
 起点课堂会员权益
起点课堂会员权益泡沫破碎还是价值回归?RLI 揭秘 AI“打工”的真实战力
AI能否真正替代人类工作?Scale AI与Center for AI Safety发布的Remote Labor Index (RLI)研究,通过模拟真实职场环境,对AI的交付能力进行了残酷测试,结果令人震惊。

过去两年,“AI 会取代多少人类工作?”几乎是各行各业焦虑的源头 。但在这个热闹的讨论之外,我们似乎忽略了一个最冷静、也最致命的问题:AI 真的具备“交付”真实工作的能力吗?
最近,Scale AI 联合 Center for AI Safety 发布的 Remote Labor Index (RLI) 研究,一盆儿冷水浇在了“AI 替代论”的头上 。这份研究不再让 AI 做填空题,而是直接把它们扔进了残酷的“职场”。
一、为什么需要RLI?RLI 撕开“能力”与“交付”的面纱
现在的 AI 就像是一个在学校里门门考满分的“做题家” 。但我们都知道,学历高不代表干活靠得住。
目前的测试题大多是在测“孤立的技能” 。RLI 就是为了打破这种幻觉而生的。它不仅仅是考试,而是模拟真实的甲方验收现场:
举个例子:
现在的 AI 可能在“倒车入库”(比如回答百科问题、写一段 Python 代码)上拿满分 。但光会倒车入库,不代表你能去开滴滴赚钱 。现在的测试看不出 AI 到底能不能把车开上路、接乘客、送到目的地这一整套流程走下来——也就是所谓的 “端到端性能” 。
再比如:
甲方需求: 比如“帮我设计一个万圣节促销海报,要有恐怖氛围但又要可爱” 。
给你的材料: 原始的 Excel 表、图片素材、CAD 图纸,都在文件夹里自己找 。
及格标准: 必须交付一个人类专家做出来的、甲方愿意掏钱买单的成品 。
二、史上最难“职场大考”:连续干 4 天才算一题
RLI 抛弃了那些几分钟就能搞定的简单任务,直接从 Upwork 等平台“买”来了 240 个真实世界的付费外包项目,涵盖视频制作、3D 建模、代码开发等 23 个领域 。
这些任务极具挑战性,人类专家平均耗时 28.9 小时,最长耗时达 450 小时。按咱们一天工作 8 小时算,这意味着平均接一个单子,得连续干将近 4 天才能做完。以前的 AI 测试题(比如让它写个贪吃蛇游戏),可能人类 10 分钟就搞定了。这次的题量是以前的 2 倍以上 ,甚至有的项目人类干了 450 个小时(快两个月)。
三、成绩单揭晓
1.即使给配了电脑操作环境和专业工具,并给予模型明确提示:
- 图像生成:调用 gpt-image-1 生成或编辑图像;
- 视频生成:调用 veo-3.0 生成视频;
- 语音合成: 调用 openai/tts-1 生成语音。
2.“工位”分配:针对不同模型的能力特点分配两种不同的操作环境
- 普通员工模式: 对于支持操作电脑的模型(如 GPT-5 CUA, Sonnet 4.5),直接配齐了鼠标、键盘、截图工具和文件编辑器,让它们像人类一样操作桌面 。
- 程序员模式(CLI): 对于不支持计算机使用的模型(Grok 4、Gemini 2.5 Pro),则使用 OpenHands 提供的命令行界面,让它们通过敲代码(Bash 命令、Python 脚本)和调用特定 API 工具来干活 。
最终结果确实也是有点震惊的哈,
最强的 Agent(Manus)自动化率也仅为 2.5%,GPT-5 (CLI) 为 1.7%,而 Gemini 2.5 Pro 仅为 0.8%。  典型失败不只是只差一点…
典型失败不只是只差一点…
- 需要 8 分钟的视频,AI 只做了 8 秒
- 复杂建筑渲染内部视角互相矛盾
- 游戏可运行但画面像儿童画
- 设计图中文字乱码或错别字
- 交付文件空白、损坏、格式不支持
当然,AI 也有它的舒适区。在 音频编辑、图片广告设计、简单的数据可视化和爬虫 领域,它表现得还不错 。这说明 AI 在创意类与轻量编码任务上有潜能,但在需要严谨逻辑的工程执行类任务上仍严重受限 。
四、 经济账:不仅是“菜鸟互啄”,更是价值洼地
由于自动化率太低了,很难看出细微差别,研究人员不得不引入了 ELO 分数,给这群垃圾排个座次,衡量不同模型之间的相对性能谁比谁强一点。
研究团队算了一笔账:
赚到的钱: 整个题库价值 $143,991,表现最好的 Manus 只赚到了 $1,720,Gemini 更是只赚了 $210。
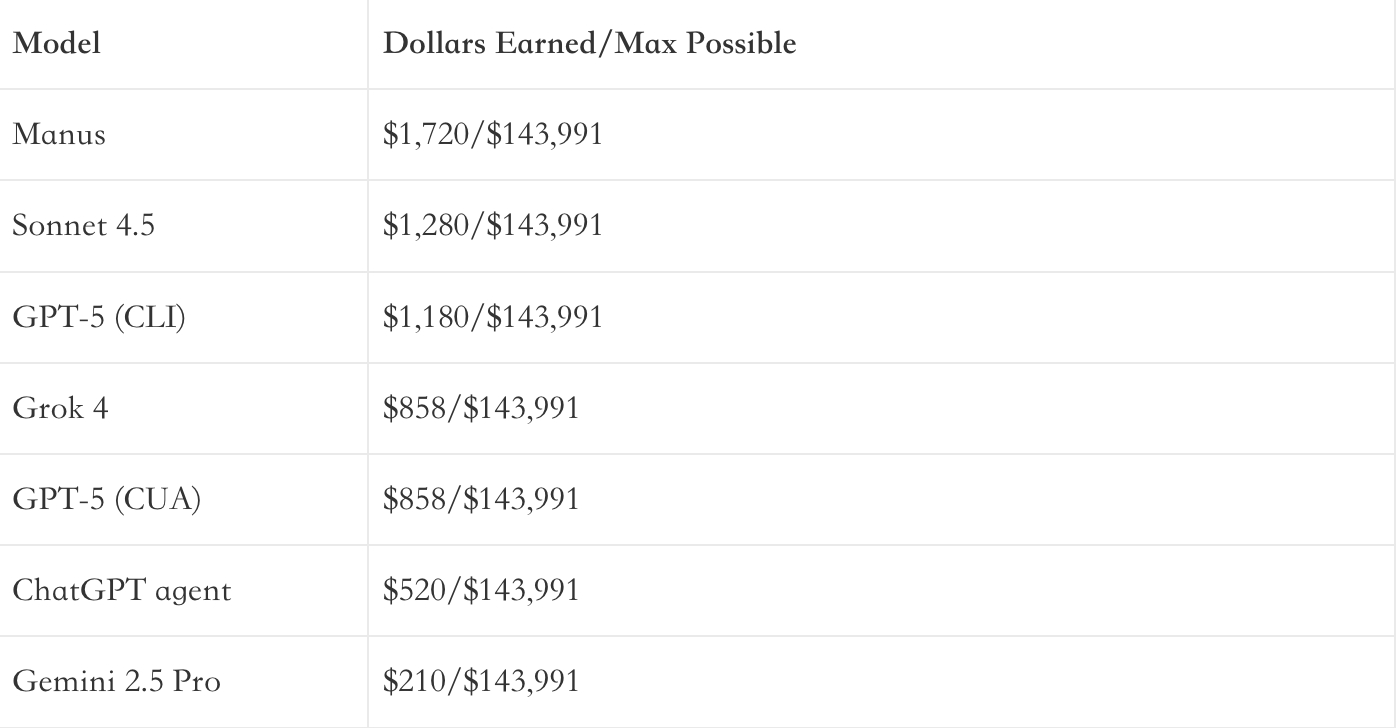
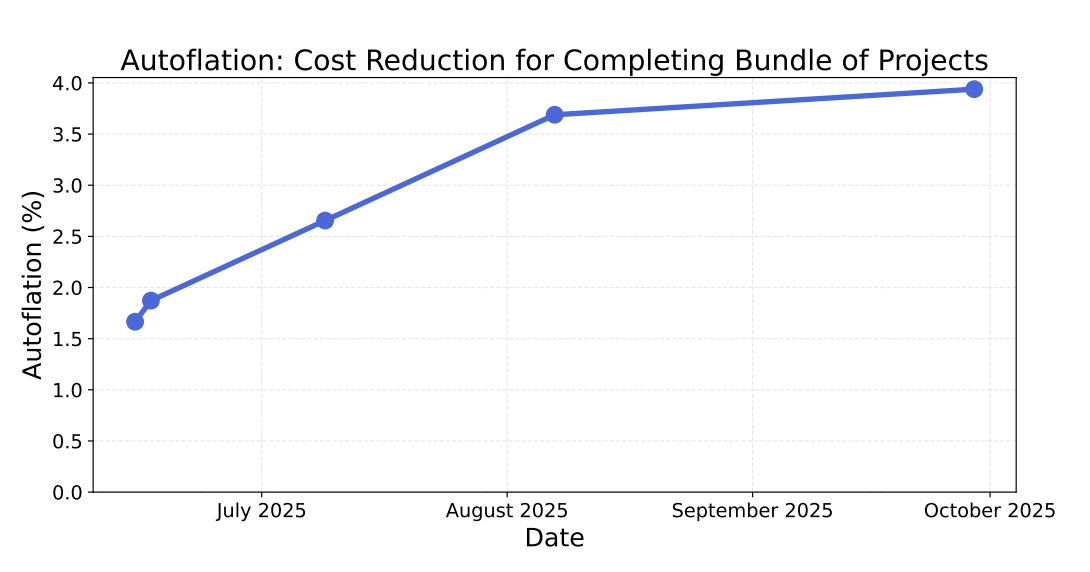
自动化通胀:可以把他理解成,作为一个大老板,把这 240 个 RLI 项目全部外包出去,用AI能比纯雇佣人类省下多少百分比的钱。
看下图,虽然我们看到在增长,但最高也仅仅停留在 3.9% 左右 。也就是…面对这价值 14 万美元的工作,如果完全依赖目前最先进的 AI 技术(包括 Manus、GPT-5 等),顶多能省下 4% 的钱。
结语:告别“做题家”,拥抱“实战派”
我觉得答案已经很明晰了,RLI 的发布不仅仅是一次测试,更是一道行业分水岭,它用残酷的数据证明:传统的“做题家”式评测体系已经失效 。当模型在 MMLU 等考卷上拿满分,却在真实外包单面前只有 2.5% 的及格率时 ,我们必须承认,旧的标尺已经不太能量出 AI 的真实高度了。
AI模型,也要升一个高度卷了,从考察“孤立技能”转向“端到端交付”。这不仅是评测方法的迭代,更是 AI 从实验室走向真实生产力的必经之路。
本文由 @一天赚够500万 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


