
 起点课堂会员权益
起点课堂会员权益大模型改造传统车企智能客服:从RAG到Agent协同的完整实践
传统智能客服的困境正在被一场技术革命改写。当65%的准确率遇上用户飙升的负面情绪,车企如何通过RAG架构重构AI客服体系?本文深度拆解从知识检索到多Agent协同的完整技术路径,揭秘如何让大模型既不说谎又能执行复杂任务,最终实现NPS与CSAT的双重提升。

一、为什么传统智能客服正在”失效”?
一次被数据”打脸”的战略复盘
故事要从一次业务评审会说起。
此前,我们的客服体系是典型的”人工+小模型”模式:简单问题由基于关键词硬匹配的机器人处理,复杂问题转人工。听起来很美好,但现实很骨感——这个小模型的准确率不到65%。
更严峻的是,我们在智能客服系统上持续投入预算,但用户净推荐值NPS(Net Promoter Score)却长期不达预期。一线客服团队反馈,”机器人答非所问”的用户转人工量正在明显上升。
当我们认真复盘数据时,发现了一个恶性循环:
- 首次联系解决率FCR(First Contact Resolution)长期在低位徘徊。**这意味着大量用户的简单问题没被解决,反而因为糟糕的体验产生了新的负面情绪。
- 人工坐席的平均处理时长AHT(Average Handle Time)不降反升。**客服人员的时间大量消耗在安抚情绪,以及重复询问那些本该由机器人在第一步就收集好的基础信息上。
- 用户抱怨集中在几类场景:**服务权益政策的细节查询、车载系统特定功能的使用方法、新能源车的充电和续航焦虑等。这些问题的共同特点是“场景化”和“个性化”——早就超出了传统关键词匹配的能力范围。
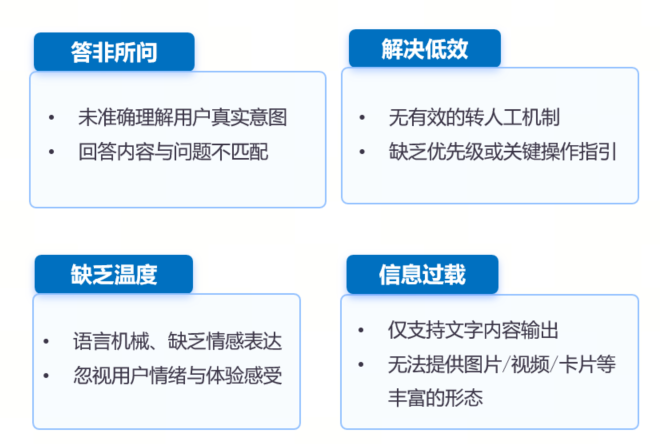
从这张痛点图可以看出,传统小模型面临的核心问题包括:
- 答非所问:未准确理解用户真实意图,回答内容与问题不匹配
- 解决低效:无有效的转人工机制,缺乏优先级或关键操作引导
- 缺乏温度:语言机械,缺乏情感表达,忽视用户情绪与体验感受
- 信息过载:仅支持文字内容输出,无法提供图片/视频/卡片等丰富的形态
这四大痛点,本质上是小模型”硬匹配”技术架构的必然结果。
目标重构:从”降本”到”体验提升”
我们意识到,问题的根源在于战略目标错位了。
过去的思路是”用机器人降本”,但现在必须转变为”用AI提升用户全生命周期价值(LTV)”。为此,我们为这个AI客服转型项目设立了全新的、可量化的目标体系:
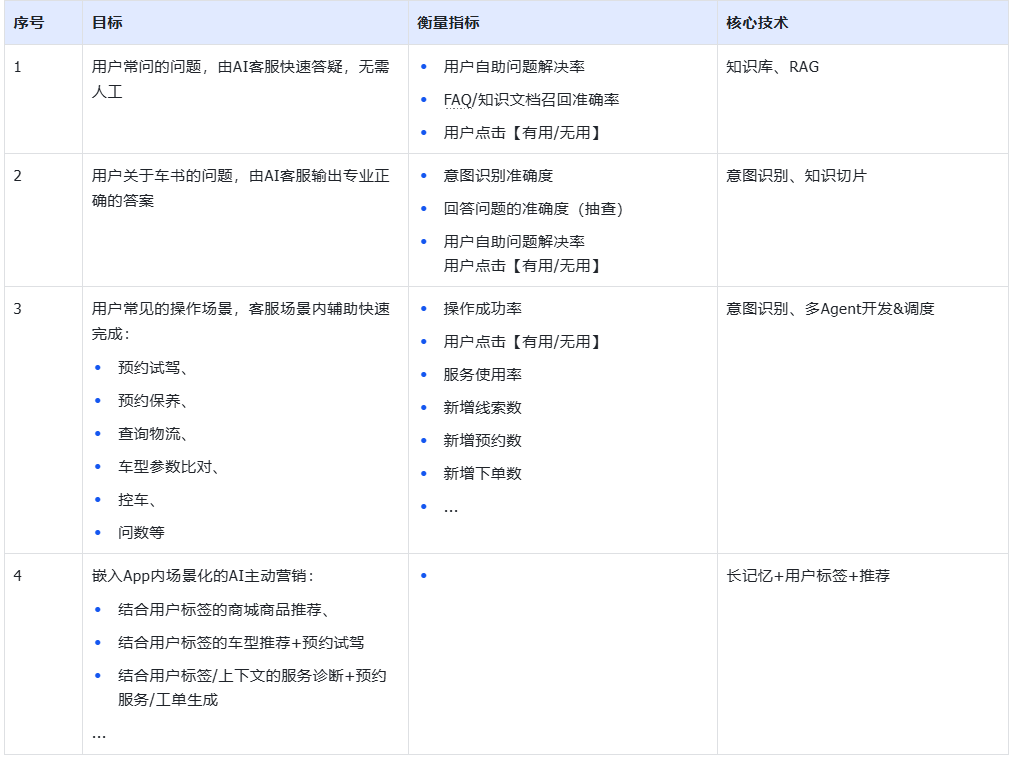
核心目标包括:
目标1:用户常问的问题,由AI客服快速答疑,无需人工
- 关键指标:用户自助问题解决率、FAQ/知识文档召回准确率、FCR(First Contact Resolution,首次联系解决率)
- 用户触点:有用/无用的反馈机制
- 核心技术:知识库、RAG
目标2:用户关于车书的问题,由AI客服输出专业/正确的答案
- 关键指标:意图识别准确度、回答问题的准确度(抽查)、用户自助问题解决率
- 核心技术:意图识别、知识切片
目标3:用户常见的操作场景,客服场景内辅助快速完成
包括预约试驾、预约保养、查询物流、车型参数比对、控车、问数等场景
- 关键指标:操作成功率、服务使用率、新增线索数、新增预约数、新增下单数、AHT(Average Handle Time,平均处理时长)降低率
- 核心技术:意图识别、多Agent开发&调度
目标4:嵌入App内场景化的AI主动营销
结合用户标签的商城商品推荐、车型推荐+预约试驾、服务诊断+预约服务/工单生成等
- 关键指标:NPS(Net Promoter Score,用户净推荐值)提升、CSAT(Customer Satisfaction,客户满意度)提升
- 核心技术:长记忆+用户标签+推荐
二、竞品分析:行业内的AI客服现状
在项目启动前,我们对汽车、金融、通信等行业的头部企业进行了系统调研。
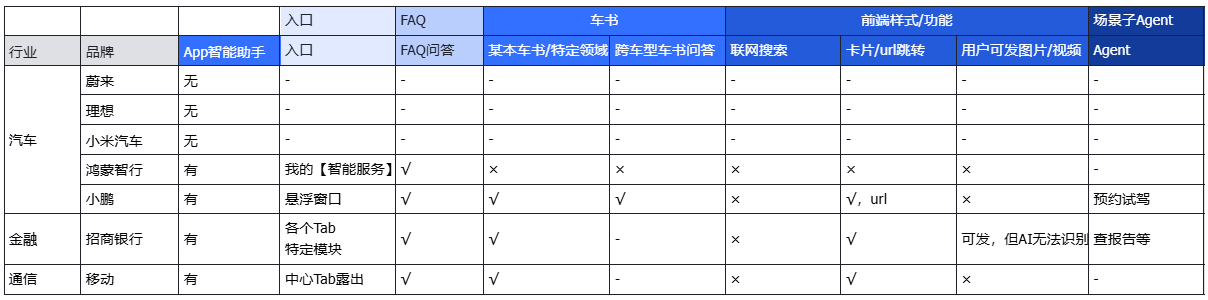
调研发现:
- 传统车企:大多数仍停留在关键词匹配阶段,智能客服功能缺失
- 新势力车企:部分已引入智能服务能力,但功能相对单一,主要集中在FAQ问答
- 金融行业:在智能客服领域相对成熟,已实现多种业务场景的Agent调用
- 通信行业:中国移动等已部署中心Tab露出,支持FAQ和跨域问答
这次调研让我们明确了几个关键洞察:
- 入口设计很重要:是悬浮入口、各tab特定入口,还是融入现有业务流程?
- 功能边界要清晰:从FAQ到车书,从问答到操作,需要分阶段规划
- 用户体验是核心:即便是AI,也要符合用户在该场景下的心智模型
三、技术方案:基于RAG构建”懂车”的私有知识大脑
面对”既要模型聪明、又要内容可控、还要数据安全”的三角难题,我们排除了直接调用公有云大模型API的方案——合规红线不容触碰。
最终选择了基于私有化部署大模型的RAG(检索增强生成)架构。简单说,就是为通用大模型外挂一个我们企业专属的、经过严格审核的”超级大脑”。
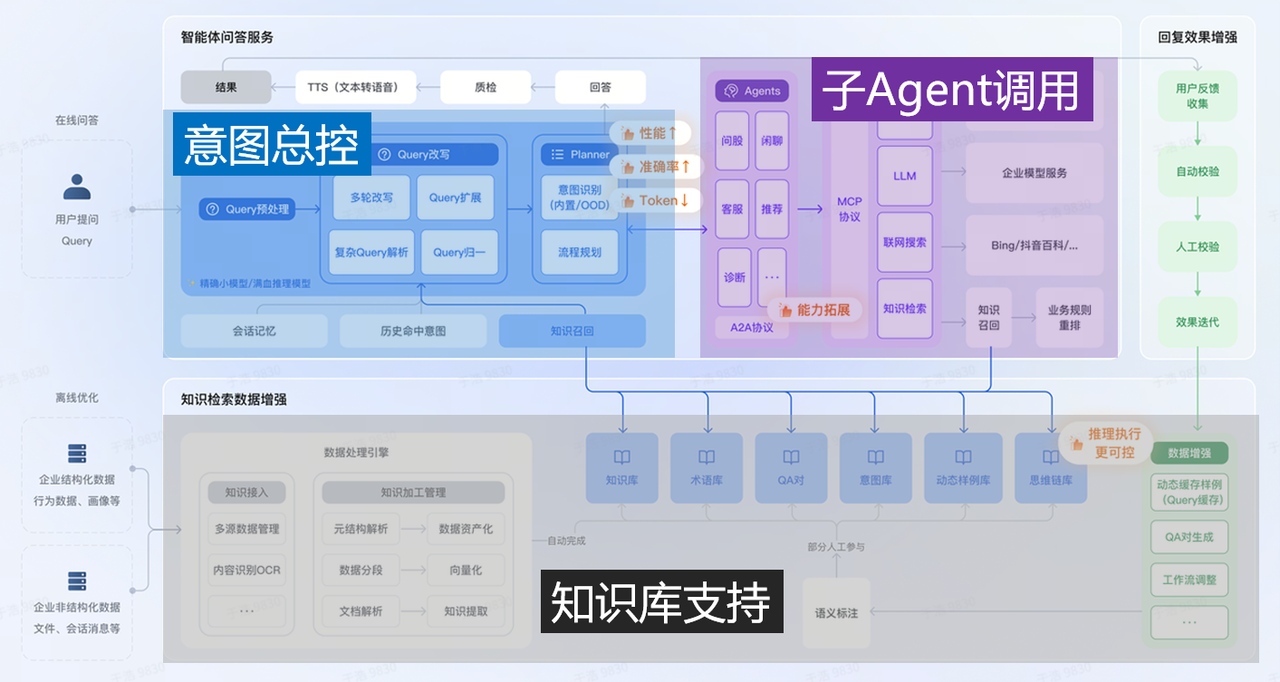
RAG架构的”三段式”设计
整个架构分为三个核心层:
底层:知识检索&数据增强
- 企业信息仓库(行业数据、高德等)
- 企业非结构化数据(文档、会话清单等)
- 支持多源数据管理、元数据抽取、文档分析、数据预处理/OCR、向量分段、同义化、知识提纯等
中层:意图总控(智能体问答服务)
- Query改写、多轮次对话、Query理解
- 复杂Query解析、Query归一
- 精准/增强/维护等策略管理
- 会话记忆、历史中间量、知识召回
上层:子Agent调用
- 问答、咨询、销售、服务等多个专业Agent
- LLM模型调度
- 联网搜索、知识体系等能力扩展
- A2A协议支撑Agent间协作
- 右侧形成完整的回复及埋点->自动校验->人工校验->效果迭代的闭环。
RAG架构的工程化实现
第一步:数据预处理与向量化
处理了数千份内部文档,包括PDF格式的《车书手册》、Word格式的《维修服务SOP》、Excel格式的《车型配置表》,以及大量营销政策公告。
第二步:知识检索
选择了开源的Milvus作为向量数据库进行私有化部署。关键的一步是,我们构建了结合传统关键词检索与向量检索的**混合检索(Hybrid Search)**系统。
第三步:内容生成
在生成环节,通过高度结构化的Prompt Engineering,将检索到的知识片段作为”上下文”注入提示词,要求模型”必须且只能依据以上信息回答问题”,从源头上遏制模型自由发挥。
V1.0上线:实现了哪些核心能力?
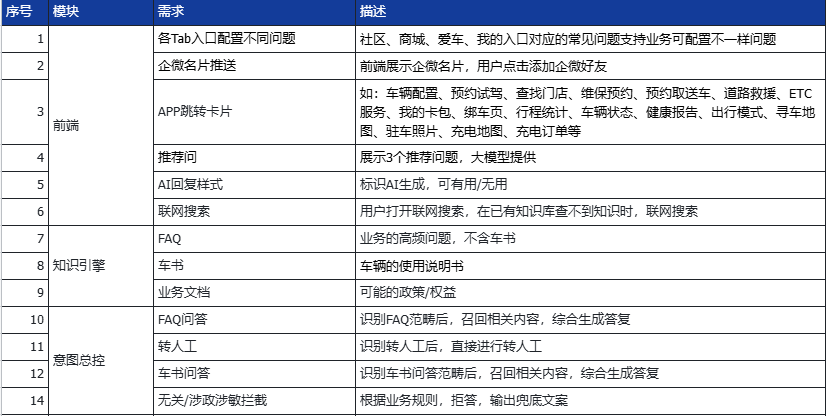
一期项目上线后,我们聚焦在”智能问答”这个核心场景,实现了以下功能模块:
1)前端交互优化
- 各Tab入口配置不同问题:社区、商域、客车、我的入口对应的常见问题支持业务可配置,让AI助手出现在用户最需要的场景中
- 企业名片推送:前端展示企业名片,用户点击添加经销商好友,基于FAQ/导购类的意图自动识别推荐时机
- APP跳转卡片:展示APP内可跳转页面功能卡片,需评估当前APP可提供哪些外链的功能。包括:车辆配置、预约试驾、查询门店、维保预约、预约取送车、道路救援、ETC服务、我的卡包、绑车页、行程统计、车辆状态、健康报告、出行模式、寻车地图、充电地图等
- 追加推荐问题:展示3个推荐问题,由大模型提供
- AI回复样式:标准AI生成,可有用/无用反馈机制
- 联网搜索:用户打开联网搜索后,在已有知识库查询不到知识时,联网搜索补充
2)知识引擎核心能力
- FAQ:识别业务的高频问题(不含车书)
- 知识引擎-车书:车书使用说明书。
- 知识引擎-业务文档:可部署的政策/权益文档
3)意图总控能力
- FAQ问答:识别FAQ范畴后,召回相关内容,综合生成答复
- 车书问答:识别车书问答范畴后,召回相关内容,综合生成答案
- 转人工:识别触发转人工相关场景后,直接进行转人工流程
- 无关/涉政涉敏数据管控:根据业务规则,拒答,输出底案文案
- 车控:车锁 、车窗 、寻车 、空调 、哨兵模式 、充电控制等简单操作的打开与关闭
这个MVP版本,我们刻意控制了范围——只做“问答”,不做“执行”。所有涉及业务流程闭环的功能(如预约试驾、控车、物流查询等),都留到了V2.0的Agent协同阶段。
这个策略让我们在3个月内完成了从0到1的上线,并通过真实用户数据验证了RAG架构的有效性。
四、核心难题:如何让模型不”一本正经胡说八道”?
“幻觉”是悬在所有大模型应用头上的达摩克利斯之剑。为此,我们设计了三重安全护栏:
- Grounding(事实锚定) 在技术层面,强制要求模型的每一个输出,都必须能找到RAG检索回的原文片段作为”证据”。如果检索结果为空,系统宁可回答”抱歉,我暂时无法回答这个问题”,也绝不自行编造。
- Citation(可信溯源) 这是Grounding机制在产品端的体现,确保了答案的”可解释性”和”可验证性”。每个回答都会标注来源,如车书问答,答案取自《用户手册》第87页,但是toC不一定露出。
- Guardrails(安全护栏) 额外部署了一套独立的内容审核模型。它像一个24小时在线的”政委”,对最终答案进行实时审查,一旦发现涉及危险驾驶引导、违规操作、或法律风险的言论,会立刻进行拦截和修正。
同时,在模型参数上,我们将Temperature值设定在较低水平,牺牲了语言的”趣味性”和”发散性”,换取回答的”高确定性”和”一致性”——这完全符合客服场景标准化的核心诉求。
五、能力跃迁:从”问答机”到”任务执行官”
V1.0上线后,核心指标得到了显著改善。但新的数据洞察浮出水面:
大量用户在得到“答案”后,会紧接着发出一个”指令”。
这驱动了我们项目的V2.0升级:从”信息提供”走向”任务执行”。
我们引入了多Agent协同架构。核心思想是将复杂的业务流程,拆解为由不同”专家”Agent来执行的原子任务。
子Agent场景设计

我们定义了多个核心Agent,覆盖了用户从售前到售后的完整旅程:
1.用户问数Agent
这是最容易被忽视,但技术挑战最大的Agent之一。
典型场景:
- “我的车还有多少电?”
- “我的订单什么时候到?”
- “我的积分还剩多少?”
- “我上个月开了多少公里?”
技术实现的核心挑战:
这类问题的特点是需要实时查询业务系统的动态数据,而不是从静态知识库中检索。如果让大模型自由发挥,100%会产生幻觉。
我们的解决方案是Function Calling + 严格的数据校验:
1)意图识别与参数提取
- Agent首先识别用户意图属于“问数”类型
- 提取关键参数:查询对象(车辆/订单/积分)、用户ID、VIN码等2)API调用而非生成
- Agent不生成答案,而是调用对应的业务系统API
- 车辆状态 → 调用TSP(车载信息服务平台)API
- 订单物流 → 调用电商/物流系统API
- 用户积分 → 调用会员系统API
3)结构化返回与自然语言包装
- API返回结构化数据(JSON格式)
- Agent将结构化数据转换为自然语言
- 例如:{“battery_level”: 68, “range”: 285} → “您的车辆当前电量68%,预计续航285公里”
4)多重校验机制
- 调用前校验:用户是否有权限查询该数据(是否为车主)
- 调用后校验:API返回是否成功,数据是否完整
- 超时处理:API响应超时时,返回“系统繁忙,请稍后再试”而非编造数据
2、预约试驾Agent
典型场景:
- “我想试驾你们的新款SUV,这周六有空吗?”
- “帮我预约一下市中心的门店”
技术实现:
这是典型的”多轮对话+业务流程编排”场景。
1)意图识别与信息收集
- 识别用户想要预约试驾
- 提取已有信息:车型、时间、地点
- 缺失信息主动询问:”请问您想试驾哪款车型?”2)调用DMS系统API
- 根据用户地理位置,查询附近经销商门店
- 根据车型和时间,查询试驾车可用性
- 查询销售顾问排班情况
3)推荐与确认
- 返回2-3个推荐选项(门店+时间+车型)
- 用户选择后,生成预约卡片
- 用户确认后,调用CRM系统创建线索
4)闭环反馈
- 返回预约确认信息(门店地址、联系电话、预约时间)
- 自动发送短信提醒
- 将线索数据回传到营销系统
5)防幻觉机制:
- 所有门店信息、车型库存、时间排期都来自API实时查询
- 不允许Agent推荐不存在的门店或车型
- 如果没有可用时段,明确告知并引导改期
3、商品推荐Agent
典型场景:
- 用户咨询:“夏天开车太晒了怎么办?”
- 系统推荐:车载遮阳帘、隔热膜服务等商城商品
技术实现:
这是”意图理解+推荐系统”的结合。
1)场景识别
- 识别用户描述的痛点场景
- 将自然语言转换为商品类目标签
- 例如:”太晒” → [“遮阳用品”, “隔热服务”, “车内降温”]
2)推荐策略
- 被动推荐:根据用户问题,从商品库中检索相关商品
- 主动推荐:在特定业务节点触发(如保养到期前推送保养套餐)
- 个性化推荐:结合用户标签(车型、购买历史、浏览记录)
3)调用商城系统API
- 查询商品详情、库存、价格、促销信息
- 生成商品卡片(图片+标题+价格+购买链接)
- 支持直接跳转到商城详情页
4)效果追踪
- 记录推荐点击率、转化率
- A/B测试不同的推荐策略
- 持续优化推荐算法
5)防幻觉机制:
- 只推荐商城系统中真实存在且有库存的商品
- 价格、促销信息实时从API获取,不允许编造
- 如果没有相关商品,诚实告知而非推荐无关产品
4、联网搜索Agent
典型场景:
- 用户询问最新的汽车政策、充电桩优惠等实时信息
- 内部知识库没有相关内容时触发
技术实现:
这是知识库的补充能力,处理超出企业内部知识范围的问题。
1)触发条件判断
- 优先从内部知识库检索
- 当知识库返回置信度低于阈值时,触发联网搜索
- 用户主动开启”联网搜索”模式2)搜索与筛选
- 调用搜索引擎API(如Bing、Google)
- 对搜索结果进行可信度评估
- 优先选择官方网站、权威媒体的内容
3)内容整合
- 提取搜索结果的关键信息
- 与内部知识进行对比验证
- 生成综合性回答并标注来源
4)风险控制
- 对联网内容进行内容审核
- 过滤虚假信息、违规内容
- 明确告知用户“以下信息来自互联网”
5)防幻觉机制:
- 必须引用真实的搜索结果,不允许无依据生成
- 每条信息都标注来源链接
- 对互联网信息保持审慎态度,提醒用户以官方为准
5、控车Agent
典型场景:
- “帮我把车里温度调到24度”
- “帮我开一下后备箱”
- “锁车门”
技术实现:
这是最敏感的Agent,涉及车辆安全,需要极其严格的权限控制。
1)身份认证与授权
验证用户是否为车主(通过VIN码绑定关系)
二次确认:敏感操作(如开车门)需要用户再次确认
地理位置校验:某些操作(如开车门)需要用户在车辆附近
2)意图识别与参数提取
- 识别控车类型:温度调节、车门控制、车窗控制、座椅加热等
- 提取参数:目标温度、开/关、前/后等
- 模糊指令处理:”打开空调”需要进一步询问目标温度
3)调用TSP平台API
- 将自然语言指令转换为标准API调用
- 例如:“温度调到24度” → {“action”: “set_temperature”, “value”: 24, “vin”: “xxx”}
- 等待API响应,确认操作是否成功
4)执行反馈
- 操作成功:明确告知“已为您将车内温度调至24度”
- 操作失败:说明失败原因(如车辆未联网、电量不足等)
- 显示当前车辆状态(温度、车门状态等)
5)防幻觉与安全机制:
- 绝对不允许虚假执行:如果API调用失败,必须如实告知,不能说”已完成”
- 危险操作二次确认:涉及车门、车窗等安全相关操作,必须二次确认
- 操作日志记录:所有控车操作记录日志,可追溯
- 异常熔断:连续失败或异常请求时,暂停控车功能并转人工
- 地理围栏:某些敏感操作需要验证用户是否在车辆附近(通过GPS)
V2.0上线:实现了哪些闭环能力?
基于Agent协同,我们上线了完整的任务闭环场景:

六、复盘总结:做 AI 产品,我们踩过的个大坑
回看整个项目,最宝贵的不是我们做对了什么,而是我们做错了什么。这些踩过的坑,可能比任何成功经验都更能帮大家少走弯路。
坑一:总想等一个“最终方案”,结果迟迟不敢动手
AI 这东西,技术一天一个样,模型、工具层出不穷。项目刚开始时,我们特别焦虑,总想看清楚全局,找到一个最完美、最先进、能一步到位的方案再开始。
- 当时的想法: “我们是不是再等等?下个季度可能就有更好的模型了。” “这个方案是不是不够全面?要不要再多规划几个版本?”
- 现实的毒打: 这种想法是做 AI 产品的大忌。你永远等不到所谓的“完美方案”。等你研究透了,风口都过去了。项目就这么在无休止的调研和规划里,差点被“拖死”。
- 后来的做法: 我们不再纠结于“终局”,而是定了一个简单的原则:先跑起来,用业务结果说话。
V1.0,目标非常纯粹:就做知识问答,把转人工率降下来。
V2.0,有了 V1.0 的成功和数据,我们才敢跟老板要更多资源,去做预约试驾这种更复杂的任务。
后面的 V3.0、V4.0,都是一步一个脚印,用上一个版本的成绩,换下一个版本的门票。
坑二:以为 AI 是神仙,结果发现主要工作是“喂数据”
很多人觉得 AI 很神奇,像个黑盒子,只要模型够强,什么问题都能解决。我们一开始也这么想,结果发现这是第二个大坑。
- 当时的想法: “我们用的是最新的开源模型,肯定很聪明。”
- 现实的毒打: 项目里最耗时间、最痛苦的工作,根本不是调模型,而是去处理各个业务部门扔过来的、乱七八糟的内部文档。AI 不是神仙,你喂给它垃圾,它只能吐出更“精致”的垃圾。
用户手册是扫描版的 PDF,得先做文字识别(OCR),格式还经常错乱。
维修流程(SOP)是 Word 文档,得手动把里面的步骤、规范给摘出来。
市场部的活动政策,三天两头变,还得专门做个时效管理。
意外的收获: 这个过程虽然痛苦,但有个意想不到的好处。为了让 AI “吃懂”这些资料,我们反过来逼着业务部门开始把自己的知识库整理得井井有条了。一个 AI 项目,竟然成了推动整个公司知识管理进步的催化剂。
本文由 @蔚见AI 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









目前在搞某个传统主机厂的售后业务转型,对文章观点深表赞同,受益颇多。
AI助力业务转型,重点其实不在AI,而在业务重塑。
越是经验丰富的业务专家,业务视角越受老业务系统的制约。
“项目里最耗时间、最痛苦的工作,根本不是调模型,而是去处理各个业务部门扔过来的、乱七八糟的内部文档。”
我自己的感觉,更痛苦的是在此之前,从第一性原则出发,带着各个业务专家一起打破老的流程边界和系统边界,回归‘解决问题’本身,而不是在老系统老流程上修修补补