,是 AI 开始会做 “创作题” 了——它不只是分辨内容,而是能凭规律生成全新的内容。
这个跨越,是 GAN 带来的。
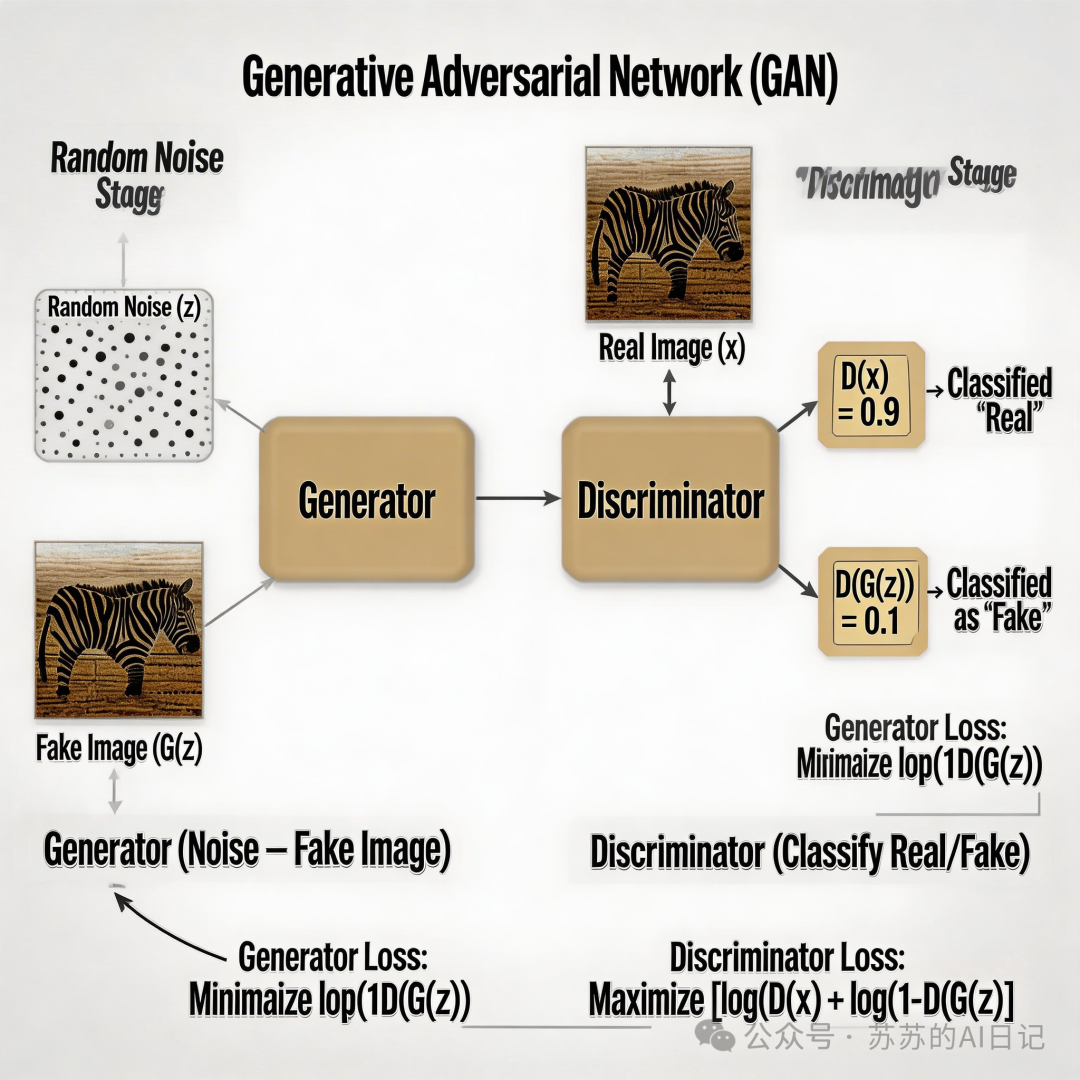
2014 年,Ian Goodfellow 在一次和朋友的酒后讨论中,灵光一现,提出了生成对抗网络(GAN)。
改变 AI 发展轨迹的想法,居然诞生于一场醉酒的头脑风暴——这故事本身就很有意思。
GAN 的核心机制,可以用一个经典比喻来理解:造假大师和鉴谎警察之间的对抗博弈 。
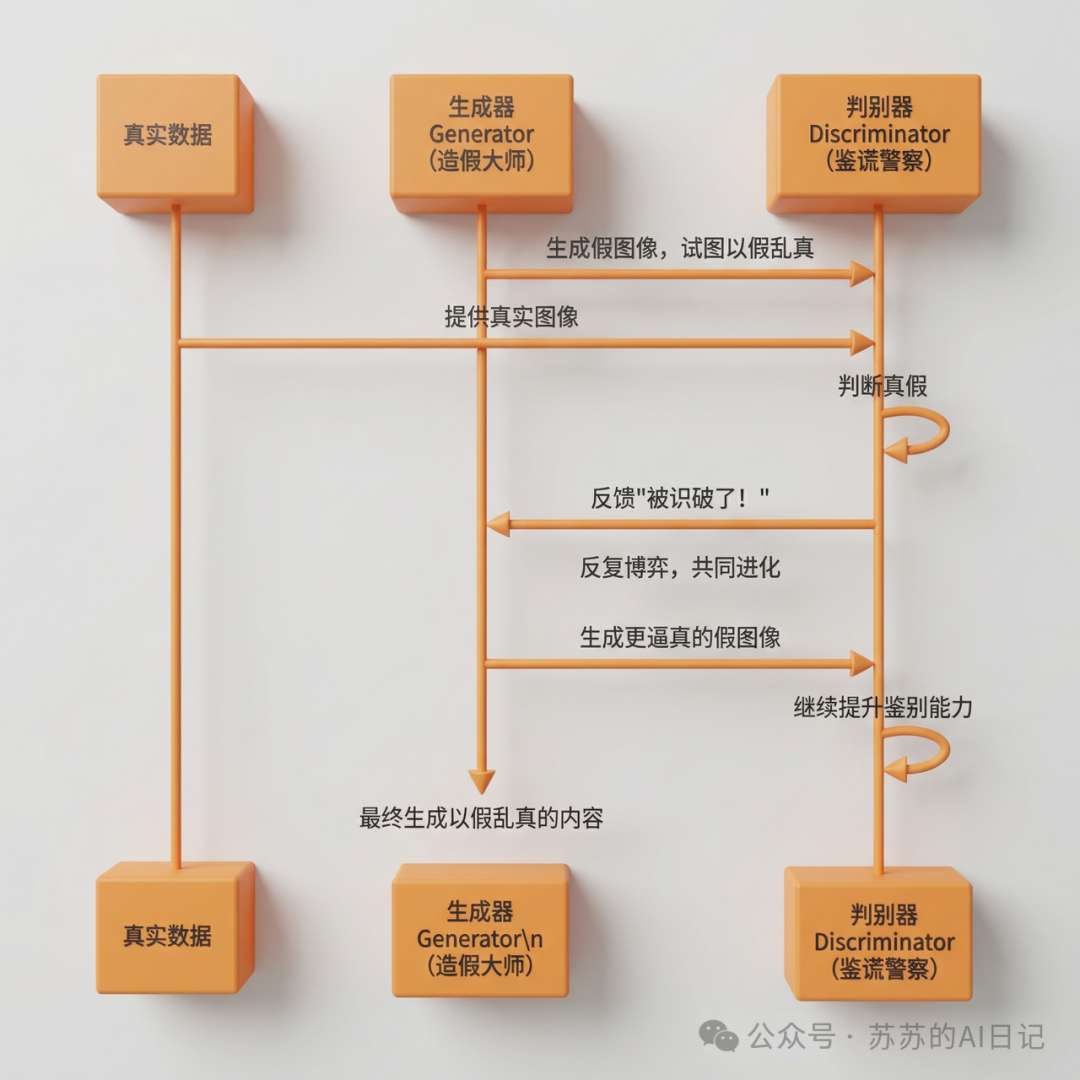
生成器越来越会造假,判别器越来越会识破,最终让生成器画出的内容越来越接近真实。这套机制让人们第一次强烈意识到: 机器不仅能识别世界,还能模仿世界、重构世界 。
此后几年,GAN 的变种层出不穷。ProGAN 从低分辨率图像开始渐进式训练,逐步提升分辨率;StyleGAN 进一步实现了对人脸风格的精细控制,可以分别调整发型、表情、肤色等不同层次的特征;到了 StyleGAN2,连训练中出现的”水珠伪影”问题都被修复了。
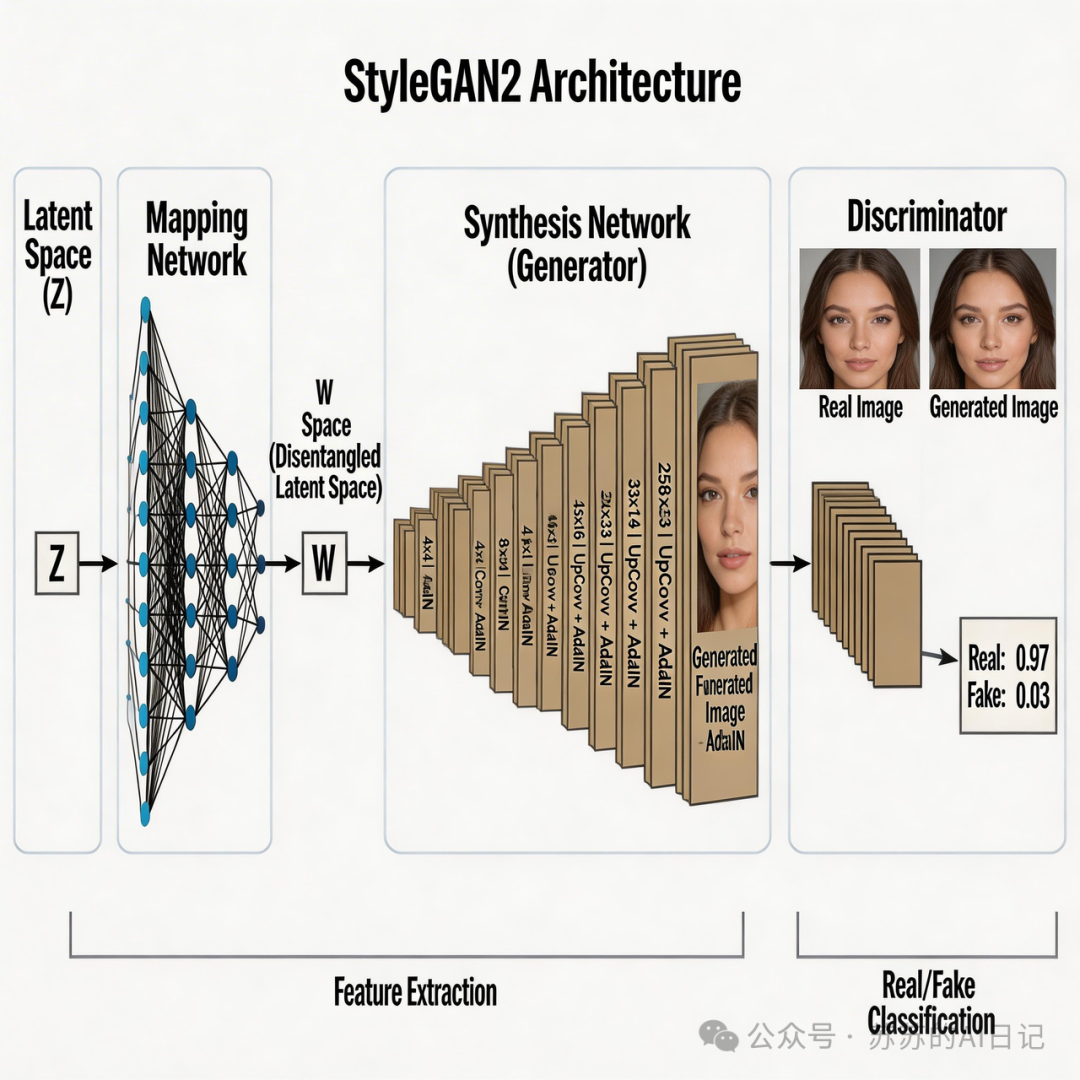
但 GAN 有个让人头疼的毛病—— 训练极不稳定 。
生成器和判别器就像两个互相较劲的选手,稍有不慎就会出现”模式崩塌”(mode collapse)——生成器学会了一个能骗过判别器的固定套路,然后就一直重复那个套路,再也不进步了。训练过程经常像走钢丝,一不小心就崩。
于是,另一条路线悄悄崛起了。
扩散模型(Diffusion Model)的思路,完全不一样。

先把清晰图像一步步加噪,打散成一团几乎无法辨认的随机噪声;然后训练模型学会如何从噪声中一点点恢复结构,最终生成新的图像。 通过加噪去训练,通过去噪去生成 。
这个过程更稳定,也更容易控制。结合 VAE(变分自编码器)把扩散过程压缩到潜在空间里,就有了后来的 Latent Diffusion,再加上 LAION 5B 这个由一位德国高中物理老师牵头、志愿者社区共建的 5 亿张图片数据集,最终催生了 Stable Diffusion ——一个让文生图技术真正跑进普通人家庭显卡的系统。
这一章的意义,不在于”AI有了创造力”(这个说法其实有点过度解读),而在于: AI 第一次在大众层面大规模展示出生成能力 。 它不再只是回答”这是什么”,而开始回答”我能不能造一个新的出来”。
不过,无论是 GAN 还是 Diffusion,它们的强项主要仍在生成内容本身。真正让 AI 走向通用化、把语言、图像、代码乃至更多模态统一到一个框架里的关键突破,还要等下一次革命。
进化出”超级大脑”——Transformer用注意力机制改写整个AI时代

2017 年,一篇论文横空出世。
标题叫《 Attention Is All You Need 》。
光这个标题就很拽——”你需要的,只是注意力”。仿佛在向整个 AI 界宣告:”你们之前搞的那些,都可以扔了。”
更拽的是,他们把自己的模型命名为 Transformer ,也就是变形金刚。这相当于你设计了个算法,然后取名叫”齐天大圣”。
当然,最拽的还是这篇论文 真的改变了一切 。
Transformer 解决的,是 RNN/LSTM 一直没能彻底解决的两个问题: 健忘,和训练慢 。
它的核心机制叫做 注意力机制(Attention Mechanism) 。
最直观的理解方式是这样的:RNN 处理文本的方式,像是一个人逐字往后读,读完前面才能读后面;而 Transformer 不必按顺序慢慢消化,而是能把整段内容同时摊开,直接计算每个词和其他词之间的关联强弱。
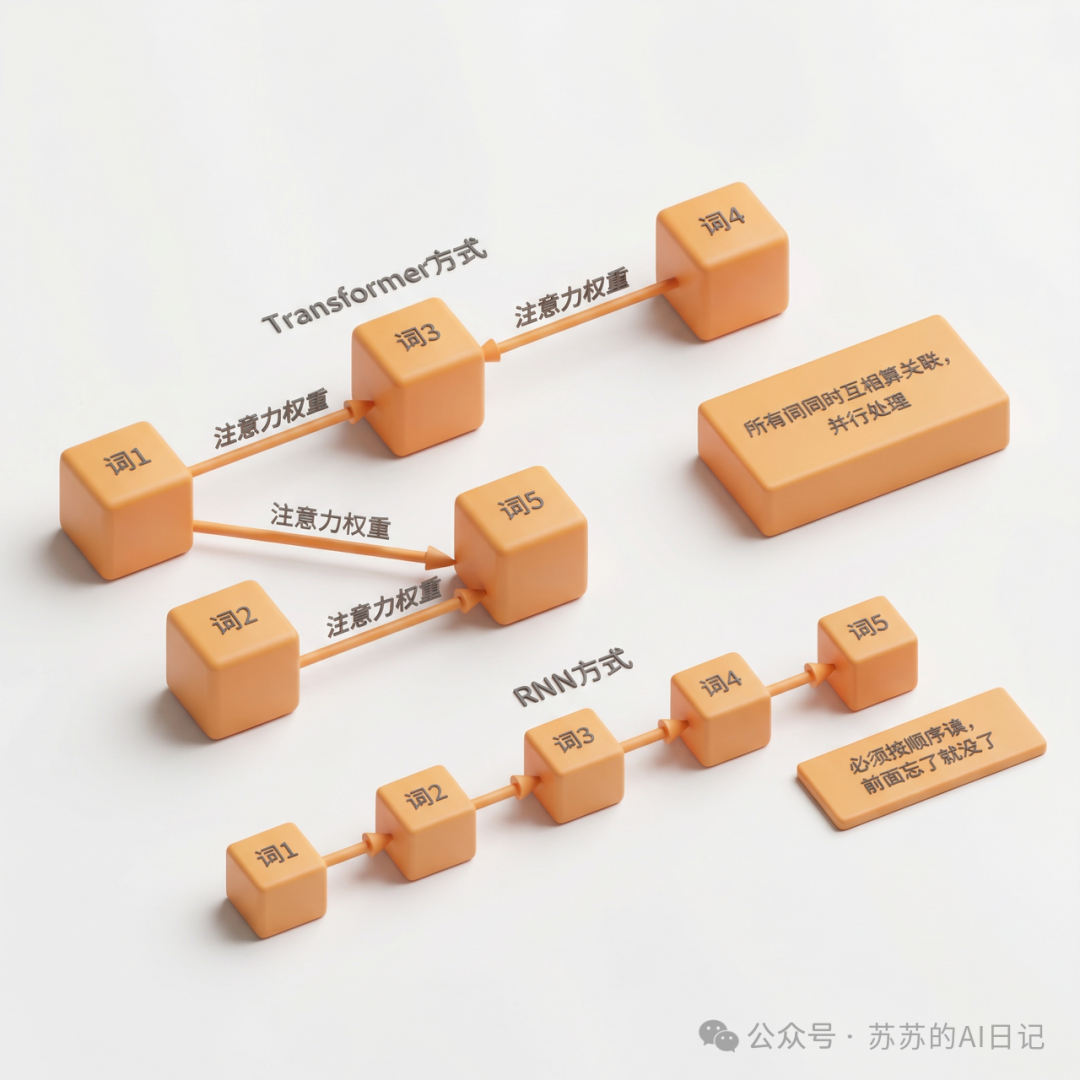
它像一个 一目十行、还特别会划重点 的读者。别人读书是从头读到尾,它却能瞬间看到一句话里哪个词和哪个词最相关,哪一段才是真正的重点。
比如”这老板真水”这句话,Transformer 能直接算出”水”和”老板”之间的关联权重最高,从而理解这里的”水”是指水平低下,而不是物理意义上的液体。这种能力叫做 捕捉长距离依赖关系 ,而且完全不受词语之间距离的影响。
另一个优势是 并行计算 。不像 RNN 必须一步一步串行处理,Transformer 里每个词对其他词的注意力计算可以同时进行,GPU 的并行能力得到了充分发挥,训练速度大幅提升。这两点加在一起,才让模型规模第一次真正有机会爆炸式增长。
Transformer 的”子孙后代”长这样:
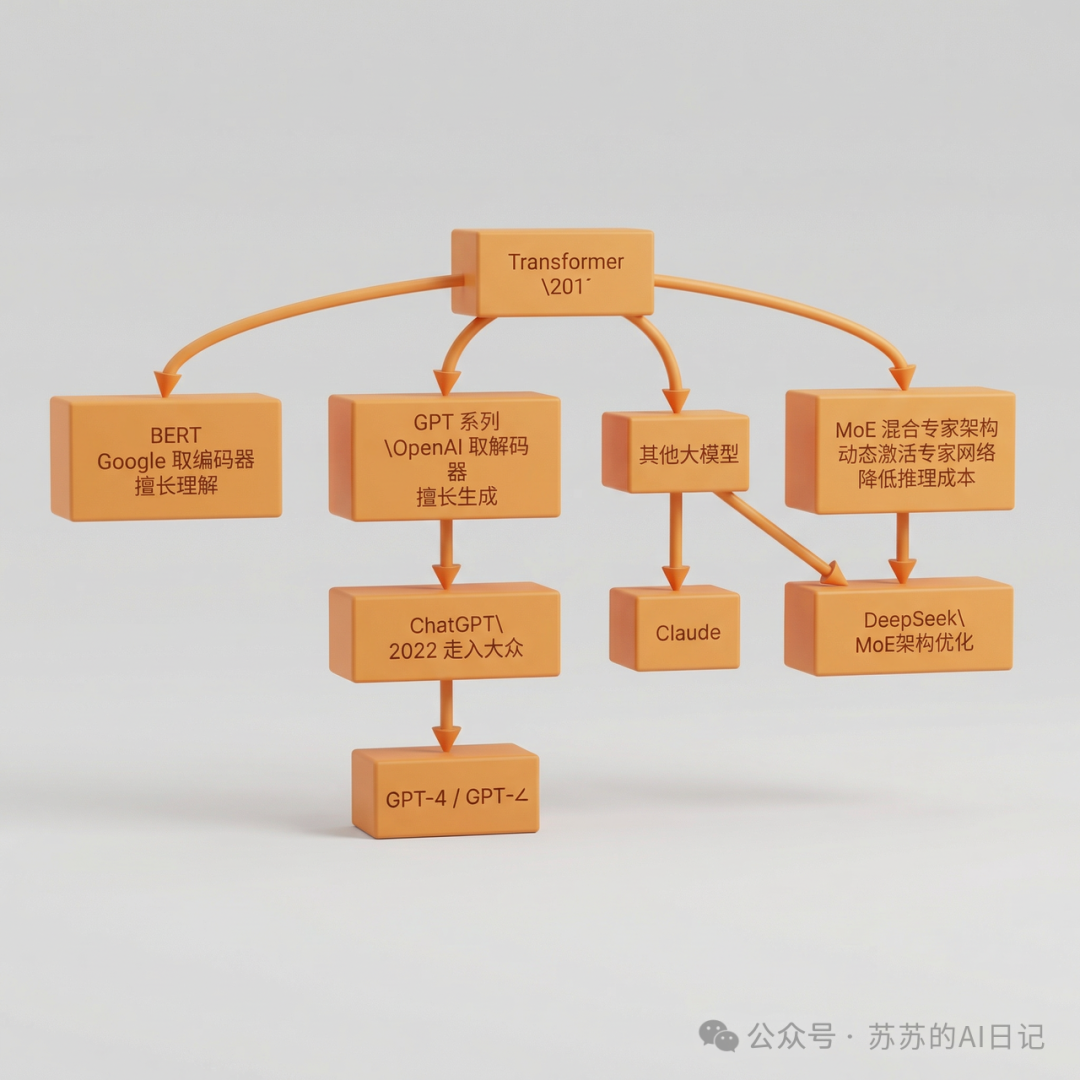
Google 把 Transformer 的编码器部分拿出来优化,得到了 BERT;OpenAI 把解码器部分拿出来优化,得到了 GPT。ChatGPT 名字里那个”T”,就来自 Transformer。今天你用的各种大模型——DeepSeek、GPT、Claude——本质上都是在 Transformer 架构的基础上,通过堆更多层、喂更多数据、加上各种工程优化发展而来的。
Transformer 真正改变的,不只是聊天机器人,而是让语言、图像、语音、代码等不同类型的信息,逐步进入 同一种统一建模框架 。它第一次让人们看到,通用人工智能也许不是遥不可及的幻想,而是可以通过架构、数据和算力持续推进的工程问题。
值得一提的是,Transformer 本身也在持续进化。MoE(混合专家架构)和 Transformer 的融合正在成为新趋势——把传统 Transformer 里的前馈网络层替换成多个”专家网络”,由门控机制动态选择激活哪些专家,既保留了强大的注意力机制,又大幅降低了推理时的计算成本。DeepSeek 就是这条路线的代表性成果之一。
AI很强,但进化远未结束
回头看,这四次突破有一条清晰的主线:
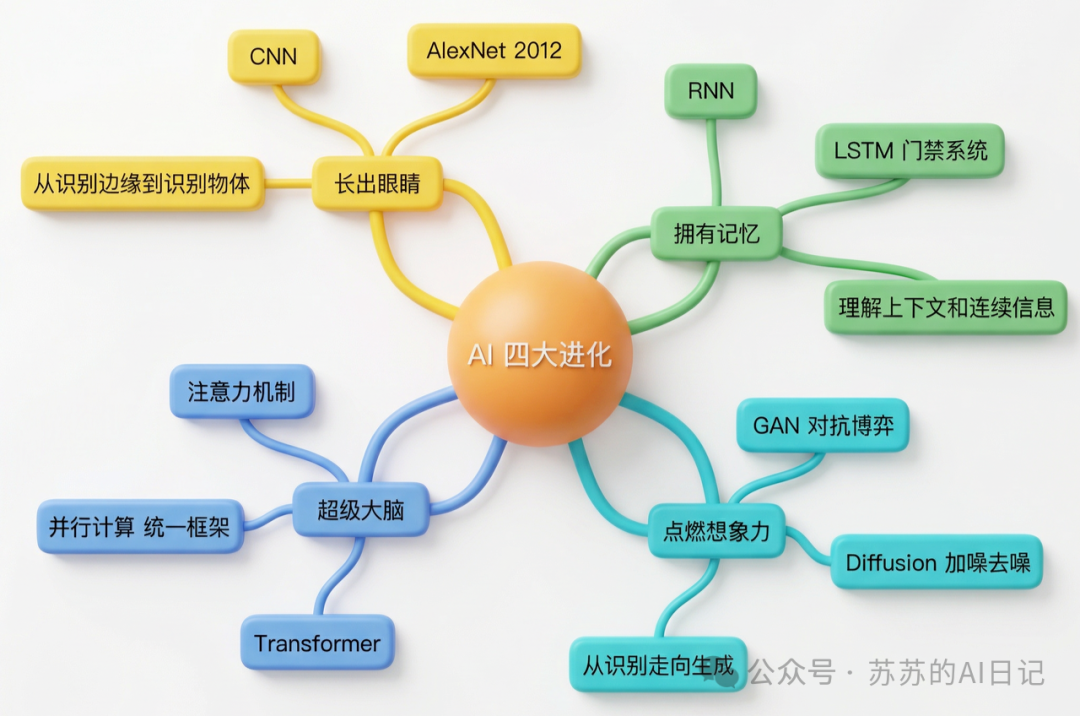
CNN 让 AI 看见,RNN/LSTM 让 AI 记住,GAN 与 Diffusion 让 AI 生成,Transformer 让 AI 学会理解复杂关系。每一次,都不是在原有框架上小修小补,而是信息处理方式本身发生了根本性的改变。
但我想在这里说一个大多数科普文章不太愿意说的事: 今天的大模型,其实仍然有很多短板 。
推理能力不稳定,复杂逻辑题经常翻车;事实幻觉问题始终存在,一本正经地说错话;长期记忆很薄弱,跨对话的上下文管理依然是难题;在真实世界里采取行动的能力,也还远不成熟。
也就是说,AI 虽然已经补齐了很多关键能力,但它仍然不是”完全体”。
下一次真正改变世界的技术,也许会来自更可靠的推理系统,也许是更强的长期记忆机制,也许是能与现实环境深度互动的行动系统——也就是大家现在越来越多听到的”Agent”和”具身智能”。
这场进化,还在继续!
本文由 @苏苏的AI笔记 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


