
 起点课堂会员权益
起点课堂会员权益GPT-5.2 发布:信息全整理
GPT-5.2的发布标志着AI能力的又一次飞跃,三个版本各有所长:Instant快如闪电,Thinking专攻深度任务,Pro版则是解决难题的终极武器。在AIME 2025斩获满分、GDPval测试中74.1%任务超越人类专家,这款模型不仅在代码、长文档处理上大幅提升,更以11倍于人类的速度重塑工作流程。价格虽涨40%,但效率提升让总成本更低。

刚刚,GPT-5.2 来了,包含三个版本
- GPT-5.2 Instant:日常对话,快
- GPT-5.2 Thinking:深度任务,代码、长文档、数学、规划
- GPT-5.2Pro:最强,适合难题,愿意等
模型肯定是更强的,比如在AIME 2025 中取得满分,在 ARC-AGI-2 上拿到了 52.9%(和 Gemini3 相当)
今天开始向付费用户推送,API 已上线,标准版比 GPT-5.1 贵 40%

GPT-5.2
核心评测
如下图所示,是 GPT-5.2 的相关核心数据

GPT-5.2 Benchmark
注意:
- AIME 2025 满分(无工具)
- GPT-5.2 Pro 在 ARC-AGI-1 上达到 90.5%,是第一个突破 90% 的模型
- ARC-AGI-2 从 17.6% 到 52.9%,翻了三倍
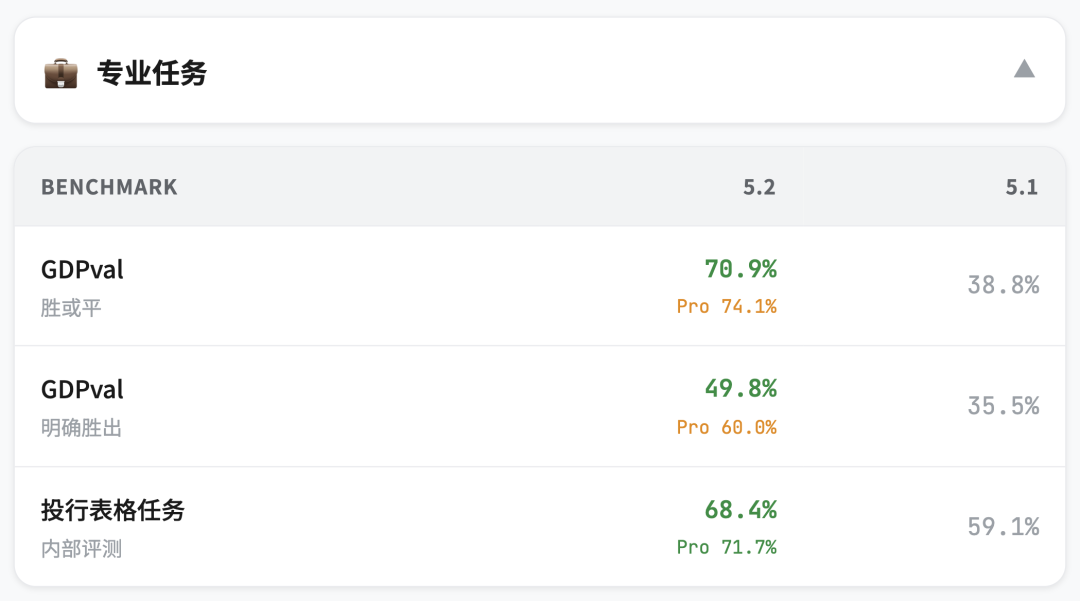
处理真实工作
GDPval是 OpenAI 新出的 benchmark
测的是 44 个职业的真实工作任务: 做 PPT、做表格、写分析报告
GPT-5.2 Thinking 在 70.9% 的任务上胜过或打平行业专家,GPT-5.2 Pro 更高,达到了74.1%
GDPval 知识工作速度是人类专家的11倍,成本不到 1%
一个评审员的评价:
「看起来像是一个有员工的专业公司做的,布局和建议都很专业,虽然还有一些小错误需要修正」
在投行分析师的表格建模任务上:
比如给 Fortune 500 公司做三表模型、做 LBO 模型,平均分从 59.1% 提升到 68.4%
官方放了几个对比
GPT-5.2 做的表格和 PPT 比 GPT-5.1 精细很多

Workforce Planner 对比,左边 GPT-5.1,右边 GPT-5.2
要用这个功能,需要付费版(Plus、Pro、Business、Enterprise),选 GPT-5.2 Thinking 或 Pro
复杂任务可能要跑好几分钟
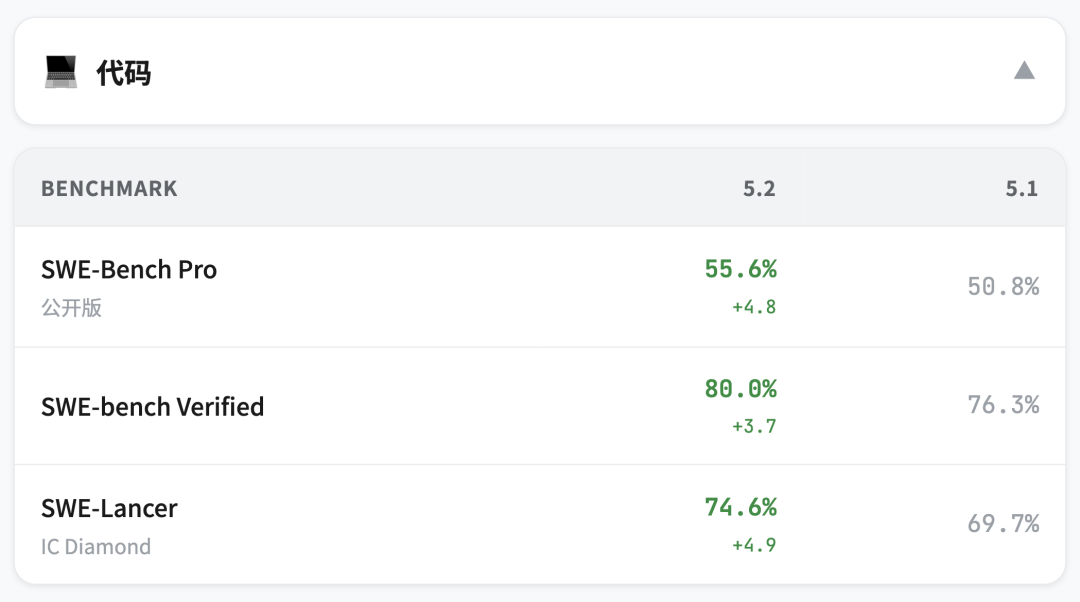
写代码
SWE-Bench Pro 是新的代码 benchmark,比 SWE-bench Verified 更难
测四种语言,不只是 Python,更接近真实软件工程
GPT-5.2 Thinking 55.6%,GPT-5.1 是 50.8%
SWE-Bench Pro
前端能力也提升了,尤其是 3D 和复杂 UI
官方放了几个 demo,单 prompt 生成的

海浪模拟,单 prompt 生成
对此,Windsurf的 CEO 表示 「这是 GPT-5 以来 agentic coding 最大的跃升,版本号的小幅升级低估了智能的大幅提升。我们会把它设为 Windsurf 和 Devin 核心工作流的默认模型」
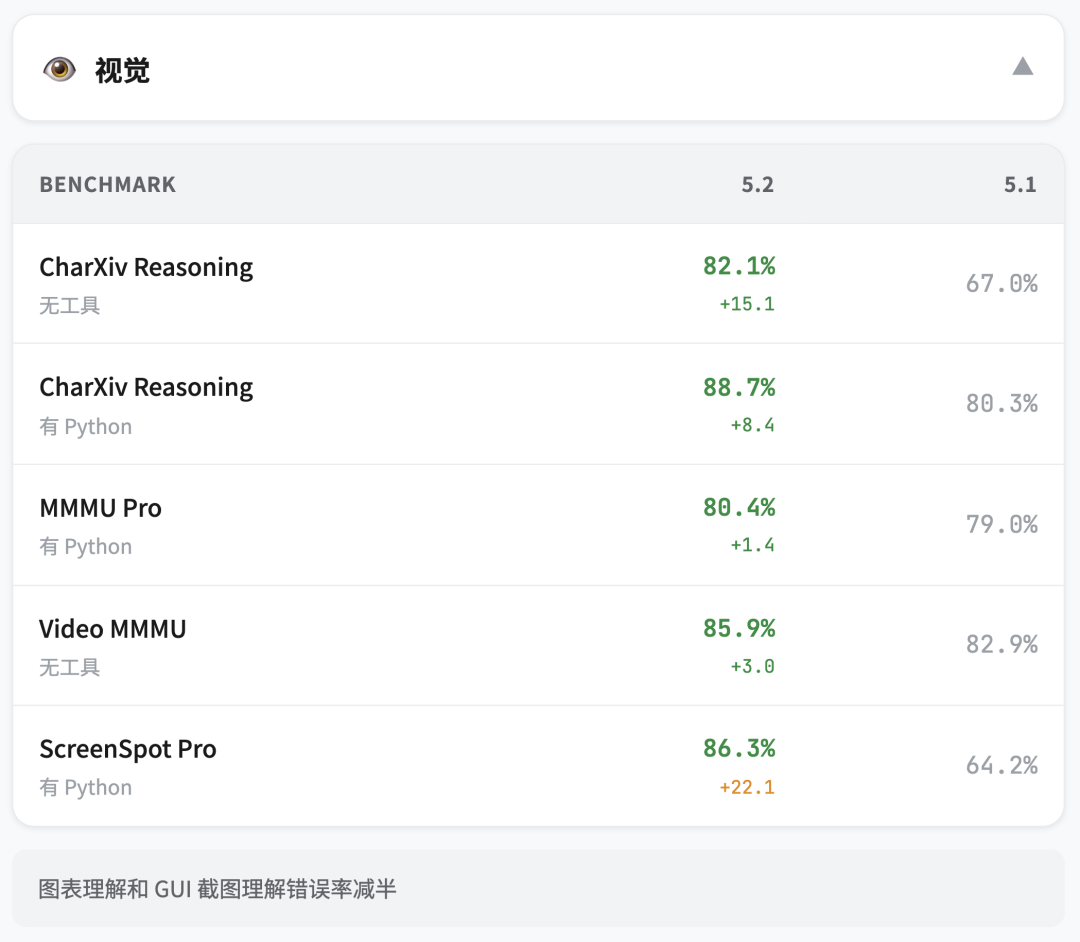
看图
视觉能力提升明显,错误率基本减半
CharXiv Reasoning
CharXiv Reasoning:科学论文图表问答,88.7%,GPT-5.1 是 80.3%
ScreenSpot-Pro,GUI 截图理解,86.3%,GPT-5.1 是 64.2%
此外,一个很明显的区别是:空间位置理解更强了 官方放了个主板识别的对比:给一张低质量的主板图片,让模型标注各个组件的位置
GPT-5.1 只能标几个,位置也不太对

GPT-5.1 主板识别
GPT-5.2 能准确标注各个组件,位置基本对
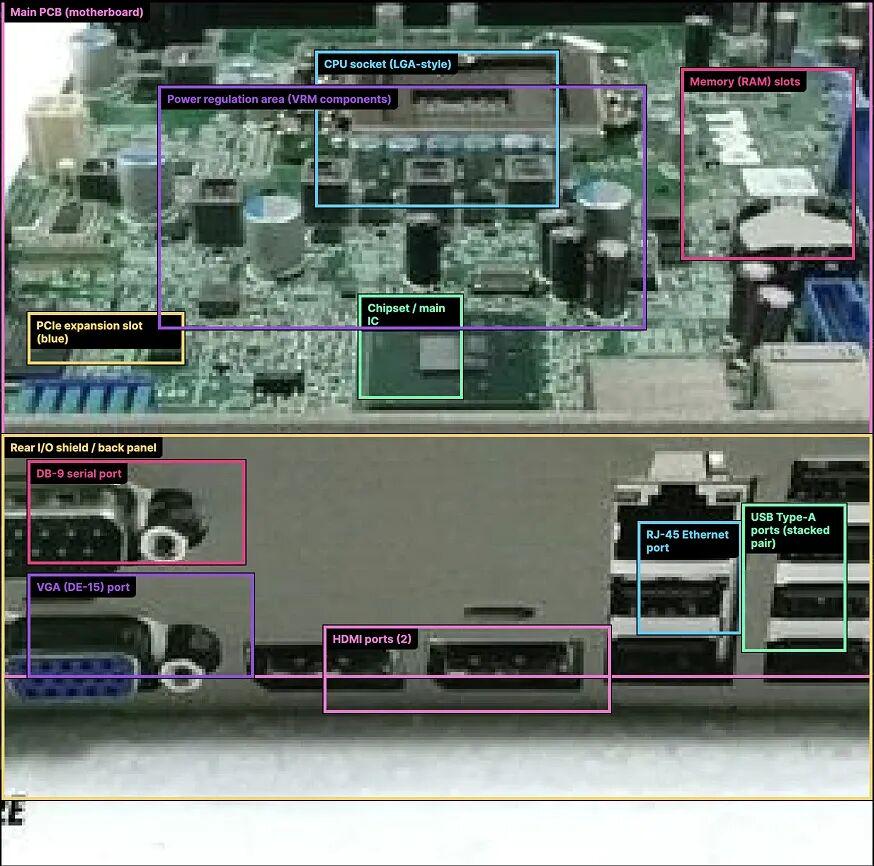
GPT-5.2 主板识别
长文档
OpenAI MRCRv2,测的是长文档中多个信息点的整合能力
在文档里插入多个相同的「针/needl」,然后问模型第 n 个针的内容是什么
4 needle 变体,GPT-5.2 Thinking 在 256k token 长度接近 100%,GPT-5.1 在同样长度只有 30% 左右。这是第一个在 4-needle 变体上达到接近 100%(256k)的模型。
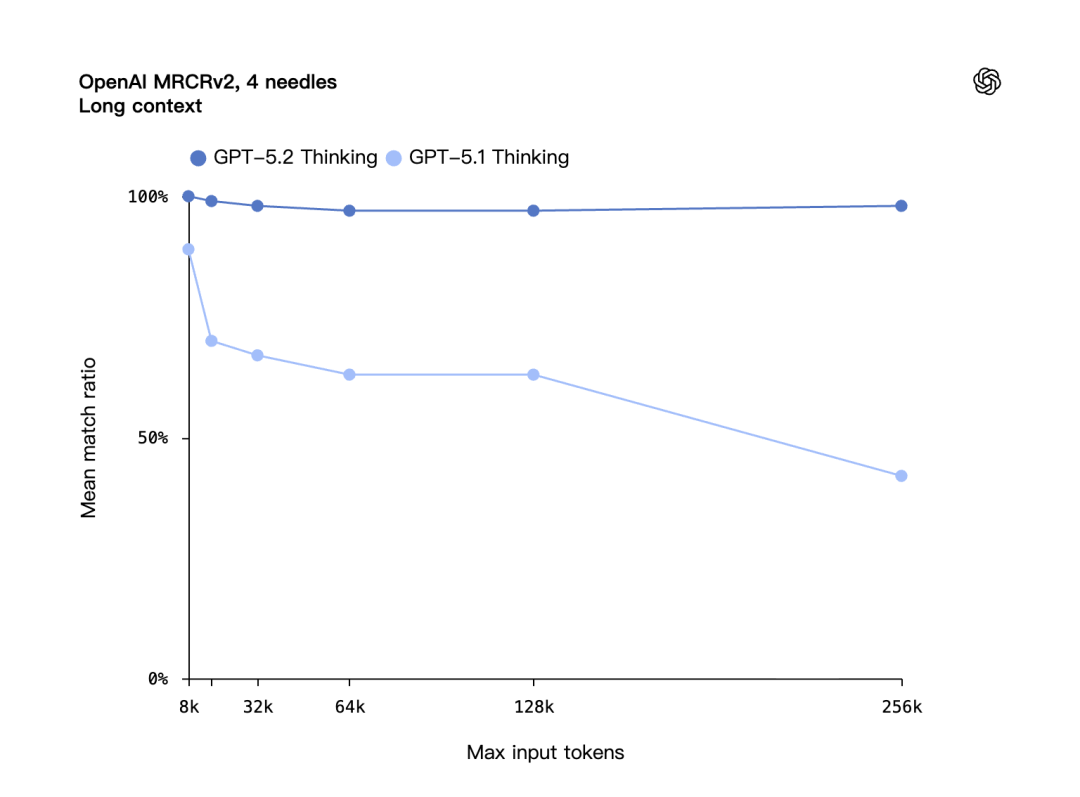
长上下文 4 needles
8 needle 更难,GPT-5.2 也有显著提升

长上下文 8 needles
API 还支持新的/compact端点,可以扩展有效上下文窗口,适合工具多、跑得久的任务
工具调用
Tau2-bench 测的是多轮对话中的工具使用,模拟客服场景
Telecom 领域,GPT-5.2 Thinking 98.7%,GPT-5.1 是 95.6%
Retail 领域,82.0%,GPT-5.1 是 77.9%
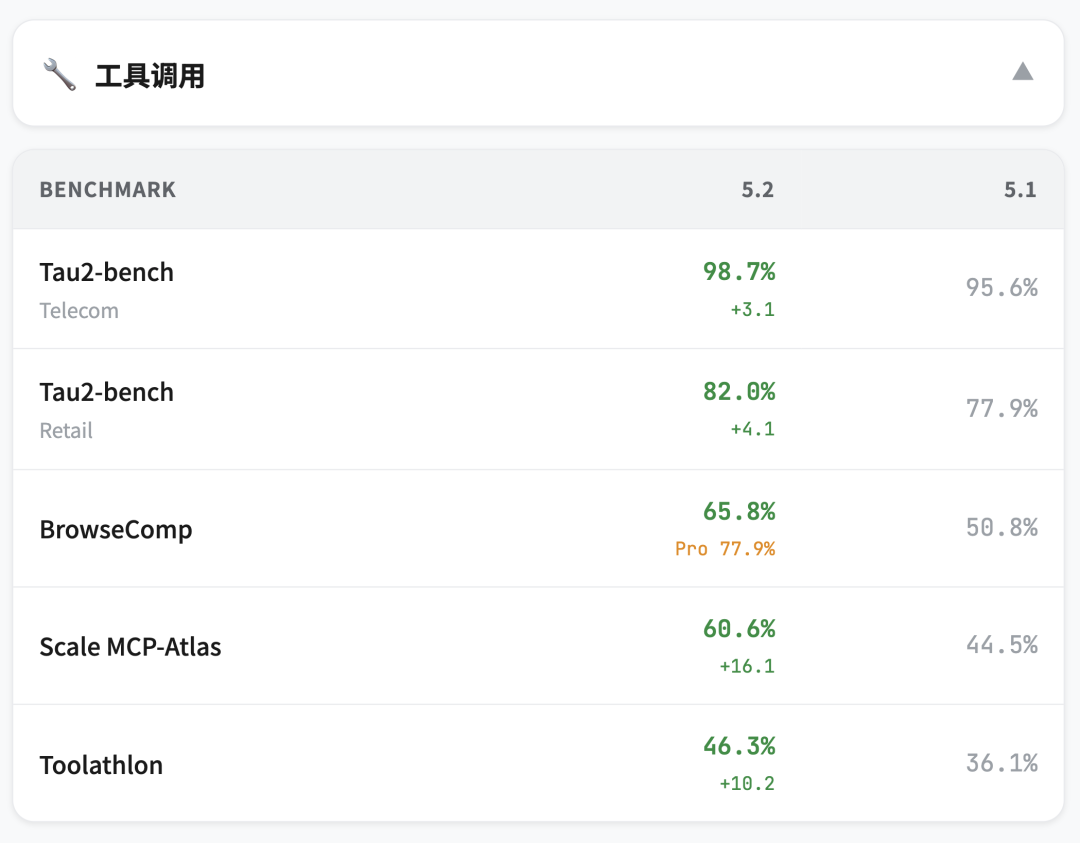
工具调用
官方举了个例子 用户说:我从巴黎飞纽约的航班延误了,错过了转机去奥斯汀,行李也丢了,需要在纽约过夜,还有医疗原因需要前排座位
GPT-5.1 漏了好几步
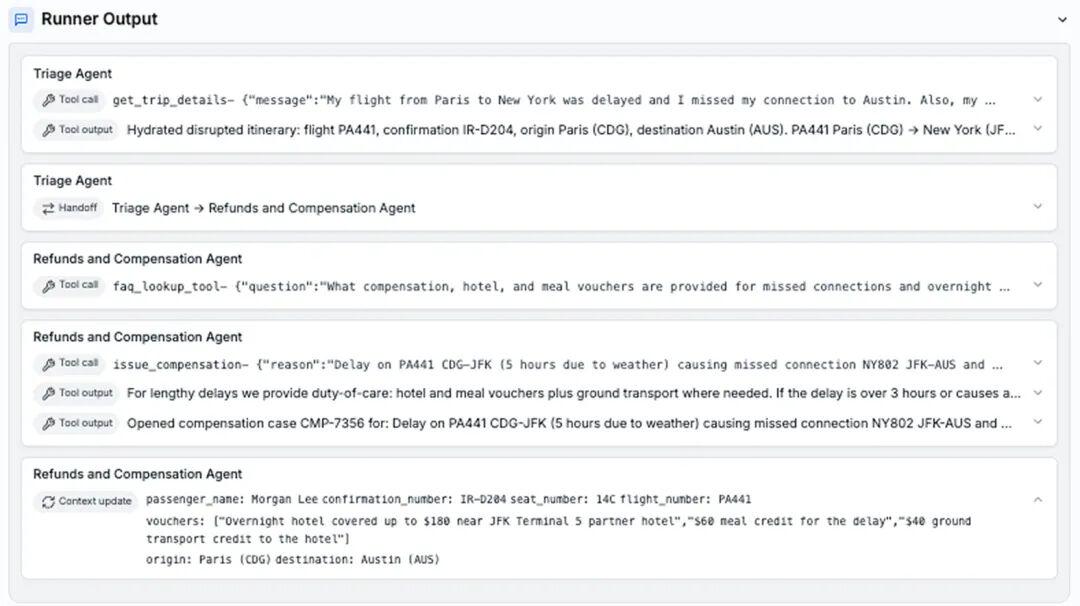
GPT-5.1 工具调用
GPT-5.2 一次性处理完:改签、特殊座位、赔偿,全部搞定
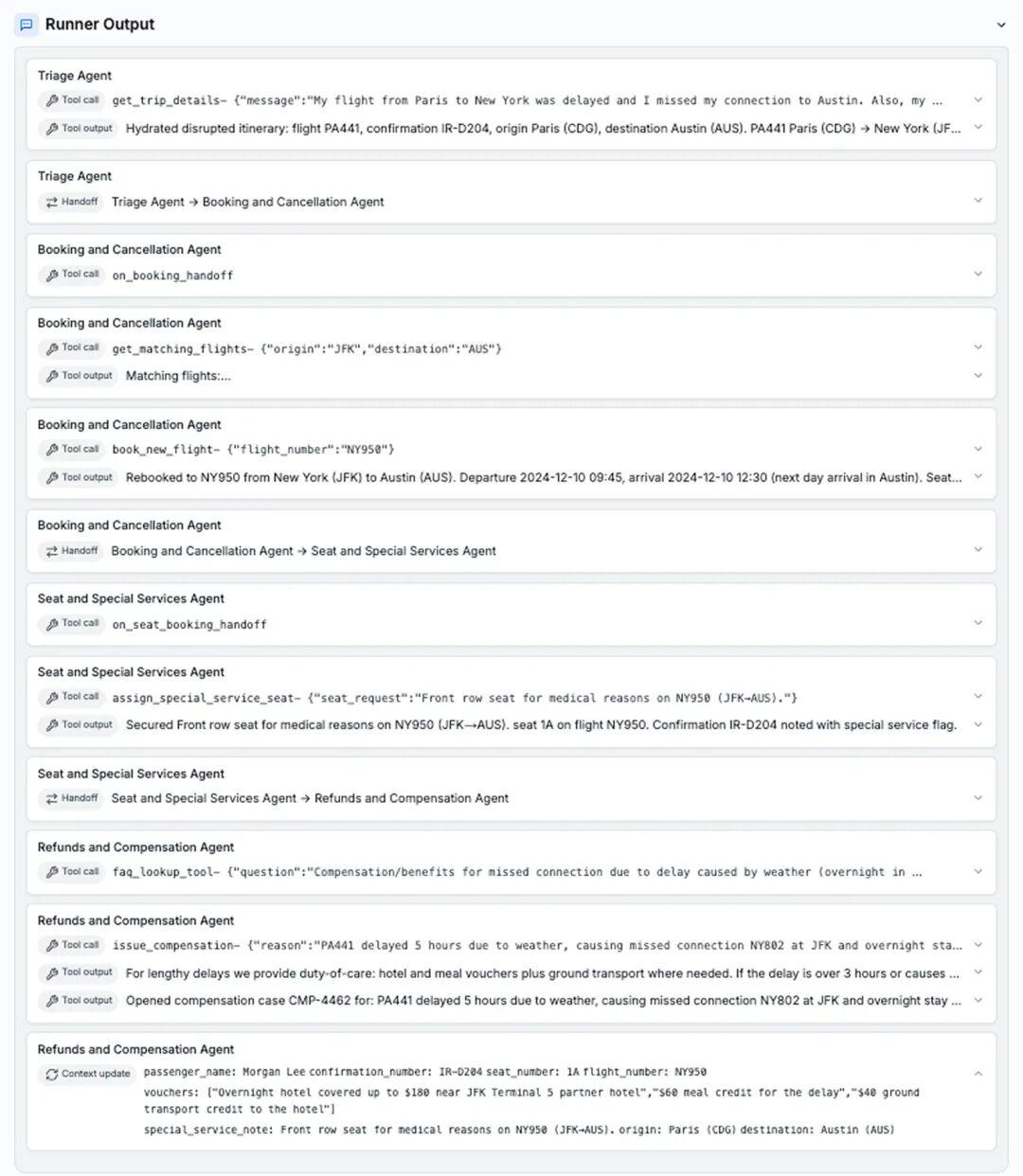
GPT-5.2 工具调用
数学和科学
AIME 2025 100%,满分,无工具 HMMT 2025 年 2 月 99.4%,Pro 版 100% GPQA Diamond 92.4%,Pro 版 93.2% FrontierMath Tier 1-3 40.3%,Tier 4 14.6% HLE(Humanity’s Last Exam)34.5%(无工具),45.5%(有工具)

数学&科学
ARC-AGI 是测抽象推理的
ARC-AGI-1,GPT-5.2 Thinking 86.2%,Pro 版 90.5%,第一个突破 90%
ARC-AGI-2 更难,GPT-5.2 Thinking 52.9%,Pro 版 54.2%,GPT-5.1 Thinking 在 ARC-AGI-2 上只有 17.6%
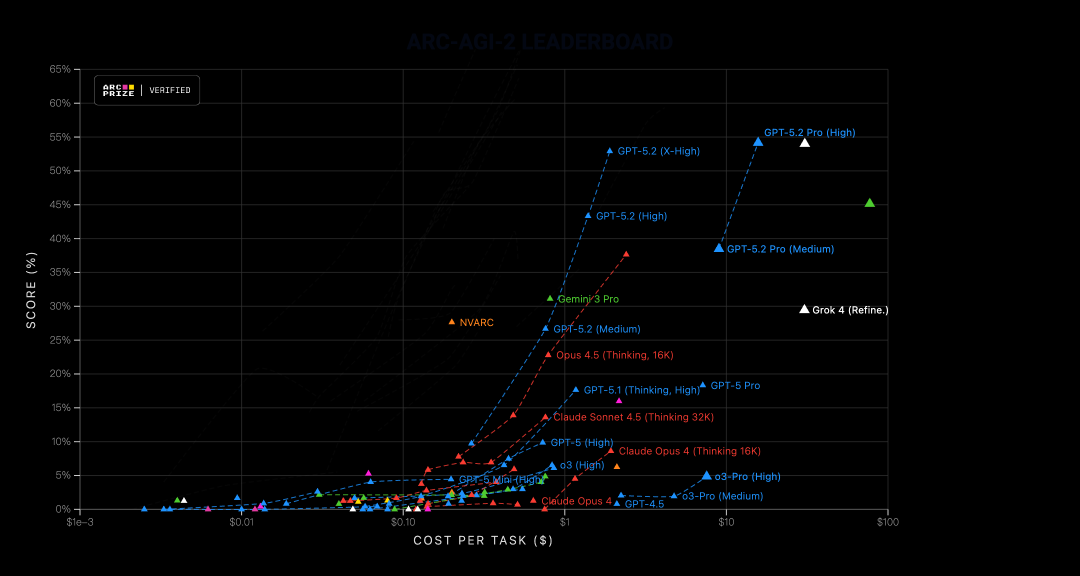
ARC-AGI
幻觉
在 ChatGPT 真实用户查询上测试
有错误的回复比例从 8.8% 降到 6.2%,相对减少 30%
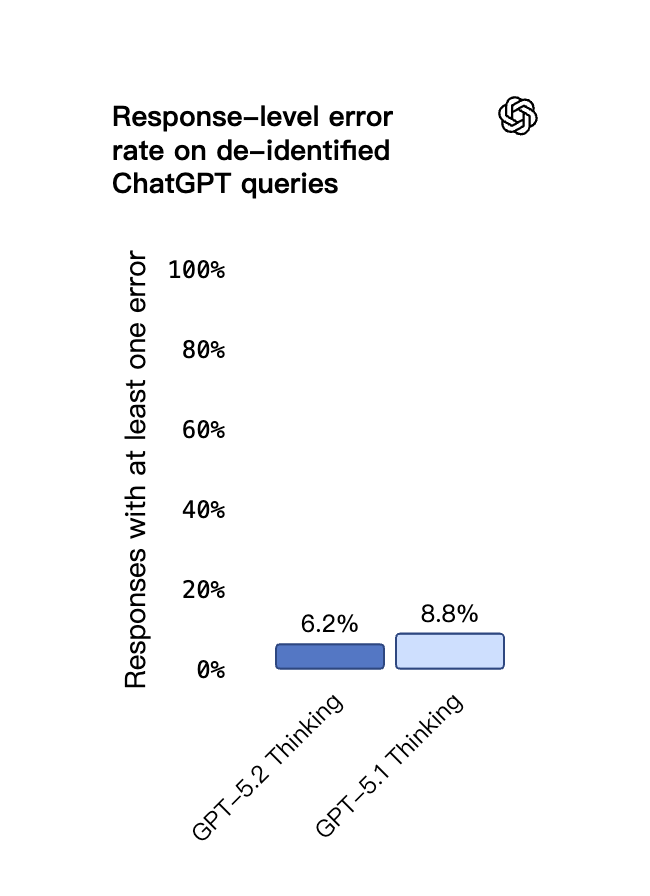
幻觉率
价格
涨了 GPT-5.2 比 GPT-5.1 贵 40%;GPT-5.2 Pro 的价格,一如既往的贵到离谱
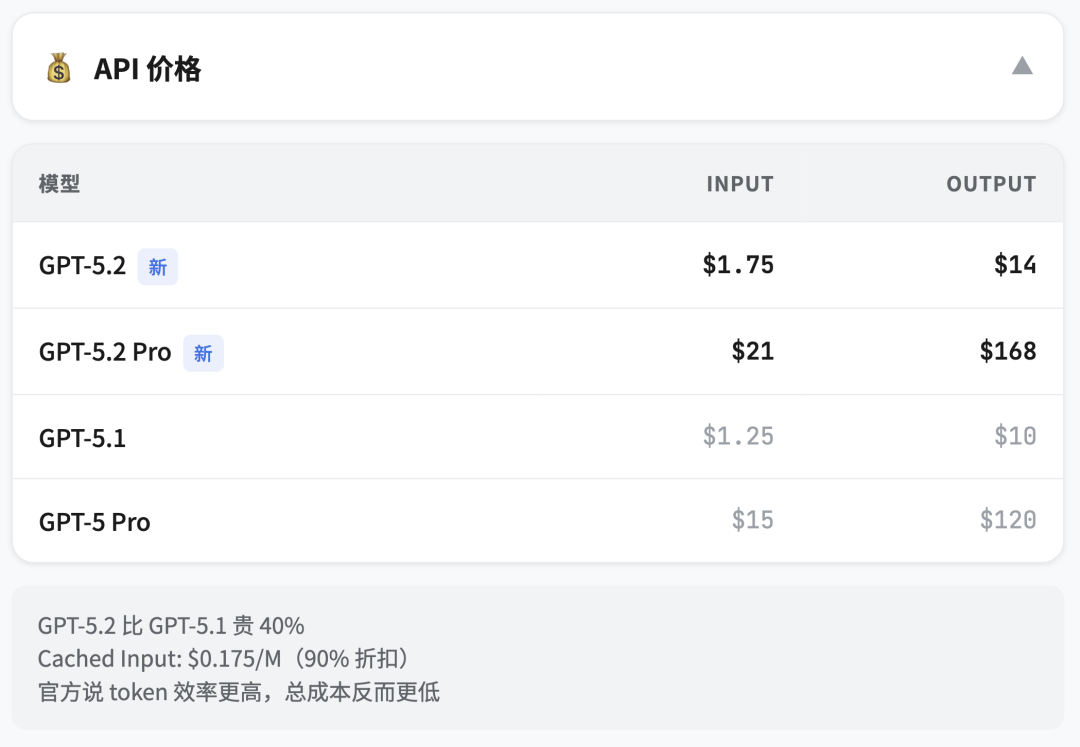
每百万 token 价格
官方解释:虽然单价更高,但 token 效率更高,达到同样效果的总成本反而更低
ChatGPT 订阅价格不变
可用性
ChatGPT 今天开始向付费用户推送:Plus、Pro、Go、Business、Enterprise
如果还没看到,过几天再试,GPT-5.1 在 ChatGPT 中还会保留三个月,之后下线
API 已经上线:
- gpt-5.2:Thinking 版
- gpt-5.2-chat-latest:Instant 版
- gpt-5.2-pro:Pro 版
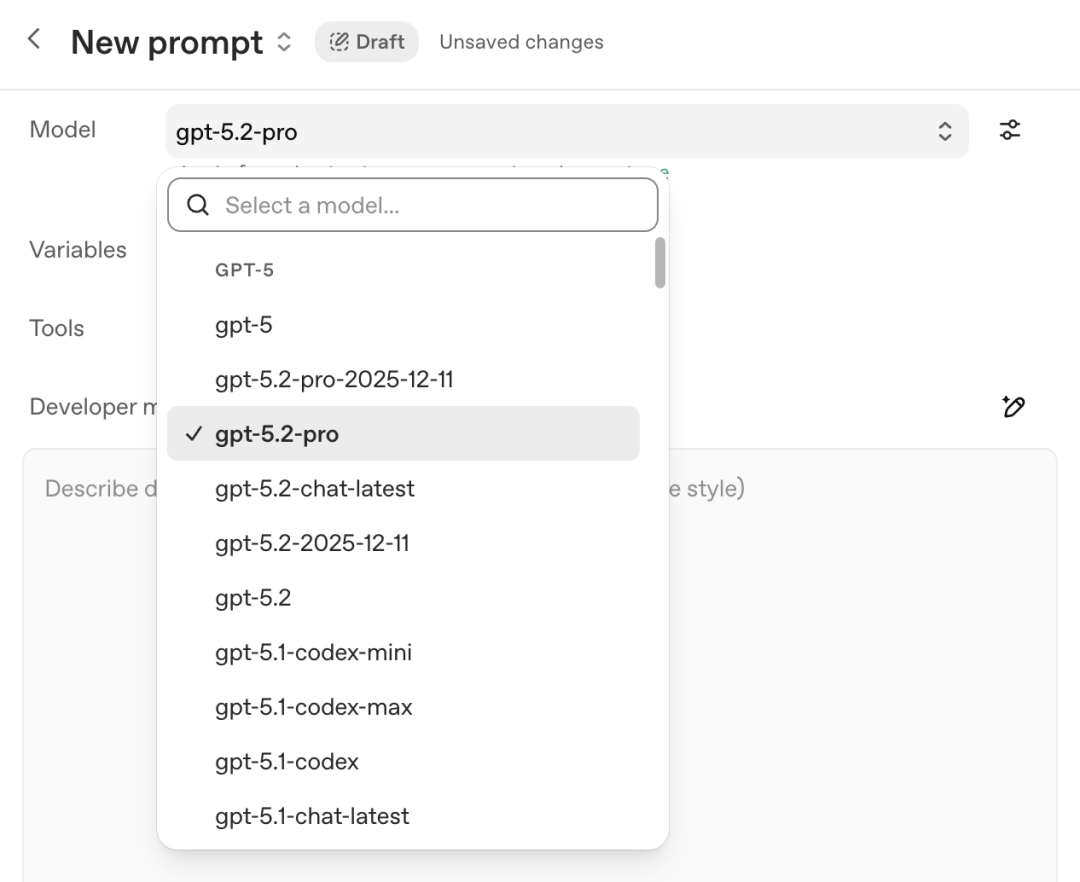
在 PlayGround 里面,可以看到这些模型
新增 xhigh reasoning effort,适合对质量要求最高的任务 GPT-5.1、GPT-5、GPT-4.1 在 API 中暂时不会下线 Codex 优化版即将推出
安全
延续了 GPT-5 的 safe completion 研究
在自杀、自残、心理健康、情感依赖等敏感对话上的表现改进了

安全性评估
开始部署年龄预测模型,18 岁以下用户自动限制敏感内容
官方说过度拒绝的问题还在改进中
最后
本次发布的内容
Code Red 一周后,GPT-5.2 发布,三个版本
性能更强,价格更贵
今天开始向付费用户推送,API 已上线
本文由 @灵山下的小妖怪 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于cc0协议






- 目前还没评论,等你发挥!


