
 起点课堂会员权益
起点课堂会员权益AI的下一张船票:世界模型——AI产品经理必须理解的技术拐点
世界模型正在成为AI领域的新焦点,它补足了大语言模型无法理解真实世界的短板。从视频生成到3D建模,从虚拟训练到抽象结构学习,四条技术路线正在重塑AI的未来。对于产品经理而言,这意味着机器人、自动驾驶、AI Agent等赛道将被彻底改写。

一、为什么你需要关注世界模型?
作为AI产品经理,你可能已经习惯了这样的叙事:大模型越来越强,应用越来越广,只要等模型能力再提升一个档次,产品体验就能再上一个台阶。
但有一个问题正在浮出水面——大模型的天花板,可能比你想象中来得更早。
单纯把模型做得更大,已经不会再像过去那样带来立竿见影的突破。规模继续上去当然可以变强,但在算力、数据、能源、成本这些硬约束下,性价比正在迅速下降。更关键的是,大模型始终缺乏一种能力:理解真实世界、预测未来变化、在物理环境中行动。
它可以写出一篇关于”杯子从桌上掉落”的精彩论文,但如果你让它控制一个机械臂去接住那个杯子,它会手足无措。
这就是世界模型要解决的问题。
二、世界模型到底是什么?
从人类的”直觉”说起
你是怎么知道一杯水放在桌边会掉下去的?
不是因为你背过”物体在桌面边缘会因重力掉落”这条规则,而是因为你在生活中积累了大量与物理世界交互的经验,在大脑中构建了一个”世界怎么运作”的内部模型。你能预判下一秒会发生什么,能想象”如果我这样做,会怎么样”,并在脑海中提前排演各种可能性。
认知科学称之为心智模型(Mental Model)。早在1943年,心理学家Kenneth Craik就提出:人在对现实作出反应之前,会先在大脑中构建一个”小规模的世界模型”,用它来模拟可能发生的过程,再据此选择行动。
世界模型,就是想让AI也拥有这种能力。
三个核心特质
2018年,Google Brain的David Ha与深度学习教父Jürgen Schmidhuber在论文《World Models》中,给出了一个简洁的框架:
世界模型 = 观察世界(V)+ 预测世界(M)+ 在内部世界中学习行动(C)
对应的是视觉(Vision)、记忆(Memory)和控制(Controller)三个核心模块。
用产品经理的语言来翻译:

Meta的Product Design Lead Yiqi Zhao的比喻更生动:世界模型就像一个缩小的平行宇宙。如果AI有了一个真正的”大脑”,它就拥有了自己的世界观——因为能做预测,所以能做推演;因为能做推演,所以能做决策。
三、世界模型 vs 大语言模型:不是替代,是补位
这是很多人最困惑的问题:世界模型和大语言模型到底是什么关系?
我用一张表说清楚:
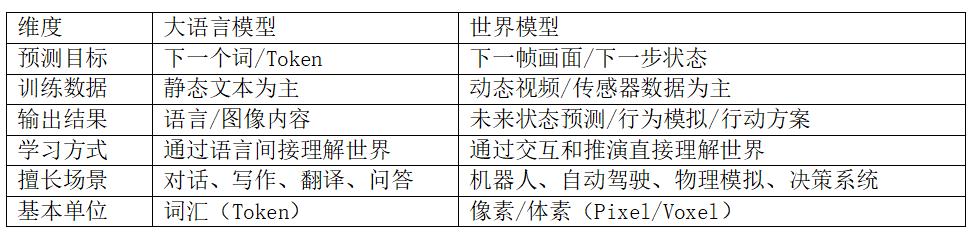
李飞飞精炼总结过两者的本质区别:大语言模型的基本单元是词库,世界模型的基本单元是像素或体素。
但这里有一个关键的认知需要建立:世界模型并不是要推翻大语言模型,而是为大语言模型补上”现实世界”的维度。
加州大学戴维斯分校的陈羽北教授打了一个很好的比方:在语言中我们有了GPT,当预训练的好处达到一定程度,它可以被快速变成任何下游应用。世界模型可以被认为是一个”大号的GPT”——它包含了感知和控制。如果这条路线也能获得根本上的成功,未来所有机器人、所有智能体都可以用预训练+后训练的方式产生,这将彻底解锁一些AI的应用场景。
对AI产品经理来说,这意味着:未来的AI产品形态,将不再只是”对话框+工具调用”,而是”世界理解+行动执行”。
四、四条技术路线:谁在做,做什么,有什么不一样
当前世界模型的产业实践,可以用一个”三层框架”来理解:
- 底层:世界模型的思想与范式(Latent MDP + Learn Dynamics + Simulator)
- 中间层:世界的”表现形式”——世界如何被生成出来
- 顶层:智能体训练——让AI在这个世界里行动
目前最热闹的是中间层,也就是”世界生成”,主要有四条技术路线:
路线一:视频生成——把世界”画”出来
代表产品:OpenAI Sora、Google Genie 3、Seedance、Veo、可灵(Kling)
视频生成路线的目标很直观:让AI生成一个”能动起来的世界”。
OpenAI发布Sora时就将其定义为”世界模拟器”——不是简单地把视频用静态图像一张张拼出来,而是让画面里的事物随时间连续演化。而Google的Genie 3更进一步,实现了实时交互性和长时间一致性:用户可以跟模型进行数分钟的互动,黑板上写的字走开再回来还在,说明模型已经能”记住世界里的状态”。
今年1月,Google推出Project Genie,将Genie 3封装为可上手体验的产品:Gemini提供逻辑支撑,Nano Banana Pro生成高精度场景与角色,Genie 3将静态设计”激活”为可互动的3D世界,依托TPU v5实现了720p/24fps的实时渲染。
优势:结果”看得见”,能快速验证,商业化路径清晰(影视、广告、游戏),对Scaling Law敏感——规模越大效果越好。
局限:世界理解是”隐式”的——藏在权重里,无法直接提取结构。比如你让Sora生成一辆车的行驶视频,光影可能很逼真,但问它车的长宽高、被挡住的轮胎在哪里,它答不上来。它学到了像素组合的概率分布,但并没有构建3D几何模型。
洞察:视频生成路线的商业化最成熟。可灵AI的ARPU已破1亿美元,AI视频深度渗透广告、影视、短剧等B端工作流。从产品形态看,视频生成正在从”工具”走向”平台”——当Genie 3实现了实时交互,它就不再只是”视频制作工具”,而是”可交互的世界构建平台”。这是一个重要的产品定位转变。
路线二:3D生成(空间智能)——把世界”建”出来
代表产品:World Labs(李飞飞)/ Marble、Meshy AI
李飞飞的思路是:真正的世界不是2D的,AI必须理解空间,才能理解世界。
World Labs最新发布的Marble模型,给它一张照片或视频,就能通过高斯泼溅技术重建出完整的3D场景结构。Marble像建筑师,看到图片时不只看到”像素”,而是看到背后的三维结构——能告诉你汽车长4.5米、宽1.8米,还能输出3D网格文件。
优势:生成的是”显式结构”——模型知道每个物体的具体位置,物理模拟、规划、控制都更容易实现。一旦掌握这些信息,就能继承传统物理引擎的优势,确保碰撞、遮挡、施力等表现严格正确,成为”可操作世界模型”的底座。World Labs一年半估值飙升5倍至50亿美元,市场认可度极高。
局限:3D训练数据稀缺(需要LiDAR等专业设备采集)、几何结构难建(需要物体封闭无穿模)、算力需求远超2D模型。
洞察:3D路线的战略价值大于短期商业价值。它是世界模型从”看起来像”走向”真的能用”的关键一跃。对于游戏、室内设计、建筑可视化等产品方向,3D生成路线可以直接落地。但从产品节奏看,3D路线的技术成熟度还不及视频路线,需要更长周期的投入。
路线三:虚拟世界训练——让AI在游戏里”练级”
代表产品:Google SIMA 2
SIMA的思路直接:既然现实世界太复杂、真实训练太昂贵,那就用虚拟世界来教AI行动。游戏天然是复杂、可交互、实时反馈的环境,是AI发展的传统摇篮。
SIMA 2将Gemini嵌入内核,首次使用Genie 3生成的游戏世界进行训练。它展现出几个突破:不仅能”跟指令做事”,还能”自己思考”——理解复杂多步任务,在陌生环境中自主探索规划。更重要的是,它具有跨游戏、跨环境的泛化能力,为将来的具身机器人迁移奠定了基础。
洞察:这条路线的本质是AI的”训练基础设施”,而非面向终端用户的产品。但作为AI产品经理,你需要理解:当世界模型能生成可交互的虚拟环境,Agent的训练成本将大幅下降。这会直接影响AI Agent产品的迭代速度和商业化可行性。
路线四:抽象结构学习——不画世界,学世界的”骨架”
代表产品:JEPA(Yann LeCun / Meta)
Yann LeCun的思路最反直觉:不用生成任何画面,让AI直接学习世界的抽象结构。
JEPA不预测图像、不预测像素,也不重建视觉内容,而是把真实世界压缩成抽象的高维潜在表示,在这个潜在空间里进行预测——预测空间上被遮挡的区域,或时间上的后续状态。
举个简单例子:轻轻推一个球,视频模型要预测下一帧里球的位置、阴影、光照、材质反射;但JEPA只关心球会往哪个方向滚、速度会怎么变、会不会撞到障碍物。它学习的是未来的结构,而不是未来的画面。
优势:计算成本更低、更容易捕捉因果关系、更适合机器人和具身智能需要的”可操作世界”。
局限:不可见(难以验证模型”理解了什么”)、自监督目标极难设计(什么才是”结构”?)、缺乏统一的评估体系。JEPA更像”世界模型的前额叶原型”——方向可能正确,但距离成熟落地还有一段距离。
洞察:JEPA路线短期内不太可能产出面向用户的产品,但它的理论价值极高。如果这条路线走通,意味着AI不需要先生成世界就能理解世界——这将是对”世界模型=世界生成”这一默认假设的颠覆。作为AI产品经理,你需要关注的是:当JEPA成熟后,那些依赖”视觉呈现”的产品形态是否会被重新定义。
五、从AI产品经理视角:世界模型会改写哪些产品赛道?
以上是技术科普。现在,让我切换到AI产品经理的视角,谈谈世界模型对产品赛道的影响。
1. 机器人产品:从”编程执行”到”理解行动”
当前机器人行业最大的痛点是:每一项新任务都意味着一次新的工程项目。机器人做的一切本质上是”被编程好的动作”,环境稍有变化就会”失能”。
世界模型带来的改变是范式级的:让机器人拥有”世界的内部模型”,先在内部模拟再决定是否执行,具备跨环境的迁移能力。结合VLA(视觉-语言-动作)模型和System 1+System 2双系统架构,机器人将从”只能执行预设动作”进化为”能理解环境、规划行动”。
机会:面向特定场景的机器人产品(仓储、餐饮、家庭服务)将率先受益。AI产品经理需要思考的是:当机器人不再需要逐场景编程,产品形态如何从”项目制交付”转向”标准化产品”?
2. 自动驾驶:从”感知-反应”到”预测-推演-决策”
L5自动驾驶迟迟未到的根本原因:系统”看得见世界”,但难以真正”预测世界”。极端天气、突发事故等长尾场景在真实道路中极其稀少,是规模化瓶颈。
Waymo正在构建以Foundation Model为核心的自动驾驶系统——内部进行端到端训练,同时保留对世界的结构化表达。这不仅还原场景,还能在不同假设下预测交通参与者行为,同时推演大量可能决策路径,筛选最安全的一条。
机会:世界模型是推动自动驾驶从”局部可用”走向”大规模商业化”的核心技术。产品经理需要关注的是:当仿真系统能高质量生成极端场景,安全验证的效率将如何提升?产品上线节奏如何调整?
3. AI Agent产品:终于有了”训练场”
当前AI Agent的讨论多集中在”够不够聪明”、”工具调用做得好不好”,但一个更底层的问题一直没解决:Agent到底在什么环境里学会”行动”的?
真实世界太昂贵、太缓慢、太危险,无法支撑大规模试错。世界模型解决的正是”环境”本身的问题——通过学习真实系统的数据,在模型内部构建可运行的世界,让Agent进行大规模训练。
世界模型不是让Agent立刻变得更聪明,而是第一次为Agent提供了可训练、可试错、接近真实的”内在世界”。
机会:AI Agent产品的迭代速度将取决于”训练环境”的质量。谁先拥有高质量的世界模型,谁就能更快地训练出更聪明的Agent。这对AI Agent产品的竞争格局将产生深远影响。
4. 内容/游戏产品:从”制作”到”生成”
游戏行业最直接:过去需要数百人团队花费数年搭建的开放世界,未来只需要设计师设定规则和生态,AI就能自动生长出地形、天气、NPC的性格和记忆、经济系统。
Meshy AI CEO胡渊鸣的描述更加具体:传统游戏的所有规则已经被写好了,但如果在游戏场景中加入生成式AI,游戏就可以on the fly(即时)生成。先用3D模型生成角色外形,再通过多模态大模型添加性格等逻辑,也可以实现一个世界模型。
机会:游戏产品从”内容产品”转向”平台产品”——不再卖固定内容,而是卖”世界生成能力”。产品经理需要重新定义”可玩性”:当世界是动态生成的,玩家的体验如何保持一致性?如何平衡”惊喜感”和”可控性”?
5. 穿戴设备:从”信息终端”到”世界理解引擎”
当前的可穿戴设备本质上是记录工具——看起来智能,但不理解你的环境。世界模型会让设备真正读懂3D世界,实时推断空间结构和潜在风险,从工具变成”数字伙伴”。
机会:眼镜、耳机、手表都可能进化为与你共同生活、共同行动的智能体。这可能是下一代计算平台的起点。
六、AI产品经理必须思考的三个问题
问题一:世界模型的”幻觉”怎么办?
语言模型的幻觉是编造事实,视频模型的幻觉是画面错误,但世界模型的幻觉出现在整个”世界结构”里——误判物体重量、高估动作可行性、低估碰撞后果,甚至构建错误的因果关系。
这种错误是”系统级”的,更难发现、更难对齐。当AI不只生成内容,而在现实中推演、行动、做决定,幻觉的代价将从”一段错误文字”升级为”一次错误行动”。
启示:世界模型产品的安全设计必须从”输出审核”升级为”系统验证”。产品需要内置”置信度评估”机制——在AI决策前,先评估模型对该场景的理解有多可靠,低置信度时降级为人类确认。
问题二:产品如何选择技术路线?
四条技术路线各有优劣,产品经理需要根据场景做判断:
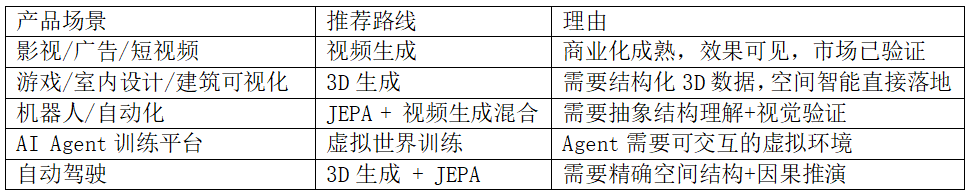
核心原则:面向用户的产品优先选”看得见”的路线(视频/3D),面向AI训练的基础设施优先选”学得深”的路线(JEPA/虚拟训练)。
问题三:世界模型产品的商业壁垒在哪里?
当世界模型成熟后,只有极少数机构有能力构建和运行世界模型——它需要海量数据、巨大算力和顶尖人才。这意味着:
- 平台层的竞争将是寡头格局(类似今天的大模型),AI产品经理不需要自己建世界模型,但需要理解不同世界模型的能力边界
- 应用层的壁垒在于”领域数据+场景理解”——谁能把世界模型的能力与特定行业的深度知识结合,谁就能建立护城河
- 数据层的价值将被重估——当世界模型需要海量动态数据训练,那些拥有独特场景数据(如工厂传感器数据、手术视频、驾驶数据)的企业,将拥有新的谈判筹码
七、这是AI产品经理的”第二个窗口期”
回看AI产品的发展,第一个窗口期是大模型爆发期(2023-2025),AI产品经理的机会在于”把大模型能力封装成用户可用的产品”。这个窗口正在逐渐收窄——对话产品、写作助手、代码工具等赛道已经拥挤。
世界模型正在打开第二个窗口期。
这一次,机会不只是”封装能力”,而是”定义场景”:当AI从”只会说话”走向”会观察、会推理、会行动”,哪些全新的产品形态会诞生?哪些传统产品会被重新定义?
AI产品发展的五阶段模型告诉我们:

世界模型,正是从Level 3迈向Level 4的关键技术底座。它让AI从”按指令执行”进化为”自主创新”——不再只是回答问题,而是能理解世界、预测未来、在世界中行动。
AI从”说话”到”干活”的进化,世界模型是最关键的那块拼图。
而当AI真的开始”干活”,AI产品经理的角色也将从”设计对话流程”升级为”设计人机协作流程”——不再是”人提问,AI回答”,而是”人设定目标,AI理解世界并执行”。
这个转变,比大模型本身带来的影响,更加深远。
本文由 @赞美愚者 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


