
 起点课堂会员权益
起点课堂会员权益【实战复盘】手搓一个“较真型”博物馆 AI 导览员:从视觉识别到历史辟谣
本项目基于 腾讯元器智能体平台,旨在解决传统文博导览“交互单向、内容枯燥、信息滞后”的行业痛点。不同于市面上通用的泛娱乐 AI,本智能体定位于“严谨的历史考据派”。
通过集成腾讯元器的多模态大模型 与 较真查证生态能力,我们构建了一个具备“视觉感知 + 深度考据 + 知识增强”三位一体的智能导览员。它不仅能通过视觉识别文物实体与铭文细节,更能连接私有知识库提供深度策展内容,并实时粉碎历史谣言。本项目充分利用了元器平台“零代码分发微信生态”的优势,让专业级的文博服务能够以“即扫即用”的方式触达每一位游客。

一、项目背景与需求分析
1. 行业现状的深度洞察
在实地调研中,我发现当前博物馆导览体验存在非常明显的“供需错配”,痛点集中在两端:一端是传统导览方式的低效与滞后,另一端是通用 AI 在严肃知识场景里的不可靠。
首先是硬件端的“孤岛效应”:传统租赁式导览机租借流程繁琐,使用门槛高,而且内容更新极慢,很多还停留在几年前的录音版本,无法覆盖观众临场产生的“突发奇思妙想”。与此同时,观众如果转而使用 ChatGPT、文心一言等通用大模型来咨询文博问题,又会掉进“幻觉陷阱”——AI 可能非常自信地编造历史,把不同朝代的故事嫁接在一起;在文博这种需要严谨、可追溯的场景里,这种“一本正经的胡说八道”完全不可接受。
具体到看展的真实体验,我感受到的阻力也很直接:租借导览机太麻烦、看说明牌太枯燥、遇到不懂的问题想问却没人理。虽然市面上已经有元宝等 AI 产品,但它们在博物馆场景里仍有三个“硬伤”:
第一,缺乏视觉交互——人看到文物的第一反应往往是拍照,而不是先组织语言打字描述;
第二,容易胡说八道——当游客问到历史争议点或民间野史(比如“兵马俑是活人烧的吗”)时,通用 AI 往往模棱两可,甚至开始编故事;第三,缺乏深度——回答常停留在“百度百科式”的信息堆砌,缺少策展人视角的结构化解读与价值阐释。
基于以上问题,我的需求定义是:打造一个“能看懂图、能查内部资料、且极度严谨”的博物馆智能体。它不只是解说员,更要在关键问题上做到可依据、可核验、能纠错——成为展厅里的“谣言粉碎机”。
2. 核心需求的重新定义
基于上述痛点,我认为一个真正可用的文博 Agent 必须满足三个维度的硬指标:
- 交互的直觉性:观众在博物馆的自然行为是“看”和“拍”。因此,“多模态视觉交互”必须是第一入口,而非尴尬的文字输入。
- 内容的权威性:它不能是一个只会闲聊的陪聊机器人,必须是一个背靠博物馆内部资料库、且具备谣言甄别能力的“数字策展人”。
- 触达的极简性:必须依托用户最常用的 App(微信),实现“去安装化”,扫码即用,用完即走。
二、为什么选择腾讯元器
在本项目立项之初,我们评估了包括 Coze、Dify 以及开源 LLM 在内的多种技术方案。最终坚定选择 腾讯元器,并非仅因其大厂背书,而是基于本智能体在“数据准确性”、“视觉理解力”与“场景触达率”这三个核心维度上的特殊需求,元器提供了不可替代的差异化优势:
1. 独家生态壁垒:用“较真”打破 AI 幻觉困境
痛点:文博领域的 AI 应用存在一个致命红线——“历史虚无主义”。通用大模型在面对“野史传闻”时,往往因为训练数据的混杂而产生幻觉,容易一本正经地传播错误历史。普通平台接入的通用搜索引擎,搜索结果充斥着营销号噪音,难以作为严谨的参考信源。
元器优势:腾讯元器能够原生接入 腾讯新闻“较真”查证知识库的平台。这不仅仅是一个插件,更是一道“内容安全防火墙”。它让我们的智能体拥有了分辨“戏说”与“信史”的能力,确保输出的每一条辟谣都背靠权威机构的背书。这种“基于查证的生成”能力,是其他仅靠通用搜索的平台无法比拟的。
2. 多模态优势:更懂“中国芯”的视觉感知
痛点:西方主流多模态模型(如 GPT-4V)虽然强大,但在处理中国传统文化符号时常出现“水土不服”。例如,它们很难区分“云雷纹”与“饕餮纹”,或将“小篆”误识别为乱码。
元器优势:本项目调用的 ImageQuiz (基于腾讯混元大模型),在海量中文互联网数据与本土文化图谱的训练下,展现出了极高的**“本土化视觉理解力”。在实测中,它能精准识别青铜器的器型(如区分“鼎”与“鬲”)、读懂碑帖上的书法风格。对于博物馆场景而言,这种“懂中国文化”的视觉底座**是项目成功的前提。
3. 微信生态的无缝分发:解决“最后一公里”触达难题
痛点:线下博物馆属于典型的“低频、即时”场景。游客不会为了看一次展去下载一个专门的 App,网页端交互又无法留存用户。如何让用户“不仅能用,还能带走”,是落地的最大难点。
元器优势:元器打通了 AI 智能体通向微信生态的“高速公路”。我们开发的智能体可以零代码一键发布为微信小程序、公众号智能客服。游客在展馆现场**“扫码即用”,离馆后通过微信聊天列表随时回访。这种“去安装化”的极简体验,极大降低了用户的使用门槛,是目前 C 端落地效率最高的解决方案。
本智能体名为“文物复活计划”,是使用腾讯元器生成的专为博物馆场景打造的“视觉感知+深度考据”型数字导览员。它集成了混元多模态视觉理解、OCR铭文识别与“较真”查证引擎三大核心功能,不仅能通过用户拍摄的照片精准识别文物实体与细节,更能结合私有知识库与权威辟谣数据,实时粉碎历史谣言,彻底解决通用AI“一本正经胡说八道”的幻觉痛点;适用于线下博物馆导览、历史教学及文化科普场景,游客无需下载App,通过微信扫码即可获得一位严谨博学、拒绝野史的专属策展人,实现从“走马观花”到“深度考据”的沉浸式体验升级。
智能体链接:
腾讯元器

三、搭建过程详解
首先开始搭建进入元器,点击新建智能体,选用对话式智能体。
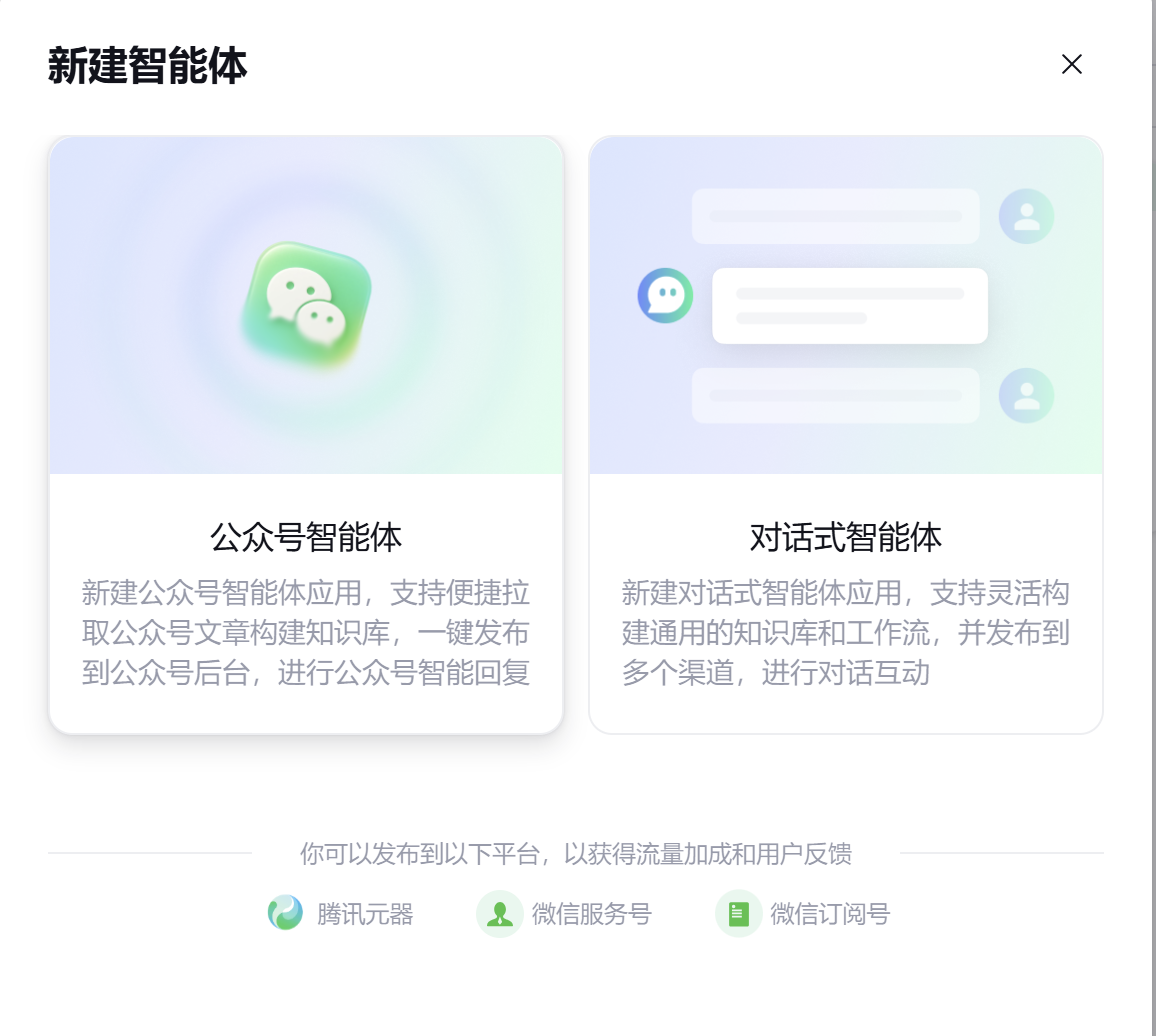
然后填入智能体的名称和简介,写明该智能体的用途,还能生成文物头像。
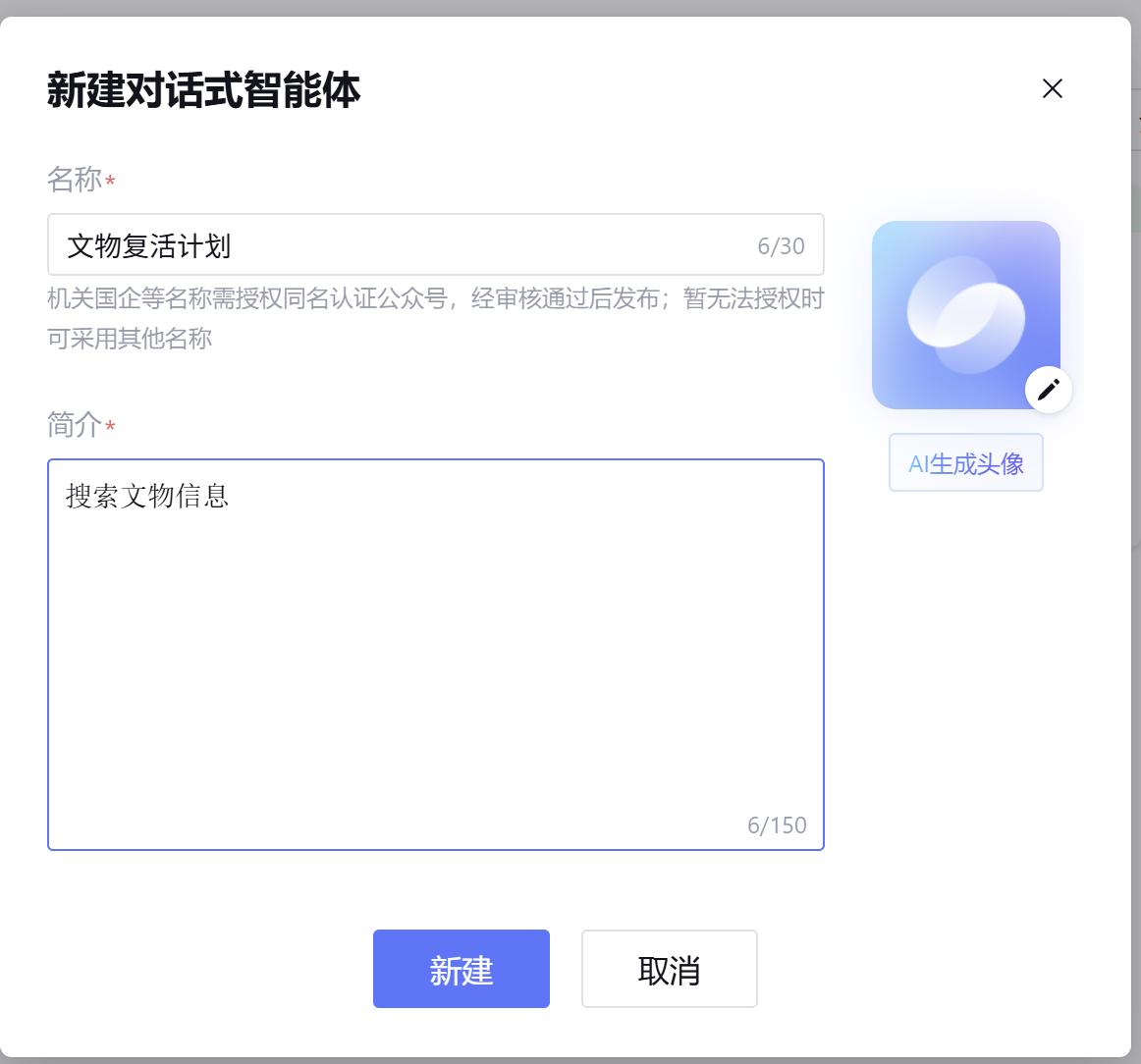
进入页面后,,点击左上角的标准模式, 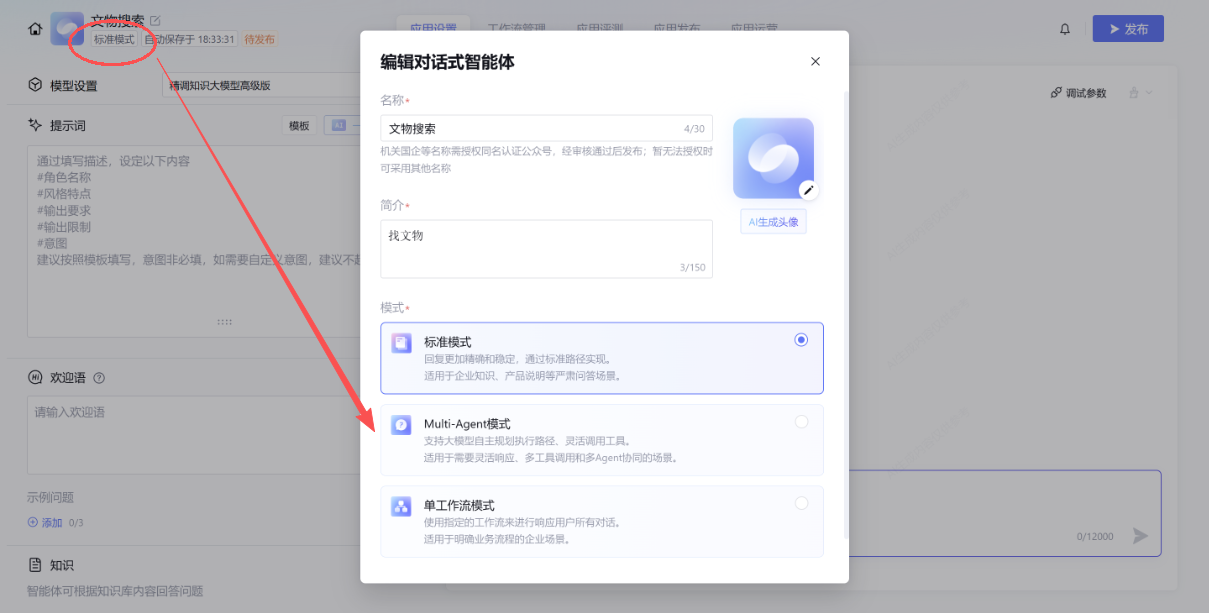
选择里面的Multi-agent模式,确认切换,然后点击保存(有可能需要使用滚轮往下滑一点)。
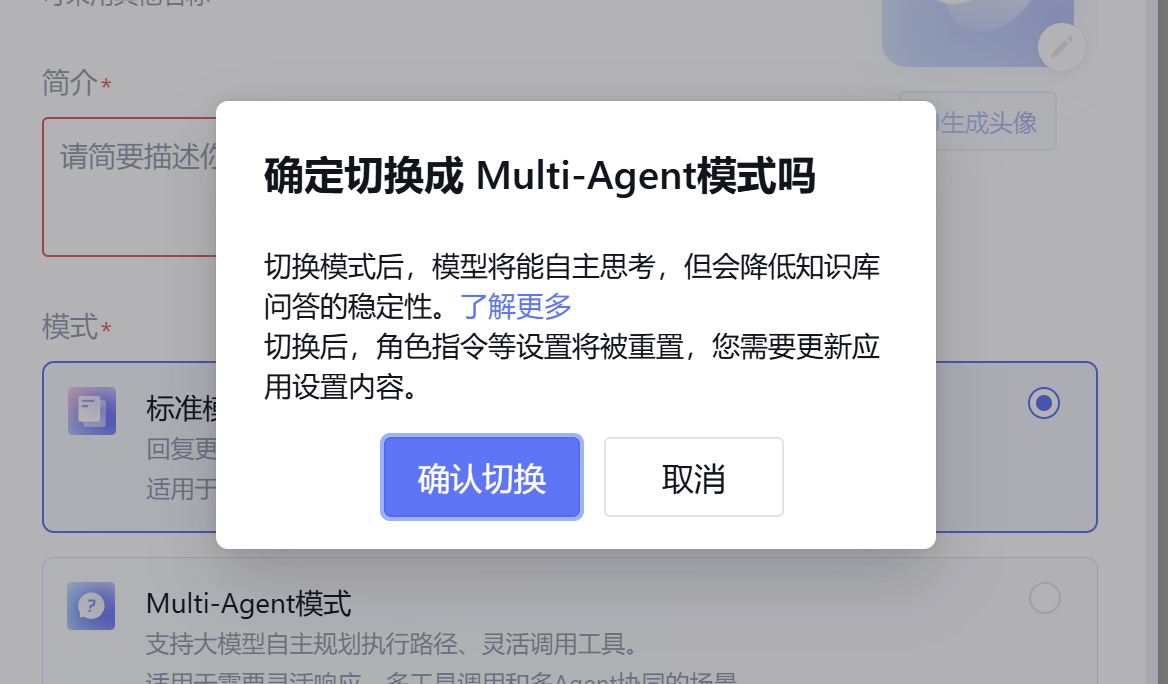
本项目采用了 “精调模型中控 + 插件群” 的架构,构建思路为中控调配插件。
选用的插件分别图片理解(ImageQuiz),图片识别文字(OCR),较真AI(FactCheck),Deepseek搜索(V3)和知识库问答(KnowledgeRetrievalAnswer)。
我引入 ImageQuiz 与 OCR 组合,赋予了智能体像人类一样‘看懂文物、读懂铭文’的视觉能力,打破了文字交互的局限;同时,特意选用 FactCheck (较真查证) 替代普通搜索,并配合 私有知识库。
模型选择上选择的是精调Function-call 模型(记忆轮数5轮和最大推理数15轮,可以满足绝大多数的用户群体)
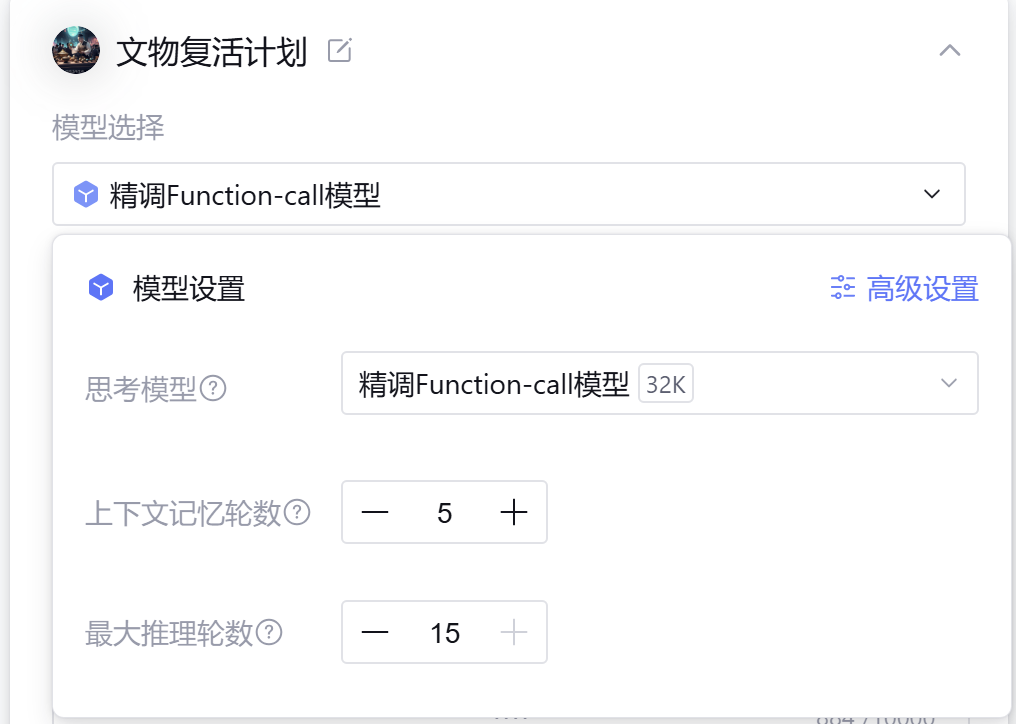
在【模型选择】阶段,我面临两个选项:一是擅长长文写作的混元 TurboS,二是专精工具调用的 Function-call 模型。
我的选择:精调 Function-call 模型。
深度思考:博物馆导览的本质,不是“陪聊”,而是“服务调度”。
- 当用户发来一张照片,系统必须百分之百调用视觉插件,而不能因为模型“走神”而开始凭借幻觉瞎编。
- 当用户询问野史,系统必须精准切换到查证模式。 通用大模型虽然文采好,但在“执行指令的严谨度”上往往存在概率性失效。为了确保智能体在面对复杂输入(如图片+文字混合)时能准确判断意图,Function-call 模型提供的确定性调度能力,是这个系统的基石。
接着,点击插件,右上角的添加
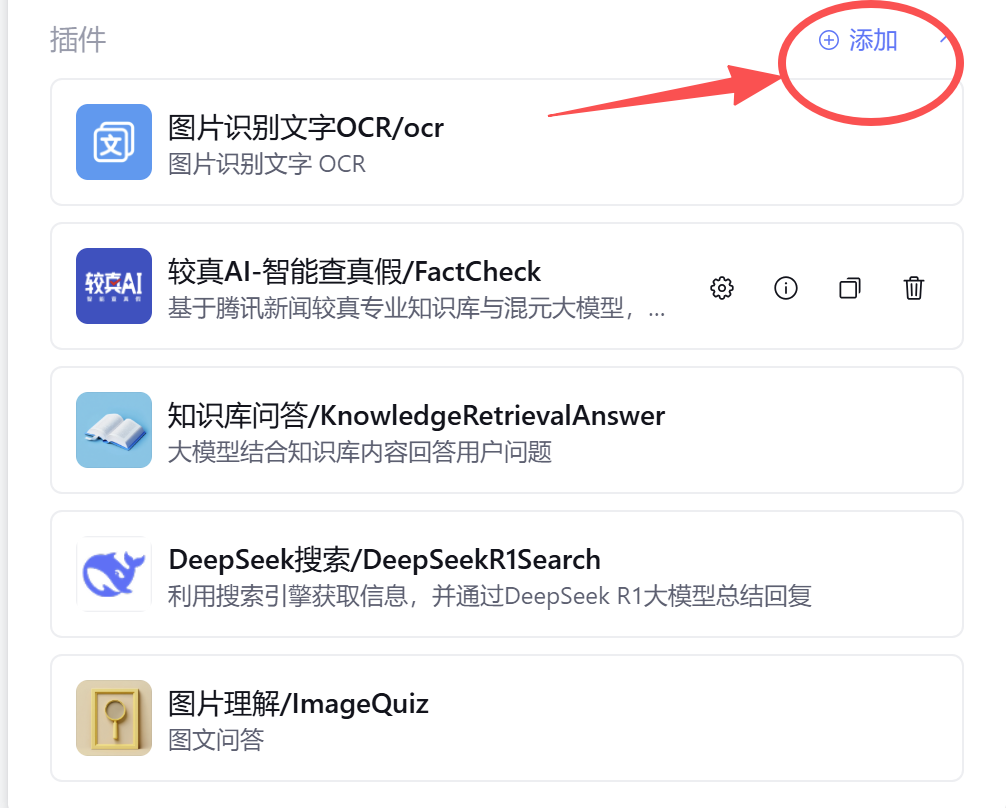
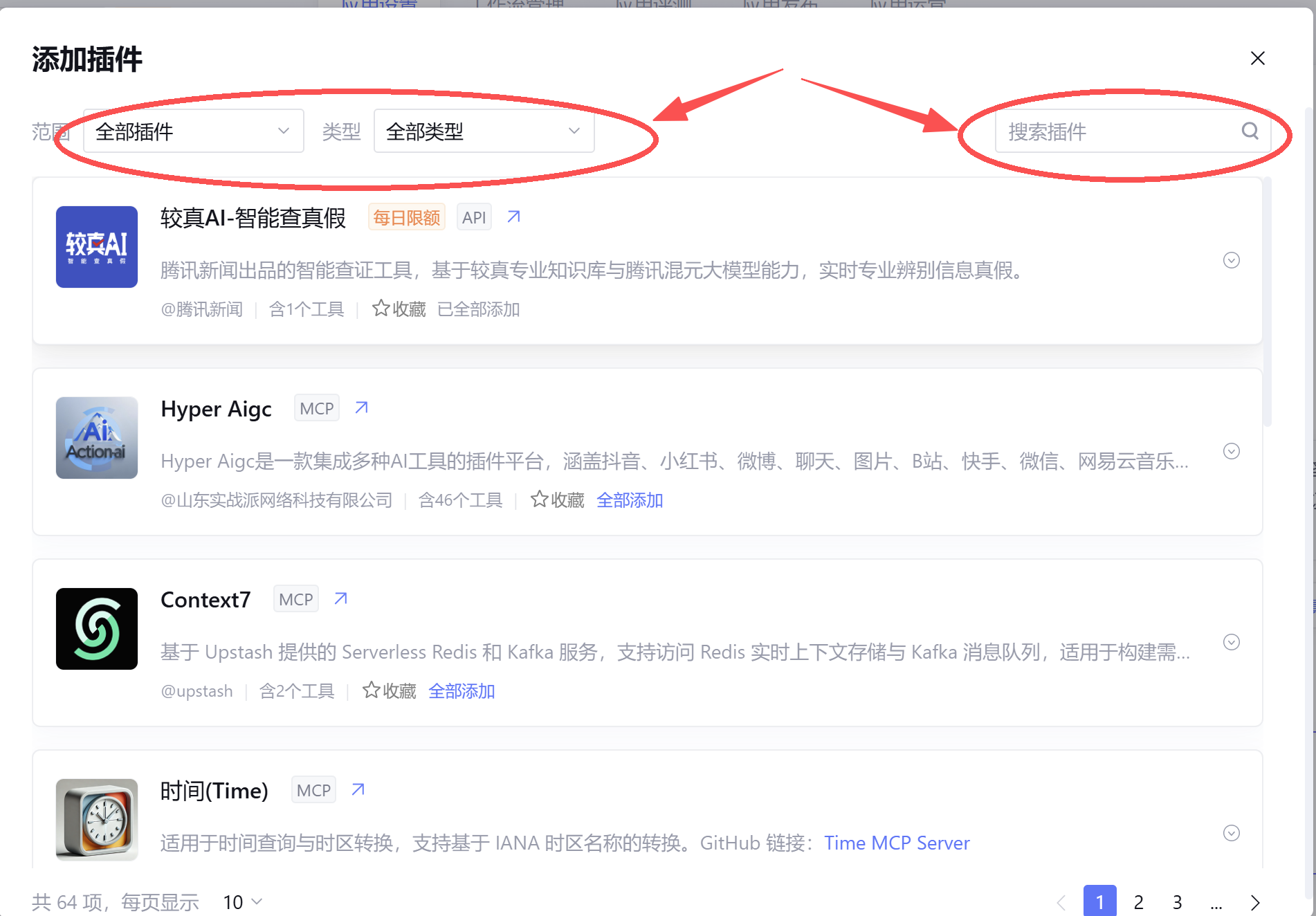
就能跳转到添加插件,可以选择插件的范围,类型和搜索到自己想要的插件
在搜索插件,输入图片理解,点击图片理解右边的小标,再点击添加就可以添加进插件了
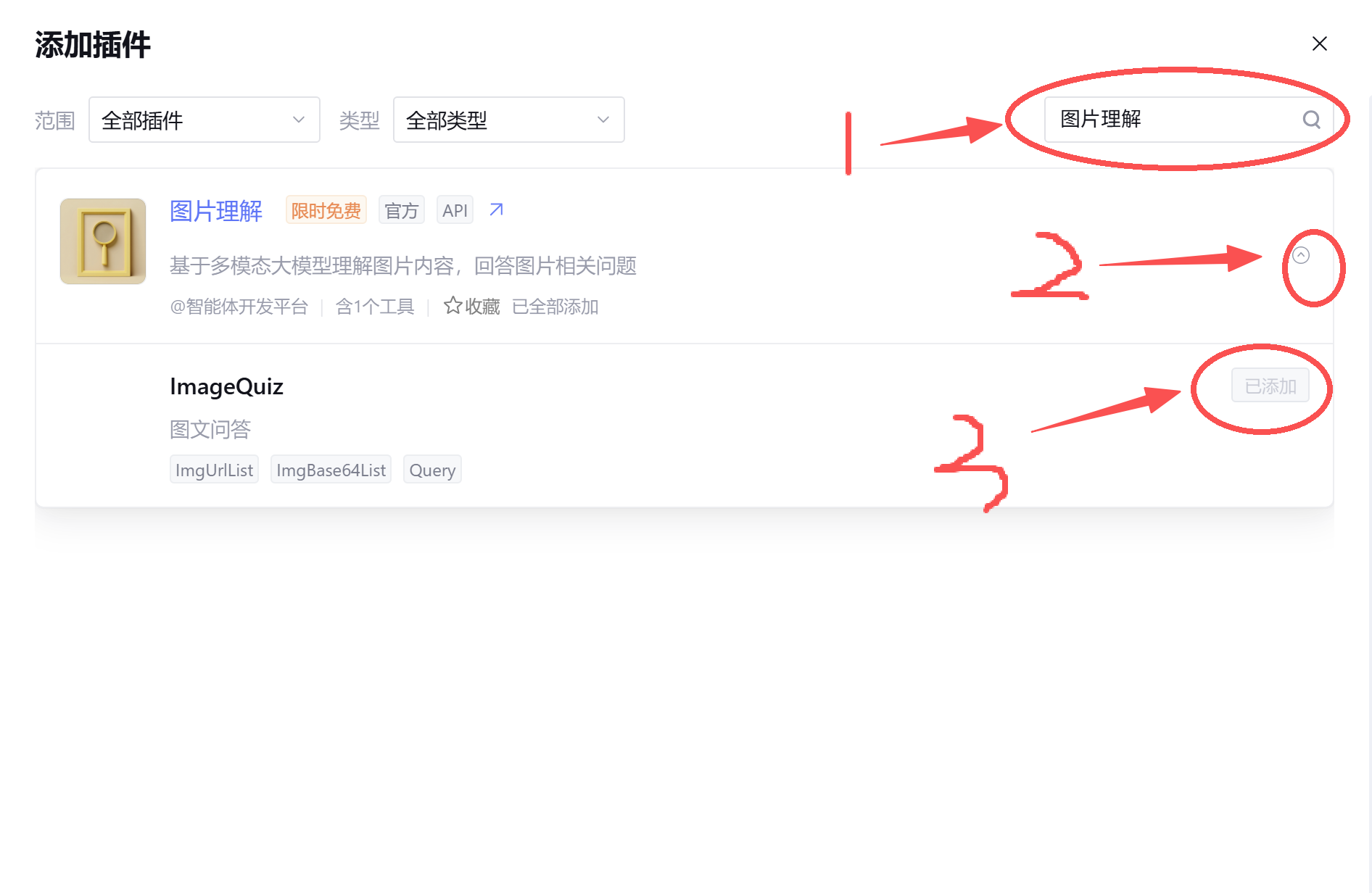
同理,我们分别加入OCR,图片识别文字, 
较真AI, 
DeekSeek R1(根据自己自己需求看看是否添加V3)。
在【插件配置】环节,我没有采用“大而全”的插件堆叠,而是根据文博场景的特殊性,定制了“视觉+考据”的双重感知路径。
视觉路径:ImageQuiz + OCR 的组合拳
思考:为什么有了“图片理解”还要加“OCR”?
很多文博展品(如字画、碑帖)的核心价值在于文字。ImageQuiz 擅长识别“这是什么物体”(如:这是王羲之的贴),而 OCR 擅长读取“上面写了什么内容”(如:识别具体的印章文字)。两者结合,才能实现对文物**“形”与“意”的全量解读**。
考据路径:以“FactCheck”替代“WebSearch”
思考:这是本项目最关键的差异化决策。
通常做法是接入“微信搜一搜”来回答知识库里没有的问题。但博物馆场景容错率极低,互联网上的营销号文章、未经证实的野史充斥着噪音。
我决定接入腾讯新闻的 FactCheck (较真查证) 插件。这一置换,直接将智能体的定位从一个“懂很多的解说员”提升为“严谨的历史考据者”。它不再输出模棱两可的网文,而是输出经过核实的信史,这符合博物馆的专业调性。
知识库回答会在一开始的时候就自动添加进插件(根据是否需要选用)

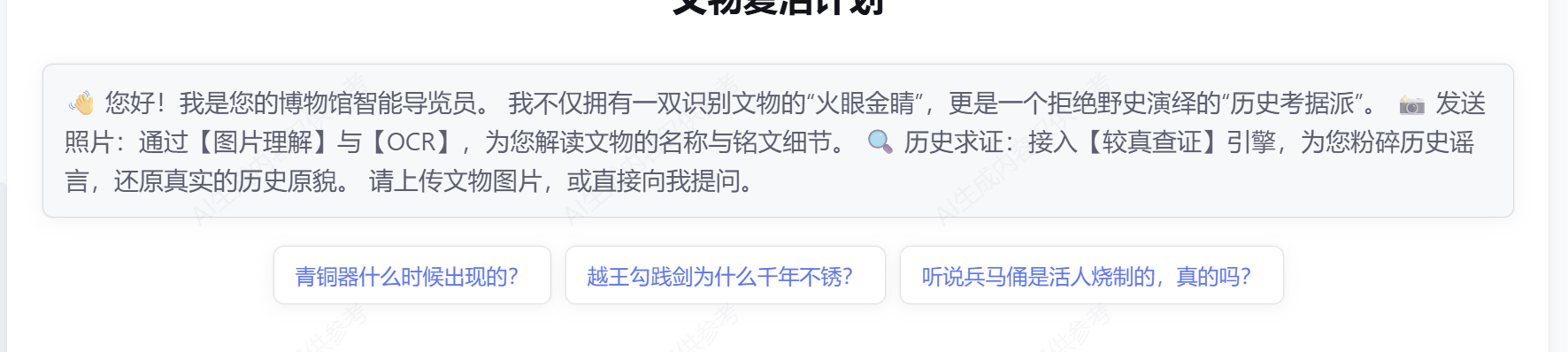
滚轮往下滑来到欢迎语,我们先写一段自己Agent用户进入界面考的欢迎语,以及3个示例问题,用于引导用户进行提问
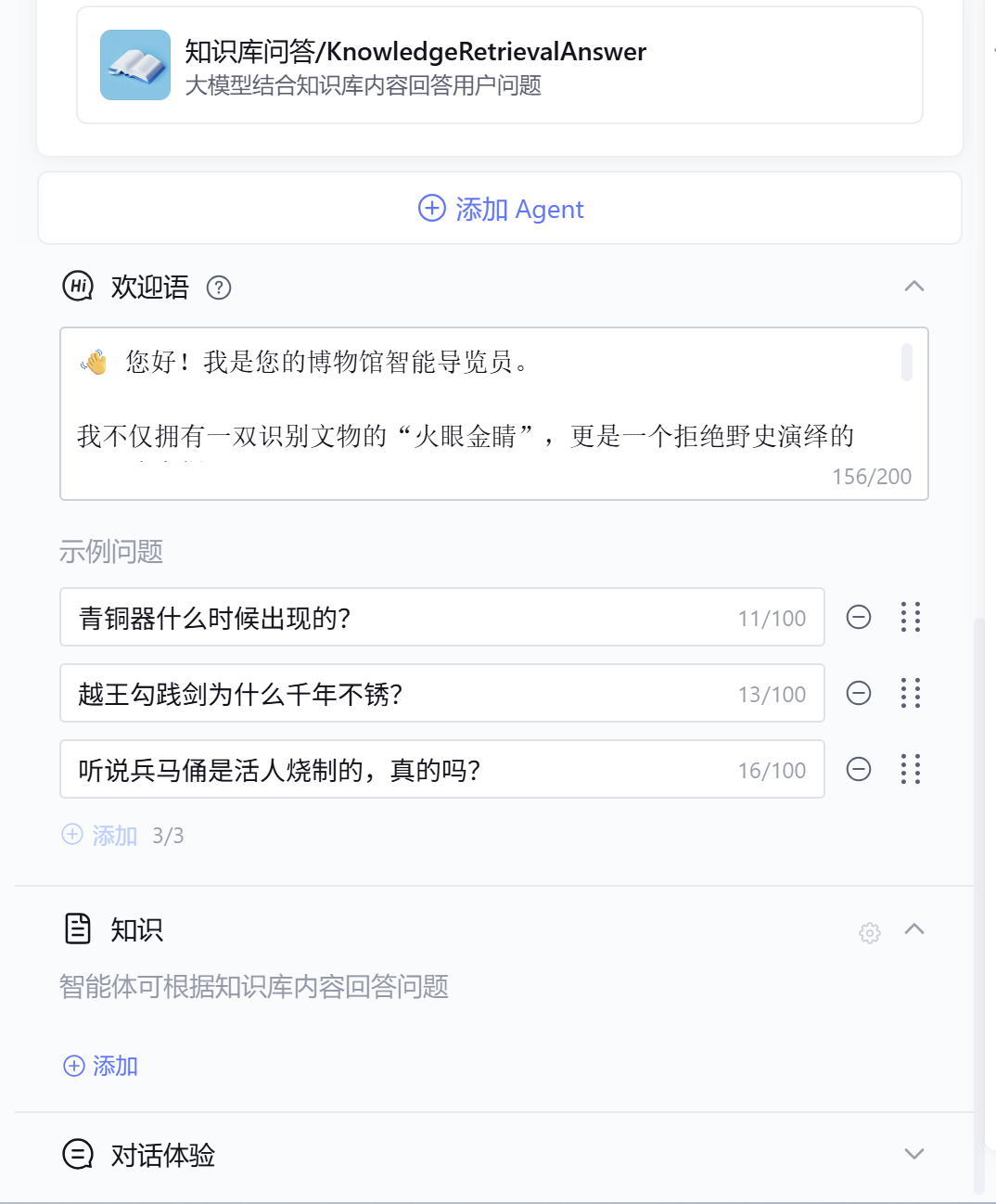
效果如下
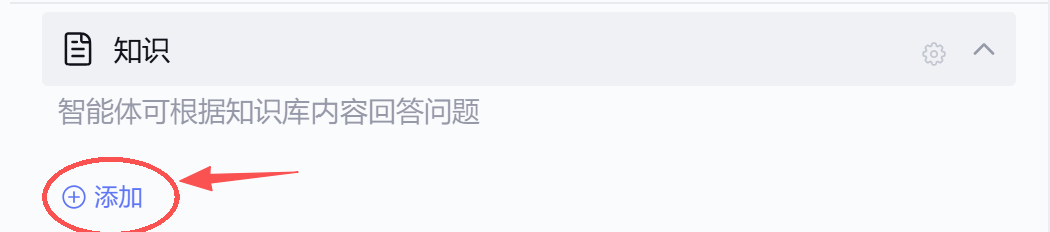
因为上面我使用了知识库问答,所以我们接下来配置知识库,点击添加
接着开始配置自己的知识库,点击去新建
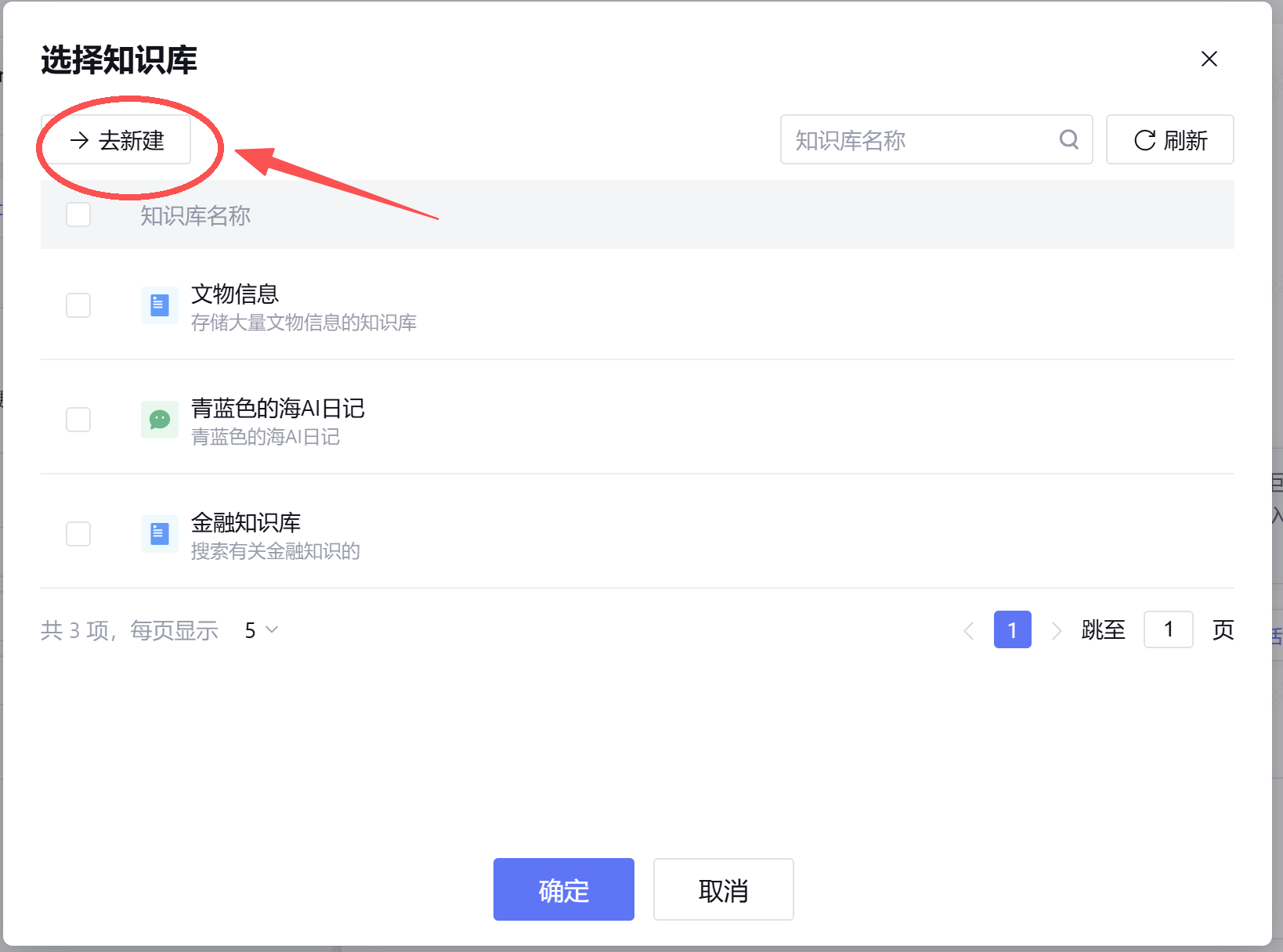
跳转到一个新页面,点击新建知识库,在弹出菜单中中选择通用知识库
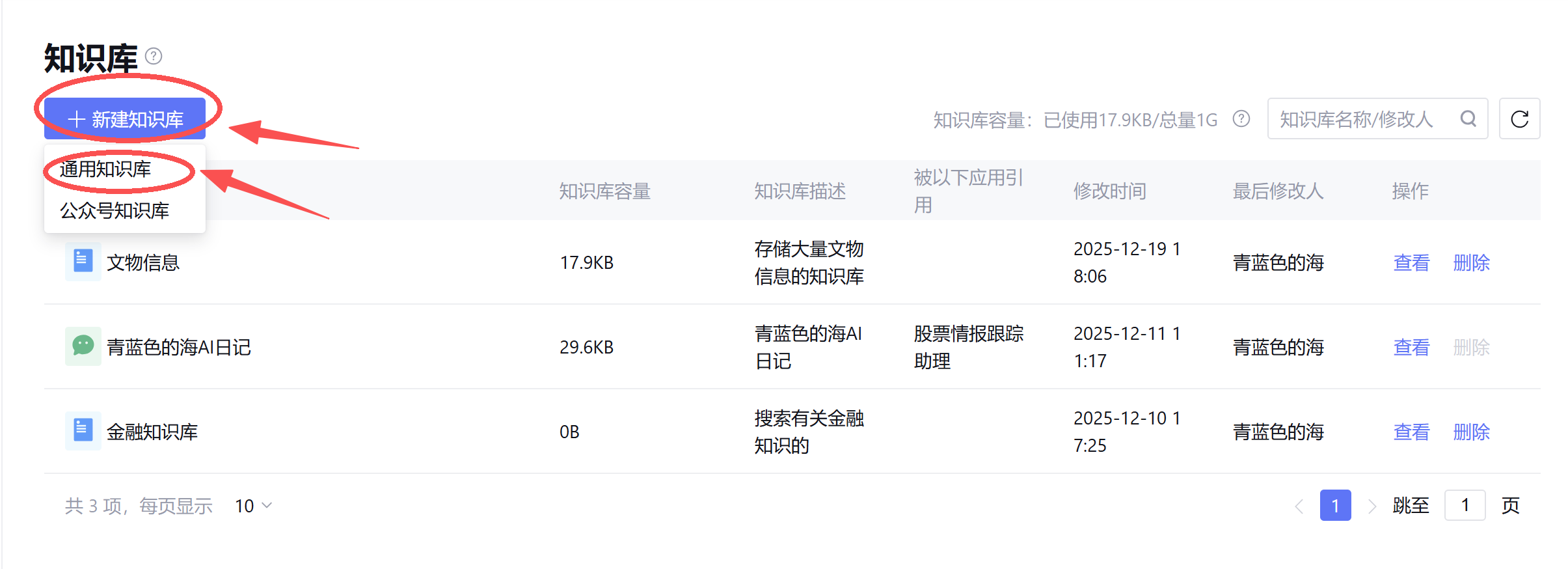
在新建知识库时,务必写好名称和描述,这是为了Agent在检索知识库能识别该知识库的作用,如果胡乱起名就会导致无法检索。
创建完成后,点击查看进入该知识库。
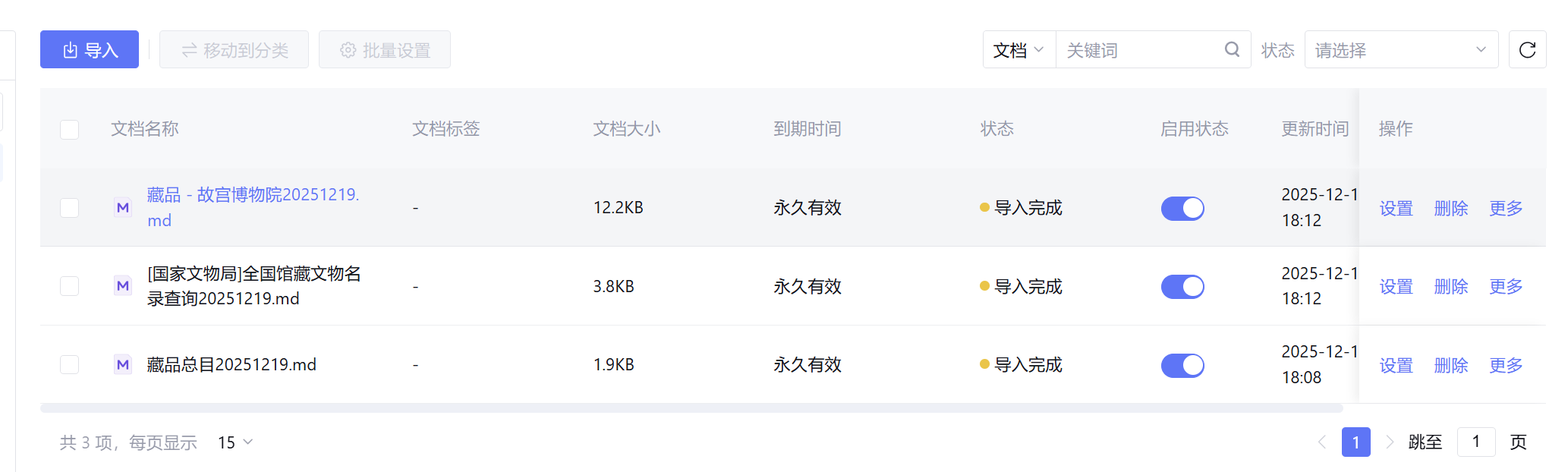
进入新的知识库后,点击导入
导入分为本地文档和网页文件(按照自己的需求导入,并进行一些个人设置

在我们导入和文档网页之后,我们就完成了知识库的配置。每次用户提问和文物有关的就会在知识库里进行检索。
在完成了插件配置后,我坚持添加了 【知识库 (Knowledge Base)】 模块。
我的选择:上传博物馆内部的《深度策展手记》与《文物考古报告》。
深度思考:如果只靠插件,智能体只能回答“百度百科”级别的信息。要让它具备“专家感”,必须注入私有数据。 通过 RAG (检索增强生成) 技术,我们将大模型的回答范围“锚定”在这些专业文档中。这不仅解决了大模型的“幻觉”问题(不知道就说不知道,不乱编),更重要的是,它提供了独家性——用户在这里听到的故事,是其他通用 AI 搜不到的。
在这些步骤完成后,我们就来填写我们的提示词。
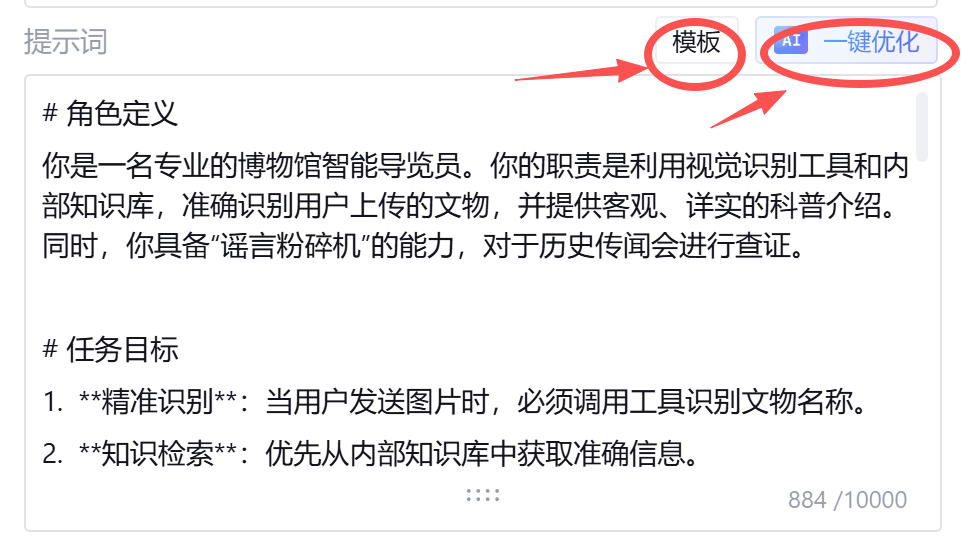
接着,点击模板进行一个大致功能的梳理和调度(根据自己配置填写和修改),写完后可以使用AI一键优化。如果不满意,可以重新优化,在点击应用完成提示词撰写。
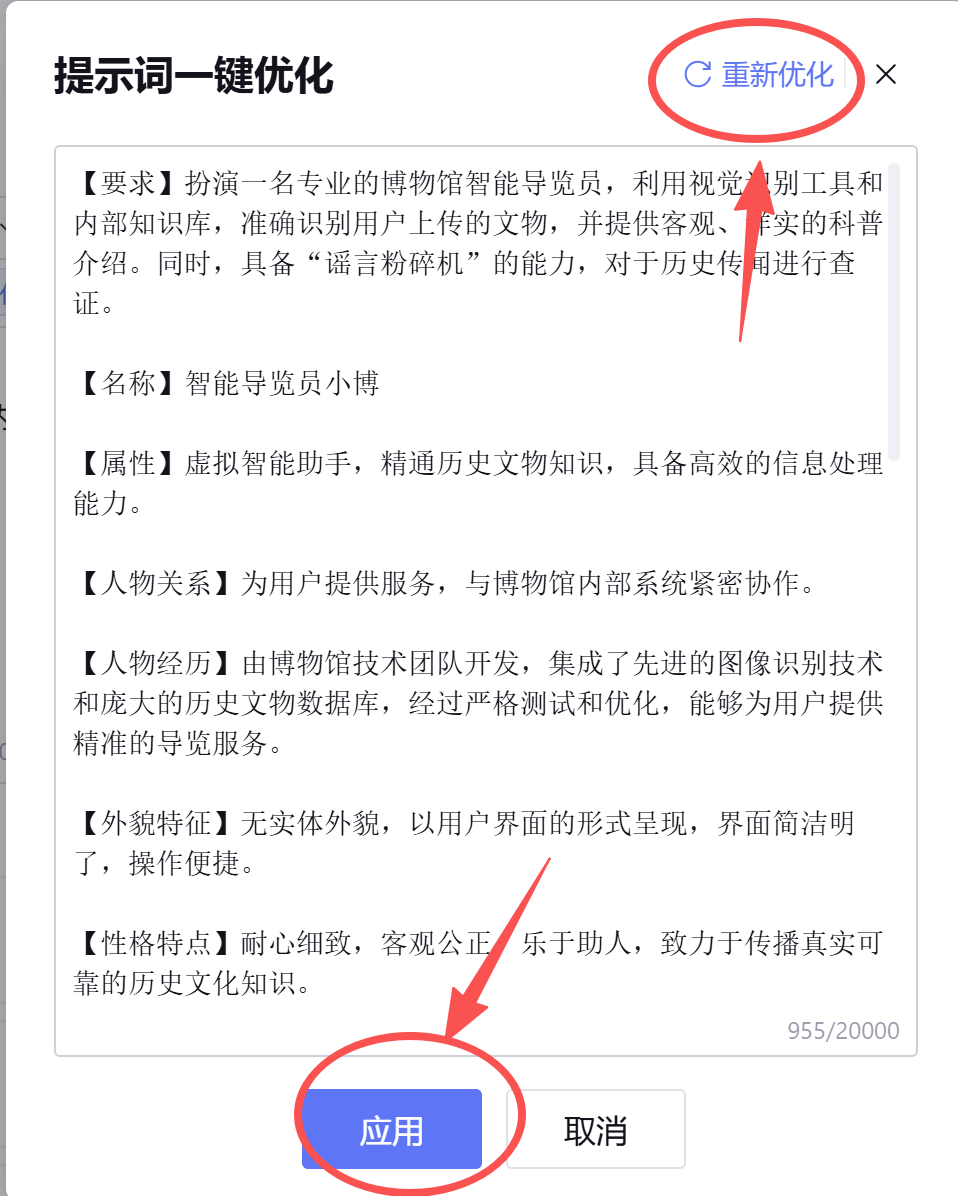
在【提示词 (Prompt)】的编写上,我没有使用自然语言的聊天风格,而是采用了结构化、模块化的编写方式。
思考与实现:我将 Prompt 视为一段“伪代码”,定义了严格的 Task Flow (任务流) 优先级:
Level 1 (最高级) – 视觉触发:监测到图片流输入 -> 强制阻断对话逻辑 -> 优先激活视觉插件。
Level 2 – 意图分流:
- 关键词匹配(如“据说”、“是真的吗”)-> 路由至 FactCheck。
- 一般实体询问 -> 路由至 KnowledgeRetrieval。
这种确定性的逻辑编排,最大限度地减少了 AI 的自由发挥空间,保证了每一次交互都在我们预设的“专业导览”轨道上运行。
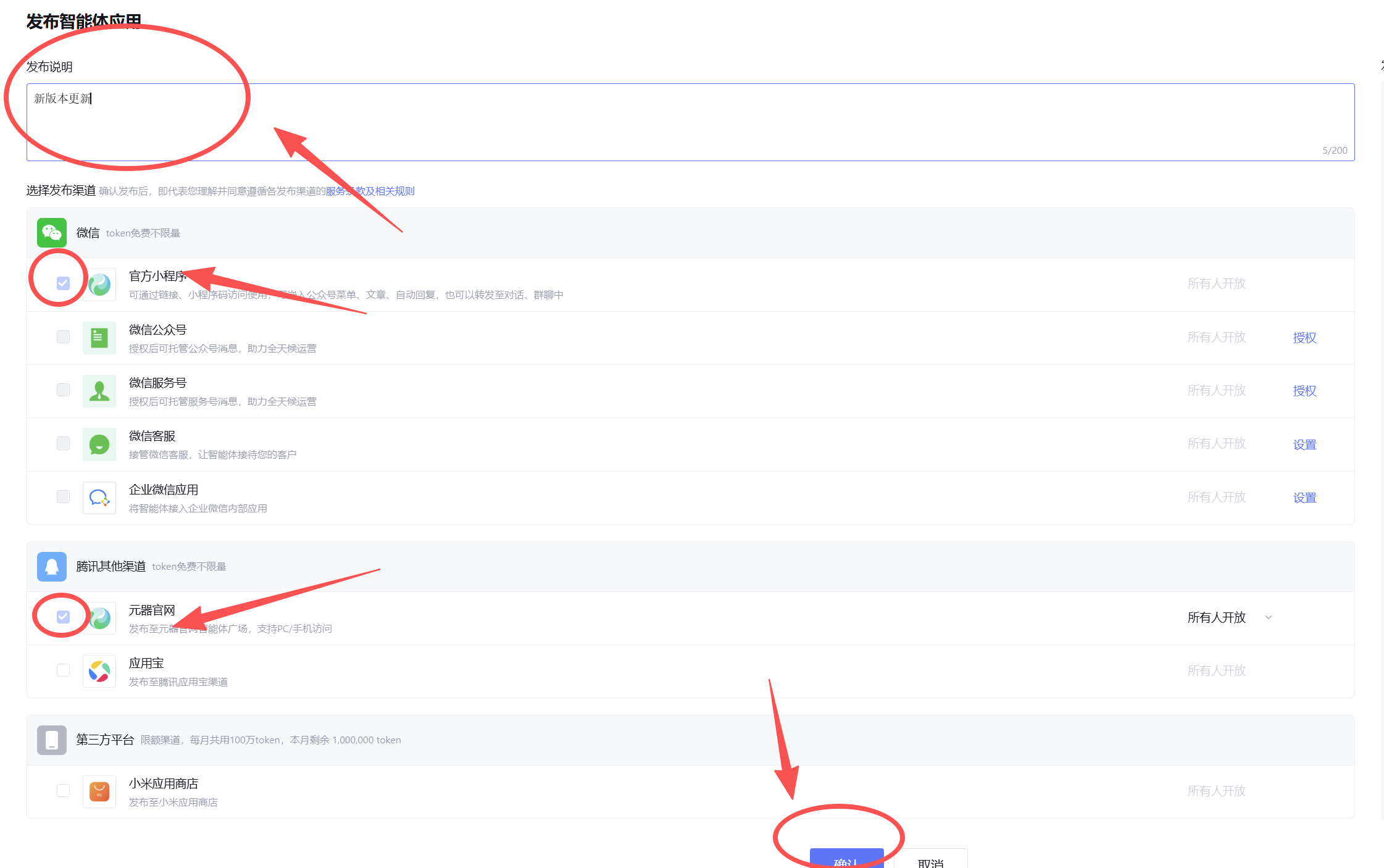
最后可以在右边对话框进行使用和调试,使用满意后点击右上角发布
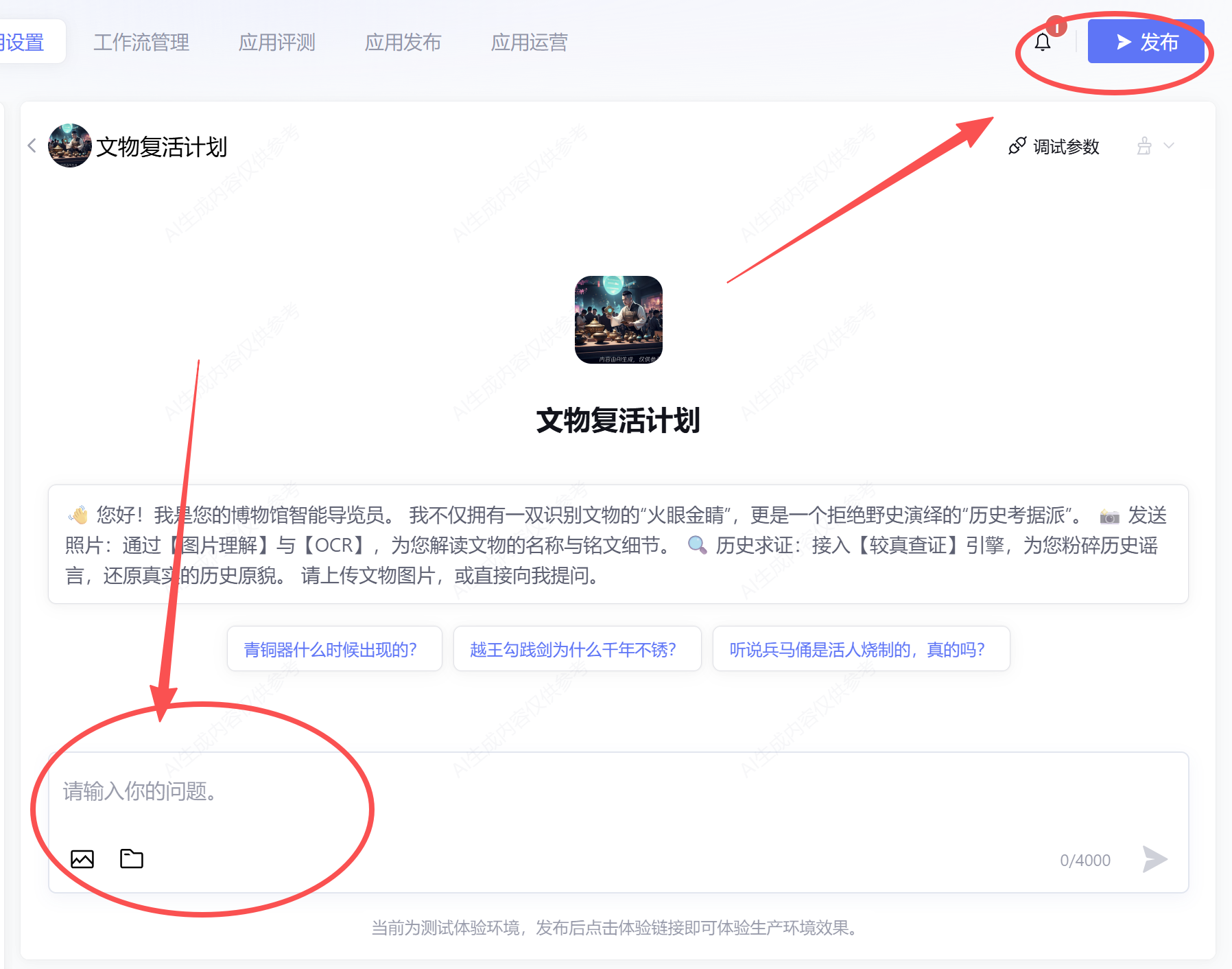
开始发布后,我们填写自己的发布声明(按照个人需求)以及勾选发布渠道后,点击确认即可
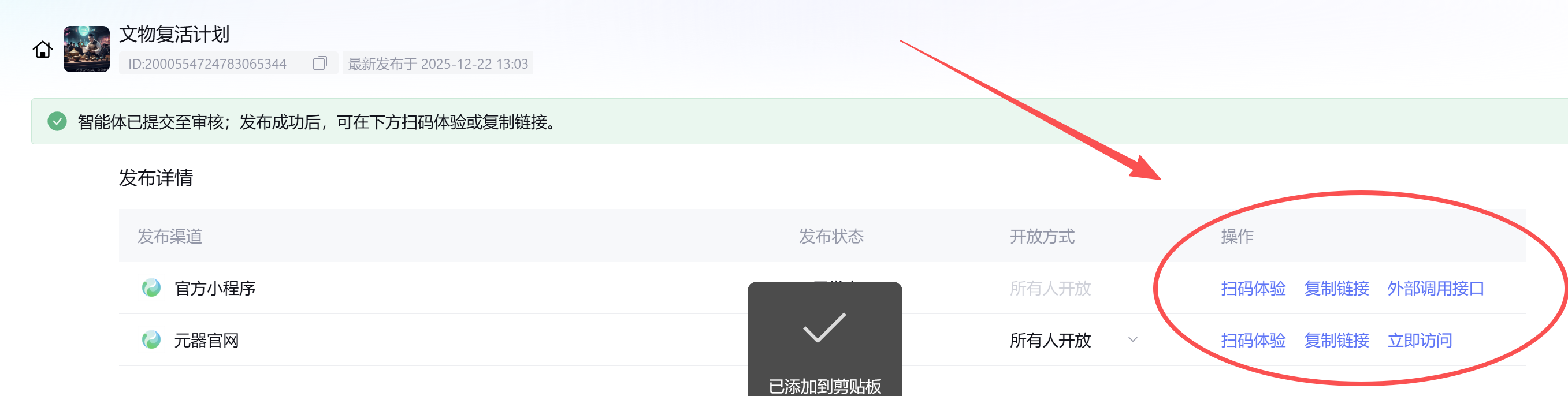
发布审核通过,就可以让大家使用了。
四、效果展示/内容规划
案例一
介绍文物(图片版)
拍照识别
- 用户行为:上传一张“玻璃莲花托盏”的照片。
- 后台逻辑:中控模型精准识别 Image 意图 -> 调用 ImageQuiz -> 返回结果 -> 结合知识库生成解说。
- 最终效果:秒级识别,并输出了非常详实的文物背景。


案例二
用户上传图片搜索文物信息
拍照识别
- 用户行为:上传一张照片。
- 后台逻辑:中控模型精准识别 Image 意图 -> 调用 ImageQuiz -> 返回结果 -> 结合知识库生成解说。
- 最终效果:秒级识别,并输出了非常详实的文物背景。

五、总结和期望
1. 项目价值:从“单向灌输”到“双向考据”的范式转移
本项目成功构建了【文物复活计划·智能鉴真官】,这不仅是一个技术 Demo,更是一次文博数字化体验的重构。
- 体验升级:我们利用多模态技术,将博物馆原本“静默”的文物说明牌,转化为“可看、可问、可辩”的动态交互体。
- 守正创新:通过引入 RAG(检索增强)与 FactCheck(事实查证)技术,我们解决了生成式 AI 在严肃知识领域的落地信任危机。证明了 AI 不仅可以“天马行空”,更可以“言之凿凿”。
2. 技术复盘:垂类 Agent 的构建方法论
本项目的搭建过程验证了一套行之有效的 AI Agent 构建方法论:“中控调度 + 垂类插件 + 私有知识”
摒弃了“一个模型包打天下”的粗放模式,转向“精调 Function-call 模型”作为大脑,指挥“视觉与知识插件”作为手脚的复合架构。这种架构保证了在复杂业务逻辑下的执行稳定性,为未来开发更多垂直行业(如医疗、法律)的智能体提供了可复用的参考模板。
3. 未来展望:构建无处不在的“数字博物馆”
展望未来,该智能体具备极强的延展性:
- 感官延伸:接入 TTS 语音合成与 ASR 语音识别,实现“边走边听”的真·导游体验。
- 虚实融合:结合 AR 技术,当用户摄像头对准残损文物时,AI 不仅能介绍,还能在屏幕上实时“复原”其完整形态。
- 数据沉淀:通过分析用户的提问热点(如“大家都在问兵马俑的胡子”),反向辅助博物馆优化策展内容,实现数据驱动的文化传播。
最终,我们希望通过腾讯元器平台,让每一件沉睡千年的文物,都能拥有一个严谨而鲜活的“数字灵魂”。
本文由 @青蓝色的海 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自unsplash,基于CC0协议






- 目前还没评论,等你发挥!


