
 起点课堂会员权益
起点课堂会员权益n8n工作流-自动获取报告内容
本文将为你介绍一种全新的解决方案:利用n8n工作流自动化获取报告内容。作者通过实际操作,展示了如何设计一个稳定且简洁的工作流,自动循环获取指定页面的报告内容,并将其保存下来。

用n8n搞了一个自动获取公开报告的工作流,以后再也不愁找引用资料找不到了,顺便也为后续知识库做个准备。
几番尝试了coze的工作流、agent,以及n8n工作流之后,处理常规重复的任务还是n8n工作流更加稳定,且简洁模块化功能较好操作。
工作流几个核心点:
1. 规划设计好工作流几个核心节点,需要调用的工具和大模型;
2.所调用工具申请APIkey,大模型prompt需含有身份、要求、示例让它工作和思考更稳定。
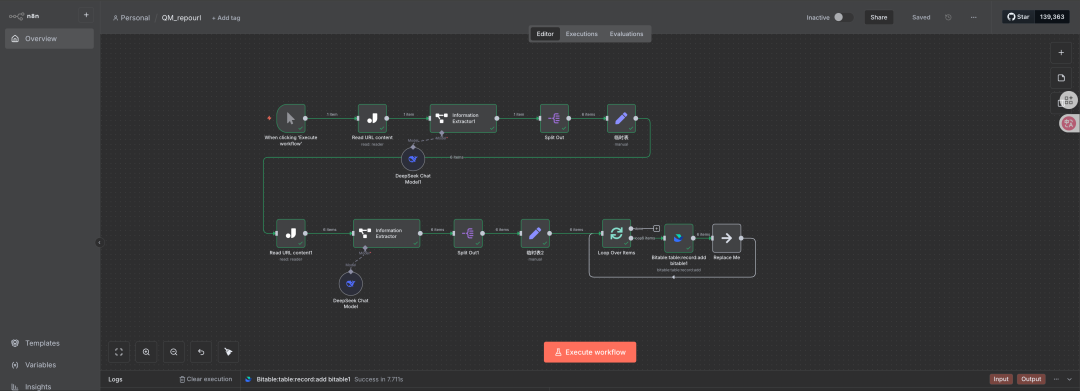
以本次尝试的工作流为例
目标:生成一个自动循环获取指定页面的工具,并把内容均保存下来。
步骤拆解:核心页面->读取页面内内容并储存->读取二级页面内容并解析储存->循环写入文档

prompt示例:
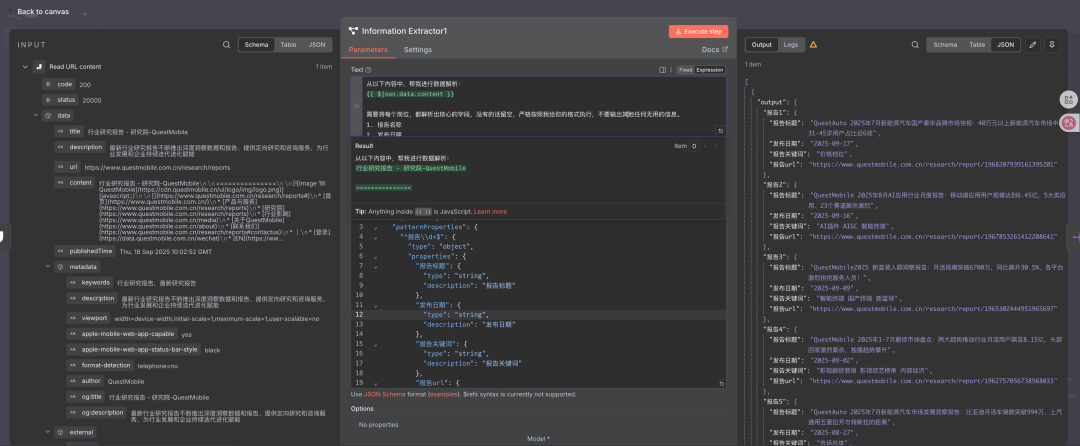
从以下内容中,帮我进行数据解析:
{{ $json.content }}
需要将每个岗位,都解析出核心的字段,没有的话留空,严格按照我给你的格式执行,不要输出其他任何无用的信息。
1. 报告名称
2. 发布日期
3. 报告关键词
4. 报告url
===以下为示例===
{
“报告1″:{
“报告名称”:”QuestMobile 2025年8月AI应用行业月度报告:移动端应用用户规模达到6.45亿,5大类应用、23个赛道厮杀激烈”,
“发布日期”:”2025-09-16″,
“报告关键词”:”AI插件 AIGC 智能终端”,
“报告URL”:”https://www.questmobile.com.cn/research/report/1967853261412208641″
},
“报告2″:{……},
“报告3″:{……}
}
===示例结束===
以上获取报告案例还算简单,后边还有更有趣的事情可以尝试,比如报告内容多为图片,可以解析出图片内文字、数字内容,存为文本文件,后续数据趋势预测就有了依据,同时预测、分类等内容同样也可使用工作流和大模型帮忙实现。到时候就真的解放双手啦~
本文由人人都是产品经理作者【小王子和小企鹅】,微信公众号:【小王子和小企鹅】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


