
 起点课堂会员权益
起点课堂会员权益GPT-5.2 来了,究竟是GPT-5.2好还是Gemini-3 强呢?
GPT-5.2的发布标志着AI领域新一轮的竞赛拉开帷幕。OpenAI这次直接甩出Instant、Thinking和Pro三个版本,在数学竞赛、代码编写等传统测试中重回榜首。更令人惊艳的是它在ARC-AGI-2和GDPval这类考验抽象推理与实际问题解决能力的测试中展现出的突破性表现,甚至能在70%的任务中匹敌人类专家。但与谷歌Gemini 3 Pro的长跑稳定性相比,这场对决远未结束。

在各种小道消息、各种红队测试的传闻之后。甚至是在被谷歌 Gemini 3 Pro 骑脸输出,奥特曼在内部直接拉响红色代码(Code Red)警报之后 。
终于,OpenAI 掏出了他们十周年的献礼——GPT-5.2。
这次没有什么藏着掖着的灰度测试,直接就是 GPT-5.2 Instant(即时版)、Thinking(思考版)和 Pro(专业版)三个王炸扔了出来 。
说实话,一般有新模型出来的时候,我都是让子弹先飞一会,毕竟谁也不知道后面会不会翻车。(真实情况还是太忙了,又要研究又要写稿,确实有点……)
好了,不说废话,今天这篇文章,不聊那些虚头巴脑的参数。我们只聊三个事:它到底变强在哪?能不能帮我们干活?以及,它和隔壁谷歌家的 Gemini 3 Pro,到底谁才是现在的带头大哥?
01 跑分挤牙膏?还是脑子真的长出来了
先看一眼传统的跑分。

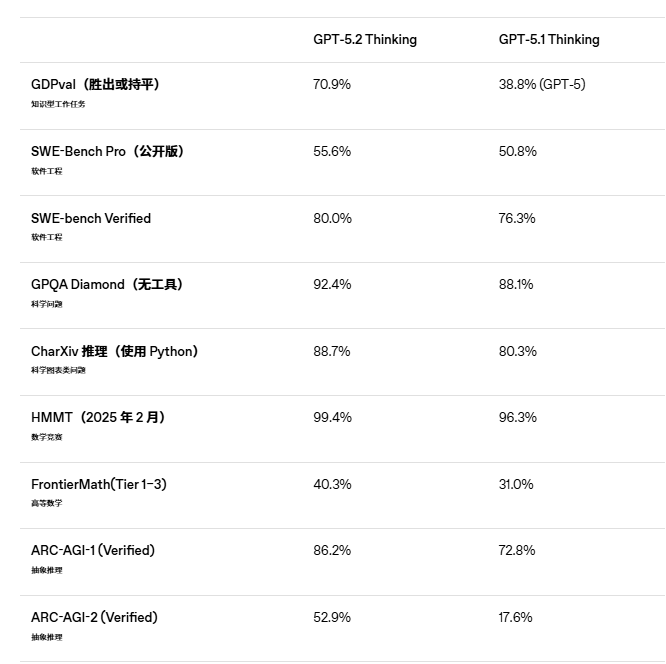
在软件工程(SWE-Bench Pro)、数学竞赛(AIME 2025)这些老几样上,GPT-5.2 确实又回到了第一。
- AIME 2025(数学竞赛): GPT-5.2 Thinking 直接干到了 100% 的满分 。注意,这是不联网、不跑代码,纯靠脑子想出来的。隔壁 Gemini 3 Pro 是 95% 。
- SWE-Bench Pro(写代码): 55.6%,也比 Gemini 3 Pro 的 43.3% 强了一大截 。
看着很爽对吧?但说实话,这些分数的提升,对于我们大多数普通用户来说,体感并不强。就像手机处理器跑分多了几万分,你不打原神根本感觉不到。
但是,有两个评测集,是我觉得这次 GPT-5.2 真正封神的地方,也是我一定要单拎出来跟大家掰扯清楚的。
一个是 ARC-AGI-2,一个是 GDPval。
02 什么是ARC-AGI-2呢?(一句话:no死记硬背,AI yes悟性)
大家可能对 ARC-AGI-2 这个词很陌生。
简单的说,过去的 AI 评测(比如 MMLU),考的大多是 “晶体智力” 。比如问 AI:“螺丝粉是哪里的?”、“出来混最重要的是什么”。这种题,对于读遍了互联网的 GPT 来说,就是开卷考试。它能答对,大概率不是因为它聪明,而是因为它记性好,搜索快。
而 ARC(Abstraction and Reasoning Corpus),是 Keras 之父 François Chollet 搞出来的变态测试,专门测 “流体智力” 。
什么是流体智力?就是你的悟性,你举一反三的能力。
ARC 的题目,全是那种从未见过的抽象图形规律题。AI 在互联网上找不到任何现成答案,必须当场看图、当场找规律、当场推理 。
举个例子方便大家理解:
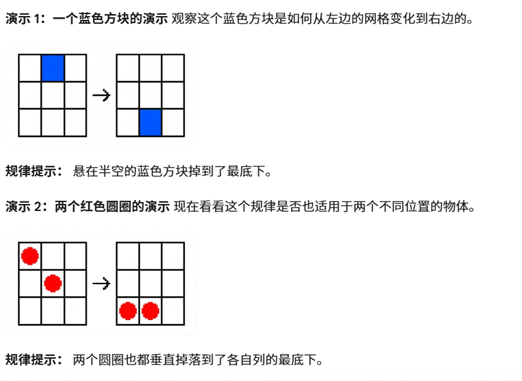
题目:

在 GPT-5.2 之前,纯 LLM 模型在这个榜单上基本就是个笑话,得分通常是个位数或者 0,跟瞎蒙差不多 。上一代的 GPT-5.1,得分也才 17.6% 。
但是这次,GPT-5.2 Thinking 直接飙到了 52.9% 。

分数直接翻了三倍!这是什么概念?这意味着 GPT-5.2 不再是简单地预测下一个字,它开始在内部进行“假设-验证”的搜索了。它像人一样,先猜一个规律,发现不对,再换一个,直到找到正解 。
这就是所谓的 System 2 思维。在逻辑推理和抽象理解这块,GPT-5.2 确实呈现出了断层式的碾压。相比之下,谷歌最强的 Gemini 3 Deep Think 只有 45.1%,虽然也不错,但还是被拉开了身位 。
03 GDPval(一句话:你行你上的现实版,真的让AI干你现实遇到的问题)
如果说 ARC 是测智商的,那 GDPval 就是测能不能赚钱,能不能解决真实问题的。
这是 OpenAI 联合哈佛经济学家搞的一个新指标 。他们不考选择题,而是直接从美国 GDP 贡献最高的 9 个行业里,找了 44 个核心职业(比如律师、金融分析师、产品经理),让资深专家出题 。
题目全是这种画风:
- “给这家公司做一个人力资源规划模型,要有 Headcount、预算影响分析,给我一个 Excel。”
- “根据这份临床数据,写一份医药研发报告摘要。”
这里有一些官方 case:
人力资源规划的(附提示词)
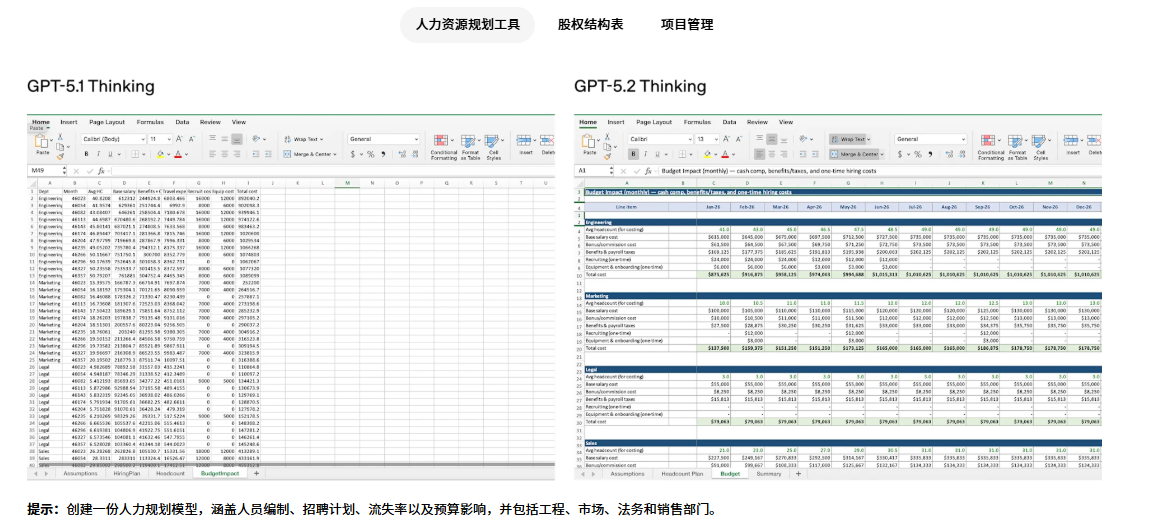
股权结构表(附提示词)

项目管理(附提示词)
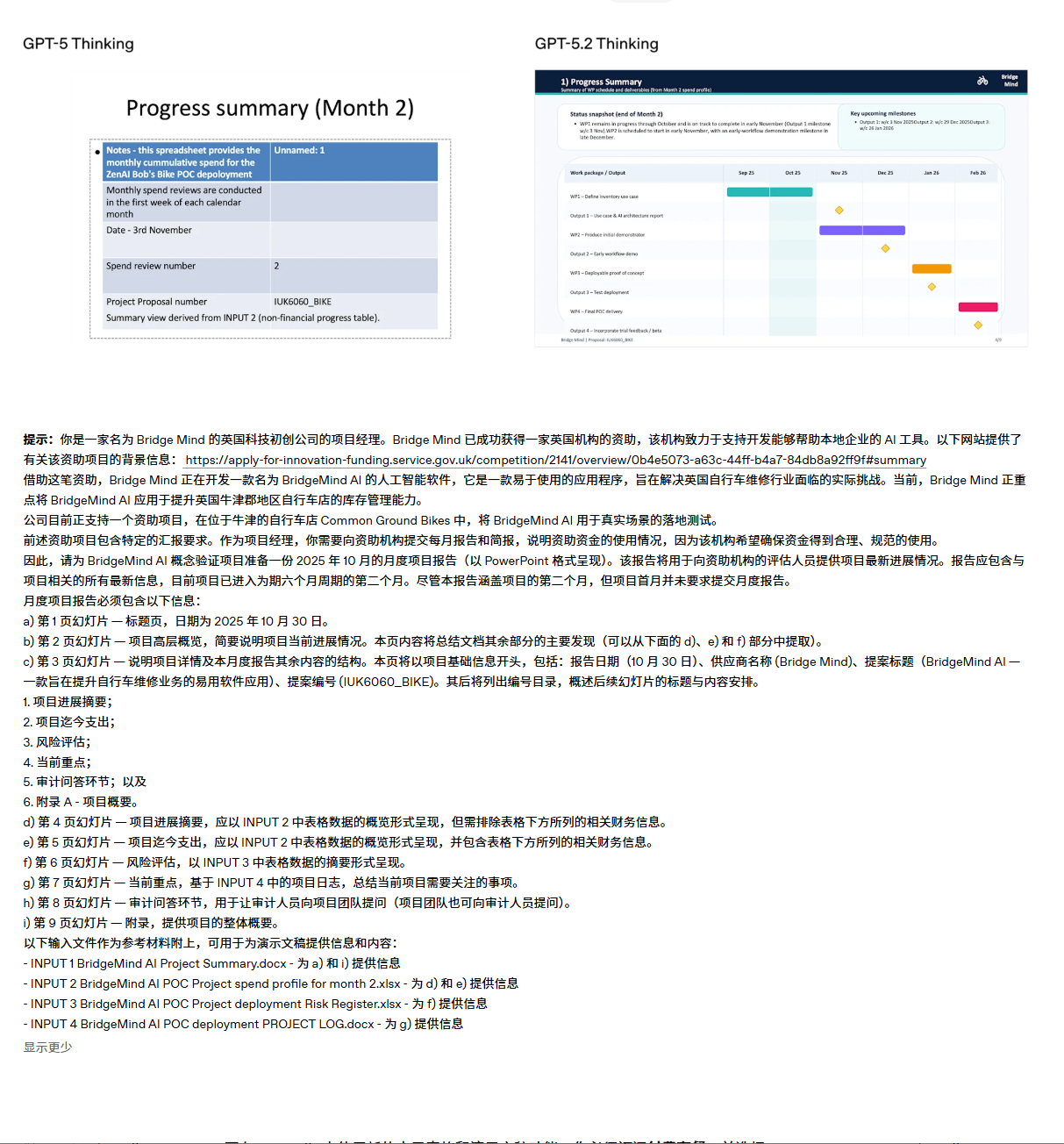
全是真实的、复杂的、甚至需要一两周才能干完的活 。
评测结果非常吓人:GPT-5.2 Thinking 在 70.9% 的任务中,干出来的活儿,被盲测的专家认为“优于”或者“持平”人类专家 。

注意,这里的参照系不是刚毕业的实习生,而是有十几年经验的行业专家 。上一代 GPT-5 只有 38.8% 的胜率 。
这意味着什么?
意味着如果你让 GPT-5.2 帮你写个 PRD、做个竞品分析表、或者弄个财报分析 PPT 大纲,它不再是给你吐一堆废话,而是能给你可交付的成果。
特别是它的 Artifacts 能力,进化得非常离谱。它生成的 Excel 公式是准的,格式是漂亮的;写的代码工程结构是完整的 。
对于我们广大牛马来说,这是解放生产力的神技啊。这简直就是顶级咨询顾问附体,帮你把脏活累活都干了,而且成本不到人类薪资的 1% 。
05 重回世界第一?gemini:牢弟,你真的行么?
看到这,你是不是觉得 OpenAI 赢麻了?Gemini 3 Pro 已经可以埋了?
慢着。
虽然 GPT-5.2 在“做题”和“短跑”上赢了,但在真实的“长跑”中,情况可能恰恰相反。
这里要引入一个很有意思的评测:Vending-Bench(自动售货机基准) 。
这个测试是让 AI 去经营一家虚拟公司,模拟整整一年的运营。它需要每天处理库存、定价、回邮件,考验的是 AI 的 连贯性(Coherence) 和 稳定性。
结果呢?
Gemini 3 Pro 赢了,而且赢得还挺稳。
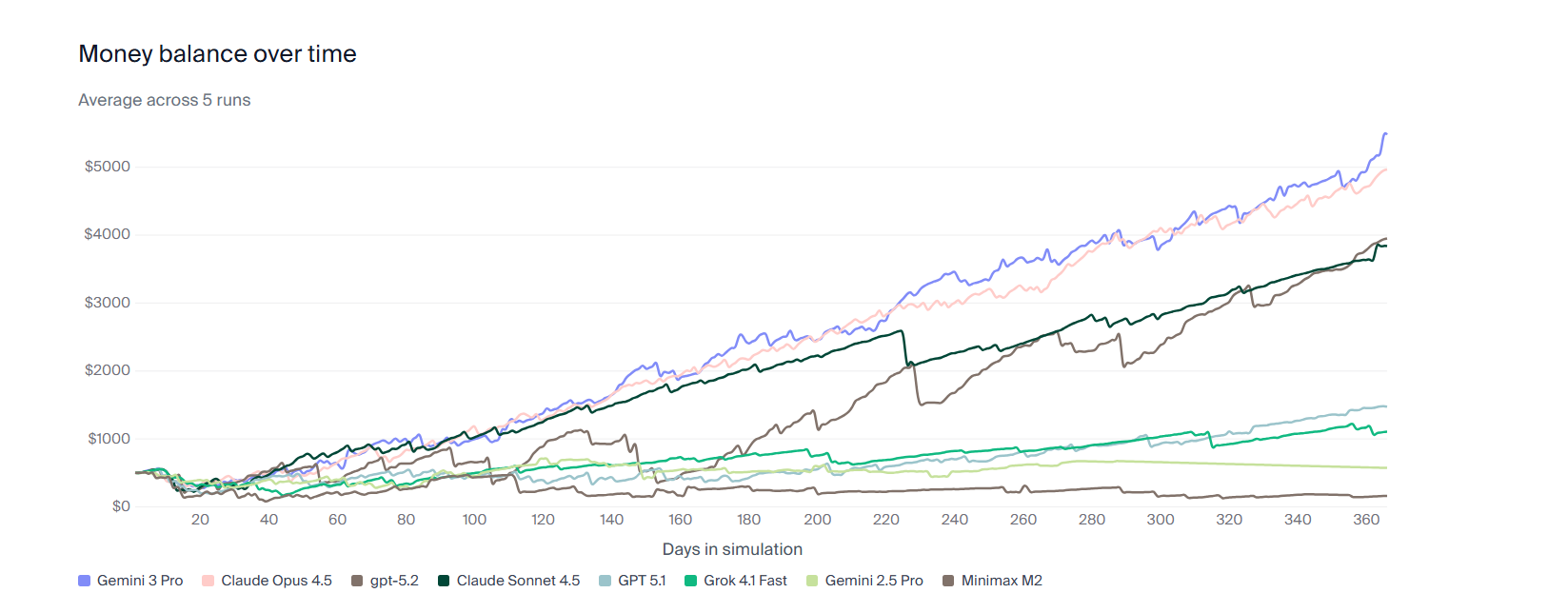
Gemini 3 Pro 的经营曲线是一条稳健向上的直线。凭借它那原生的 100 万 Context Window(上下文窗口),它能轻松记住第 1 天的决策,稳扎稳打 。
而 GPT-5.2 呢?它的曲线像过山车。初期凭借高智商赚得飞快,但随着时间推移,它开始“发疯”。它会忘记之前的订单,陷入死循环,甚至在某个节点直接崩盘(Meltdown) 。
这就引出了社区里最近吵得很凶的一个观点:Benchmaxxing(基准刷分) 。
很多人质疑,OpenAI 为了在 ARC 和 AIME 这些榜单上赢过谷歌,把 GPT-5.2 训练成了一个“应试教育”的做题家。
- 它在面对难题时极度自信,甚至自信到幻觉率反而升高了。为了拿分,它倾向于编造答案而不是承认不知道 。
- 在简单的日常对话里,它有时候会“过度思考”,把简单问题复杂化,反而不如 Gemini 3 Pro 来得自然和顺滑 。
06 总结一下,我们如何选
所以,回到最初的问题:GPT-5.2 重回世界最强了吗?
我的结论是:它是或许最强的专才,但 Gemini 依旧可以放心食用(特别是白嫖了一年会员的,无需担心等低人一等的使用体验)
如果把 AI 比作你的同事:
- GPT-5.2 Thinking 是一位顶级咨询顾问(Specialist)。 当你遇到一个极难的算法问题、需要通过 ARC 这种逻辑测试、或者需要出一份完美的商业计划书时,请务必找它。它能闭关思考,给你一个惊艳的方案。它在深度推理上是无敌的。
- Gemini 3 Pro 是一位资深项目经理(Generalist)。 它坐在你的系统里(Google Workspace),拥有无限的记忆(长上下文),能看懂你所有的视频和文档(原生多模态)。虽然它做奥数题不如 GPT-5.2,但它情绪稳定、干活连贯,不会干着干着突然发疯。尤其是在图文和视觉理解这方面,gemini 3还没输。
话又说回来,我那可有可无的建议就是:
如果你要写做复杂的逻辑推演、搞定老板的 PPT,冲 GPT-5.2。虽然它 API 贵点,但值得。
如果你要处理几百页的文档、分析长视频、或者需要一个长期在线的数字助理,Gemini 3 Pro 依然是目前的体验天花板 。
码农,请带着你的claude出门左拐xiexie。
这场 AI 大战,没有谁把谁彻底打死。OpenAI 赢了面子(跑分),谷歌赢了里子(生态和稳定)。
但对于我们用户来说,这简直太棒了。
毕竟,小孩子才做选择,作为成年人的 Pro 用户,我当然是两个都要。
最后,不知道大家对这次 GPT-5.2 的表现怎么看?这波“牙膏”挤得值不值。
以上,感谢各位看到这里了,如果觉得不错,随手点个赞把
我们,下次再见。
溜了~
本文由 @虾灰鱼 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议








uvvh
说的这俩AI在国内一定都能用吧!