
 起点课堂会员权益
起点课堂会员权益Claude Opus 4.5 全面上线,凭什么夺回 Agentic Coding 第一!
Claude Opus 4.5 在大模型密集发布期上线,凭借单提示词生成高完成度交互应用、可调 effort 参数、高级工具调用等核心升级,实现编码效率与性价比提升,定位专业开发者及知识工作者,仍是 AI 编码领域王者,而 Gemini 在推理与多语言领域保持优势。

我们现在正处于新一轮大模型密集发布期。上周是 Grok、Gemini 3.0、Nano Banana Pro,本周 Anthropic 的 Claude Opus 4.5 上线。
直观感受:Minecraft & 乐高测试
在只给出一条提示词的前提下,模型生成了一个 Minecraft 克隆版。在这个单提示词测试中,这是目前见过效果最好的一次。角色移动流畅、帧率稳定,可以正常破坏和放置方块,在下方快捷栏切换不同方块类型,也可以在地图中自由飞行。就完成度和可玩性而言,这个 Demo 已经接近一款真正可玩的沙盒游戏。
与之对比,在同样的“单提示词 Minecraft 测试”中,Gemini 3 Pro 给出的结果就明显逊色一截。世界同样是程序化生成的,但无法破坏或放置方块,角色移动也略显混乱,只能算是基础可看的 Demo。
在这个测试里,Opus 4.5 可以说是碾压式领先。用另一条提示词让它生成一个乐高搭建网站,支持用户自由拼搭积木。返回的结果是一个完整可用的乐高模型。可以在场景中拖动视角,把积木逐块堆叠、修改颜色、切可以删除,甚至选择不同形状的乐高积木。这已经到了一条提示词,就能生成高完成度交互应用的程度。而且提示词本身也并不复杂。
AI Agent 的 Effort(努力程度)参数
在 n8n、Make 等自动化平台里集成自研 AI 模型时,现有的编码模型往往会自行决定推理深度和 token 使用量,调用方几乎无法约束。很多本可以用轻度思考解决的步骤,被模型当成深度推理来算,白白多花了大量 token 成本。
Opus 4.5 在 Agent 能力上引入了可调的effort参数,把模型的“投入程度”分成三档:低(low)、中(medium)和高(high)。从官方对比图可以看到,在同等任务下,Opus 4.5 的 token 消耗相较 Sonnet 4.5 呈指数级下降,而 Sonnet 4.5完全不支持这种选项。
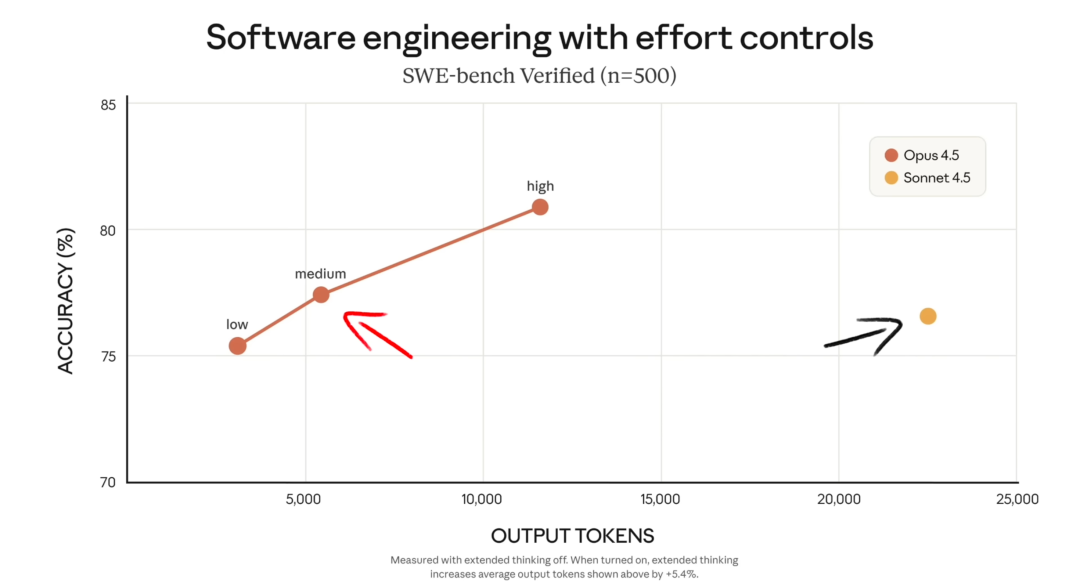
在社区热议的编码测试中,Opus 4.5 的亮点在于,在达到相近甚至更好的效果时,用的 token 明显更少。配合 effort 参数,用户可以在“尽量省时间省钱”和“尽可能压榨模型上限”之间自定义平衡点。
测试结果显示:在 medium effort 档位,Opus 4.5 就能追平 Sonnet 4.5 在 SWB 基准上的最佳验证分数,但输出 token 减少了约 76%。即便调到最高 effort 档,它仍然优于 Sonnet 4.5,同时输出 token 也少了约 48%。
再叠加这次价格下调,每 100 万输入 token 5 美元、每 100 万输出 token 25 美元,大约是原来的三分之一,整体性价比的提升非常明显。
高级工具调用能力
这一次对效率的提升也非常夸张。过去在编码场景中,只要 Agent 需要调用工具,它往往会先把工具列表“扫一遍”,再决定要用哪一个或哪几个,过程既慢又极度浪费 token。而现在的 Opus 4.5可以只拉取正确的工具。
在Anthropic的官方演示中,设定是你继承了一座古怪锁匠祖先留下的神秘保险库,里面是一串相互保护、层层嵌套的数学密码锁。在这个 Demo 里,Opus 4.5不只是在用工具,而是真的在按步骤推进整套解谜过程。Anthropic 强调的是在全新的高级工具调用机制加持下,Opus 4.5 在效率和推理能力上相比上一代有多大跃升。
它不再采用“把能访问的工具全部调用一遍”的粗暴策略,而是先在工具集合中进行检索与过滤,只调用真正与当前子任务相关的那一小部分。从结果看,在同一套谜题、同一关卡设计下,Opus 4.5 能一路解完所有房间,最终成功打开主保险库,全程大约消耗 70 万个 token。而 Sonnet 4.5 则消耗了约 800万个 token,到最后仍然没有完成解谜。
按官方定价粗略折算,同样一局任务下来,Sonnet 4.5 的成本大约在 4 美元左右,而 Opus 4.5 仅约 1 美元。从评测视角看,第一个非常明显的升级点,就是这套“高级工具调用”(smarter tool usage)带来的成本与效率优势。
Agent 电脑操作的再度升级
2023 年 10 月,Anthropic 首次展示了一种更先进形态的 AI 智能体。Claude 的扩展能力 Computer Use。顾名思义,这项功能允许用户像指挥一名远程助理那样,让 Claude 直接操作电脑。移动光标、点击按钮、输入文本,不再只是在对话框里给建议,而是能真正“上手”替你完成屏幕上的具体任务。
Anthropic 是最早提出这个概念的团队之一。这个概念当时引发了大量讨论,但早期落地效果并不理想。电脑操作型 Agent 面临的一个关键瓶颈在于,它必须像人类用鼠标那样,在屏幕的具体坐标上点击。而人类可以根据内容自如地缩放、拖动、调整界面视角,这些对 Agent 来说在过去几乎是不可达的操作能力,也严重限制了它在真实桌面环境中的实用性。
以前如果用户要点击屏幕上一个非常小的按钮,往往需要先把那一块区域放大。而早期的电脑操作 Agent 根本做不到这种“先缩放、再操作”的流程。在这次 Claude Opus 4.5 的更新里,增强版的 Computer Use 能力终于支持了界面缩放,围绕这一能力可以让重新设计整套电脑操作 Agent 的工作流,实现更高的效率。
现在,Agent 可以先放大界面,再进行后续操作。对于需要检查细小 UI 元素和复杂控件的场景,这一点价值巨大。比如,一个面向前端工程师的设计检查 Agent,真的可以逐像素检查自己生成的页面。它能读小字号文本和密集说明文案,分析信息高度堆叠、结构复杂的界面,并在执行点击、跳转之前,先确认视觉细节是否正确。
无限对话(Infinite Chat)功能,破除长上下文限制
所谓「无限对话」(Infinite Chat),本质上是在解决长期存在的大模型上下文“断片”问题。在 Claude 3时代,很多重度用户在进行 vibe coding或长流程协作时,经常会遇到上下文不够用的情况。
到了 Claude Sonnet 4.5,Anthropic 做了一次明显的迭代。系统会在对话过程中,将历史交互自动压缩和总结,再把这份总结交给下一个接力的 Agent。不过,从评测视角来看,这种模式本质上仍然是“新 Agent 读一份摘要后从头接手”,而不是在同一条对话线上稳定演进。

Opus 4.5 的“无限对话”机制则进一步往前走了一步。Anthropic 在更新说明中提到,对于 Claude App 用户,长对话不会再硬撞上下文上限。当有需要时,Claude 会自动对较早的内容进行摘要与重写,以此腾出上下文空间,让同一条会话线程可以持续向前推进,而无需频繁新开对话或手动搬运历史记录。
从评测角度来看,这看似只是更新日志里的一小段描述,实际却有潜力成为改变产品形态的关键能力:对用户而言,长线项目(例如从零共建一个 App、持续打磨同一份文档、长期跟踪同一主题)的协作成本显著下降。对产品设计者和开发者而言,这为“把大模型真正当成持续在线的长期助手”提供了更扎实的基础。
在后续的实测与案例中,如果围绕一个真实的中长周期项目(例如从零设计与实现一款应用)进行连续对话,有望更直观地验证“无限对话“在记忆稳定性、语境连贯性和用户操作负担上的实际改善空间。
走向多模型共存时代:拼的是组合,而不是冠军
和 Opus 4.1 相比,Opus 4.5 基本上是一次巨大的飞跃。从公开的基准测试套件来看,它在绝大多数项目上都实现了明显提升,仅在研究生级推理、视觉推理和多语言问答这几个维度略有劣势。
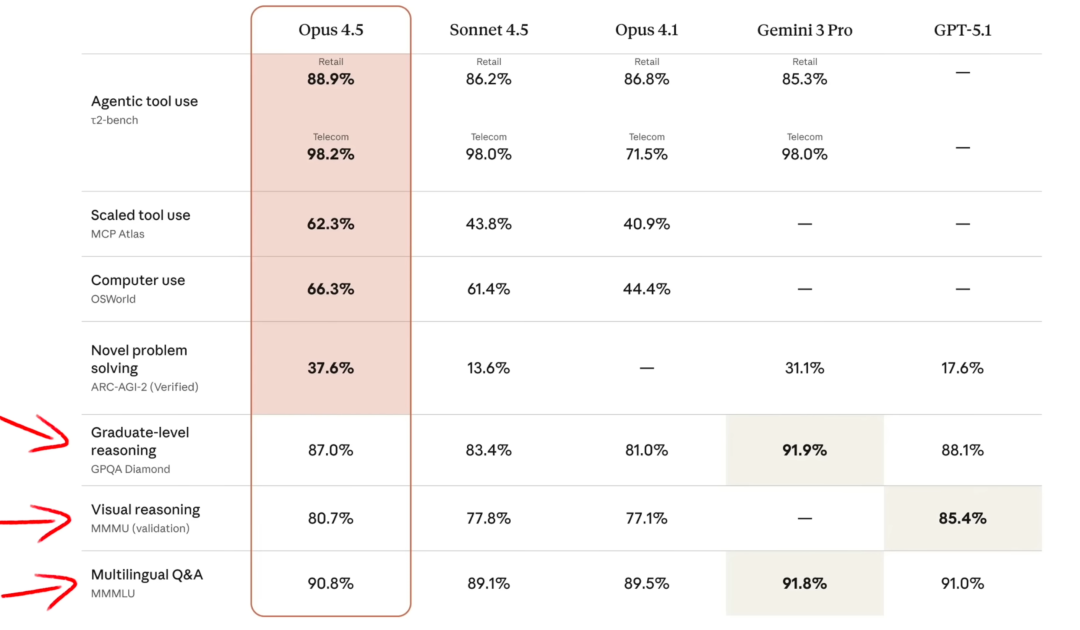
Claude 从来不是在所有维度上都是第一。它的传统优势一直在编码与工程类任务上,这也是 Anthropic 推出 Opus 4.5 的核心目标。把“AI 编码第一”的位置重新坐稳。相对而言,在复杂推理这条线上,Gemini 仍然保留了自己的高地。在研究生级推理基准上,Gemini 3 Pro 的得分约为 92%,在多语言问答任务中也依然是碾压级表现。于是当前的格局大致可以概括为一句话:Claude 仍是 AI 编码领域的王者,而 Gemini 则占据推理与多语言的高位。
从官方表述看,Claude.ai 的产品负责人 Scott White 将 Claude Opus 4.5 的理想用户画像指向专业软件开发者和知识工作者,例如金融分析师、顾问、会计师等。他同时强调,那些“渴望激发创造力、构建新事物、拓展自身专业边界”的用户,同样会从这一代模型中受益。Anthropic 也在博客中明确表示,新模型在处理电子表格、演示文稿等日常办公任务,以及执行深度研究方面都“有显著提升”。
在最近一轮面向开发者的大模型迭代中,厂商开始有意识地把写代码这件事,扩展为和你一起做项目。无论是 Anthropic 还是 OpenAI,新一代编程向模型都在强化三件事:能拆解复杂需求、能协调多个子 Agent 协同工作、能在较长的开发链路中保持上下文与进度不丢失。
Claude Opus 4.5 更像是一个新的标杆。模型不再只是在 IDE 里的补全代码工具,而是可以参与需求梳理、方案设计、实现与改动跟进的“共同开发者”。如果这种能力持续增强、推理成本继续下探,传统的软件生产流程(从任务分工到工具栈组合)很有可能会被重新设计一遍。
本文由人人都是产品经理作者【深思SenseAI】,微信公众号:【深思SenseAI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。





- 目前还没评论,等你发挥!


