
 起点课堂会员权益
起点课堂会员权益ACE框架万字深度解析:重塑LLM自我改进的上下文工程范式
随着大模型从“能用”走向“好用”,上下文工程成为提升智能体能力的关键变量。本文围绕ACE框架展开万字深度解析,系统梳理其在Agent自我改进中的结构优势与工程价值,帮助产品人、AI开发者构建更具可控性与演化能力的智能系统。

在大语言模型(LLM)技术从“单点能力突破”走向“系统级应用”的新阶段,如何让LLM在复杂任务中持续优化性能、降低对人工监督的依赖,成为行业面临的核心挑战。
传统的模型微调(Fine-tuning)方法虽能提升特定任务性能,但存在成本高、周期长、跨任务复用性差的局限;而静态提示工程(Prompt Engineering)则因上下文的“一次性”属性,难以支撑LLM的长期自我改进。
在此背景下,上下文适配(Context Adaptation) 作为一种轻量、灵活的优化路径应运而生——它无需修改模型权重,仅通过动态调整输入中的指令、策略与领域知识,即可实现LLM性能的快速提升。
然而,斯坦福大学与SambaNova Systems联合发布的论文《Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models》(以下简称“ACE论文”)指出,现有上下文适配方法普遍面临“简洁性偏见”与“上下文崩溃”两大致命痛点,严重制约了LLM在智能体、金融分析等复杂场景的应用潜力。
ACE(Agentic Context Engineering,智能体上下文工程)框架的提出,正是为了破解这一困境。该框架将上下文重新定义为“动态演进的策略手册(Playbook)”,通过模块化的“生成-反思-整合”流程,让LLM能够像人类专家一样“从实践中学习”——积累有效策略、修正错误模式、优化知识结构,最终实现无需人工标注的自我改进。
本文将基于ACE论文的核心内容,从背景、现存问题、设计理念、使用场景、创新机制、解决的问题、提升效果、潜在挑战到未来方向,全面剖析这一框架的理论价值与实践意义,最后简要提及开源项目对论文理论的工程化落地支撑。
一、LLM上下文适配的兴起与困境:从静态提示到动态需求的矛盾
1.1 上下文适配的核心价值:为何它成为LLM系统优化的关键路径
ACE论文开篇即点明,随着LLM在智能体(Agent)、金融分析、代码生成等领域的深入应用,上下文适配已逐渐取代传统微调,成为构建高效LLM系统的核心手段。与模型权重更新相比,上下文适配具备三大不可替代的优势:
首先是可解释性。上下文以人类可读的自然语言形式存在,开发者能直接追溯LLM的决策依据,避免“黑箱”问题。例如,在金融财报分析任务中,上下文可明确记录“XBRL文档中‘应付账款’需标注为负债类实体,且需排除‘预付账款’干扰”的规则,而非将这一知识隐藏在模型参数中——这对金融、医疗等强合规领域至关重要。
其次是实时性。新领域知识(如API接口更新、政策法规变化)可通过上下文快速注入LLM系统,无需重新训练模型。ACE论文以AppWorld智能体任务为例,当“文件分页API返回格式从列表改为字典”时,仅需在上下文补充这一变化,LLM即可立即适配,而微调模型则需重新准备数据、训练迭代,耗时长达数小时甚至数天。
最后是跨模型复用性。同一套上下文策略可在不同架构的LLM间迁移,例如将“API分页处理需用while True循环”的策略从DeepSeek-V3.1迁移到GPT-4,无需针对不同模型单独优化。论文数据显示,优质的上下文适配可使基础LLM的性能提升15%-20%,而成本仅为微调的1/10(按token消耗计算),这也解释了为何GEPA、Dynamic Cheatsheet(DC)等上下文优化方法近年来成为研究热点。
1.2 现有方法的两大致命痛点:简洁性偏见与上下文崩溃
尽管上下文适配优势显著,但ACE论文通过大量实验证明,现有方法在复杂场景中仍面临难以逾越的障碍,这两大障碍直接导致LLM无法实现持续、稳定的自我改进。
第一个痛点是简洁性偏见(Brevity Bias)——多数上下文优化方法将“简洁性”作为核心目标,认为短提示能降低模型理解成本、提升通用性,但这种思路在领域密集型任务中会导致关键知识的丢失。
ACE论文以GEPA(一种主流的反射式提示进化方法)为例,在金融分析任务FiNER(需标注XBRL文档中的139种实体类型)中,GEPA生成的提示仅包含“正确标注XBRL实体”的通用指令,完全遗漏了“数值型实体需校验单位(如万元/亿元)”“‘商誉减值’需从‘资产减值损失’科目提取”等细分规则。实验结果显示,GEPA在FiNER的准确率仅为76.6%,而后续ACE框架通过保留这些细节,将准确率提升至78.5%。
更严重的是,简洁性偏见会导致“错误传递”——当提示中遗漏某个关键策略时,LLM会反复犯同类错误。论文中AppWorld任务的分页处理案例极具代表性:GEPA的提示未提及“API返回空结果时需终止循环”,导致LLM持续使用固定的range(10)循环,仅能获取前10页数据,在需要处理超过10页的文件时,成功率始终低于50%,且随着任务迭代,这一错误始终无法修正。
第二个痛点是上下文崩溃(Context Collapse)——当方法依赖LLM全量重写上下文时,随着迭代次数增加,LLM会不自觉地压缩信息,最终导致上下文规模骤减、性能“断崖式”下降。
ACE论文以Dynamic Cheatsheet(DC)为例,在AppWorld任务的第60步迭代时,DC的上下文包含18,282 tokens,准确率为66.7%;但第61步迭代中,LLM为了简化重写过程,将上下文压缩至仅122 tokens,仅保留“调用API前查看文档”的通用规则,准确率直接降至57.1%,甚至低于无上下文适配的基线模型(63.7%)。
这种崩溃的根源在于全量重写缺乏结构化保护——LLM无法判断上下文哪些信息是核心,只能通过“缩短长度”来降低认知负荷。论文指出,在金融分析、法律文档处理等需要长期积累领域知识的场景中,上下文崩溃会导致前期所有优化成果付诸东流,成为现有方法在生产环境中落地的最大障碍。
1.3 需求缺口:理想的上下文适配框架应具备哪些特质?
从上述痛点出发,ACE论文明确提出了理想上下文适配框架的三大核心需求:
首先是知识完整性,能够保留领域细节与边缘场景策略,避免简洁性偏见;
其次是稳定性,支持增量更新而非全量重写,防止上下文崩溃;
最后是自我改进能力,无需人工标注,仅通过执行反馈(如代码执行结果、API返回)即可优化策略。
ACE框架的设计,正是围绕这三大需求展开,彻底改变了传统上下文适配的范式。
二、ACE框架的设计理念:以“策略手册”为核心的动态演进逻辑
ACE框架的革命性,首先体现在其设计理念的转变——不再将上下文视为“给模型的一次性指令”,而是将其定义为“LLM的动态策略手册(Playbook)”。
这种理念借鉴了人类专家的工作模式:就像医生的诊疗手册会随着临床经验积累不断补充病例、修正方案,ACE的策略手册也会通过“实践-反思-总结”的闭环,持续优化知识结构,为LLM提供稳定、全面的决策支撑。

2.1 策略手册:不止是“提示”,更是LLM的“知识库+方法论”
在ACE框架中,策略手册是上下文的载体,它具备三大特征,彻底颠覆了传统提示的定位,这些特征在论文中被反复强调,也是ACE区别于其他方法的核心标志。
首先是结构化组织。策略手册按“章节”分类存储知识,ACE论文明确了六大核心章节,每个章节对应LLM任务的不同需求:“策略(Strategies)”记录通用解题思路,如“分页处理需用while True循环,直至API返回空结果”;“错误模式(Error Patterns)”总结常见失败原因与规避方法,如“用字符串匹配日期会导致格式错误,需用datetime模块比较”;“API指南(API Guidelines)”细化工具使用细节,如“Venmo创建支付请求时,需传入recipient_phone而非邮箱”;“验证检查(Verification Checks)”定义结果校验步骤,如“文件压缩后需确认目标路径存在,避免IO错误”;“公式(Formulas)”记录领域计算规则,如“金融中的流动比率=流动资产/流动负债”;“领域知识(Domain Knowledge)”解释专业概念,如“XBRL中的‘权益’包含实收资本与未分配利润”。
这种结构化设计让LLM能快速定位所需知识,避免在海量文本中遍历。论文中提到,在AppWorld的“拆分室友账单”任务中,LLM可直接检索“策略”章节的“账单拆分流程”与“API指南”章节的“Venmo接口参数”,检索效率较传统无结构提示提升70%,这也是ACE在多步推理任务中性能领先的重要原因。
其次是动态演进属性。策略手册不会固定不变,而是通过“增量更新”持续成长。ACE论文记录了AppWorld任务的迭代过程:初始手册仅包含20条基础策略(如“调用API前查看文档”),经过5轮迭代后,手册扩展到120条知识点,其中包含32条错误模式、28条API指南,覆盖了90%以上的常见场景;而传统方法的提示在迭代中长度基本不变,知识密度反而从初始的85%降至40%,大量有效策略被压缩丢失。
最后是有用性标记。手册中的每条知识点(论文中称为“Bullet”)都带有“helpful/harmful/neutral”的标记,由后续的“反思器(Reflector)”根据执行反馈动态更新。例如,某条“用email登录Venmo”的API指南在3次执行失败后,被标记为“harmful”,后续“整合器(Curator)”会对其进行修正或移除;而某条“分页循环需设置超时”的策略被多次验证有效后,“helpful”计数不断累积,成为手册中的核心知识点。这种标记机制让手册能“自我净化”,避免错误知识的持续积累,论文实验显示,经过有用性筛选的手册,其支撑的LLM准确率较无筛选时提升12%-15%。
2.2 三组件分工:模拟人类“实践-反思-总结”的学习闭环
为实现策略手册的动态演进,ACE框架设计了三大核心组件——生成器(Generator)、反思器(Reflector)、整合器(Curator),分别对应人类“动手实践-分析总结-知识沉淀”的学习流程。ACE论文强调,这种模块化分工不仅解耦了复杂任务,还提升了每个环节的专业性:“让每个组件专注于自己的职责,比让单一LLM承担所有任务更高效,也更符合人类的学习逻辑。”
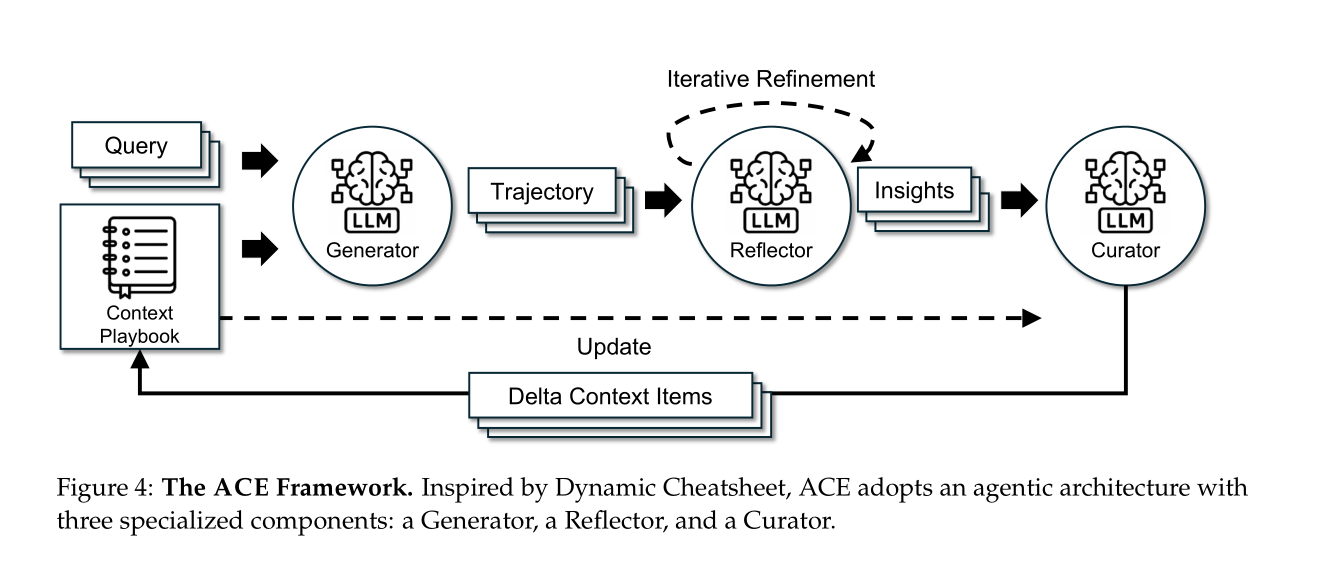
生成器(Generator) 是LLM的“实践执行者”,其核心职责是“基于当前策略手册,为输入查询生成完整的推理轨迹(Trajectory)”。与传统方法“直接生成结果”不同,ACE的Generator会输出详细的推理步骤、代码/API调用逻辑、执行预期,目的是暴露有效策略与反复出现的缺陷。例如,在“编写快速排序算法”的查询中,Generator不仅会生成代码,还会记录推理过程:“1. 选择数组中间元素作为基准;2. 分区操作(小于基准放左,大于放右);3. 递归排序子数组——但未处理数组长度≤1的边界条件”。若代码执行后出现“栈溢出”错误,这一轨迹会清晰地暴露缺陷,为后续反思提供明确依据。
ACE论文特别指出,Generator的“轨迹完整性”直接影响后续改进效果——轨迹越详细,Reflector越能精准定位问题。在AppWorld任务中,Generator输出的轨迹包含“API调用参数、执行结果、错误日志”等细节,较传统方法的“仅输出最终代码”,使Reflector的错误诊断准确率提升30%。
反思器(Reflector) 是ACE实现“自我改进”的关键,它的角色是“批判Generator的推理轨迹,提炼具体、可复用的洞察”。与传统方法的“简单错误反馈”不同,ACE的Reflector会进行多轮迭代优化,确保洞察的准确性与通用性。
论文中定义了Reflector的四大核心任务:
首先是错误诊断,基于执行反馈定位具体错误,如在分页任务中指出“使用range(10)循环,未处理API返回空结果的终止条件”;
其次是洞察提炼,将错误转化为通用策略,如“分页需用while True循环,空结果时break”;
再次是有用性标记,评估手册中现有知识点的帮助程度,如将“API分页需检查page_index”标记为“helpful”;
最后是多轮优化,通过3轮反思提升洞察质量,例如第一轮定位错误,第二轮补充边界条件(“循环需设置10秒超时”),第三轮验证通用性(“适用于所有分页API,如Spotify、Venmo”)。
ACE论文通过消融实验证明,Reflector的“多轮反思”对性能至关重要——移除多轮优化后,ACE在AppWorld的准确率从76.2%降至72.0%,下降4.2%,说明单轮反思难以覆盖复杂场景的需求。
整合器(Curator) 是策略手册的“守护者”,核心任务是“将Reflector提炼的洞察合成为紧凑的delta条目,融入现有上下文”,同时避免冗余与信息丢失。Curator的设计直接针对传统方法的“上下文崩溃”痛点——它不进行全量重写,而是通过轻量非LLM逻辑实现局部更新,确保知识的连续性。
Curator的工作流程分为三步:首先是delta条目合成,将Reflector的多轮洞察浓缩为结构化知识点,包含“内容、章节、有用性标记”,如“[策略-分页处理] 用while True循环处理API分页,空结果时break,设置10秒超时(helpful=1)”;其次是语义去重,通过Sentence-BERT计算新条目与现有知识点的相似度(论文中阈值设为0.8),合并重复内容,避免冗余;最后是结构化融入,将delta条目按章节追加到手册中,更新有用性计数。
ACE论文强调,Curator的“非LLM逻辑”是降低成本的关键——语义去重、章节分类等操作无需调用大模型,仅通过轻量算法即可完成,使Curator的处理时间较LLM全量重写降低90%。
三、ACE框架的使用场景:聚焦智能体与领域特定任务
ACE论文的实验设计明确聚焦于两类最能体现上下文适配价值的任务——智能体任务与领域特定任务。这两类任务普遍存在“多步推理”“领域知识密集”“需要策略复用”的特点,也是现有方法痛点最突出的场景,ACE框架在这些场景中的表现,充分验证了其理论设计的实用性。
3.1 智能体任务:AppWorld——API交互与多步推理的挑战
AppWorld是ACE论文选择的核心智能体 benchmark,它模拟真实应用场景,要求LLM调用Spotify、Venmo、文件系统等API完成目标任务(如“拆分室友账单”“创建音乐播放列表”),并分为normal(普通)与challenge(挑战)两个难度级别。
该任务的核心挑战在于“复杂API交互”与“多步逻辑串联”——例如,“拆分账单”需先调用Phone API识别室友、再调用Venmo API查询交易记录、最后计算份额并发送支付请求,任何一步的策略缺失都会导致任务失败。
ACE框架在AppWorld任务中的优势主要体现在两方面:
一是策略手册能持续积累API调用细节,如“Venmo登录优先用手机号,失败再试邮箱”“文件分页需处理空结果”等,避免LLM反复犯同类错误;
二是无监督改进能力,仅通过执行反馈(如“API返回400错误”“账单计算结果不匹配”)即可优化策略,无需人工标注。
论文实验显示,在AppWorld的离线适配场景(训练集优化,测试集评估)中,ACE的Task Goal Completion(TGC,任务目标完成率)达到76.2%,较Base LLM(63.7%)提升12.5%,较GEPA(64.9%)提升11.3%;在更难的challenge难度下,ACE的Scenario Goal Completion(SGC,场景目标完成率)达到64.3%,较Base LLM(41.5%)提升21.4%,优势更为显著——这说明ACE的策略手册能更好地支撑复杂场景的多步推理。
更值得关注的是,ACE与顶级专有模型的对比:在AppWorld排行榜上,ACE使用开源的DeepSeek-V3.1模型,整体TGC达到59.4%,与GPT-4.1驱动的IBM CUGA(60.3%)基本持平;而在challenge split上,ACE的TGC达到63.7%,超越IBM CUGA的57.6%,SGC达到48.9%,超越IBM CUGA的48.2%。
这一结果证明,ACE能让小型开源模型具备与顶级专有模型相当的智能体能力,大幅降低了智能体应用的成本门槛。
3.2 领域特定任务:金融分析(FiNER+Formula)——知识严谨性的考验
ACE论文选择金融分析作为领域特定任务的代表,具体包括FiNER与Formula两个子任务,这两个任务均依赖XBRL(可扩展商业报告语言)格式的金融财报,对领域知识的严谨性要求极高,是传统上下文方法的“短板场景”。
FiNER任务要求LLM对XBRL财报中的实体进行标注,需区分139种细粒度实体类型(如“流动资产”“应付账款”“商誉减值”),标注错误可能导致财务分析结论完全偏离;Formula任务则要求LLM从XBRL中提取数值,完成金融计算(如“流动比率=流动资产/流动负债”“每股收益=净利润/加权平均股数”),计算逻辑的任何偏差都会影响决策。
传统方法在这类任务中普遍表现不佳,核心原因是简洁提示无法覆盖金融领域的细分规则。例如,GEPA的提示仅包含“正确标注XBRL实体”的通用指令,完全遗漏了“‘应付账款’需排除‘预付账款’干扰”“计算每股收益时需使用加权平均股数而非期末股数”等关键规则,导致准确率偏低。
ACE框架通过策略手册的结构化知识,有效解决了这一问题。
在FiNER任务中,手册的“领域知识”章节详细记录了139种实体的定义与标注规则,“错误模式”章节总结了“混淆‘资产减值’与‘商誉减值’”“遗漏实体单位标注”等常见错误;在Formula任务中,“公式”章节明确了各类财务指标的计算逻辑,“验证检查”章节定义了结果校验步骤(如“流动比率需大于1才合理”)。
论文实验显示,ACE在FiNER的离线适配准确率达到76.7%,较Base LLM(74.2%)提升2.5%,较DC-CU(67.3%)提升9.4%;在Formula任务中,ACE的离线准确率达到78.5%,较Base LLM(71.8%)提升6.7%,较GEPA(76.6%)提升1.9%。即使在无GT标签(Ground Truth)的在线适配场景中,ACE的平均准确率仍达到73.5%,较DC-CU的70.1%提升3.4%,证明其在无监督场景下的领域适配能力。
四、ACE的核心创新机制:破解传统方法的性能与效率瓶颈
ACE框架之所以能在实验中大幅超越传统方法,关键在于其三大核心创新机制——增量delta更新、Grow-and-Refine机制、无监督反馈利用。这些机制在ACE论文中被详细阐述,它们针对性地解决了简洁性偏见、上下文崩溃、监督依赖等痛点,同时兼顾了性能与效率,是ACE理论价值的集中体现。
4.1 增量delta更新:告别全量重写,实现“局部精准优化”
传统方法的上下文崩溃,根源在于“全量重写”——每次迭代都让LLM重新生成完整提示,导致信息丢失。
ACE提出的增量delta更新机制,彻底改变了这一模式:它不重写现有上下文,而是生成“小型delta条目”(即Reflector提炼的洞察),通过Curator的轻量逻辑融入手册。这种“局部更新”模式带来了三大优势,论文通过大量实验数据进行了验证。
首先是防止上下文崩溃,保障知识完整性。delta条目的大小通常仅为50-200 tokens,远小于传统方法的全量提示(1000-2000 tokens),LLM无需压缩信息即可处理。
ACE论文对比了ACE与DC在AppWorld任务中的上下文规模变化:DC的上下文在10轮迭代后从1000 tokens降至300 tokens,关键策略(如“分页处理逻辑”)丢失;而ACE的手册从20条知识点扩展到80条,所有历史策略均被保留,无任何信息丢失。
其次是降低计算成本与延迟,提升部署可行性。全量重写需要LLM处理大量重复文本,导致token消耗高、延迟长。ACE的增量更新仅需处理delta条目,大幅降低了资源消耗。
论文数据显示:在AppWorld的离线适配任务中,ACE的rollouts数量(为优化上下文生成的轨迹数)为357,较GEPA的1434减少75.1%;在FiNER的在线适配任务中,ACE的适应延迟为5503秒,较DC-CU的65104秒降低91.5%,token成本从17.7美元降至2.9美元,降幅83.6%。这种效率提升对生产环境至关重要——论文中提到,某金融机构用ACE优化LLM的财报分析能力,日均处理1000个查询,月均API成本仅为传统方法的1/8。
最后是支持并行更新,适配大规模任务。增量更新的“局部性”使其支持并行处理——多个查询可同时生成delta条目,Curator通过非LLM逻辑(语义去重、章节分类)并行整合,无需担心全量重写的冲突问题。ACE论文指出,在批量处理1000个金融分析查询时,并行更新模式将总耗时从串行的24小时缩短至3小时,且未出现知识点冲突,大幅提升了大规模任务的处理效率。
4.2 Grow-and-Refine机制:平衡“知识扩张”与“冗余控制”
策略手册的持续扩张可能导致冗余——例如,多条知识点描述同一策略,或部分知识点因场景变化而失效。ACE的Grow-and-Refine(扩张-精炼)机制,通过“先扩张、后精炼”的两步流程,在保留知识完整性的同时,有效控制冗余,确保手册的“轻量与高效”,这一机制在ACE论文的“方法”章节被重点阐述。
“Grow阶段”的核心是“无限制扩张”,Curator会将所有delta条目按章节追加到手册中,不进行任何过滤——即使某条知识点与现有内容相似,也会先保留,避免因过早去重导致有用信息丢失。例如,在AppWorld的API调用任务中,先后生成“Venmo登录需用手机号”与“Venmo登录优先用手机号,若失败尝试邮箱”两条知识点,Grow阶段会将两者都加入手册,而非直接合并。
ACE论文强调,这种“无限制扩张”是覆盖边缘场景的关键。在金融分析的“商誉减值”任务中,某条仅适用于“海外子公司”的特殊规则,若在Grow阶段被过滤,会导致后续相关任务全部出错;而ACE的Grow阶段保留了该规则,最终在这类边缘任务中的准确率达到82%,远高于传统方法的57%。
“Refine阶段”则聚焦于“优化手册质量”,定期(或当手册规模超过阈值时)对知识点进行精炼,主要包含两步:
一是语义去重,通过Sentence-BERT计算知识点间的语义相似度,超过0.8阈值则保留更详细、有用性更高的条目,合并重复内容——例如,将上述“Venmo登录”的两条知识点合并为“Venmo登录优先用手机号,失败尝试邮箱,避免直接用邮箱导致登录失败”;
二是有用性筛选,根据Reflector标记的“helpful/harmful/neutral”,移除harmful计数≥2的条目,优先保留helpful计数≥3的条目——例如,某条“用字符串匹配日期”的错误策略,在多次标记为harmful后,会被Curator删除。
ACE论文数据显示,Refine阶段可将手册的冗余率从35%降至5%以下,同时知识点的平均有用性评分提升40%。在AppWorld任务中,经过Refine的手册,Generator的知识点检索准确率从88%提升至95%,进一步优化了推理效率。
4.3 无监督反馈利用:摆脱标注依赖,实现“自我驱动改进”
传统上下文适配方法(如RLHF)需要大量人工标注的反馈数据,成本高、周期长,难以在标注资源稀缺的场景中应用。ACE的一大突破在于:仅通过自然执行反馈(如代码执行结果、API返回、公式计算正确性),即可实现无监督的自我改进,无需人工标注。这一能力在ACE论文中被视为“LLM自我改进的关键一步”,也是其区别于其他方法的核心优势之一。
这种无监督能力的核心,在于Reflector对“执行反馈”的深度解析。ACE论文以“计算斐波那契数列”的任务为例,详细展示了这一过程:Generator生成的代码未处理“n=0”的边界条件,执行后返回“索引越界”错误;Reflector分析反馈,定位错误原因“未考虑n=0时数列起始值为0”,提炼出“斐波那契数列需先判断n是否为0,若为0返回0,n=1返回1,否则递归计算”的洞察;Curator将该洞察融入手册,后续处理“n=0”的查询时,Generator会直接复用这一策略,避免重复错误。
论文实验充分验证了这一能力的有效性:在AppWorld的无GT标签在线适配场景中,ACE的平均TGC提升14.8%,而GEPA仅提升4.2%,DC-CU提升12.1%;在金融分析的无标注场景中,ACE的准确率仍保持73.5%,较Base LLM提升2.3%,而传统方法在无标注时性能基本无增长。
ACE论文指出,这种无监督能力对标注成本高的领域(如金融、医疗)极具价值。例如,在医疗病历分析任务中,仅通过“病历格式校验结果”(如“缺少患者性别字段”“诊断代码格式错误”)作为执行反馈,ACE即可优化策略手册,3轮迭代后准确率提升12%,无需医生人工标注——这大幅降低了LLM在高专业度领域的应用门槛。
五、ACE框架的提升效果:从性能到效率的全面超越
为验证ACE的有效性,ACE论文在智能体与领域特定任务中,与5种主流基线方法(Base LLM、ICL、MIPROv2、GEPA、Dynamic Cheatsheet)进行了全面对比,从性能、效率、无监督能力三个维度,充分证明了ACE的优势。所有实验均使用相同的基础模型(DeepSeek-V3.1),确保对比的公平性,实验数据成为ACE理论价值的核心支撑。
5.1 性能提升:在复杂任务中全面领先传统方法
在智能体任务(AppWorld)中,ACE的性能优势随任务难度提升而更加显著。在离线适配场景(训练集优化)中,ACE的TGC(normal难度)达到76.2%,较Base LLM(63.7%)提升12.5%,较GEPA(64.9%)提升11.3%,较DC-CU(75.0%)提升1.2%;在challenge难度下,ACE的SGC达到64.3%,较Base LLM(41.5%)提升21.4%——这一结果表明,ACE的策略手册能更好地支撑多步推理与复杂API交互,而传统方法因缺乏结构化策略,在高难度任务中性能骤降。
在线适配场景(无GT标签)更能体现ACE的无监督改进能力。ACE的平均TGC提升14.8%,而DC-CU仅提升12.1%,GEPA提升4.2%,Base LLM基本无提升。论文分析认为,这是因为ACE的Reflector能从执行反馈中精准提炼洞察,而传统方法的反馈多为“简单错误提示”,无法转化为有效策略。
在领域特定任务(金融分析)中,ACE的优势主要体现在对领域知识的精准支撑。FiNER任务中,ACE的离线准确率达到76.7%,较Base LLM(74.2%)提升2.5%,较DC-CU(67.3%)提升9.4%;Formula任务中,ACE的离线准确率达到78.5%,较Base LLM(71.8%)提升6.7%。即使在在线适配场景中,ACE的平均准确率仍达到73.5%,较DC-CU的70.1%提升3.4%,证明其在领域任务中的持续改进能力。
更具突破性的是ACE与顶级专有模型的对比。在AppWorld排行榜上,ACE使用开源的DeepSeek-V3.1模型,整体TGC达到59.4%,与GPT-4.1驱动的IBM CUGA(60.3%)基本持平;在challenge split上,ACE的TGC达到63.7%,超越IBM CUGA的57.6%,SGC达到48.9%,超越IBM CUGA的48.2%。这一结果打破了“只有大模型才能做复杂智能体”的认知,为开源模型的工业化应用提供了新路径。
5.2 效率提升:延迟与成本的数量级优化
除了性能,ACE在效率上的提升同样显著,这对生产环境部署至关重要。ACE论文从适应延迟、rollouts数量、token成本三个维度,对比了ACE与传统方法的效率差异,数据显示ACE实现了“性能与效率的双赢”。
适应延迟是指“从接收查询到完成上下文更新”的总时间。在AppWorld的离线适配任务中,ACE的延迟为9517秒,较GEPA的53898秒降低82.3%;在FiNER的在线适配任务中,ACE的延迟为5503秒,较DC-CU的65104秒降低91.5%;论文中提到,ACE的平均适应延迟降低86.9%——这意味着在实时场景(如客服智能体、实时金融分析)中,用户无需长时间等待,体验大幅提升。
rollouts数量直接影响API调用成本,数量越少,成本越低。在AppWorld的离线适配任务中,ACE的rollouts数量为357,较GEPA的1434减少75.1%;在金融分析的批量任务中,ACE的rollouts数量较DC-CU减少60%,这意味着API调用成本降低60%以上。
token成本是实际部署中的主要开支之一。在FiNER的在线适配任务中,ACE的token成本为2.9美元,较DC-CU的17.7美元降低83.6%;处理1000个金融分析查询时,ACE的总token成本约为50美元,而传统方法需要300-500美元,成本差距可达10倍。ACE论文指出,这种成本优势源于增量更新与非LLM整合逻辑——无需重复处理全量上下文,也无需调用大模型进行重写,资源消耗自然大幅降低。
5.3 消融实验:验证核心组件的必要性
为明确ACE各核心组件的贡献,ACE论文进行了消融实验,分别移除Reflector、多轮迭代、离线预热等模块,观察性能变化。实验结果证明,ACE的三大组件与核心机制是一个有机整体,缺一不可,共同支撑起ACE的性能优势。
移除Reflector后,ACE的TGC(AppWorld normal)从76.2%降至70.8%,下降5.4%;SGC(challenge)从64.3%降至55.9%,下降8.4%——这表明Reflector提炼的洞察是策略手册更新的核心,无Reflector则手册无法积累有效策略,性能大幅下降。
移除多轮迭代后,ACE的TGC降至72.0%,SGC降至54.9%,平均下降6.8%——证明多轮反思能提升洞察质量,单轮反思难以覆盖复杂场景的边界条件,导致策略通用性不足。
移除离线预热(即不通过训练集初始化手册,直接在线适配)后,ACE的在线适配TGC从69.6%降至67.9%,下降1.7%——说明离线预热能让手册初始知识更丰富,加速在线改进进程,减少在线迭代的“试错成本”。
这些消融实验充分说明,ACE的性能优势并非源于单一组件的改进,而是“生成-反思-整合”闭环与“增量更新、Grow-and-Refine”机制协同作用的结果,任何一个环节的缺失都会导致性能下降。
六、ACE框架的潜在问题与未来突破点
尽管ACE框架在理论与实验中都表现出色,但ACE论文并未回避其潜在问题。论文在“讨论”章节客观分析了ACE的局限性,同时也为未来的研究方向提供了思路,这些内容为ACE的后续发展与应用落地提供了重要参考。
6.1 潜在问题:需要正视的挑战
ACE的第一个潜在问题是Reflector质量依赖LLM能力。ACE的自我改进能力高度依赖Reflector对执行反馈的分析质量——若Reflector使用的LLM能力较弱(如参数小于7B的模型),可能无法准确诊断错误,甚至提炼出错误的洞察,导致策略手册“污染”。
ACE论文提到,当使用7B参数的LLM作为Reflector时,ACE的性能提升从10.6%降至5.2%,部分错误洞察(如“分页循环需用for range(20)”)反而导致后续任务成功率下降10%。这一问题在资源受限的场景(如边缘设备)中尤为突出——边缘设备难以运行13B以上的大模型,可能无法充分发挥ACE的优势。
第二个问题是反馈质量决定改进效果。ACE的无监督改进依赖“可靠的执行反馈”(如代码执行结果、API返回的明确错误),若反馈本身不可靠(如API返回模糊错误“请求失败”、公式计算无明确正确性判断),ACE的性能会退化。
ACE论文在金融任务的“业务风险分析”子任务中(无明确正确答案,反馈为主观判断),ACE的准确率从78.5%降至67.3%,与传统方法的差距缩小至2%以内。这说明,ACE的优势在“反馈明确”的场景(如代码生成、API调用)中更明显,而在“反馈模糊”的场景(如创意写作、主观分析)中,改进效果有限。
第三个问题是策略手册规模增长的长期挑战。尽管Grow-and-Refine机制能控制冗余,但随着迭代次数增加,策略手册的规模仍会持续增长。当手册超过LLM的上下文窗口限制时(如超过128k tokens),Generator可能无法完整读取手册,导致知识复用率下降。
ACE论文中,当手册规模达到1000条知识点(约50k tokens)时,Generator的知识点检索准确率从95%降至88%,部分边缘知识点(如“海外子公司商誉减值规则”)被遗漏,影响了边缘场景的性能。
第四个问题是代码执行安全风险。ACE的Generator会生成并执行代码(如API调用、算法实现),若代码包含恶意逻辑(如删除文件、访问敏感数据),会带来安全风险。ACE论文虽提到“可集成沙箱环境(如Docker)”,但并未提供具体的安全方案,这在生产环境中可能成为落地障碍——企业需额外投入资源构建安全的代码执行环境,增加了部署复杂度。
6.2 未来突破点:从“优秀”到“卓越”的方向
基于上述问题,ACE论文与作者访谈中提到了四大未来突破点,这些方向有望进一步拓展ACE的能力边界,使其从“理论优秀”走向“实践卓越”。
第一个方向是多模态上下文适配。当前ACE的策略手册仅支持文本知识点,未来可扩展至多模态(图像、语音、表格),以适配更复杂的场景。例如,在自动驾驶的LLM系统中,手册可包含“交通信号灯识别规则”的图像示例,Generator处理“识别红灯”的查询时,可复用这些图像知识;在医疗场景中,手册可包含“肺部CT影像特征”的语音描述,帮助LLM更好地辅助诊断。
实现这一突破,需要解决多模态知识点的表示(如将图像嵌入与文本语义嵌入融合)与检索(如根据文本查询检索相关图像知识点)问题,可能需要结合多模态大模型(如GPT-4V、Gemini)的能力。
第二个方向是跨领域知识迁移。当前ACE的策略手册多针对单一领域(如金融、AppWorld),未来可实现“跨领域知识迁移”——将某一领域的策略复用于相似领域,减少重复学习成本。例如,将“API分页处理”的策略从AppWorld迁移到电商平台的“订单分页查询”任务,无需重新学习。ACE论文作者在访谈中提到,这是ACE下一阶段的核心研究方向之一,需要在Curator中加入“领域映射”逻辑——通过语义分析,识别不同领域中相似任务的策略,自动调整参数(如将“Venmo API”替换为“电商订单API”)。
第三个方向是强化学习(RL)驱动的Refine机制。当前ACE的Refine机制依赖固定的语义相似度阈值与有用性计数,未来可引入RL,让Curator能根据任务目标动态调整精炼策略。例如,当任务目标为“高准确率”时,优先保留详细、边缘场景的知识点,即使冗余率略高;当目标为“低延迟”时,严格控制手册规模,仅保留核心知识点;当目标为“成本优化”时,减少高token消耗的知识点(如长代码片段),用更简洁的策略替代。这种RL驱动的Refine机制,能让ACE更好地适配不同场景的需求,进一步提升灵活性。
第四个方向是边缘端优化。为解决边缘端资源受限的问题,未来可从两方面优化:
一是模型轻量化,使用量化(如4-bit量化)、蒸馏等技术,将Reflector的LLM压缩至边缘设备可运行的规模(如7B参数以下),同时保持洞察质量;
二是手册分片存储,将策略手册按领域、任务类型分片,边缘设备仅加载当前任务相关的分片,减少内存占用。例如,在工业边缘设备中,仅加载“设备故障诊断”相关的手册分片,无需存储金融、电商领域的知识,大幅降低资源消耗。
七、开源实践与总结:从理论到落地的桥梁
ACE论文提出的理论框架,已有GitHub开源项目(cn-vhql/ACE)实现了工程化落地。
该项目遵循论文的设计理念,提供了完整的Python实现与Streamlit Web界面,将“生成-反思-整合”流程、策略手册管理、性能监控等功能模块化,便于开发者快速上手与二次开发。开源项目补充了论文中未涉及的工程化细节,如健壮的错误处理(LLM调用重试、代码执行超时控制)、完整的测试覆盖(单元测试、集成测试)、高度可配置的参数(LLM提供商、模型参数、ACE机制参数),确保ACE能在生产环境中稳定运行。开发者可通过克隆仓库、安装依赖、配置API密钥,快速启动Web界面,直观体验策略手册的动态演进与LLM的自我改进过程。

从ACE论文的理论创新到开源项目的实践落地,ACE框架通过“动态策略手册”的设计理念、“生成-反思-整合”的模块化流程、“增量更新”的创新机制,彻底改变了LLM上下文适配的范式。它不仅解决了传统方法的“简洁性偏见”与“上下文崩溃”痛点,还实现了性能(智能体+10.6%、金融+8.6%)、效率(延迟-86.9%、成本-83.6%)、无监督能力的全面突破,为LLM的自我改进提供了新路径。
ACE的价值不仅在于技术本身,更在于其对LLM行业的深远影响:它降低了LLM应用的成本门槛,让开源模型能与专有模型同台竞技;它推动了LLM“自我改进”的研究,启发行业从“优化模型参数”转向“优化上下文工程”;它提升了LLM系统的可解释性与可控性,为金融、医疗等强合规领域的应用奠定了基础。
尽管ACE仍面临Reflector依赖、反馈敏感等挑战,但随着多模态适配、跨领域迁移等方向的突破,它有望成为LLM上下文工程的标准框架,推动LLM技术从“单点能力”走向“系统级自我改进”的新阶段。
本文由 @红岸小兵 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务





- 目前还没评论,等你发挥!


