
 起点课堂会员权益
起点课堂会员权益DeepSeek拿捏了人情味
与依赖强大算力的传统大模型不同,DeepSeek通过系统化的创新,以极低的训练成本实现了高效且人性化的输出。本文将通过一系列实际对话案例,展示DeepSeek在文本处理、文化分析、情感共鸣等方面的出色表现,并探讨其背后的技术逻辑和对行业的影响。

2025年:DeepSeek彻底火了。
01
这谁能想到?
人工智能行业,在2024年经历短暂的混沌之后,热度被DeepSeek再次搅起来,这次终于轮到国内的AI企业扛热搜了。
此前爆火的ChatGPT和Sora,都是出自OpenAI。
关注AI赛道的都清楚,OpenAI作为这个行业的领头羊,在资金算力和人才等各个方面,都拥有绝对的领先优势,而普遍的共识:大模型训练要先储备好大量的算力。
直到DeepSeek被架上热搜,这个共识才出现了动摇。
DeepSeek模型以极低的训练成本,以及系统化的创新思路,成功证明了一个问题:不强依赖算力,以技术和算法层面的系统性创新,也可以训练出好用的大模型。
AI赛道的公司苦算力久已,更别提是国内的企业了。
去年国内多家AI公司,频频被爆出在大模型训练上萌生了退意,转而走AI应用和商业化探索的战略方向。
甚至有声音称:AI公司都训练自己的大模型,是一种资源浪费。
随着DeepSeek的爆火,关于2023年5月采访幻方创始人梁文锋的那篇文章,也跟着刷遍了朋友圈,梁文锋表达了创建深度求索这家公司,并且专注探索大模型的初心。
采访中展现出迷一样的淡定和自信,就是专注于大模型方向的研究。
深度求索背靠幻方这家量化公司,在资金和算力方面有很大的优势,但是具备这些优势的公司,在国内可不只有这一家,然而推出的多款大模型各有优劣,都算不上真正的出圈。
股民更是调侃到:幻方拔的韭菜都成了AI的养料。
市面上多款大模型都经常使用,各家的模型也都有相对擅长的领域,就从此前个人的体验情况来看,国内的主流模型和ChatGPT还是存在一定的差距。
国内几款主流模型的“技术味”很冲,不论是文本还是绘图领域,但是这种味道在ChatGPT模型上淡化了很多。
然而在DeepSeek模型里,能神奇的体会到“人情味”了。
02
这里不过度吹捧DeepSeek,也不带着此前对大模型的刻板印象,相同的问题都在多款大模型中提出。
经过对比之后,个人客观的评价DeepSeek确实更胜一筹。
对于一款产品来说,好不好用以及背后研发团队是否用心,体验过后自然心里有数,下面分享几个和DeepSeek对话的问题以及答案。
A:请你用谦逊且自豪的表达风格,从创始人,算力,和人才团队三方面,简明扼要的分析你自己爆火的原因。

整个回答的内容透着人情味和高级感,尤其是创始人初心这一段,再结合23年的那篇采访,真的是相得益彰。同样的问题抛给不同的产品,哪一款模型更符合使用习惯就了然于心了。
B:你如何看待哪吒系列电影的爆火,并到达国内票房榜首?

回答中涉及关键的文化创新,和呕心沥血的工业制作,还顺带分析了IP经济的市场运营,以及下沉市场的消费爆发,这其中又多少带了点“量化”的味道。
C:哪吒系列电影对申公豹角色的精彩刻画,衍生一个“申公豹文学”的说法,请你用调侃的口吻,简单分析申公豹和普通打工人的理想和困境。

哪吒两部影片中的角色刻画都非常成功,但是最能引起打工人共鸣的就是申公豹。
年少轻狂时觉得「我命由我不由天」,踏入社会几年后发现只是个「小镇做题家」,忙忙碌碌许多年不过就是为了「碎银几两」,这大概就是成长的过程和代价。
生活没必要强行赋予意义,经历过精彩过就过去了。
D:从本质和趋势上进行简明扼要的分析一个问题:黑神话悟空,DeepSeek模型,哪吒系列电影,这三款产品能出圈火爆全球的原因。
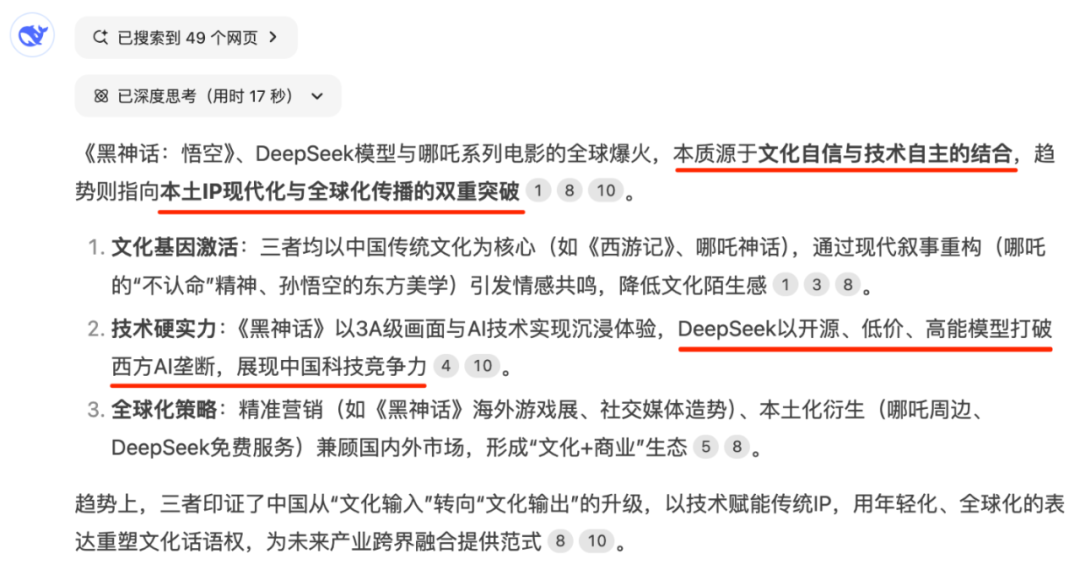
对于这个问题的回答,其它几款模型更多是逐个分析,只有DeepSeek采用的是横向总结的方式,更加符合提问者和问题自身所想要的答案。
比较几款模型的答案,实际上差异并不大,但是DeepSeek对于内容关键标签的采集和组合更加高级且流畅。
E:春节作为民族传统节日,近年却成了年轻人最怕的假期,因为要面对催婚催生的问题,请你用相对轻松的语气就催婚问题,分别和长辈、年轻人聊一聊。

就催婚这件事来说,由于两辈人经历的时代和大环境不同,所以对婚姻的态度也不一样,甚至很多时候会造成对立的场面,但是双方都无法用对错来界定,只能是理解万岁了。
不过有一说一,对于流浪在外的打工人来说,糊弄模式应付催婚的确是最合适的手段。
F:春节后开工综合征一直困扰着打工人,但是随着DeepSeek爆火,网络上出现了DeepSeek赚钱指南的培训课,请你结合自身分析一下,你能在打工人的路上提供哪些帮助?

这个提示词故意写的有点含糊,也是想看看DeepSeek对于问题本身是否具备精准的分析能力,作为提问者个人希望看到三个维度的回答:AI培训课的现象,AI为职场提升效率,AI缓解开工综合征。
DeepSeek的回答,基本符合自己的预期方向。
G:对于漂泊在外的打工人来说,春节前后的奔波和忙碌,面对催婚的两难抉择,请你用一句话,宽慰身心俱疲的打工人。

这个文案水平真的是吐槽不了一点,感性之中藏着理性,既有高级感又充满人情味。
此前在大模型使用的过程中,个人更喜欢ChatGPT这一款,其综合能力和内容输出都符合自己的喜好,在DeepSeek出圈的前期也并没有太多关注,感觉一时半会也很难有模型能追赶ChatGPT的能力。
这真是应了那句:人心中的成见是一座大山。
春节后只试用DeepSeek两天,就被这款模型的能力惊艳到了,除了内容问答这块,其它方面的实践也很多,比如做设计写程序,分析互联网事件和趋势等。
就文本处理这块来说,效果不说超越ChatGPT,但差距已经微乎其微了。
03
在个人的理解上,要做成AGI通用人工智能,最先要解决的就是语言层面的问题,尤其是中文这类内涵丰富的语言。
可用和好用的模型,创新和付出绝对不是一个量级。
这里不得不再提一句关于梁文锋的那篇采访:淡定的表达了,对于大模型底层和基础研究的坚定态度。
建议和DeepSeek一样,具备资金和算力优势的公司,出来对个线反思一下问题在哪。
DeepSeek并不像多数AI企业那样,自下而上的综合战略,既追求大模型的训练成果,又探索上层应用和商业化的进程,当然这里也无法站在对错的角度来衡量,毕竟大部分公司都差钱且差算力。
生存压力,决定了大部分公司做事的方向和态度。
另外一个比较热门的话题,就是DeepSeek是否会改变算力市场的现状,把DeepSeek和ChatGPT模型都放在好用这个维度来比较,DeepSeek的训练成本远远低于ChatGPT模型。
在数据公司做系统的时候,见识过算力服务器集群建设的高昂成本,想要处理海量的数据规模,必须是算法和算力层面的双重支撑,毫无疑问的是算力越强效率越高。
DeepSeek证明了另一个方向:大模型训练可以不强依赖算力。
所以综合来看的话,只要人工智能还在持续发展,应用层面的产品不断探索迭代,那么对于算力的需求和储备都不会减弱。
然而算力绝对主导的天平,在DeepSeek的冲击下,开始倾斜了,如此对于很多AI赛道的企业来说,也可以去重新审视一下方向了。
没有算力优势,大模型是不是真的就做不好了?
作者:半问 ,公众号:半问
本文由 @半问 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务









DeepSeek确实有点东西,腾空出世时的大模型就出乎意料!同时它的出现,也为国内智能体的发展提供了方向,我国人工只能也向着ChatGPT靠近,这样的探索值得多关注啊!