
 起点课堂会员权益
起点课堂会员权益具身智能的“视界观”:AI视觉感知传感器全景解析
本文深入探讨了具身智能感知技术的多种传感器,包括单目视觉、双目视觉、结构光、ToF、激光雷达和事件相机等,分析了它们的技术原理、优缺点及应用场景,展望了未来具身智能感知系统的发展趋势。

1 具身感知
在讨论具体视觉传感器之前,先抛出一个问题:为什么具身智能的感知如此困难?
传统的工业机器人工作在结构化环境中,坐标是确定的,光照是恒定的。而具身智能面临的是充满不确定性的现实世界——强烈的阳光干扰、透明的玻璃幕墙、快速移动的行人以及纹理缺失的白墙。
1.1 从2D图像到3D语义的跨越
感知的本质是信息的重构。摄像头捕捉的是3D世界在2D平面上的投影,这个过程伴随着维度的丢失(深度信息消失)。感知的核心任务就是通过算法或主动探测手段,把这个丢失的Z轴找回来,并在此基础上叠加语义信息(这是杯子还是石头?)和时序信息(向左还是向右移动?)。
这一过程不仅依赖于传感器本身的性能(信噪比、动态范围),更依赖于后端算力的支撑。随着NVIDIA Orin等大算力芯片的普及,原本受限于计算瓶颈的算法(如OCC占用网络)得以在端侧实时运行,推动了感知技术的代际跃迁。
1.2 主动感知与被动感知的博弈
基于场景定义产品形态,首先要面对的决策是:主动感知(Active Sensing)vs被动感知(Passive Sensing)。
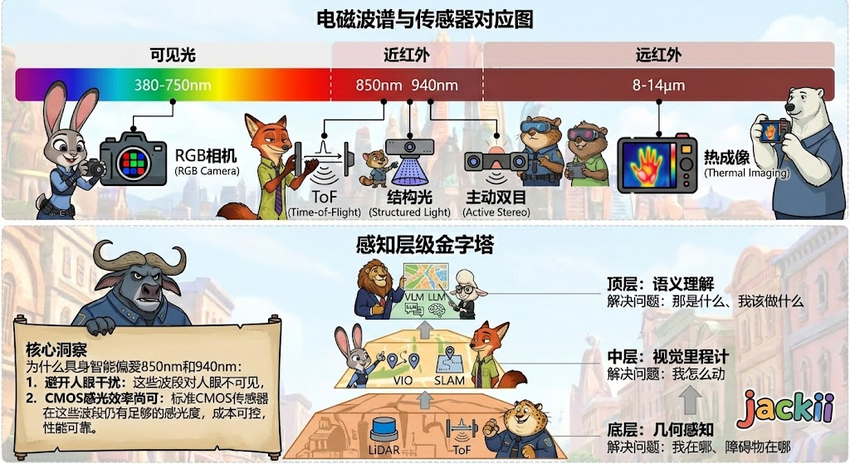
- 被动感知(如单目、双目):像人眼一样,不发射能量,仅接收环境光。隐蔽性好,功耗低,无多机干扰,但极度依赖环境光照和纹理。
- 主动感知(如LiDAR、ToF、结构光):像蝙蝠一样,向环境发射能量(激光、红外光)并接收回波。精度高,不受光照影响(除非阳光过强导致饱和),但存在功耗高、多机干扰和材质吸收问题。
2 单目视觉
单目视觉是目前最具争议也最具潜力的技术路线。以Tesla为代表的“纯视觉派”从第一性角度认为,既然人类靠双眼(实际上大部分时间靠大脑对单眼信息的脑补)能开车,机器人也应该可以。
2.1 技术原理
传统的单目测距极其困难,因为一张照片中,近处的小车和远处的大车可能占据相同的像素面积(尺度模糊性)。
现代单目视觉不再依赖几何计算,而是依赖数据驱动的先验知识。
- 自监督学习:利用视频序列中的帧间运动作为监督信号。如果一个物体在相邻帧中移动得快,它离得近;移动得慢,离得远。神经网络通过数亿帧的视频训练,学会了这种“直觉”。
- BEV变换:将前视摄像头的透视图像,通过Transformer模型投影到俯视的3D空间坐标系中。这是实现自动驾驶和机器人路径规划的关键步骤。
2.2 核心算法:Occupancy Network
Tesla的Occupancy Network(占用网络),这是目前单目视觉的巅峰之作。
- 体素化:将机器人周围的空间切割成无数个微小的立方体(Voxel)。
- 状态预测:网络不输出“这里有辆车”,而是输出每个体素的“占用概率”和“语义标签”。
- 优势:它可以识别训练集中从未见过的异形障碍物(如侧翻的卡车、散落的石块),这是传统目标检测算法无法做到的。

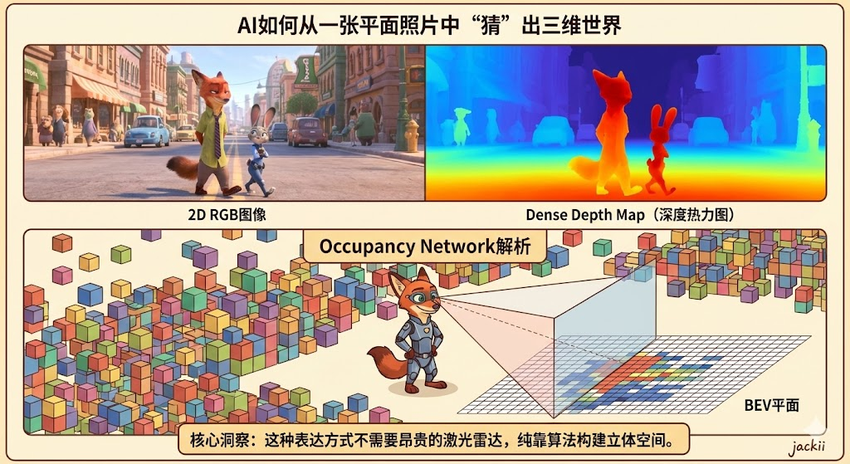
通过稠密的空间体素占用确定感知结果,为预测和规划提供更加准备的条件。
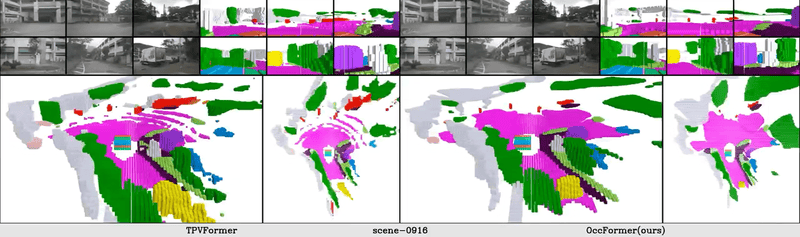
2.3 硬件选型与工程挑战
- 传感器:通常选用高动态范围的CMOS以应对隧道出口或逆光场景。
- 视场角 (FoV):往往需要鱼眼(Fisheye)与长焦(Narrow)组合。接近量产的Tesla Optimus 3.0应该就是采用和cybercab前后周视和后视这五个摄像头一样的摄像头。共5个摄像头,前面2个,侧向2,正后1个。
- 算力门槛:单目视觉是“硬件省钱,软件烧钱”。它需要极高的端侧推理算力来运行巨大的Transformer模型,否则延迟会高到无法接受。
3 结构光:工业级的毫米精度
如果说单目是“脑补”,双目就是“几何”。它是目前最具性价比、最成熟的近场深度感知方案,广泛应用于无人机、扫地机器人以及波士顿动力Spot。
3.1 技术原理:三角测距的几何美学
双目相机模仿人眼,利用两个平行放置的摄像头之间的视差来计算深度。
3.2 极线矫正与立体匹配
双目的核心难点在于立体匹配——要在左图中找到一个点,然后在右图中找到完全相同的那个点。
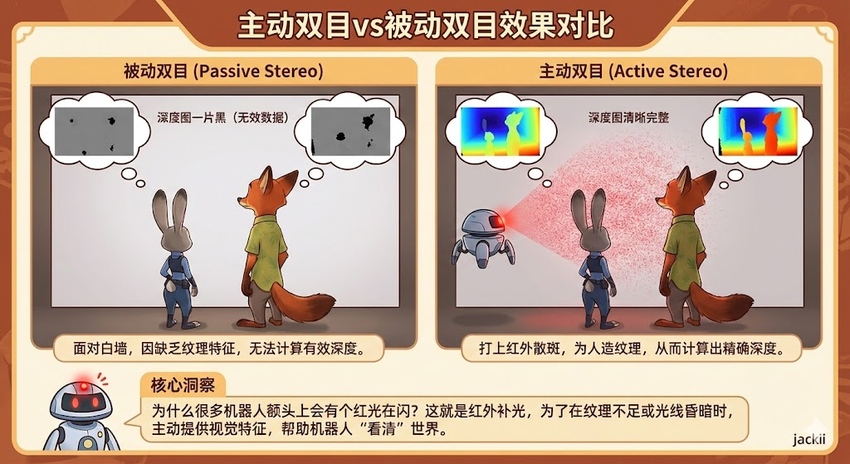
被动双目 (Passive Stereo):纯靠图像纹理。
死穴:遇到白墙(无纹理)或重复纹理(瓷砖地、绿草地),算法无法匹配,深度图会出现空洞。
主动双目 (Active Stereo):为了解决白墙问题,在两个摄像头中间加一个红外投影仪,向墙面打上伪随机散斑。这样即使是白墙也有了“人造纹理”。
4 结构光:工业级的毫米精度
结构光是3D感知的“显微镜”,它在近距离(<1.5米)拥有无与伦比的精度,是机械臂抓取和FaceID人脸识别的首选。
4.1 技术原理:编码光场的形变
结构光不依赖两个摄像头找不同,而是通过一个投影仪投射特定的编码图案,再用一个摄像头拍摄图案在物体表面的形变。
- 格雷码 (Gray Code):投射一系列黑白相间的条纹。精度高,鲁棒性好,但需要连续投射多帧图像,因此只能测静止物体。
- 相移法 (Phase Shift):投射正弦波条纹,通过相位的偏移计算深度。精度可达微米级,但同样怕动。
- MEMS散斑 (Speckle):如第一代Kinect和iPhone前置。投射数万个离散光点。只需要一帧图像,适合动态场景,但精度略低于条纹法。

4.2 致命弱点与应用局限
结构光是典型的“室内温室花朵”。
- 阳光致盲:室外阳光中的红外成分远强于投影仪的功率,会瞬间淹没编码图案,导致室外完全失效。
- 距离限制:光能随距离衰减,超过2米后信噪比急剧下降。
- 多机干扰:两个机器人的结构光投影仪如果照在一起,图案会互相干扰,导致谁也算不准。
4.3 具身智能中的应用
在人形机器人中,结构光通常安装在手腕处 (Eye-in-Hand)。当机器人伸手去抓一个反光的螺丝钉,头部的相机可能看不清细节,但手腕上的结构光可以提供亚毫米级的操作引导。
5 ToF:光速的测量艺术
ToF(飞行时间)技术是近年来增长最快的领域,得益于苹果在iPad/iPhone Pro上的引入,ToF已经从工业神坛走向了消费电子。但“ToF”是一个大筐,里面装了两种截然不同的物理原理:iToF和dToF。
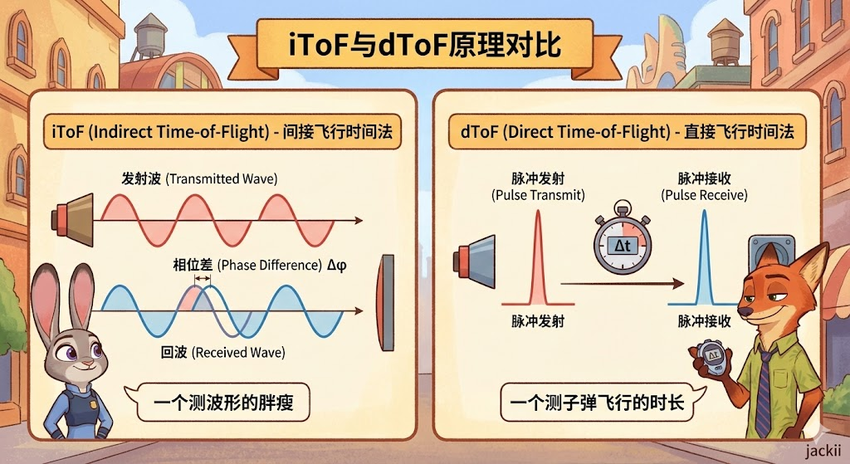
5.1 iToF (Indirect ToF):相位的游戏
iToF并不直接掐表测量时间,而是发射连续的调制光波(如正弦波),测量回波与发射波之间的相位差 (Phase Shift)。
优点:使用标准的CMOS工艺即可制造,分辨率可以做得很高(如VGA、百万像素),成本相对较低。
缺点:
- 相位模糊:就像时钟转了一圈回到原点,如果物体距离超过了调制波长(例如5米),相位会发生卷绕(Wrapping),导致5.1米被误判为0.1米。
- 多径干扰:光线打到墙角反弹多次回到传感器,会导致测量出的角落是圆角的,这对机器人沿墙走是致命的误差。
5.2 dToF (Direct ToF):光子秒表
dToF是真正的“掐表计时”。它发射极短的激光脉冲(纳秒级),利用SPAD(单光子雪崩二极管)捕捉反射回来的第一个光子,直接计算。
优点:
- 抗干扰强:脉冲能量极其集中,能穿透阳光。
- 无模糊距离:测到多少就是多少,没有相位卷绕。
- 低功耗:激光器大部分时间在休息。
技术突破:以前dToF很难做高分辨率,但随着Sony等厂商攻克了SPAD阵列堆叠技术,现在已经有了几万像素的dToF传感器(如iPhone LiDAR)。
5.3 选型指南:iToF vs dToF
- 选iToF:如果你需要近距离(<5米)的高分辨率3D建模,且主要在室内使用(如扫地机避障)。
- 选dToF:如果你需要中远距离(>5米),或者经常在室外工作,或者需要极低的功耗(如无人机定高)。
6 激光雷达 (LiDAR):构建上帝视角
激光雷达本质上是dToF技术在空间上的扫描延伸。它是所有传感器中真值属性最强的——无论算法多烂,激光雷达扫到的墙一定就在那里,不会像视觉那样把白墙看成无限远。
6.1 技术演进:从机械旋转到固态芯片
LiDAR是目前硬件迭代最激烈的战场,存在多条技术路线博弈。
机械旋转式 (Mechanical)
- 形态:经典的“全家桶”,头部360度旋转。
- 原理:垂直排列多束激光器,通过马达带动整体旋转进行扫描。
- 局限:成本高昂,机械部件寿命短,体积大,难以集成进人形机器人的体内。目前正逐渐被边缘化,主要用于Robotaxi开发验证。
混合固态 (MEMS/转镜)
- 形态:只有内部微小的镜面在动,外观不动。
- 原理:利用MEMS微振镜反射激光束进行扫描。
- 优势:车规级可靠性,成本可控,体积小。是目前Unitree B2、CyberDog 2等高端四足机器人的首选。
- 视场角限制:通常只有120°的前向视角,不像机械式那样自带360°。因此机器人通常需要前后各装一个,甚至侧面也要装。
纯固态 (Flash/OPA)
- Flash LiDAR:就像拍照一样,一次闪光照亮全场,用SPAD面阵接收。完全无运动部件,极其耐造。但受限于功率密度,目前探测距离较短(<50米),常作为补盲雷达。
- OPA (光学相控阵):利用硅光芯片调节光波相位来改变光束方向,是LiDAR的终极形态(类似相控阵雷达)。目前仍处于实验室阶段,良率和旁瓣干扰是难题。
6.2 波长之争:905nm vs 1550nm
- 905nm:硅基探测器,成本低,产业链成熟。但为了人眼安全(不烧伤视网膜),发射功率受限,探测距离难做远。
- 1550nm:铟镓砷(InGaAs)探测器,成本极高。但该波长会被人眼角膜吸收,不伤视网膜,因此可以肆无忌惮地加大功率,看透雨雾和长距离(>250米)。
6.3 3D点云与SLAM
LiDAR输出的是点云 (Point Cloud)——数百万个(x,y,z,反射率)坐标点。
- LOAM/LIO-SAM算法:机器人利用点云进行SLAM(即时定位与建图),精度可达厘米级。这是视觉SLAM(VSLAM)难以比拟的稳定性。
- 痛点:点云数据稀疏,缺乏颜色和纹理。虽然知道前面有个物体,但很难知道它是纸箱还是石头。

7 事件相机:神经形态的毫秒级反应
如果说前面的传感器都在模仿“眼睛的结构”,事件相机模仿的是视网膜的神经元机制。这是一个可能颠覆未来5年机器视觉的黑科技。
7.1 技术原理:只关注变化
传统相机不管画面动不动,都按30fps傻傻地拍照。事件相机(Event Cameras)的每个像素都是独立的神经元。只有当光照强度变化超过阈值时,该像素才会被激活,发送一个信号(Event)。
- 输出:不是图像,而是连续的事件流,其中是微秒级的时间戳,是极性(变亮还是变暗)。
7.2 降维打击的优势
- 极低延迟:响应速度是微秒级的(<1ms),比传统相机快100倍以上。非常适合捕捉高速运动(如接球、躲避飞来的物体)。
- 超高动态范围 (HDR):>120dB。能同时看清隧道内的黑暗和出口的强光,这对于机器人进出室内外至关重要(40)。
- 无运动模糊:因为没有“曝光时间”的概念,高速旋转的扇叶也能看得清清楚楚。
7.3 应用困境
虽然物理性能无敌,但算法太难了。现有的CNN、Transformer都是为帧图像设计的,无法直接处理异步的事件流。目前主要用于极速避障和视觉伺服,尚未成为主摄。

8 未来趋势预测
具身智能的视觉感知,本质上是在用硅基的材料去逼近碳基的奇迹。
在这个技术爆炸的时代,没有最完美的传感器,只有最适合场景的感知组合。站在2025年的节点,具身智能的感知系统正处于收敛的前夜,做一下预测:
- LiDAR的退守与进化:随着视觉算法的进步,高线束机械LiDAR将彻底退出人形机器人市场。取而代之的是低成本、芯片化的固态LiDAR(Flash/OPA)。
- 端到端感知的崛起:传统的“感知-规划-控制”模块化架构正在瓦解。未来的传感器数据可能不再生成点云或地图,而是直接输入到端到端大模型(E2E Model),直接输出电机扭矩。
- 事件相机的爆发:随着机器人运动能力的提升(跑酷、接飞盘),传统相机的帧率将成为瓶颈,事件相机必将成为高性能机器人的标配。
注:本文引用的数据和参数基于2024-2025年的行业公开资料及技术白皮书。
本文由 @杰克说AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


