
 起点课堂会员权益
起点课堂会员权益数据准备占80%时间?LLM能帮你把这块时间砍掉一半吗?
数据科学家60%-80%的时间都在处理数据准备,传统规则方法面对复杂现实数据时捉襟见肘。这篇爆火论文揭示了LLM如何用「理解」替代「规则」,实现数据清洗、集成与增强的范式变革,但也直面成本、幻觉与评估三大挑战。本文深度解析AI数据处理的革命性突破与残酷现实。
数据准备,真的是AI落地路上最大的隐形坑。
这篇最近很火的论文《Can LLMs Clean Up Your Mess?》,讲的就是这个问题。

数据准备为什么这么难?
论文开头有个数据挺扎心的:数据科学家60%-80%的时间都花在数据准备上。
这个数据我信。我自己的经验也是这样,真正用来建模、训练、优化的时间,可能就20%左右。
问题在于:传统的数据准备方法是规则驱动的。
你写SQL、写正则、写脚本,一条一条规则地处理数据。
但现实世界的数据太复杂了,规则永远写不完。
比如处理电话号码,你可能写了个规则:”所有电话号码都是11位”。
结果发现:
- 有些是区号+号码:”010-88888888″
- 有些是国际号码:”+86 138 8888 8888″
- 有些用横杠分隔:”138-8888-8888″
- 有些用空格分隔:”138 8888 8888″
规则就崩了。
你得继续加规则,但加着加着你就发现:规则越写越复杂,维护成本越来越高,最后连自己都不知道哪条规则在起作用。
这不是技术问题,是方法问题。
规则适合处理结构化、标准化的数据,但现实数据往往是混乱的、非结构化的、充满各种边缘情况的。
LLM带来的可能性
大模型的出现,给了数据准备一个新的可能性:用”理解”替代”规则”。
这不是换个写法,是范式转换。
传统方式:你告诉机器”怎么处理”——写几百条规则,机器照着规则做。
LLM方式:你告诉机器”要处理成什么样”——给几个例子,机器自己理解你的意图。
举个例子,处理客户名称:
传统方式:
if name contains “先生”:
remove “先生”
if name contains “(VIP)”:
remove “(VIP)”
if name contains “Mr.”:
remove “Mr.”
…
写了几十条规则,还是漏掉”Miss.”、”Ms.”、”Dr.”等各种情况。
LLM方式:
请把这些客户名称标准化,移除所有称呼和标记:
- “张三先生” → “张三”
- “李四 (VIP)” → “李四”
- “王五 Mr.” → “王五”
给几个例子,LLM就能理解你的意图,然后处理成千上万条数据。
这不是效率提升,是方法论改变。
论文的三大任务框架
论文把LLM数据准备分成了三类任务,这个框架挺清晰的:
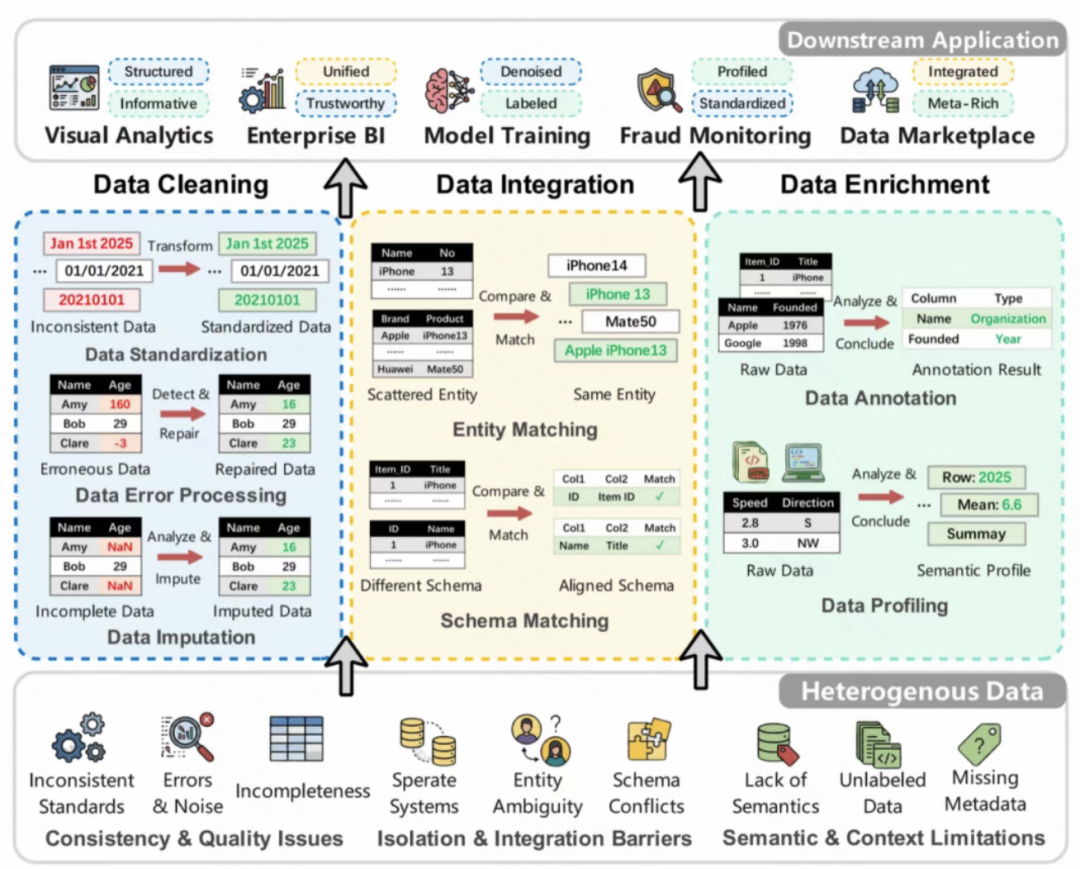
1. 数据清洗
核心目标:把脏数据洗干净。
包括:
- 标准化:统一格式(日期格式、电话号码格式、地址格式)
- 错误处理:识别和修复错误数据(拼写错误、格式错误、逻辑错误)
- 缺失值填充:根据上下文推断缺失的值
论文里有个例子挺有意思:处理地址数据。
传统方法用规则匹配邮政编码、城市名、街道名,但地址格式千奇百怪——有的”北京市朝阳区xxx路123号”,有的”朝阳区xxx路123号,北京市”,甚至有的”朝阳区xxx路123号 100000″。
LLM可以直接理解地址结构,自动提取和标准化。
我之前用GPT-4处理过地址数据,效果确实比规则强多了。
但问题也在这里:成本。
论文提到一个很现实的问题:LLM的调用成本太高了。
处理100万条数据,用规则可能几秒钟,成本几乎为0。用LLM可能要几个小时,成本几千甚至上万。
这个数据还挺猛的。企业真的愿意为这个买单吗?
2. 数据集成
核心目标:把不同来源的数据整合在一起。
包括:
- 实体匹配:识别不同数据源中的同一个实体(比如”张三”、”张三先生”、”Zhang San”是不是同一个人)
- 模式匹配:理解不同数据源的字段对应关系
论文引用了一个经典问题:实体匹配。
你有一份电商订单数据,客户叫”张三”;又有一份社交媒体数据,用户叫”Zhang San”。怎么判断是不是同一个人?
传统方法用字符串相似度——计算”张三”和”Zhang San”的编辑距离,如果超过某个阈值,就认为不是同一个人。
但这个方法显然有问题。”张三”和”Zhang San”拼音相同,显然是同一个人,但编辑距离很大。
LLM可以直接理解语义:它知道”张三”和”Zhang San”都是中文名字的拼音转写,可以通过其他信息(比如地址、电话号码、订单时间)判断是否是同一个人。
这个能力,传统方法很难做到。
但问题又来了:幻觉。
LLM可能会”过度自信”——它可能会把两个不同的实体误认为同一个,或者把同一个实体误认为两个不同的。
论文里提到一个实验:在实体匹配任务上,GPT-4的准确率是85%,但还是有15%的错误率。
这个15%可能还好,但在某些场景下(比如金融风控、医疗诊断),错误率就是不能接受的。
3. 数据增强
核心目标:从数据中提取更多价值。
包括:
- 数据标注:自动给数据打标签
- 数据画像:分析数据的特征和模式
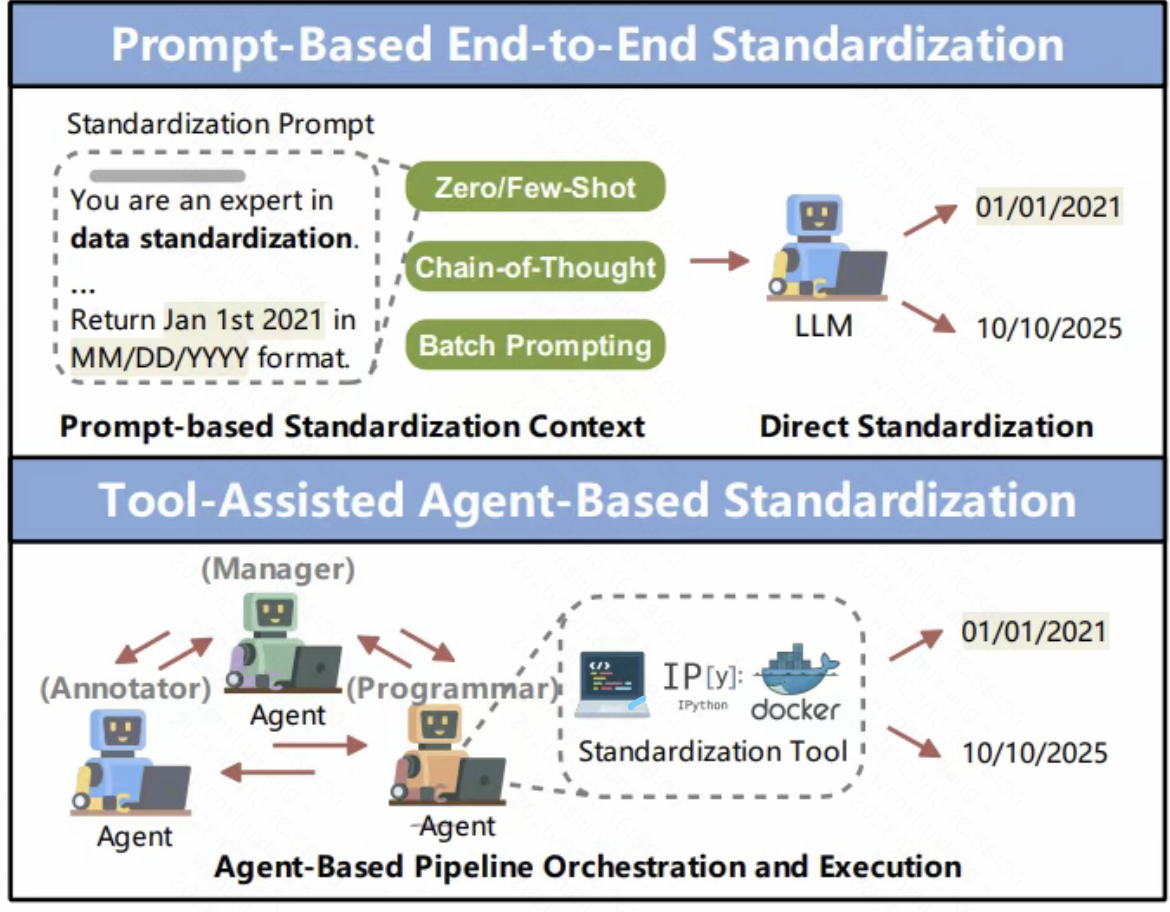
论文举了个例子:电商评论的情感分析。
传统方法用规则或者小模型——如果评论里有”好”、”不错”、”推荐”,就判断为正面评价。
但这个方法太粗浅了。比如”还行吧,比我想象中差一点”,这句话里有”还行”(中性偏正面),但整体其实是负面评价。
LLM可以直接理解上下文,准确判断情感倾向。
更厉害的是,LLM还能解释原因——它不仅能告诉你这条评论是正面还是负面,还能告诉你为什么(比如”提到了产品质量问题”)。
这个能力,传统方法完全做不到。
但问题还是那个:成本。
处理10万条评论,用规则可能几秒钟,用LLM可能要几个小时,成本上千。
企业真的愿意为这个买单吗?
哪些场景真的有用?
小批量、高价值的数据
比如你有一个1000行的客户数据,每个客户都是高价值客户(比如VIP、大客户)。这种情况下,花点钱用LLM仔细处理是值得的。
规则很难写、但人类很容易理解的场景
比如处理自然语言文本——识别一段话中的关键信息、判断情感倾向、提取实体。这种场景,规则根本写不出来,或者写出来效果很差。
需要灵活性的场景
比如你今天要处理”北京、上海、广州”的地址格式,明天要处理”成都、重庆、西安”的地址格式。规则要改,LLM只需要给几个新例子。
不能用的场景
大批量、低价值的数据
比如你有1000万条日志数据,这些数据只是为了做简单分析。这种情况下,用规则几秒钟搞定,用LLM可能要几天,成本几万。
规则简单、效果好的场景
比如处理电话号码、身份证号这种标准化数据。规则几行代码就能搞定,没必要用LLM。
对准确率要求极高的场景
比如金融风控、医疗诊断。这种场景下,LLM的15%错误率是不可接受的。
论文提到的挑战
论文不只是讲LLM有多强,也坦诚地提到了很多挑战。
1. 成本问题
LLM的调用成本太高了。处理100万条数据,成本可能几千甚至上万。
论文提到一个研究:在数据清洗任务上,用LLM比用传统方法贵100倍以上。
这个数字让我有点意外。我以为也就是10倍、20倍,没想到这么夸张。
2. 幻觉问题
LLM会”瞎编”。在数据准备任务上,这可能表现为:
把错误数据”修复”成错误的结果
把不同的实体误认为同一个
把同一个实体误认为不同的
论文提到:即使是最先进的LLM,在数据准备任务上的错误率仍然在10%-20%之间。
3. 评估问题
这个问题可能比前两个更严重。
我们怎么知道LLM做对了没有?
数据准备任务不像分类任务,有明确的标签。你要评估”数据清洗”的结果,得有人工审核,或者有一个”黄金标准”。
但人工审核的成本太高了,而构建”黄金标准”本身又需要大量人力。
论文提到一个很现实的问题:很多论文的评估方法都很弱——有的只在小数据集上测试,有的用简单的规则作为基准,有的甚至没有对比实验。
最后
回到开头那个问题:LLM能帮你把数据准备的时间砍掉一半吗?
关键在于:
- 数据的体量有多大?
- 数据的复杂度有多高?
- 数据的价值有多高?
- 对准确率的要求有多高?
如果是小批量、高价值、复杂度高、准确率要求不是极致的场景,LLM确实可以大幅减少时间成本。
但如果是大批量、低价值、复杂度低、准确率要求极高的场景,传统方法可能还是更优选择。
论文里有一句话我挺认同的:
“LLM-enhanced methods are rapidly becoming a transformative and potentially dominant paradigm for data preparation.”
LLM确实在改变数据准备的范式,但这个”transformative”是渐进的,不是一夜之间的颠覆。
参考资料:
论文原文:https://arxiv.org/abs/2601.17058
GitHub项目:https://github.com/weAIDB/awesome-data-llm
本文由 @卡萨丁AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


