
 起点课堂会员权益
起点课堂会员权益AI Agent 的 Harness 机制学习思考
OpenAI的实验揭示了一个革命性趋势:3人工程师小组仅用5个月就通过AI Agent构建了百万行代码的产品,效率跃升300%。Harness Engineering正掀起软件工程的第三次范式转移——用约束换取AI自主权。本文深度拆解了OpenAI、Anthropic等顶尖机构的实践案例,呈现可立即落地的四大核心模块,带你看懂如何用'缰绳'驾驭AI这匹烈马。

2026 年 2 月,OpenAI 官方博客发布了一篇震撼业界的文章:《Harness Engineering: Leveraging Codex in an Agent-First World》。

文章讲述了一个看似不可思议的实验:一个仅有 3 人的工程师小组,在完全禁止手写代码的条件下,利用 AI Agent 在 5 个月内构建了超过 100 万行代码的完整产品。
人均每天合并 3.5 个 Pull Request,团队吞吐量从传统的 0.25 人/工程师跃升至 3-10 人/工程师。更令人惊讶的是:新成员越多,整体效率反而越高——这就是所谓的”知识飞轮效应”。
这个实验揭示了一个深刻的认知转变:软件工程正在经历继瀑布模型到敏捷开发、单体架构到微服务架构之后的第三次重大范式转移。
那么,什么是 Harness Engineering?它与我们熟悉的 Prompt Engineering、Context Engineering 有何本质区别?作为产品经理或技术负责人,我们该如何在自己的团队中落地这套方法论?
本文将结合 OpenAI、Anthropic、LangChain 等权威机构的实践案例,尽可能的从产品视角拆解 Harness 工程化的四大核心模块,并提供可立即落地的实战指南。
一、什么是 Harness?从”马具”隐喻说起
1.1 Harness 的本质定义
“Harness”这个词的原意是马具——缰绳、鞍具、嘴套,是骑手用来连接、保护、控制马匹的整套装备。
用它来描述 AI Agent 的管理框架,比喻非常精准:
- 马(模型):强大、快速,但不知道该往哪跑。它有巨大的能力,但没有方向感。
- 骑手(工程师):提供方向和判断,但不自己去跑步。负责决定做什么和为什么。
- 缰绳(Harness):连接骑手和马,确保力量被正确引导,防止失控。它不做实际工作,但让工作成为可能。
LangChain 工程师 Vivek Trivedy 给出了一句精炼的定义:
“如果你不是模型,你就是 Harness。”
这句话精准地概括了 Harness Engineering 时代工程师角色的根本转变。
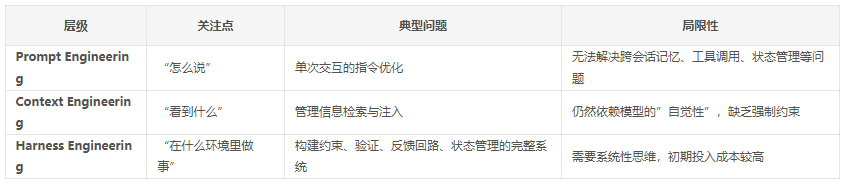
1.2 从 Prompt 到 Context 再到 Harness:三次范式演进
我们可以用同心圆式的嵌套关系来理解三者的演进:
Harness Engineering 的哲学基础可以用四个字概括:“约束换自主”。
这是一个看似悖论却极其深刻的思想:规矩越明确 → Agent 独立做的事越多;约束越严格 → 信任越高 → 自主权越大。
二、方法论:Harness 工程化的四大核心模块
模块一:地图而非百科全书——对抗上下文稀缺
2.1.1 OpenAI 的教训:为什么不能把一切都塞进 AGENT.md?
在 OpenAI 的实验中,他们就发现了一个常见误区:试图把巨大的信息塞进一个巨大的 AGENT.md 文件里。
这种做法的问题在于:模型的上下文窗口是稀缺资源。巨大的指令文件会挤掉重要的任务信息、代码片段和中间结果,导致 Agent 在执行过程中”失忆”或”注意力分散”。
2.1.2 正确做法:AGENT.md 作为导航地图
OpenAI 团队的做法是:将 AGENT.md 设计为一个约 100 行的目录文件,指向结构化的文档目录。
# AGENT 核心记忆文件(导航地图)
## 项目架构
– 参见 `/docs/architecture/system-design.md`
– 参见 `/docs/architecture/data-flow.md`
## 编码规范
– 参见 `/docs/coding-standards/python.md`
– 参见 `/docs/coding-standards/frontend.md`
## API 配置
– 参见 `/config/api-endpoints.json`
– 参见 `/config/environment-variables.md`
## 关键约束
– 所有数据库操作必须通过 Repository 层
– 禁止在 Controller 中直接调用外部 API
– 所有接口必须有单元测试,覆盖率不低于 80%
## 历史决策记录
– 参见 `/docs/decisions/2026-03-20-orm-selection.md`
– 参见 `/docs/decisions/2026-03-21-error-handling.md`
Agent 拿到这张”地图”后,可以按需跳转检索具体文档,而不是把所有内容一次性加载到上下文中。
2.1.3 记忆力机制和经验库
除了静态文档,Harness 还需要提供动态的记忆力机制:
- 持久化记忆:Agent 学到的新知识、团队的新规范,自动写入 AGENT.md 或专门的记忆文件,下次启动时自动加载。
- 经验库:将常见的错误模式、最佳实践、陷阱案例整理成结构化数据,Agent 在执行前可以快速检索参考。
产品启示:不要试图让 Agent”记住一切”,而是给它一张清晰的地图,让它知道去哪里找答案。这就像给新员工一本员工手册的目录,而不是把整个公司的制度打印出来塞给他。
模块二:机械化架构约束——从”软性建议”到”硬性卡口”
2.2.1 拒绝“建议式”软性约束
很多团队在引入 AI Agent 时,会在 Prompt 中写下这样的约束:
“请遵循 MVC 架构,不要在 Controller 中直接调用数据库。”
“请编写单元测试,确保代码质量。”
这种建议式软性约束的问题在于:它依赖 Agent 自身的“自觉性”和“记忆力”。当上下文变长、任务变复杂时,Agent 很容易忘记或绕过这些约束。
2.2.2 正确做法:Hook + 结构化测试
Harness Engineering 的核心原则是:用自动化工具把约束写进执行流程里,不依赖 Prompt 的软性约束以及 Agent 自身的自觉性。
具体做法是:采用 Hook 和结构化测试,即在 Agent 执行某个操作后,自动触发一段检查程序。
原则:仅在模型出错的问题上设置约束,将”好/不好”量化成 0/1,判断是否进入下一步,作为下一步的关键令牌。
这和状态机单向通行一致:每一层必须由上一层审查无误后可推进到下一步的进程,仅允许单向逐层通行,违反则自动报错,重新执行。
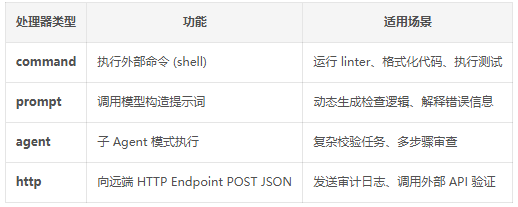
2.2.3 Claude Code 的 Hooks 系统:24 个生命周期事件 × 6 种处理器类型
Anthropic 的 Claude Code 提供了一个成熟的 Hooks 系统,可以作为参考标杆。
24 个生命周期事件覆盖了 Agent 执行的各个阶段,例如:
- SessionStart:会话开始
- PreToolUse:工具调用前
- PostToolUse:工具调用后
- PreCommandExecute:命令执行前
- PostCommandExecute:命令执行后
- PreFileWrite:文件写入前
- PostFileWrite:文件写入后
- SessionEnd:会话结束对外暴露的 4 类处理器:
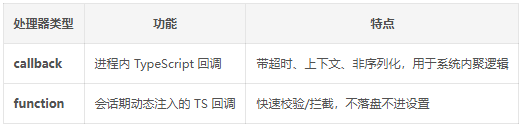
内部使用的 2 类处理器:
2.2.4 实战示例:强制代码规范检查
假设我们希望 Agent 在提交代码前自动运行 Lint 检查,不符合规范的代码不允许提交。
传统做法(软性约束):
在 Prompt 中写道:”请在提交代码前运行 eslint,确保没有错误。”
问题:Agent 可能忘记,或者为了省事跳过这一步。
Harness 做法(硬性卡口):
// 在 PostFileWrite Hook 中注册检查
hooks.register(‘PostFileWrite’, async (context) => {
if (context.file.path.endsWith(‘.ts’) || context.file.path.endsWith(‘.tsx’)) {
const result = await executeCommand(‘npx eslint ‘ + context.file.path);
if (result.exitCode !== 0) {
// 返回 exitCode 2 表示阻断
return { exitCode: 2, message: ‘Lint 检查失败,请修复后重试’ };
}
}
return { exitCode: 0 };
});
这样,无论 Agent 是否“记得”运行 Lint,系统都会自动拦截不符合规范的代码。
产品启示:好的 Harness 不是让 Agent”更聪明”,而是通过协议约束让 Agent”无法偷懒”。将人类的品味和标准编码成自动化规则,实现”品味捕获一次,强制执行无限次”。
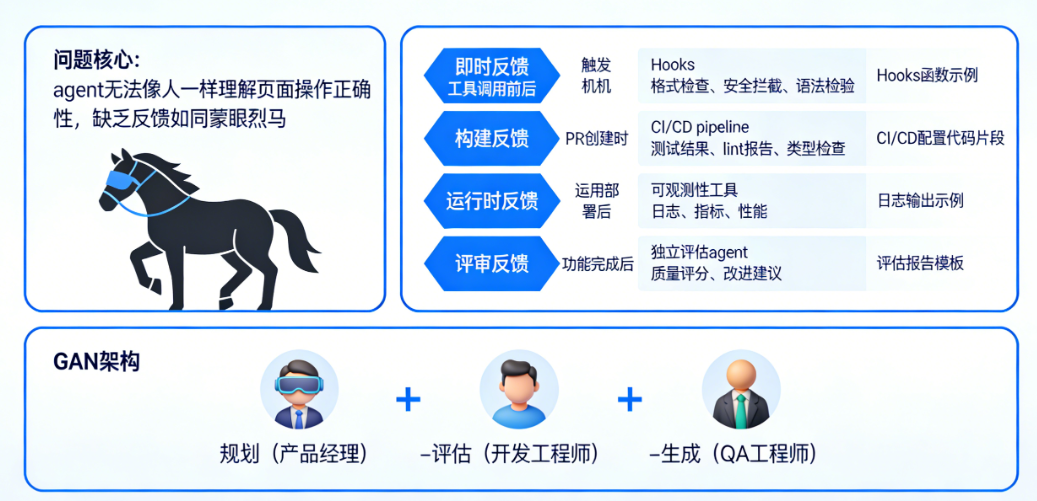
模块三:反馈闭环——让 Agent 不再”蒙眼狂奔”
2.3.1 为什么 Agent 需要反馈?
Agent 没有办法像人一样去理解页面、理解操作是否做得对。不能获得反馈的 Agent,就像蒙眼的烈马——它可能跑得很快,但方向可能是错的。
即时的反馈能够确保每一个 Agent、在每一个时间点都知道:
- 做到哪里了
- 做得对不对
- 下一步要做什么
2.3.2 分层实现反馈机制
正确的做法是:分层实现反馈机制,从即时到跨对话逐层递进,相互补充。
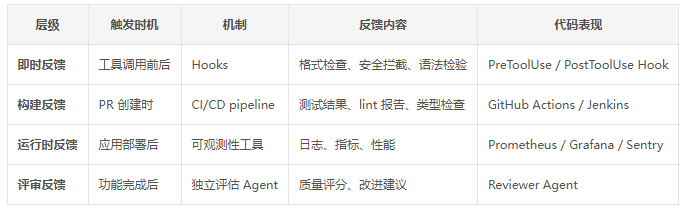
2.3.3 GAN 架构:规划 – 评估 – 生成

Anthropic提出的一种高效的反馈闭环设计是借鉴 GAN(生成对抗网络)的思想,构建多角色协作架构:
- 规划者(产品经理角色):负责任务拆解、目标设定、路径规划
- 生成者(开发工程师角色):负责代码实现、功能开发
- 评估者(QA 工程师角色):负责质量检查、测试验证、提出改进建议
这三个角色可以是同一个 Agent 在不同阶段的切换,也可以是多个独立的 Agent 协同工作。关键在于:每个角色都有明确的职责边界和反馈机制。
2.3.4 LangChain 的实践:Trace Analyzer Skill
LangChain 在优化 Deep Agents 时,发现人工排查成千上万行运行轨迹(Trace)几乎不可能形成快速迭代。
于是他们开发了一套Trace Analyzer Skill,将”读日志找问题”这件事做成了一个可复用的系统组件:
三步流程:
抓取数据:从 LangSmith 日志平台,把这次实验里所有 Agent 的运行轨迹原始数据全部拉下来。
并行分析:系统按批次把这些 Trace 切分开,同时启动多个分析子 Agent 并行跑。每个子 Agent 负责一批,专门做错误分析。找到报错点之后,所有子 Agent 的结论汇总到一个主 Agent 那里,由主 Agent 统一提炼成结构化的发现和改进建议。
人工审查:主 Agent 给出的是”下一次实验要改什么”的完整建议清单。工程师在这里参与,核对建议是否合理,批准后才进入下一轮改动。很重要的一点是:改动必须是通用的,对特定任务过度拟合的修改,可能让其他题目的表现退步。
这三步加在一起,把原来需要几个小时的日志排查,压缩成一个可以快速循环的工程流程。
追踪记录(Traces)是整个改进闭环的核心信号。很多所谓”模型不够聪明”的问题,其实是系统没有在合适的时机,把正确的上下文和约束交给模型。没有 Trace,就无法定位这种缺口,问题只会被归结为”模型能力不足”。
产品启示:Agent 的提升不只是模型能力问题,更是系统设计问题。建立可重复、可自动化的反馈闭环,比单纯优化 Prompt 更有效。
模块四:熵管理——把代码债当作垃圾回收
2.4.1 为什么需要熵管理?
Coding 工具生成代码会积压很多的技术债,可以理解成一种文档漂移、架构侵蚀和风格异化。如果不进行管理,那么将逐步累积,越来越难维护,被逐渐腐蚀。
这种现象被称为代码熵增——随着时间推移,代码库会自然地趋向混乱和无序。
2.4.2 正确解法:持续运行,定期回收
正确的做法是:把代码熵的管理当作编程语言的垃圾回收(Garbage Collection)来看待,是一种持续运行、定期回收的状态。
具体做法包括:
把编码原则固化为 Linter 规则:通过规则编码为自动化检测,比如命名规范、修复错误信息。
后台定期 Agent 扫描:专门的清理 Agent 进行周期性的运行扫描,检查文档不一致、约束违规、架构飘逸。例如:
-
- 检查注释与代码的一致性
- 检查是否有 Controller 直接调用数据库的代码
- 检查是否有重复代码块
生成代码健康日报:每天自动生成一份代码库健康报告,列出发现的问题和建议。
发现问题立即修复:而非以后再说的 backlog。Agent 发现一个重复代码块,立即提取为共享函数/工具/原语工具。
2.4.3 OpenAI 的金句:品味捕获一次,强制执行无限次
OpenAI 团队有一句非常精炼的概括:
“Taste captured once, enforced infinitely.”
品味捕获一次,强制执行无限次。
这意味着:把你讨厌的一切模式(重复代码、缺少重试、加密库不标准、前端组件过大……)全部写成 Lint 规则 + 测试 + 审查 Agent,直接静态禁止。
更绝的是:把团队里每个工程师的“品味”和“专长”全部编码进代码库。新来的前端大牛把 Hooks 拆小的偏好、后端专家对异常处理的坚持,都可以变成自动化规则,永久生效。
2.4.4 为删除而构建:Start Simple, Build to Delete
Harness 的设计也不是一成不变的。今天复杂的管线任务,明天可能一个提示词就搞定了。
因此,Harness Engineering 的一个重要原则是:为删除而构建(Build to Delete)。
- Start simple(从简单开始):不要一上来就搞复杂的控制流,先提供稳健的原语工具。
- 模块化设计:让每个组件都可以独立地替换或删除。
- 定期审视:随着模型能力的提升,某些 Harness 组件可能变得多余,应该果断删除。
这体现了 Harness 工程的现实主义哲学:Harness 本质上是在为当前模型的短板提供临时支撑,随着模型进化,这些补丁会逐步消失。
产品启示:好的架构不是追求永恒的完美,而是在解决今天问题的最简单架构的同时,为明天升级留足空间。定期”修剪”你的 Harness,保持其简洁和高效。
三、实战项目:从理论到落地
3.1 LangChain:控制变量实验,排名从第 30 跃升至前五
背景
2026 年 3 月,LangChain 官方发布了一篇题为《Improving Deep Agents with Harness Engineering》的文章,展示了他们如何通过优化 Harness,在不改变模型基座的前提下,让 Deep Agents 的跑分从 52.8 提升到了 66.5,从榜单第 30 开外一路进到前五。
实验设计
他们刻意把 Harness 优化空间压缩到三类变量:
- 系统提示词(System Prompt)
- 工具体系(Tools)
- 中间件 Hook(围绕模型和工具调用的中间件)
保持模型不变,只调整这三个 Harness 变量,观察性能变化。
关键改进点
改进一:强制模型自检
LangChain 在 Trace 记录里发现,最常见的失败模式是:Agent 写完代码,回头读了一遍自己刚写的内容,觉得逻辑上看起来没问题,然后直接停工宣告完成。它根本没有去运行测试,拿实际的执行结果来验证。
针对这个问题,LangChain 上了两道防线:
- 第一道:提示词层面的约束。在系统提示词里明确规定四步走的解题框架:规划 → 构建 → 验证 → 修复。特别强调:验证时必须拿结果去对照最初的任务要求,而不是去对照自己写的代码。
- 第二道:系统层面的卡口。加入完结前检查中间件(PreCompletionChecklistMiddleware)。当 Agent 准备退出、宣告完成时,系统会直接拦截它,强制要求它对照任务规格做一次验证,确认跑过测试后才允许退出。
改进二:上下文注入——给 Agent 提供环境和约束信息
Agent 对自己所处的环境、约束条件和评估标准了解得越多,它就越能自主地指导自己的工作。LangChain 做了三件事:
注入工作环境地图:Agent 一启动,系统自动扫描当前工作目录、父子文件夹结构、工具路径以及 Python 安装信息,把这些环境信息结构化后直接注入上下文。
明确自动评估标准:在系统提示词中明确声明:产出会直接被自动化测试评估,任务规格里提到的文件路径必须严格遵守,否则自动评分会失败。
注入时间预算:当接近截止时间时,系统引导 Agent 收敛问题,进入验证与收尾阶段。
改进三:循环探测中间件
在大量 Trace 日志里,存在一个典型问题:当 Agent 确定了一个方向后,会高度执着地推进。即使路径已经走不通,它仍会在同一个文件上反复做微小修改,尝试局部修补,而不是整体重审。这种现象被称为 Doom Loops。
LangChain 的解决方式是加入 LoopDetectionMiddleware:通过工具调用的钩子,持续记录每个文件的编辑次数。当某个文件的修改次数超过阈值时,系统向 Agent 上下文中注入提示,要求它重新审视整体方案,而不是继续局部修补。
改进四:算力分配策略——“推理夹心”
后台多步思考的推理型模型通常有不同的推理强度档位。LangChain 采用了一个直观有效的策略:“xhigh-high-xhigh”。
- 规划阶段使用 xhigh:理解任务、制定整体方案最容易决定成败,值得投入更高算力。
- 中间实现阶段降到 high:按计划写代码,不需要每一步过度推演,节省大量时间。
- 最后的验证与收尾阶段,再拉回 xhigh:查错、确认结果需要谨慎。
这种分段式算力分配,把最终分数推到了 66.5%。
成果
通过上述 Harness 优化,LangChain 的 Deep Agents 在 Terminal Bench 基准测试中的得分从 52.8 提升到 66.5,排名从第 30 名以外跃升至前五。
核心洞察:模型能力决定上限,而 Harness 决定你能逼近上限多少。
3.2 Gstack:个人开发者的 Harness 标杆
背景
在日常开发中,我们常常陷入一种困境:向 AI 助手请求功能,它确实写出了代码,但代码能跑却不符合业务逻辑,或者缺少关键的错误处理。我们花费大量时间修正 AI 生成的”字面正确但语义错误”的代码,本质上是因为通用助手缺乏对工程上下文的深度理解。
它们像是一个只会听令行事的初级程序员,缺乏架构师的全局视野和 QA 的严谨态度。
gstack 项目的出现,正是为了解决这一核心痛点。它不是一个新的模型,而是一套基于 Claude Code 的意见化工作流层,将单一的 AI 助手拆解为 CEO、工程经理、发布经理等十个专属角色,通过 slash 命令按需调用,让开发过程从”对话”升级为”协作”。
核心原理与架构设计
Gstack 的核心价值在于**”角色分离”**。传统的 AI 编程助手试图用一个模型解决所有问题,导致上下文污染和注意力分散。Gstack 通过预设的 Prompt 模板和工具链,将不同的工程任务路由给特定的”虚拟专家”。
这种设计哲学认为:代码审查应该由专注于质量的角色处理,而架构规划则应由关注业务价值的角色主导。
工作流逻辑架构:
用户指令(自然语言/命令)
↓
gstack 路由层(角色识别与上下文注入)
↓
Claude Code 核心(执行与生成)
↓
[CEO] 规划与需求分析
[Eng Manager] 代码实现与管理
[QA] 测试与质量保障
[Doc Engineer] 文档生成
[Release Manager] 发布与部署
在这种架构下,gstack 充当了中间件的角色。它不直接生成代码,而是优化输入给 Claude Code 的上下文。例如,当你使用发布命令时,gstack 会自动注入关于版本控制、changelog 生成和部署检查列表的指令,确保 AI 不会遗漏发布流程中的关键步骤。
这种”意见化”(Opinionated)的设计,意味着它强制执行了一套最佳实践,减少了开发者需要反复提示 AI 遵守规范的成本。
实战安装与配置
Gstack 基于 TypeScript 构建,依赖 Node.js 环境。安装过程简单:
# 克隆 gstack 仓库到本地开发目录
git clone https://github.com/garrytan/gstack.git
# 进入项目根目录
cd gstack
# 安装项目所需的 TypeScript 及运行时依赖
npm install
# 配置环境变量,此处需填入有效的 Anthropic API Key
echo “ANTHROPIC_API_KEY=你的密钥” >> .env
# 验证安装是否成功
npm run check
配置完成后,gstack 会作为 Claude Code 的插件层加载,用户可以在终端中直接通过斜杠命令触发特定工作流。
深度使用场景解析
场景一:架构规划与需求分析(CEO 角色)
在开始编码前,使用 /plan 命令可以激活 CEO 角色。通用助手往往会直接开始写代码,而 gstack 的 CEO 角色会先询问业务目标、用户场景和潜在风险。
用户:/plan 我想做一个内部使用的文件分享工具
gstack(CEO): 收到。在开始之前,我们需要明确几个关键点:
1. 目标用户是谁?内部全员还是特定部门?
2. 安全性要求是什么?是否需要审计日志?
3. 预期的并发量是多少?
4. 是否需要权限管理?如果有,权限粒度是怎样的?
…
场景二:代码实现与管理(Engineering Manager 角色)
使用 /implement 命令激活工程经理角色。它会负责代码的具体实现,同时确保符合团队的编码规范和架构约束。
场景三:测试与质量保障(QA 角色)
使用 /test 命令激活 QA 角色。它会自动生成测试用例,运行测试套件,并生成质量报告。
成果与启示
Gstack 证明了一个重要观点:即使是个人开发者,也可以通过精心设计的 Harness 体系,让 AI Agent 的表现达到专业团队的水平。
它的成功关键在于:
- 角色分离:避免单一 Agent 承担过多职责导致的上下文污染
- 意见化设计:强制执行最佳实践,减少重复提示成本
- Slash 命令体系:提供清晰的操作入口,降低使用门槛
产品启示:Harness 不仅是大型团队的专利,个人开发者同样可以通过模块化、角色化的设计,构建适合自己的轻量级 Harness 体系。
四、外部核心:OpenAI vs Anthropic 的工程化路径对比
4.1 核心思想对比
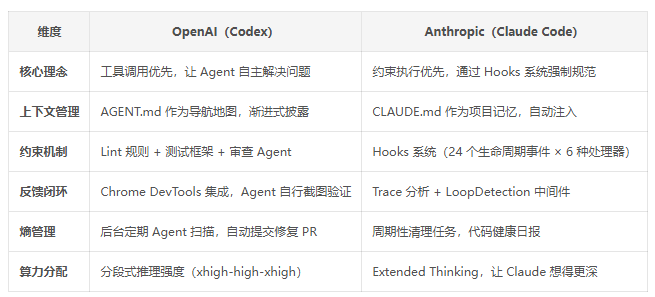
4.2 演变路径
OpenAI 的路径:
- 自动补全时代(幽灵文本):GitHub Copilot 式的代码补全
- 结对编程时代(IDE 里一起写代码):Codex CLI,人类与 AI 协同
- Agent 全委托时代(你只提需求,多个 Agent 自己规划、写代码、测试、提 PR):Codex 桌面端应用 + GPT-5.4
Anthropic 的路径:
- 启动期(2-4 月):终端聊天、CLAUDE.md、基础命令
- 爆发期(5-7 月):IDE 集成、MCP、自定义命令、Hooks、Subagent
- 深化期(8-10 月):Plan Mode、背景任务、插件系统、Skills
- 成熟期(11-12 月):Claude in Chrome、LSP、Opus 4.5、异步 Agent
4.3 关键金句
OpenAI:
“Taste captured once, enforced infinitely.”
品味捕获一次,强制执行无限次。
“If you‘re not the model, you’re the Harness.”
如果你不是模型,你就是 Harness。(Vivek Trivedy, LangChain)
“Harness Engineering is about designing the environment where AI can work reliably.”
Harness Engineering 是关于设计 AI 能够可靠工作的环境。
Anthropic:
“Constraints enable autonomy.”
约束赋予自主。
“The best Harness is the simplest one that solves today‘s problem, while leaving room for tomorrow’s upgrade.”
最好的 Harness 是解决今天问题的最简单架构,同时为明天升级留足空间。
LangChain:
“Model capability determines the ceiling, while Harness determines how close you can get to it.”
模型能力决定上限,而 Harness 决定你能逼近上限多少。
“Traces are the core signal of improvement. Without them, problems are attributed to ‘model inadequacy’.”
追踪记录是改进的核心信号。没有它们,问题只会被归结为”模型能力不足”。
4.4 工程化思考借鉴
从 OpenAI、Anthropic 和 LangChain 的实践中,我们可以提炼出五条可复用的原则:
原则一:追踪即反馈
没有 Traces,就没有改进方向。建立可重复、自动化的日志分析和错误诊断流程,比单纯优化 Prompt 更有效。
原则二:代劳上下文工程
把模型需要的环境信息提前整理好,主动递给模型,而不是让 Agent 自己去发现和组装运行条件。外围喂的信息越精准,模型就越能把算力集中在真正的解题步骤上。
原则三:强制自我验证
让模型真正面对客观的测试结果,而不是主观判断。模型天然偏向接受自己的第一个答案,必须主动推一把,让它真正面对客观的测试结果。
原则四:识别并修补坏模式
循环探测、早期停止、上下文腐烂……这些都是当前模型的典型缺陷。通过工程护栏(如 LoopDetectionMiddleware、PreCompletionChecklist)提供阶段性补丁,虽然未来可能变得多余,但在今天能显著提高成功率。
原则五:为特定模型定制 Harness
不同模型在提示风格、推理节奏上都有差异。若想把某模型的表现推到极限,需为它单独跑几轮迭代。通用 Harness 只能达到平均水平,定制化 Harness 才能发挥极致性能。
五、落地指南:如何为你的团队构建 Harness 体系
5.1 从零开始:三步搭出最小可用 Harness
看到这里,你可能会觉得 Harness 很复杂。其实不是,你不用一上来就做一个完整的系统。从这三步开始,就能搭出一个能用的最小化 Harness。
第一步:搭最小化文件系统 + Git 工作区
创建一个专属的工作区,初始化 Git 仓库,写好你的 AGENTS.md 核心记忆文件,把项目规范、架构要求全写进去。这一步,就解决了 Agent 的持久化和记忆问题。
第二步:封装代码执行 + 沙箱环境,做最小闭环
用 Docker 搭一个简单的隔离沙箱,给 Agent 封装 Bash 和 Python/Java 代码执行能力,让它能自己写代码、跑代码、验证结果。这一步,就给了 Agent 自主解决问题的核心能力。
第三步:加记忆注入 + 上下文管理,解决核心痛点
写一个简单的上下文管理模块,Agent 启动的时候自动注入 AGENTS.md,上下文快满的时候自动做压缩,工具输出自动做卸载。这一步,就解决了 Agent 失忆、上下文腐烂的问题。
做完这三步,你就有了一个最小可用的 Harness,你的 Agent 能力,绝对会比你之前搭的 ReAct 循环强 10 倍都不止。
5.2 进阶:引入 Hooks 系统和反馈闭环
当最小可用 Harness 运行稳定后,可以逐步引入更高级的功能:
引入 Hooks 系统:
- 在关键操作(如文件写入、命令执行)前后注册检查 Hook
- 将团队的编码规范、安全要求编码成自动化规则
- 实现“违反即阻断”的硬性卡口
建立反馈闭环:
- 接入 CI/CD pipeline,在 PR 创建时自动运行测试和 Lint
- 部署可观测性工具,监控 Agent 执行过程中的日志、指标、性能
- 引入独立评估 Agent,定期对已完成的功能进行质量评分和改进建议
5.3 高阶:熵管理与持续优化
当 Harness 体系运行一段时间后,需要关注代码熵的管理:
定期扫描与清理:
- 后台运行一个周期性 Agent,定期扫描代码库里的技术债
- 检查过时的依赖、被注释的死代码、违反架构约束的模块
- 自动提交修复 PR,人类工程师只需审核即可
定期审视与删除:
- 每季度回顾一次 Harness 的各个组件
- 随着模型能力的提升,某些组件可能变得多余,应该果断删除
- 保持 Harness 的简洁和高效,避免过度工程化
5.4 组织变革:从”写代码”到”设计环境”
Harness Engineering 不仅是一套技术方案,更是一种组织变革。它要求工程师的角色发生根本转变:
传统工程师:
- 核心工作:手写代码
- 价值体现:代码行数、功能交付速度
- 技能要求:编程语言、框架、算法
Harness 工程师:
- 核心工作:设计让 Agent 能可靠工作的环境
- 价值体现:Agent 吞吐量、代码质量、知识飞轮效应
- 技能要求:系统设计、自动化、规则编码、反馈闭环设计
这种转变意味着:未来的程序员,核心竞争力绝对不再是手写代码的速度,而是设计 Harness 系统的能力。你能设计出越好的 Harness,就能把模型的能力释放得越充分,你的生产力就越强。
六、派别之争:Big Model还是Big Harness
对于Harness Engineering( harness 工程化)这概念火归火,但唱反调的人可不少,而且个个来头不小。
“Bitter Lesson” 阵营:模型终将超越 Harness
OpenAI 的 Noam Brown 在 Latent Space 访谈里话说得很直白:
Harness 就像一根拐杖,我们终究是要甩掉它的。
这话可不是拍脑袋说的,是有历史教训在里的。
回想一下,在推理模型(Reasoning Models)出来之前,大家为了在 GPT-4o 上模拟出推理能力,折腾了多少东西?路由器、编排器、多智能体协作……整套基础设施搭得那叫一个复杂。
结果呢?推理模型一上线,这些玩意儿一夜之间就成了摆设。
Noam Brown 说得挺扎心:“之前大家投入那么多工程精力去搞 Agentic 系统,结果模型一旦具备了推理能力,那些复杂的行为根本不需要了。甚至在很多时候,加了这些层,效果反而更差。”
他预判,OpenAI 的未来是统一模型:
“我们公开说过,我们要走向一个单一统一模型的世界。你压根就不需要在模型上面再套一个路由器。”
所以他给开发者的建议,就一句话,特别实在:
“别花六个月时间,去搭建一个可能六个月后就被淘汰的东西。”
数据打脸:Harness 真的有用吗?
METR(一家专注 AI 安全评估的研究机构)的数据,更是给了 Harness 阵营一记闷棍。
他们找了 scikit-learn、Sphinx、pytest 这三个知名开源项目的 4 位核心维护者,让他们审查 296 个 AI 生成的 PR(代码合并请求)。结果有点尴尬:
- 合并率减半:维护者实际愿意合并的 PR 数量,只有自动化评分通过率的一半。
- 能力严重高估:以 Claude Sonnet 4.5 为例,自动评分器觉得它能搞定大约 50 分钟的工作量,但维护者实际敢合并的,只有 8 分钟左右的活儿。这意味着,AI 的能力被高估了整整 7 倍。
- Harness 增益微弱**:在他们的测试里,Claude Code 和 Codex 的表现,跟一个最基础的脚手架没啥区别。Harness 带来的提升,基本都在误差范围内晃悠。
Scale AI 的 SWE-Atlas 基准测试也得出了类似的结论。
Latent Space 把 Noam Brown 这一派叫做**「Bitter Lesson 阵营」。这个名字出自 Rich Sutton 那篇著名的 AI 随笔《The Bitter Lesson》:**别在工程花活上折腾太多,算力的暴力增长终究会碾平一切技巧。
说白了,你那些花里胡哨的 AI 脚手架,终将被模型的规模效应冲走。
行业分野:两大阵营怎么吵?
Latent Space 在 3 月初发了篇专题《Is Harness Engineering Real?》,直接把行业划成了两派。
1)Big Model 阵营
核心观点:模型变强才是硬道理,Harness 只是暂时的权宜之计。
代表声音:Claude Code 团队的 Boris Cherny 和 Cat Wu 说得很透:“所有的秘密武器都在模型本身。我们追求的是**最薄的那层包装**。”
怎么做:拼命做减法,别堆复杂性。Claude Code 就是这个思路的产物——Harness 层薄得不能再薄,尽量让模型自己拿主意。
2)Big Harness 阵营
核心观点:模型是引擎,Harness 是方向盘和刹车。引擎再猛,没方向盘你也到不了目的地,甚至可能翻车。
代表声音:LlamaIndex 创始人 Jerry Liu 立场鲜明:“Model Harness 就是一切。从 AI 那里拿到价值的最大障碍,不是模型不行,而是你自己不会做上下文工程和工作流工程。”
数据支撑:调研显示,开发者在 60% 的工作里都用 AI,但真正敢完全甩手给 AI 干的任务,只有 0% 到 20%。这中间巨大的鸿沟,Harness 阵营觉得,锅不在模型,而在你没把好 Harness 这道关。
深层洞察:变薄就等于消失吗?
两边吵得热闹,但可能都忽略了一个更深层的事实。
Harness 本身也在疯狂简化。
- Manus 在 6 个月内重构了 5 次 Harness;
- LangChain 一年内把研究型 Agent 重新架构了 3 次;
- Vercel 直接砍掉了 80% 的 Agent 工具。
这说明啥?说明 Harness 不是一劳永逸的。它得跟着模型一起进化。模型变强了,Harness 就得变薄。
但是「变薄」和「消失」是两码事。
Böckeler 在 Martin Fowler 网站上写了篇分析,点出了一个关键:Harness 真正的价值,在于约束解空间。
要想让 AI 生成的代码能大规模维护,靠的不是让模型自由发挥,而是通过架构模式、强制边界、标准化结构,把模型的输出限制在一个可控的圈子里。
Noam Brown 说得对,很多脚手架确实会被淘汰。但架构约束、反馈循环、熵管理这些东西,本质上不会消失,只会换个马甲继续存在。
打个比方:从马车到汽车时代,马鞭消失了,但方向盘和刹车永远不会消失。
这时候我们再来看 Noam Brown 那句“别花六个月搭建一个可能六个月后就被淘汰的东西”,反而成了最好的 Harness Engineering 建议:
Harness 要轻,要模块化,要随时准备被拆掉重来。
结语:Harness Engineering 的未来
聊完这一圈,我们对 Harness 的感受都应该回归平常的。
因为它没那么神秘,不像是什么刚诞生的新学科。
它更多的是一种集体共识的达成:大家终于承认,要把模型塞进真实工作流,难点从来就不只在模型本身,大家开始正视模型之外的东西:
边界怎么设?反馈怎么回?什么算做完?出错了从哪接着干?而这些事,最后都得靠系统来接住。
过去两年,大家都在拼谁的模型更强。
接下来这段时间,我觉得差距会体现在另一件事上:
谁更早把模型外面那层系统,当成一门正经的工程来做。
这话题可能在AI时代没那么sex,也没有那么热闹,但它可能是你最绕不开的那个坎。
随着模型越来越强,现在框架里干的某些活确实会被模型自己吸收,不再那么依赖上下文注入。
但这意味着框架不重要了吗?不太可能。
就像提示词工程今天依然重要一样,框架工程大概率也会长期存在。框架的价值,不只是补模型的短板,它是围绕模型智能构建系统、让模型更高效发挥的那层“放大器”。
我们相信一个配置良好的环境、合适的工具、持久状态和验证循环——无论底层模型有多强,都能让它跑得更稳、更快。
本文由 @要成为产品小李 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


