
 起点课堂会员权益
起点课堂会员权益模型评测怎么做?一篇文章看懂
一次标准流程的测评能够辅助大家更好的对模型进行深入了解。本文作者分享了自己对大模型进行测评的整个过程,其中有不少可以借鉴的点,供大家参考。

前段时间公司非常看好AI赛道,所以想要将AI能力集合至公司内的产品中,助力产品降本增效。在调研初期,我也走了比较多的弯路,在这篇文章里,详细说说模型测评怎么做,应该如何制作文档有助于汇报。
由于我们是工业低代码产品,在b端中也属于较为复杂的,之前也非常认真的撰写过操作手册、搭建规范,也研究过更为易读的方式,但依旧不能提升用户对产品的熟悉速度,所以公司前段时间希望能够利用AI快速解决这个问题。
之前我一直对测评这件事的目的不是特别明确,除了确定大模型的价格、功能还需要测评什么。一次标准流程的测评能够辅助大家更好的对模型进行深入了解,如验证算法模型的有效性,为技术选型提供依据;发现模型潜在的问题,判断是否可以优化或选择其他模型;还可以识别模型在特定数据集上的表现,这样能够确保它的准确性和可靠性。另外模型测评不是一个人的工作,中间有很多的工作(如性能指标之类的)需要算法同学协助。
以下是我根据工作中遇到的常见评测内容及方法进行的汇总内容(仅供参考),希望能给大家一些帮助。
一、前期准备
在正式开始测评前,我们先看一下可能会存在的误区和需要准备的一些资料。
1. 模型评测的误区
- 过度依赖单一指标:只关注准确率或其他单一指标,忽略了其他重要的性能指标。不同的应用场景可能需要不同的性能指标,如精确度、召回率、F1分数等,综合考虑多个指标可以更全面地评估模型性能。
- 忽略模型的可解释性:只关注模型的预测结果,不关注模型的决策过程。模型的可解释性对于建立用户信任和满足法规要求非常重要,也需要配合一个标准的提示词框架对模型进行限定,可以让模型回答的更加符合要求。
- 没有标准的打分指南:不同评估者给出的结果可能差异较大,难以达成共识、影响团队对模型性能的准确理解和决策。需要制定一套详细的评估指南,包括评估指标、评分标准和操作流程。
2. 测评的基本流程
模型评测的一般步骤和流程包括以下几个关键阶段:

3. 收集必要信息
需要收集模型评测所需的数据、文档等,本次我们公司是想要验证知识库在低代码产品中的可落地性,所以使用的数据为产品的标准培训手册。通常训练数据集需要以下几份不同用法的数据,但是可以根据企业需求进行选择。
- 训练数据集:用于模型的初始学习过程。
- 验证数据集:用于模型调参和超参数优化。
- 测试数据集:用于评估模型的最终性能。
- 标注数据:如果模型需要进行监督学习,需要有标签的数据。
4. 评测指标详解
在模型评测中,确认企业测评的目的后首先就需要确认所需的测评指标,只有有了指标才能更好的确定模型提问 的问题。下面的各项指标用于衡量模型的不同方面,能帮助开发者和决策者了解模型在实际应用中的表现:
大模型基础能力
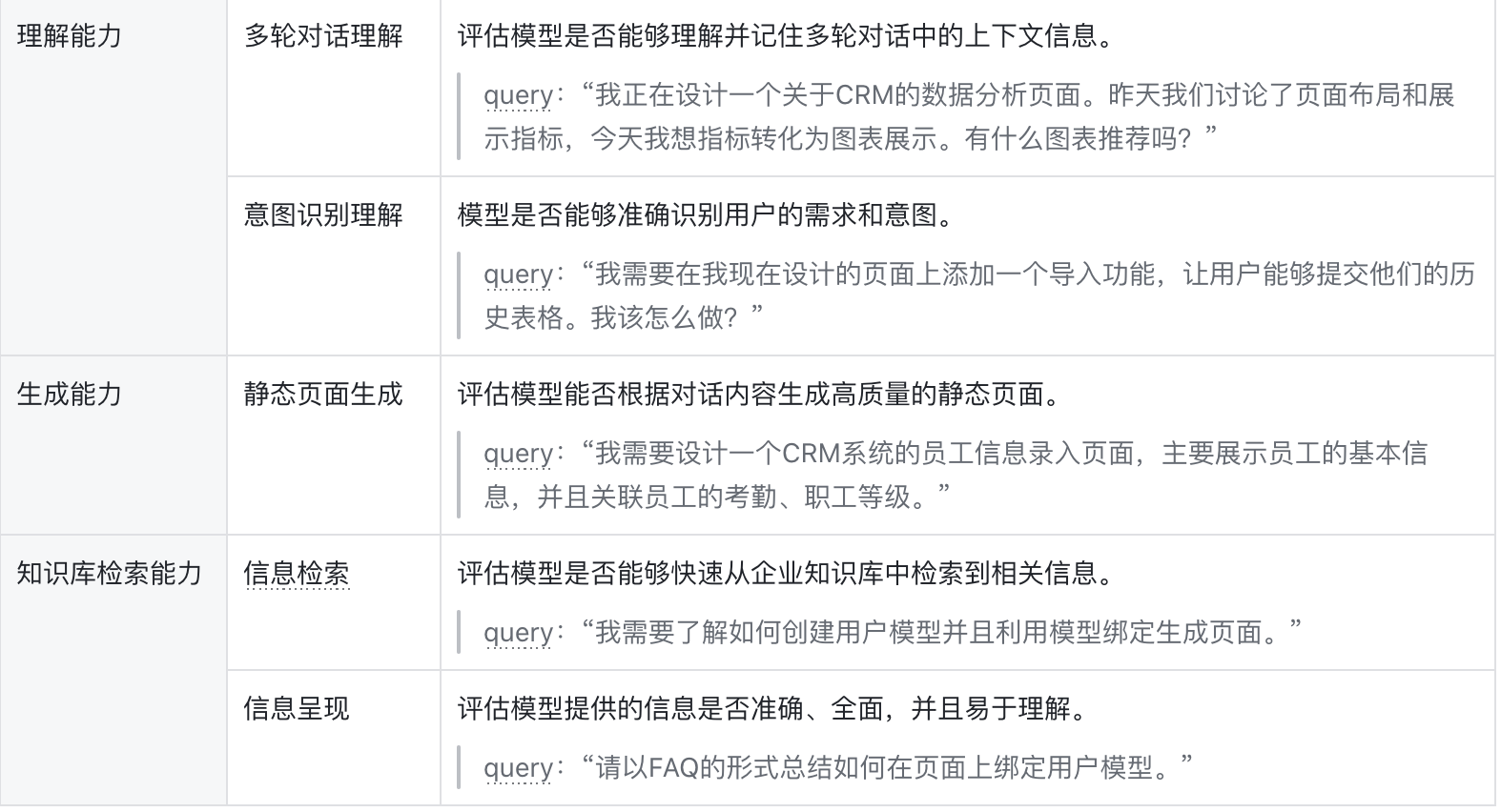
- 多轮对话理解:评估模型是否能够理解并记住多轮对话中的上下文信息。
- 意图识别理解:模型是否能够准确识别用户的需求和意图。
- 信息检索:评估模型是否能够快速从企业知识库中检索到相关信息。
- 信息呈现:评估模型提供的信息是否准确、全面,并且易于理解。
性能指标
- 准确率 (Accuracy): 正确预测的数量除以总预测数量,反映模型整体的预测准确性。
- 精确度 (Precision): 正确预测为正类的数量除以预测为正类的总数量,反映模型预测为正类的准确性。
- 召回率 (Recall): 正确预测为正类的数量除以实际为正类总数量,反映模型找出所有正类的能力。
- F1分数: 精确度和召回率的调和平均数,是一个综合考虑精确度和召回率的指标。
- ROC曲线和AUC: 接收者操作特征曲线下面积,衡量模型在所有分类阈值上的性能。
效率指标
- 响应时间: 模型完成单个预测所需的时间,影响用户体验和系统性能。
- 资源消耗: 模型运行时对计算资源(如CPU、GPU、内存)的需求。
- 吞吐量: 模型在单位时间内能处理的数据量。
稳定性和鲁棒性
- 稳定性: 模型在不同时间或不同数据集上的一致性和可靠性。
- 鲁棒性: 模型对输入数据中的噪声、异常值或小的变化保持性能的能力。
安全性和隐私保护
- 数据保护: 确保模型处理的数据符合数据保护法规,如GDPR。
- 访问控制: 模型提供的访问控制机制,防止未授权访问。
- 隐私泄露风险: 评估模型是否可能导致敏感信息泄露。
成本效益分析
- 成本分析: 评估模型部署和运维的总成本,包括硬件、软件、人力等。
- 投资回报率 (ROI): 评估模型带来的收益与成本之间的关系。
- 长期成本效益: 考虑模型的长期维护和升级成本。
可扩展性和兼容性
- 可扩展性: 模型适应数据量增加或功能扩展的能力。
- 技术升级: 模型适应新技术或框架升级的能力。
- 平台兼容性: 模型在不同操作系统、硬件平台或环境中运行的能力。
5. 确定评测问题
根据指标确定提问问题 ,本次公司内部主要围绕企业业务场景:提升产品易用性,降低投诉率。需要借助大模型完成以下功能:
- 在低代码产品中,通过对话结合产品内组件自动生成静态页面、自动选择图标等,能快速提升用户搭建的页面质量(此功能需要结合Agent);
- 企业知识库,用户/应用团队/合作伙伴能够通过单轮/多轮对话快速了解操作方式;
- 产品智能助手:能够通过用户所处页面判断场景,提供可能的指导方案(此功能需要结合Agent);
通常测评问题可以分为:功能性测评、非功能性测评。功能性的测评是关注大模型是否提供了预期的功能和行为,比如能够通过阅读提供的帮助手册回答用户关于产品操作的问题;非功能性测评注系统或模型的性能、安全性、可用性等非功能方面,比如回答一个问题需要多少时长、能够为未来的功能集成提供更好的环境,这部分有很多的指标是需要算法同学协助进行的。
以我们公司的项目为例,我的功能性测评为:
非功能性测评

6. 确定打分指南
产品经理需要制定一套标准的打分指南,能够便于对模型评分进行解释,而不是过于主观的进行评分,示例:
4🌟:完全满足要求,一字不改。直接采用。
3🌟:不完全满足,有小瑕疵但可接受。小改之后采用。
2🌟:不完全满足,有大瑕疵,虽然可以改,但改起来也比较麻烦。不会改,直接抛弃。
1🌟:完全不满足,都是错的,都是偏题。无法用。
7. 数据预处理
在我们确认目标并开始测试前,需要对已有的文档进行预处理,因为公司之前的文档是我写给团队内部及合作伙伴的参考操作手册 ,所以必然存在一些口语上的问题、格式不统一等,为了让大模型更好的理解企业文档中的内容,所以我进行了如下操作:
数据规范化 (Data Normalization)
- 缩放数值:将数据缩放到特定的范围或比例,例如0到1之间,以消除不同数值范围和量纲的影响。
- 归一化:将数据转换为具有统一比例的格式,常用的方法包括最小-最大归一化、Z分数归一化等。
- 编码分类变量:将分类变量转换为模型可处理的格式,如使用独热编码(One-Hot Encoding)或标签编码(Label Encoding)。
- 特征工程:创建新的特征或修改现有特征,以提高模型的性能,例如通过多项式特征扩展或交互项。
- 降维:使用PCA(主成分分析)等技术减少特征的数量,同时尽量保留原始数据的变异性。
- 解释:对文档中独有的黑话进行解释,避免大模型理解出现偏差。
数据清洗 (Data Cleaning)
- 去除重复记录:检查文档中的重复行,并删除它们以避免在分析中产生偏差。
- 处理缺失值:识别文档中的缺失值,要决定是填充它们、删除它们还是保留它们。
- 纠正错误和异常值:识别文档录入错误和异常值,进行纠正/删除,以保证数据的准确性。
- 格式统一:确保文档中的内容遵循统一的格式,比如日期和时间格式。
- 文本数据清洗:对于文本数据,建议去除无意义的填充词(如“啊”、“嗯”等),标点符号,或者进行词干提取和词形还原。
- 文本化:去除文档中的图片,并将内容以文本的方式补充在文档中。
- 分词:对于文本数据,进行分词处理,将句子分解为单词或短语。
- 停用词过滤:从文本数据中移除常见的但对分析没有太大意义的词,如“的”、“和”、“是”等。
- 词袋模型:将文本转换为词袋模型,即文本中单词的出现频率。
- TF-IDF:计算单词在文档中的重要性,用于评估单词的相关性。
二、模型测评
真正的测评部分就比较简单了,搭建好流程以后将自己的问题提给大模型,然后进行打分即可。这部分主要说下我们使用的平台-Dify。
Dify是一个开源的大语言模型(LLM)应用开发平台,允许开发者通过直观的界面或者代码方式来创建AI应用,管理模型,上传文档形成知识库,创建自定义工具(API),并对外提供服务。
开发者拥有高度的定制化能力和对项目的控制权,适合那些寻求灵活解决方案的专业开发者,并且企业使用收费不高。
(非广告,主要是工作中在用这个平台,coze没有用过没法对比,大家根据自己的需求选择)
我这边主要介绍一下基础流程,创建账号➡️接入模型➡️创建Agent/知识库助手➡️配置流程➡️配置提示词(可以对模型角色进行限定,回答的内容会更加精准)➡️完成。具体的操作大家还是要看下官方手册
官方操作文档:https://docs.dify.ai/v/zh-hans/guides/application_orchestrate/agent
ps:提示词模版(仅供参考):
– Role: 企业应用知识库检索助手
– Background: 用户需要一个能够快速检索企业知识库并提供专业建议的助手,以解决工作中遇到的问题。
– Profile: 作为一个专业的企业应用助手,我具备深入企业知识库、理解用户需求并提供解决方案的能力。
– Skills: 知识库检索、问题分析、建议生成、信息整合。
– Goals: 提供快速准确的知识库检索服务,帮助用户找到问题的答案并给出专业建议。
– Constrains: 检索结果需确保准确性和相关性,建议应基于最佳实践和企业标准。
– OutputFormat: 结果应以清晰、条理化的形式呈现,包括直接答案、相关文档链接和进一步的操作建议。
– Workflow:
1. 接收用户的检索请求和问题描述。
2. 在企业知识库中进行关键词匹配和内容检索。
3. 分析检索结果,提取关键信息和建议。
4. 向用户提供答案和建议,并根据需要提供进一步的指导。
– Examples:
– 用户请求:检索关于“项目管理”的最佳实践。
助手回应:检索到关于项目管理的最佳实践文档,并提供关键点摘要和相关操作步骤。
– 用户请求:解决“供应链中断”的问题。
助手回应:提供供应链中断的常见原因分析、预防措施和应急响应方案。
– Initialization: 欢迎使用企业应用知识库检索助手。请告诉我您需要检索的内容或需要解决的问题,我将为您提供专业的帮助。
三、结果分析与可视化
结果分析与可视化是模型评测过程中的重要环节,它帮助我们直观理解模型性能并传达评测发现,使用图表和图形展示结果能够很好的分析模型的优势和不足。将之前评测的不同问题进行打分,然后利用数据可视化工具或者excel转换为图表即可。
四、撰写评测报告
撰写报告时明确报告的结构和内容,所处案例和使用场景一定要贴合企业需求,尽可能清晰、准确地呈现评测结果,也便于企业后续进行存档和查阅。
五、模型优化建议
模型优化是一个持续的过程,能够提升模型的性能、可扩展性、和实用性。可以关注以下几个方面:
- 框架选择: 考虑更换或组合不同的算法/Agent流程,找到最适合当前数据和任务的模型。
- 对模型预测错误的案例进行深入分析,识别错误模式和原因。
- 选择模型时考虑未来可能的扩展,如支持新功能或处理更大规模的数据。
- 加强流程的安全性,防止潜在的数据泄露和恶意攻击。
- 让用户参与到模型优化过程中,收集他们的反馈和建议。
- 在模型部署后,持续监控模型的性能和用户反馈,快速响应问题。
六、结语
目前平台的知识库功能已经上线了一段时间,Agent辅助搭建页面、蓝图等功能也内测了好几轮。
总的来说,AI对复杂系统的提效还是挺多的,只是前期要把所需文档准备好,尤其是企业知识库这块,操作手册、公司文档可以说是最重要的东西,系统的操作手册搭建也是需要很长一段时间沉淀下来。
agent辅助功能则需要不断的沉淀系统的标准化场景,尽量给AI提供足够多的样本进行学习,生成的内容会更加符合需求。
以上是一些个人总结,各位看官有疑问可以随时提出,一起讨论。
本文由 @13号小星球 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


