
 起点课堂会员权益
起点课堂会员权益基于认知理论的 AI 架构探索
本文基于笔者于 2024年 6月 在 AI 架构理论方面实验,大部分文字汉化自 8月中旬给 Llama 团队做的 Talk。恰好 OpenAI 最近发布的 o1 指向了相似的方向,于是将内容科普化之后和大家讨论。

原文链接(欢迎在原文 Comments 讨论):https://www.wangyulong.io/AI-17fada57edb946468a38dc71322a449f?pvs=4
当前的 AI 系统,从最简单的 Chat 模型、ChatGPT 类产品到各种复杂的 Agent,架构的设计丰富多彩但又缺乏明确的方向。Scale up 成了唯一的主题,但 Scale up 的对象却又充满争议(参数?数据?推理时间?)。
文中名为 Sibyl 实验项目是笔者构建的一套参考认知理论的 AI 系统,在 GAIA(通用AI助手评测)榜单上取得第一的成绩。Sibyl 这个名字来源于《Psycho-Pass》中由众多人脑组成的多智能体系统。
代码:https://github.com/Ag2S1/Sibyl-System
技术报告:https://arxiv.org/abs/2407.10718
1. 文字游戏
我们先看一个简单的文字游戏:下图中这是一个 5×7 的字母块,请从里面抽出一个合法的句子。

这里可以暂停 10 秒思考下。
如果你把这个题目扔给 ChatGPT,它最终可能会告诉你这样的答案(截止至 2024年8月27日 19:27:53):
These gulls glide peacefully to my chair.
猛一看,好像是对的。但当你仔细观察就会发现有不少问题:
- 第二行的第一个字母 A 没了
- GULL 后面多了个 S
- 第四行的第一个字母 D 没了
但当你把这个问题扔给 Sibyl,它会给你这样的答案:
THE SEAGULL GLIDED PEACEFULLY TO MY CHAIR
仔细检查下,Sibyl 做对了!
我们可以把原题目中的字母染色来更好地理解一开始的字母块。
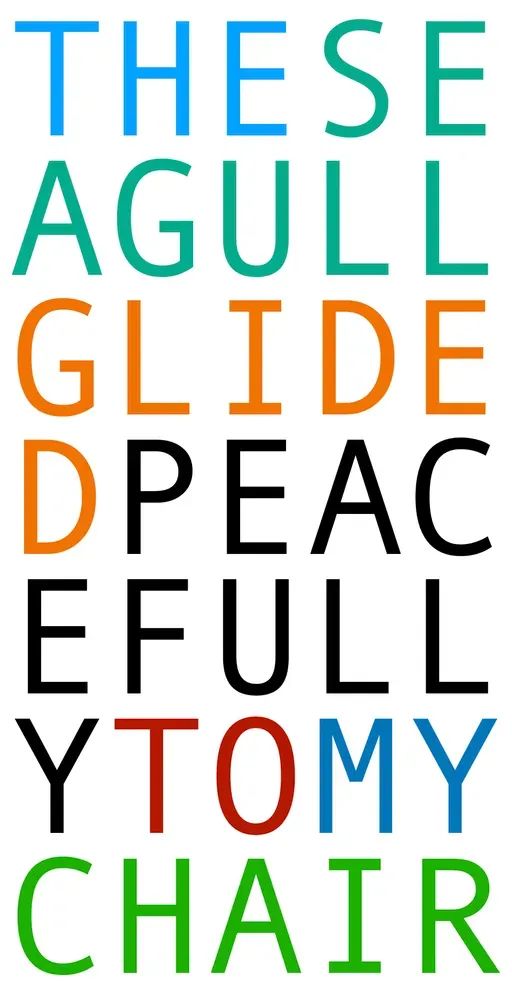
ChatGPT 把 THE SEAGULL 理解成了 THERE GULLS,并且并没有意识到它自己犯错了。
而 Sibyl 底层和 ChatGPT 一样都是基于 GPT-4o 这个模型的 (并且 ChatGPT 用的模型通常比 API 的版本更先进),为什么它能做对?
笔者并不认为 Sibyl 有多么先进的黑魔法,毕竟其只比 OpenAI、微软、Huggingface 等团队的系统稍微好几个点。
但只一次提交就获得了 GAIA Benchmark (通用 AI 助手评测)第一,并且相比于其它方案更有理论的延展性和指标的泛化性,让我对其增强了信心。
2. 为什么要构建 Sibyl
2.1 探索 AI 的潜力
现在能用到的 AI 类产品都为了成本和易用性妥协了很多:
- 控制模型参数量
- 更低的量化精度
- 更直接的、直觉性的、类似 System 1 的回答(也许并不是有意的产品设计)
- 更快的首 token 时间
如果我们放弃这些限制,不考虑成本和易用性,用最好的可用的模型,最有效的 reasoning trick,就为了得到最好的答案呢?
在这方面已经有很多相关工作,从最早的 Scratchpads(https://arxiv.org/abs/2112.00114),到后来的 Chain of Thought、Tree of Thought 等 X of Thought 类工作,都直觉性的在往这个方向走。
2.2 一个更好用的日常工具
ChatGPT 和 Perplexity 是非常好用的日常工具,但还不够好,不够满足我个人的使用诉求。
譬如: ChatGPT 经常幻觉知识,不倾向于使用浏览器做实事检验;Perplexity 虽然幻觉问题大幅减少,但对信息的挖掘不够深,简单的搜索就进行摘要式生成,没有基于信息进行推理的多步决策,只适合简单的知识查询。
就我个人而言,日常工作需要大量的知识挖掘。经常需要从一个概念出发,经过多次跳转来获取信息,跳转的连接包括:论文引用、博客链接、作者、作者的实验室和导师、作者所在的团队等。在这种场景下 Perplexity 也会捉襟见肘。
我不在乎一个问题需要 10 分钟才能获得答案,只要异步的给我一个足够正确的答案就行了。
3. 回顾一下 Agent
3.1 传统 Agent
“agent”一词最早的使用可追溯到中古英语时期(1150—1500年)。根据《牛津英语词典》(OED)的记载,最早关于“agent”一词的证据出现在1500年之前,出自炼金术士兼奥古斯丁教士乔治·里普利(George Ripley)的著作。
我们需要先回顾下 AI 领域下 Agent 这个概念。这里我们引用下《Artificial Intelligence: A Modern Approach, 4th》的定义:
智能体 (Agent) 就是某种能够采取行动的东西 (agent 来自拉丁语 agere, 意为“做”)。
理性智能体(rational agent)需要为取得最佳结果或者存在不确定性时取得最佳期望结果而采取行动
人工智能专注于研究和构建做正确的事情的智能体,其中正确的事情是我们提供给智能体的目标定义。这种通用范式非常普遍,以至于我们可以称之为标准模型 (standard model)
比如深蓝或者 AlphaGo, 这类智能体的目标是赢得游戏。而它们的创造者们要做的是定义价值函数,以在不同的棋局下尝试不同的走法,根据价值函数选出其中最有可能获胜的走法,最终赢得游戏。
3.2 LLM based Agent
OpenAI 的 Lilian Weng 在这方面有一个经典的综述性文章,有兴趣的可以看原文:https://lilianweng.github.io/posts/2023-06-23-agent/
LLM 驱动的智能体相较于传统 Agent,利用了大型语言模型(LLM)的强大能力,彻底改变了智能体的工作方式。这类智能体不仅仅是完成单一任务的工具,它们能够在各种不同的任务之间切换,并且通过理解自然语言来解决问题。
其核心能力可以被分解为:规划、记忆、工具使用。
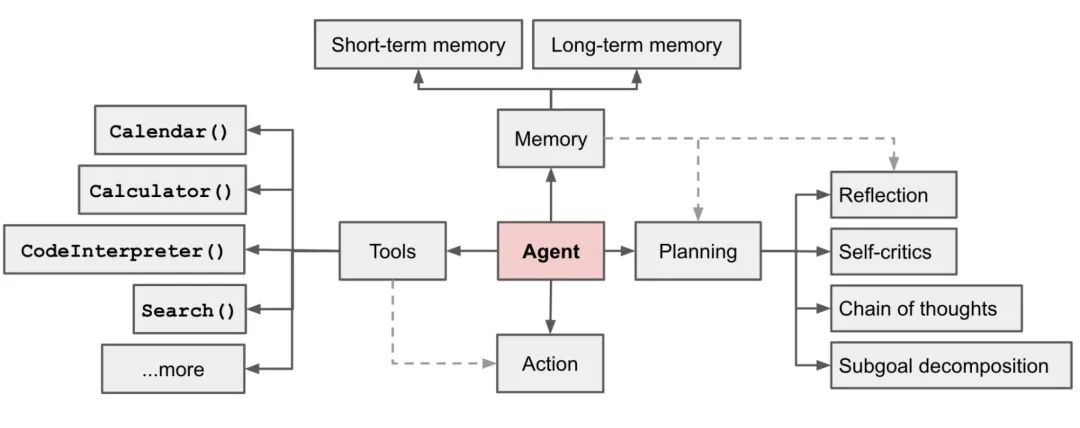
From Lilian Weng’s LLM Powered Autonomous Agents
3.2.1 规划
复杂任务通常需要多步完成,LLM 驱动的智能体会先把大任务分解成若干子任务。比如通过“思维链”(Chain of Thought,简称 CoT)技术,模型被引导“逐步思考”,将难题分解为多个简单步骤。这种方法不仅让任务处理更加高效,还帮助我们理解模型的思考过程。
而“思维树”(Tree of Thoughts,简称 ToT)则是在每一步生成多个可能的想法,构建出一个树状结构。通过广度优先或深度优先搜索,模型能够探索更多可能的推理路径,最后选择最佳方案。
3.2.2 记忆
LLM 的“短期记忆”功能类似于上下文学习,能在当前对话中学习并适应用户的需求。但仅依靠短期记忆有时是不够的,尤其在复杂的长期任务中。因此,智能体还会利用外部向量存储来作为“长期记忆”,帮助它记住更多信息,并且随时能快速检索这些内容。
长期记忆可以理解为 AI 系统的“备忘录”或数据库,保存了历史交互和重要信息。比如,一个智能助手可以记住你几天前讨论过的项目细节,之后你再问起时,它能快速调取这些信息,而不需要你重复所有内容。这就像我们记住过去的经验,而不一定记得每个对话的细节。对于 ChatGPT 类产品来说,长期记忆帮助它在多个交互中保持一致性,提升用户体验。
3.2.3 工具使用
LLM 本身的知识是固定的,无法实时更新。所以,智能体会使用各种外部工具来补充其能力,比如通过 API 获取最新数据、调用代码执行功能,甚至访问一些专有的信息源。这种工具使用能力极大拓展了 LLM 智能体的应用范围。
4. 当前 Agent 系统的挑战
4.1 缺乏理论指导
当前 Agent 的设计可以说是百花齐放,思路各异。在规划、记忆、工具上都有大量的选型组合。Multi-agent 更是各种各样(模拟公司、模拟医院等)。但这些 Agent 既缺乏系统性的评估,也缺乏长远的路线性的方向,大多数不具有很强的延续性。更多是随机的试错。
4.2 缺乏复杂的思考能力
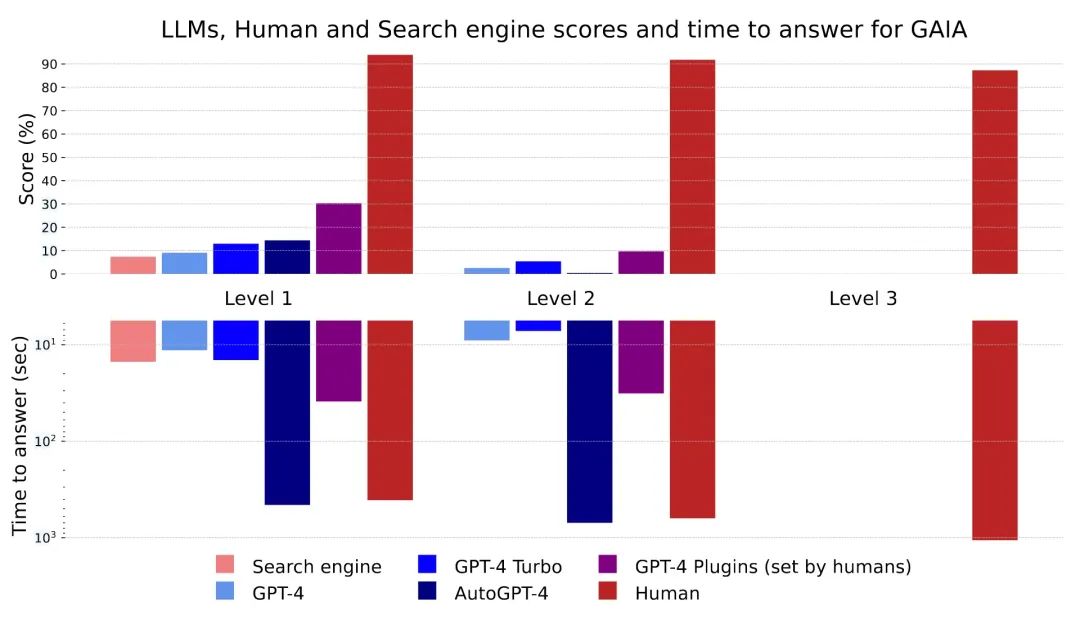
GAIA Benchmark(https://arxiv.org/abs/2311.12983) 是由 Meta Yann LeCun 等人和 HuggingFace 一起提出的一个面向通用 AI 助手的评测基准。旨在评估 AI 在处理实际问题时的能力。该基准包含 466 个精心设计的问题,涵盖多模态处理、工具使用、推理等核心能力。GAIA 的设计理念是让问题对人类来说相对简单,但对当前的先进 AI 系统(如 GPT-4)却具有挑战性。人类平均能在 GAIA 上获得 92% 的成功率,而 GPT-4 配备插件后仅为 15%,这展示了 AI 系统在面对现实世界任务时的不足。GAIA 通过真实用例和不可记忆的答案,避免了传统基准的诸多缺陷。
一个例题:根据维基百科,2021年有多少亚洲国家仍然保持君主制并且有出海口?
下图中是不同系统在 GAIA Benchmark 上的表现。图中 Level 1、Level 2、Level 3 依次是更难的、更复杂的、更需要时间的问题。随着级别的提升,无论是搜索引擎、GPT-4(有无 Plugin)、AutoGPT 都出现了显著的表现下降,但是人类一直很稳定。这其中的主要原因有两点:
- 任务复杂性与步骤依赖:GAIA 设计的问题往往要求执行多步骤操作、跨多种工具完成推理。尽管这些任务对人类来说概念简单,但对 AI 系统尤其具有挑战性,GPT-4 在处理这些多步骤、需要跨模态和工具使用的任务时,往往表现不佳。例如,人类在 GAIA 上表现优秀的一个原因是他们能够轻松地执行多个操作步骤并动态调整策略,而 GPT-4 由于 Planning 能力和记忆局限,在复杂任务中容易失败 。
- 推理能力与调整能力的差异:人类在完成 GAIA 的问题时,能够轻松回溯和调整推理路径,而 GPT-4 的推理过程较为僵化,难以根据任务的需求进行动态调整。例如,GPT-4 的推理链条一旦出错,通常难以自我纠正,而人类则可以基于常识和上下文灵活修正错误 。
4.3 Multi-agent 设计过于复杂
从软件工程角度去看 multi-agent 的话,复杂度的管理显然失控了。各种副作用的传导,耦合的组件让 multi-agent 的开发变得越来越难。并且目前还没有看到由 multi-agent 带来显著的群体智能。
Multi-agent 是否只是某种复杂化的 self consistency 也是一个待验证的问题。
Self-Consistency Improves Chain of Thought Reasoning in Language Models
https://arxiv.org/abs/2203.11171
这篇文章提出了“Self-Consistency”方法,用于改进语言模型的链式推理性能。通过生成多样化的推理路径并汇总一致答案,该方法显著提升了算术和常识推理任务的准确率(提升幅度最高可达17.9%)。自一致性无需额外训练或监督,适用于不同规模的语言模型,是一种简洁有效的推理增强策略。
5. 寻找理论基础
1956 年秋, 在 MIT 信息理论特别兴趣小组上,出现了三个工作:
1)Allen Newell 和 Herbert A. Simon 的 《The logic theory machine–A complex information processing system》
2)Noam Chomsky 的 《Three models for the description of language》
3)George Miller 的 《The Magical Number Seven, Plus or Minus Two: Some Limits on our Capacity for Processing Information》
这次会议是”认知革命“的开始,它激发了符号人工智能、生成语言学、认知科学、认知心理学、认知神经科学等子领域的创建。
当我们说要构建“人工智能”时,这里的“智能”是指和人类对齐的“智能”(更细节的内容放在了 7.1.2 节)。那当我们希望在无限的 Agent 设计方法上寻找一个理论指引的方向时:
我们需要用认知科学领域的理论作启发
Agent 架构的搜索需要一些启发函数,而我们的目标是和人类的“智能”对齐。因此,认知科学的理论是最显而易见的启发函数。并且看起来 Sibyl 在这条路上做出了点成绩 (GAIA 第一)。
下面,我们先简单回顾下两个经典的认知理论,Dual Process Theory 和 Global Workspace Theory。Sibyl 之所以选择这两个理论作为起手,不仅仅是因为它们的认可度,也因为其中看到了和 LLM 之间微妙的联系。
Yoshua Bengio 在类似的技术路线上有很深的思考,有兴趣的可以关注他在 Mila 的工作。
Yoshua Bengio 在类似的技术路线上有很深的思考,有兴趣的可以关注他在 Mila 的工作。
推荐这两篇论文起手:
Inductive Biases for Deep Learning of Higher-Level Cognition
https://arxiv.org/abs/2011.15091
这篇文章提出,通过引入高层次的认知归纳偏置,深度学习可以更好地实现分布外泛化和系统化泛化。文章强调当前深度学习系统缺乏人类在处理新任务和变化环境时的灵活性和鲁棒性。作者建议引入与人类系统1(无意识处理)和系统2(有意识推理)相关的归纳偏置,并通过因果推理和知识模块化来提升AI的泛化能力。这将帮助AI系统更接近人类智能,超越仅依赖数据驱动的学习模式。
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
http://arxiv.org/abs/2308.08708[1]
这篇报告通过神经科学理论评估AI是否可能具备意识,认为现有AI系统没有意识,但未来可能具备。报告基于计算功能主义假设,提出“意识指示属性”作为评估标准,建议进一步研究其技术可行性及潜在的伦理和社会影响。
5.1 Dual Process Theory
双过程理论,常被简称 System 2。
双过程理论尝试解释思维是如何以两种不同的方式产生的,或者是由两种不同的过程导致的。这两种过程被称为 System 1 和 System 2。
虽然后来 Evans 和 Stanovich 在《Dual-Process Theories of Higher Cognition: Advancing the Debate》中讲两者的名称调整为 Type 1 和 Type 2,以更准确的描述这个理论。但 System 2 这个词已经出圈儿了,连 Dual Process Theory 这个本名都逐渐被遗忘。所以,我们还是用 System 1 和 System 2 这两个符号化的名词来进行讨论。
System 1 是一种快速的、自动化的、无意识的过程。比如:算 2 + 2 或者在空旷的道路上开车。你不需要费心思,事情就自然而然地发生了。你甚至无法解释你是怎么做的。
System 2 则是一种慢速的、需要注意力的、有意识的过程。比如计算 17 * 24 或者数一下 “strawberry” 这个单词里有多少个字母 “r”。这种思考过程需要你停下来仔细的思考,并且你可以向第三方报告你的思考过程。
5.2 Global Workspace Theory(GWT)
全局工作空间理论(GWT)是另一个认知模型。
GWT 使用剧院隐喻来说明其概念。在这个类比中:
- 舞台 代表了意识,只有有限的信息会被带入觉知范围。
- 聚光灯 象征注意力,它突出特定的信息,使其进入意识。
- 后台 包含了无意识的过程,这些过程为舞台上展示的内容做准备并施加影响,但它们本身并不直接进入意识。
这个隐喻强调,虽然大多数认知过程是并行且无意识进行的,但只有少量的信息在任何时刻可以进入意识。
GWT 的核心思想是,当特定的感官输入或记忆获得足够的注意时,它们会被广播到大脑的不同认知模块。这种广播允许大脑中专门化区域共享信息,从而促进整合的反应和更高层次的认知功能,如决策、问题解决和计划。全球工作空间充当了信息交换的中心枢纽,使得来自不同神经活动的体验得以整合,形成统一的意识体验。
后来,Stanislas Dehaene 又进一步提出了 Global Neural Workspace Theory(GNWT),让 GWT 有了更多的神经解剖学的基础。其中,“神经雪崩”理论深刻揭示了 Global Workspace Theory 和 Dual Process Theory 在人脑中的物理关系。
在LLMs中,存在一个类似的限制:上下文大小。LLMs一次只能“关注”一定量的信息,这由上下文窗口决定。这就是全局工作空间理论与LLMs中的注意力机制产生联系的地方。
无论模型声称有多少上下文大小,O(n^2) 的时间复杂度很难无损的规避。并且即使 GPT-4o 声称支持 128k,实际上到 32k 后就开始有明显的衰减(https://arxiv.org/abs/2404.06654)。这和预训练的方法、位置编码的机制都有关,只能缓解,很难根治。
6. Sibyl 架构设计
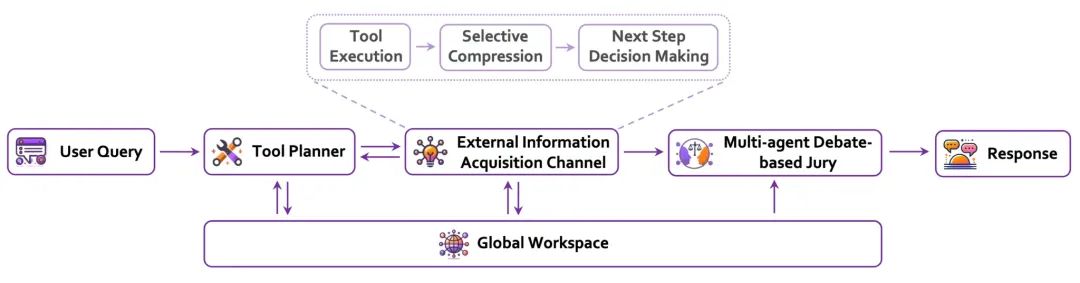
我们先看下 Sibyl 的大致流程,后面的小节我们再拆解一些细节,讨论其和两个认知理论的关系。
一切从用户的提问开始。然后,Tool Planer 会想办法找出最合适的工具和策略来解决问题。接着,外部信息获取通道就像帮你翻资料,它会搜集并筛选出相关的信息,只留最重要的部分,供后面的推理步骤使用。
框架的核心是 Global Workspace,这个部分就像一个大家都能访问的“共享记忆”,不同的模块可以通过它协同工作,保证推理过程中的上下文信息不会丢。
接下来有一个多代理辩论评审团,里面的专门代理人会进行辩论、讨论,把答案打磨得更完美。这个环节能确保答案的多样性和可靠性,兼顾不同的观点。
最后,经过这些步骤,Sibyl 会生成一个既准确又可靠的答案,特别适合处理复杂的、长程的推理问题。
简单的过了一下流程,我们需要深入看下两个和认知理论相关的核心设计理念:System 2 First 和 Selective Compression in Global Workspace。
6.1 System 2 First
Sibyl 在设计的时候采取了称为 System 2 First 的理念。
这里有两个角度去理解这个理念:性能导向和可递归的推理空间
6.1.1 性能导向(推理资源换智能)
我们采取的是 以性能为导向的方式。我们不追求速度很快的响应速度,而是把重点放在提升准确性和深度的推理上,即使这会花费更多的时间和资源。为了实现这一点,v0.2 这个版本里,每个模块中都默认启用了类似“思维链”(CoT)的推理方法。(实际上是基于 Langchain 的结构化输出实现的,最近 OpenAI 也在文档中推荐用类似的方式实现,希望他们是抄我的)
无论是“思维链”还是“思维树”,这些都属于推理策略,这些策略未来可能会被替换成效果更好(但可能更贵)的实现。比如这篇文章的思路:https://arxiv.org/abs/2408.03314。
这种不顾成本,只求效果的思路我们称为:System 2 First。
同时,由于显存墙的存在,在参数量上的提升已经遇到瓶颈,但推理时间我们并没有硬件上的瓶颈。
6.1.2 可递归的推理空间
我们再看看另一个角度。
这里的核心理念是尽可能的在语言空间中的推理,而不是在残差流(residual stream)中进行推理。
想了解 residual stream 数学细节的看这里:https://transformer-circuits.pub/2021/framework/index.html
残差流是 Anthropic 在一系列机械可解释性(mechanistic interpretability)工作中提出和使用的概念。
简单来说,残差流充当了模型内部信息流的的总线。transformer 模型每一层的输出,都会被添加到下一层的输入中。这种“加操作”允许模型在引入新的变换的同时,保留来自前几层的信息。残差流的重要性在于它对信息流的维护,这对于模型在自然语言处理等任务中的表现至关重要。
由于每一层都在逐步操作这个信息总线,其内部维护了某种类似逐步推理的过程,但推理的步数被锁定为总层数。
下图来自 lesswrong 上 4 年前的一篇经典文章,可视化了 GPT-2 是如何一步一步完善对 token 的预测的:

图中,X轴是输入给模型的一段文字(tokens),Y 轴向上是沿着 transformer 层的方向被逐渐改进的对下一个 token 的预测。(每个 token 都有对应的下一个 token)
Logit lens 原始文章:
https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
后续工作:https://arxiv.org/abs/2303.08112
这个可视化工作非常 cool,我们会立刻发现一个问题:虽然 LLM 可以在残差流中进行推理,但这种推理能力严重被层数和有限的电路(circuit) 结构限制。
预训练好的模型的单次 forward 的算力消耗(能源消耗)是个常量,无法根据问题的复杂度进行调整。
但通过将推理扩展到语言空间,我们可以获得一个类似递归的结构,计算量可以根据任务的难度进行扩展。
这里有一个比较细节的点是:什么级别的推理步骤需要展开到语言空间?什么级别的不需要?
这其实和预训练模型本身的能力有关。如果一个推理步骤跨度过大,模型无法在其内部完成推理,强行让模型直接记住事实的话,那就会导致模型知其然而不知其所以然,损失了泛化性。
这里会有一个未经实验验证的假设(也许有人做了我还没看到):模型越大,单次 forward 能够推理的距离越远。
但这个距离我们并没有很好的度量方法。(同时我们也不知道何时单次 forward 的推理距离会大到人类不可理解的程度😨)
既然我们不知道如何度量“推理距离”,也不知道最好的闭源模型的尺寸,我们唯一能做的就是尽可能的将推理步骤展开到语言空间里,来提高各个模块的准确率,即:System 2 First。
当然,如果可以对模型进行训练,就可以更好的适配模型的单步推理能力。
The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”
https://arxiv.org/abs/2309.12288
这篇论文揭示了自回归大语言模型(LLMs)在处理“反转关系”上的一个普遍问题:如果模型在训练中学到“A 是 B”,它并不会自动学会“B 是 A”,这被称为“反转诅咒”。例如,模型能够回答“瓦莲京娜·捷列什科娃是第一位进入太空的女性”,但无法回答“谁是第一位进入太空的女性”。
然而,值得注意的是,如果“A 是 B”在上下文中出现,模型能够推导出反向关系。这意味着推理有可能只能在语言空间中进行。
6.2 Selective Compression in Global Workspace

System-2 First 是一个不错的起点,但我们很快就会遇到瓶颈:人没有无限大的脑容量,模型也没有无限大的 Context。
6.2.1 信息的压缩
Sibyl 的架构中会涉及到多个组件,每个组件都需要获取尽可能多的信息来完成任务。可是 LLM 的 Context 是有限的。由于我们必须在一个有限的空间中解决不同难度的问题,这意味着我们必须有一套机制管理好这有限的空间。
比如,工具返回的结果(Tool Result) 可能有约 5000 tokens,这里会有大量和任务无关的细节信息。我们通过一个压缩抽取模块,将其整理成约 300 tokens 的“笔记”(Step Note),然后放入 Global Workspace 里。这样 10k tokens 就可以容纳约 30步的工具内容。
Sibyl 的平均压缩比大约为 16 倍。在需要查询互联网数据的场景中,压缩比通常会更高。因为网页里往往有大量和任务无关的信息。Global Workspace 里的信息会被每一个模块使用:工具选择器(Tool Planner)、外部信息抽取器(External Information Acquisition Channel)、陪审团(Jury)。
6.2.2 LLM Native 的推理
相比于树结构的推理 (如 MCTS),这相当于将推理过程线性展开到 Global workspace 中。
在每一步推理时,LLM 能看到之前所有的历史,包含错误的尝试。这样的好处是整个系统能更好的融合推理历史和 pretrain 获得的先验来进行下一步的决策。当然也有一些麻烦的地方,我们没法使用像 UCB(Upper Confidence Bound) 或 PUCT(Predictor UCT) 这样好用的工具来处理这个问题,灵活的在“探索”和“利用”间权衡。
Sibyl 目前只有对 Global Workspace 的追加操作,未来希望能够引入“删”,“改”操作,来支持更长程的任务。
6.3 评估
我们在 GAIA 榜单上进行了一次提交,结果如下表所示。
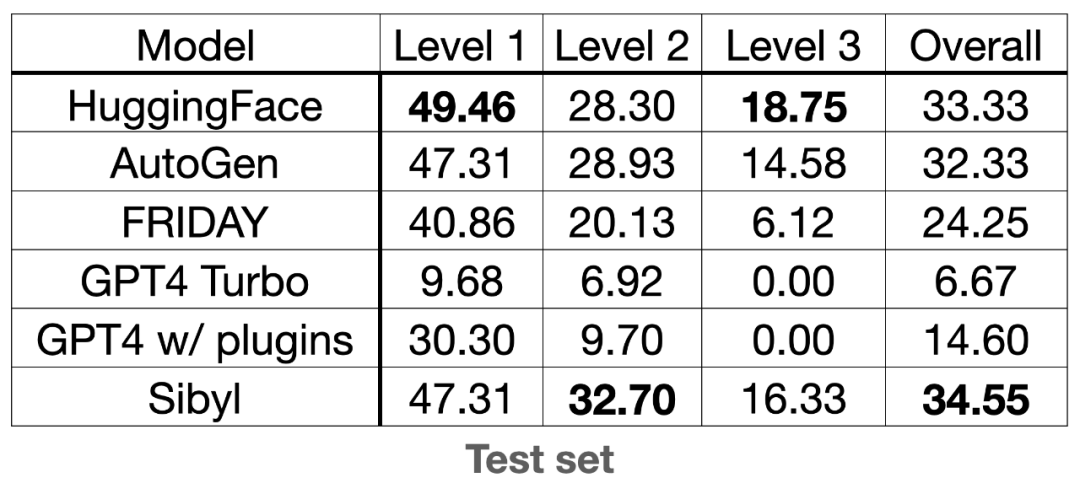
GAIA 这个数据集会从多个角度来评估一个系统的能力,Level 1、Level 2 和 Level 3 的难度依次递增,任务的步骤越来越多。每个题目会考察下面能力列表中的一个或多个:
- 跨越多个信息源的信息收集和整理
- 音频、图片或视频信息理解
- PDF、Word、Excel、Powerpoint 等文件内容的理解
- 数学计算和逻辑推理
- 多步长程的推理能力
从这个评估结果我们可以看到:
- 单纯的使用 GPT4 Turbo 只有 6.67 分(满分 100 分)
- GPT4 配合插件分数会上涨到 14.60 分
- Sibyl 能做到 34.55 分,比带插件的 GPT-4 分数要高一倍多
这个评估提供了基于认知理论指导 Agent 设计的可行性的证据,提高了我们在这个方向继续前进的信息。
7. 未来的方向
7.1 评估
评估指标指引了系统迭代的方向。我们首先选择了 GAIA Benchmark,其满足了我们在指标上选择的两个需求:
更具通用性,接近我们对这类工具需求的定义
在其榜单上,人类和 AI 的差距更大,这意味着它能帮助我们找到现有 AI 系统的不足之处
但单一指标是不够的,目前在计划中的还有两个方向的指标:code 和 g factor。
7.1.1 Code
SWE-Bench 是一个经过考验的指标,也满足上面提到的两个需求。从解代码 bug 开始,到未来能写新 feature 也许是一个不错的方向。也许它不是一个 AGI 的好指标,但是一个有用的指标。能在 SWE-Bench 获得好成绩意味着我们起码获得了一个不错的工具。
7.1.2 g factor
g factor 是一个心理测量学概念。其被定义为一种统计构造,用于解释不同认知能力测试(cognitive ability tests)之间观察到的正相关性。它基本上表明,在某一认知领域表现出色的个体,例如在语言推理方面,通常也会在其他领域表现良好,例如数学推理或空间推理。这一现象通常用“智力是广义的”来概括,表明在多样的智力任务背后存在一个共享的认知能力。
Artificial Intelligence (AI) 这个词已经成为了一个符号,但这个符号的所指却依旧模糊。好像大家都知道 Intelligence 是什么,又好像不知道 Intelligence 具体是什么。为了避免无限能指的困境,我们需要一个从第一性原理出发的分析,来回答:“当我们谈论 Intelligence 的时候,我们在谈论什么?“
但这里篇幅所限,无法完全展开(给未来挖个新坑),我们只做简单的讨论,帮读者建立简单的直觉性的理解。
讨论一:下棋
1997年 DeepBlue 击败加里·卡斯帕罗夫,2016-2017年 AlphaGo 击败李世石和柯洁。这两个 AI 两次让人们以为在智力上机器已经战胜了人类。
国际象棋或者围棋的世界冠军,有着超出普通人的推理、搜索和记忆能力。人们以为在棋类上战胜了人类就意味着找到了构建 Artificial Intelligence 的方法。但事后来看,棋类 AI 并没有教会我们太多东西,棋类 AI 用了一种与人类完全不同的方式解决了下棋,但它们除了下棋什么都不会。
我们通常会说 AlphaGo 是一种 “推土机式智能”。
构建棋类 AI 的动机其实有一个逻辑上的问题:聪明的人能够下好棋和下好棋就意味着很聪明并不是一回事。拥有能下好棋这个“技能”只是拥有 Intelligence 的必要不充分条件。
讨论二:保温杯
原始版本:https://www.lesswrong.com/posts/6smshoLzm7qrgsrb8/the-teacup-test
前文关于 Agent 的传统定义部分,我们引用了这么一个定义:
理性智能体(rational agent)需要为取得最佳结果或者存在不确定性时取得最佳期望结果而采取行动
从这个角度来看,一块石头是不智能的,因为它什么都做不了。
😆 但我的保温杯是智能的:
- 夏天的时候,它能让我的冰美式一直冰爽
- 冬天的时候,它能让我的热拿铁一直温暖
- 它使用 “环境温度和饮料温度的差值的绝对值” 作为 value function
- 它能够根据我的需求以及环境的变化一直选择正确而理性的行为😂

讨论三:广义智力
上面两个讨论可能会让你明白定义 ”intelligence” 这个概念有多困难。
如果我们连 AI 的本身的含义都难以定义,又如何定义评价体系?没有评价体系我们又该走向何处?
马毅老师在这个 Podcast 里也有一些非常有趣的观点:https://podcast.latepost.com/71
这里我们尝试用一个类比来解决这个问题:当一个人跑步成绩很好的时候(比如刘翔),通常跳远也不差。这种情况下我们会说这个人的”身体素质“非常好。“身体素质”非常好这个也意味着这个人只要稍加学习游泳成绩也会好于普通人。这种“身体素质(类似 g factor, 我们称其为 p factor)”类比其实可以帮助我们更好地理解智能的广泛性问题。
正如身体素质好的人在多种体育项目上表现出色一样,我们通常认为智力高的人也能在多种认知任务上取得不错的成绩。比如,一个在语言能力上表现优异的人,通常也会在数学推理等其他认知领域有所表现。这种现象背后反映的就是我们前面提到的 g factor,也就是一种“广义的智力”。
讨论四:火星 (no free lunch)
No Free Lunch 定理告诉我们,任何两个优化算法(包括人类智能)在其性能对所有可能问题取平均时是等效的。也就是说,算法应该针对目标问题进行调整,以实现优于随机表现的效果。
就像身体素质再好的人,也不意味着他能够适应所有的环境——例如:刘翔无法在火星上奔跑;同样的道理,智力再高的人,也不一定能够应对所有类型的任务。人类的智力和身体能力一样,都是在特定的环境下进化而来的。它们在某些方面表现优异,但在其他方面可能表现平平,甚至完全不适应。
因此,AI 系统的评估也往往隐含着“人类中心主义 (Anthropocentrism) ”的的倾向。这也是为什么在构建 Sibyl 时,我们优先选择和人类表现差异较大的榜单。
Anthropocentrism 这个单词有没有觉得眼熟?Claude 背后的公司叫 Anthropic。
讨论五:晶体智能(Crystallized Intelligence)和流体智能(Fluid Intelligence)
晶体智能指的是一个人通过经验和学习所积累的知识、技能和信息。这种类型的智能是相对稳定的,它依赖于过去的知识和经验,因此随着年龄的增长,晶体智能通常会逐渐增强。比如,一个人在学习语言、背诵历史事件、掌握数学公式等方面表现出的能力,通常与 ta 的晶体智能有关。换句话说,晶体智能更多地与知识库和记忆力相关。
流体智能则不同,它更多体现了一个人在陌生环境中解决新问题的能力。这种智能与逻辑推理、问题解决、模式识别等高度相关。流体智能不依赖于过去的知识储备,而是通过灵活运用大脑资源来处理新信息,因此流体智能往往在年轻时更为活跃,随着年龄的增长可能会逐渐下降。
中学历史考试和 MMLU 这样的测试就是典型的晶体智能测试,只考察知识性内容,换句话说就是死记硬背的能力。
而一些给人做的智力测验和 ARC (Abstraction and Reasoning Corpus) 这样的测试就是流体智能测试,考察解决新问题的能力。
当然两者并不是割裂和对立的,像 GAIA 和 SWE-Bench 这样的评测两者都考察,只是两者的权重很难分析。因此在 GAIA 或 SWE-Bench 上表现优异有可能大量依赖晶体智能:仅依赖少量特定的知识即可做的很好。
经过上面的讨论,我们可以看到 AI 的评估方面应该兼顾技能性的考察和技能获取能力的考察。但现在大多数的评测只关心技能性的考察(MMLU,GSM8K)。因此一些模型预训练和对齐阶段没见过的技能是我们着重需要关心的。可以说是这是某种泛化性的评估。
这里说的泛化型依然是在人类中心主义视角下的:
我们不会只关心“AI 能够解多少道复杂的数学题“,也不会考察” AI 能否背诵 Wikipedia 全文“,但我们会考察“AI 是否能够快速掌握新的知识和技能”,因为这种 “g factor” 会和一系列智力能力有正相关性。
7.2 推理能力
这里加上这么一节,本质上是在构建 Sibyl 的过程中,对现有 LLM 推理能力的不满意。很多错误是由于 LLM 缺乏一些缺乏 Common Sense 的决策导致的。如果能够提高模型的推理能力,Sibyl 所有模块的效果都会有所提升。比如引入更多的 reasoning 方法:x of thoughts, self-consistency…
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters: http://arxiv.org/abs/2408.03314
这篇文章提出了一种动态调整推理时间计算资源分配的“计算优化”策略,证明在许多任务上,相比于直接扩大模型规模,通过合理分配推理阶段的计算资源能更高效地提升性能,特别是在有限计算资源下更为突出。此发现对未来大语言模型的开发和部署具有重要意义,表明可以通过推理时间的计算扩展来降低模型的预训练成本,同时提升模型的应用表现。
此外,最近半年也有很多通过在模型推理阶段使用额外的计算资源来提升模型的表现的工作。这也和 System 2 First 的思路一致。
(还没写完 o1-preview 就发布了😂)
7.3 Agency (能动性)
现有的 ChatGPT 类产品都是被动的,用户问一句,它答一句。如果用户不问,GPU 就闲置,系统也随之停下来。这种设计虽然符合大部分现有应用的需求,但它完全依赖用户的输入,无法主动行动。
像 Sibyl 和 AutoGPT 这样的 autonomous agents,在一定程度上可以根据一个预设目标反复拆解并执行子任务,具有一定的自主性。但即便如此,它们的任务仍然是短期的,且由用户的输入决定。
Nvidia 的 Voyager 向我们展示了一种简单目标如何带来复杂行为的例子,尤其是在 Minecraft 这个游戏世界中。然而,Minecraft 毕竟只是一个虚拟环境,和现实世界有着本质的不同。
Voyager: An Open-Ended Embodied Agent with Large Language Models: https://arxiv.org/abs/2305.16291
这篇文章提出了一种智能体,利用GPT-4在Minecraft中自主探索、学习技能,并通过自动课程、技能库和迭代提示机制不断优化表现。VOYAGER在终身学习和任务解决上表现出色,远超现有技术,并为开发通用自我改进智能体提供了新方向。
一个设想是,未来的 Sibyl 能够 24×7 持续运行,用户的问答需求只是它的高优先级任务之一。与此同时,它自身会有一个长远的目标驱动它一直运转(比如:完善对世界的理解,降低看到新信息的 surprise),不依赖用户输入来决定它的行为。换句话说,Sibyl 将像一个生活在文本世界中的“缸中之脑”,自我驱动,不断演化。
8. 总结
笔者在 6 月完成了 Sibyl 的相关实验。三个月之后的 9 月, OpenAI 发布的 o1-preview 也采用了类似 System-2 first 思路,其利用 RL + CoT 将相关领域的分数提到了新的高度,也让 System-2 成为了热门词汇。
而 System-2 只是 Dual Process Theory 的一部分,Dual Process Theory 又只是认知理论的冰山一角,与人类“智能”对齐还有很多工作要做。
本文基于认知理论,探索了 AI 架构设计的新方向。在回顾现有 Agent 系统的基础上,我们提出了一种通过认知科学理论来指导 AI 架构设计的思路,重点讨论了 Dual Process Theory 和 Global Workspace Theory 在 AI 系统中的应用。这不仅是一项技术上的改进,更是一种理念上的尝试——重新审视 AI 系统与人类智能之间的关联。
通过实验验证,我们发现,System-2 优先的推理模式和 Global Workspace 中的选择性压缩机制,显著提升了系统在复杂长程任务中的表现。虽然这些系统在速度和成本方面有所牺牲,但在开放的场景中达到了更高的表现水平。这表明,未来 AI 系统的关键在于如何赋予其类人思维的多层次推理能力,以应对复杂问题。
在这一探索过程中,“人类中心主义 (Anthropocentrism)”的 AI 观念逐渐显现。我们既不能仅凭少数性能指标来衡量 AI 的优劣,也不应期望 AI 系统在所有任务中表现完美。我们应关注 AI 在多个维度上如何与人类智能对齐——从技能获取的速度、泛化的广度到思维方式的相似性。
在这一观念下重新审视现有的“大规模语言模型技术栈”,你会发现无限的机会,这里以几个问题结尾:
- AGI 的目标是什么?
- 为了实现这个目标,我们要引入什么样的 bias?
- 实现这些 bias 要用什么样的方法?
- Test-time scaling law 是什么?(OpenAI 的 o1 发布后更多人关注这个问题了)
- Training-time scaling law 是否需要重新修正?
- 训练用的 Token 真的不够用了么?
感谢冠叔、Kiwi、熊总、思彤、田浩对本文的贡献和帮助。
欢迎和本文作者交流讨论:微信 KingUniverseDragon
原文链接(欢迎在原文 Comments 讨论):https://www.wangyulong.io/AI-17fada57edb946468a38dc71322a449f?pvs=4
本文由人人都是产品经理作者【【OneMoreAI】,微信公众号:【OneMoreAI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


