
 起点课堂会员权益
起点课堂会员权益万字拆解Prompt Engineering的进化史:从手工调优到自动优化
本文深入剖析提示工程从Zero-Shot到Chain-of-Thought、Tree-of-Thoughts,再到APE、OPRO、DSPy等自动优化技术的演进历程,解读这场静默但深刻的AI交互范式革命。

2020年,当GPT-3横空出世时,人们惊讶地发现,仅仅通过改变输入的措辞,就能让同一个模型表现出截然不同的能力。这种通过精心设计输入来引导模型输出的技术,被称为Prompt Engineering(提示工程)。
五年过去,Prompt Engineering已经从一门”玄学”发展成为系统化的工程学科。从最初的手工调优,到思维链(Chain-of-Thought)的引入,再到思维树(Tree-of-Thoughts)的探索,直至今天自动提示优化(APE、OPRO)和编程式提示框架(DSPy)的兴起——提示工程正在经历一场从”艺术”到”科学”的范式转移。
这场变革的核心驱动力是什么?
答案很简单:效率与规模化。
手工设计提示词耗时耗力,且难以复用。当企业需要将大模型应用于数百个不同场景时,手工调优的方式显然无法规模化。自动提示优化技术的出现,让机器能够自动发现最优提示,大大降低了应用门槛。
这场变革不仅仅是技术层面的创新,更是对整个AI应用开发范式的重新定义。在过去,开发者需要花费大量时间调试提示词,尝试各种措辞和格式。而现在,自动优化技术可以在几分钟内找到比人工设计更好的提示。这种效率提升将极大地推动大模型在各个行业的应用。
同时,提示工程的发展也正在改变人机交互的方式。从命令行到图形界面,再到自然语言交互,提示工程正在成为新一代人机交互的核心技术。未来的用户可能不需要学习复杂的软件操作,只需要用自然语言描述需求,AI就能自动完成任务。
本文将带你穿越这场Prompt Engineering演进的时间线,深入理解:
- Zero-Shot和Few-Shot提示为何能成为基础范式?
- Chain-of-Thought如何开启推理能力的新篇章?
- Tree-of-Thoughts如何模拟人类的多路径思考?
- 自动提示优化(APE、OPRO)如何实现提示的自动发现?
- DSPy等编程式框架如何重新定义提示工程?
通过本文的阅读,你将系统性地了解Prompt Engineering从诞生到成熟的完整历程,掌握各种提示技术的原理和应用场景,为实际工作中的大模型应用打下坚实基础。
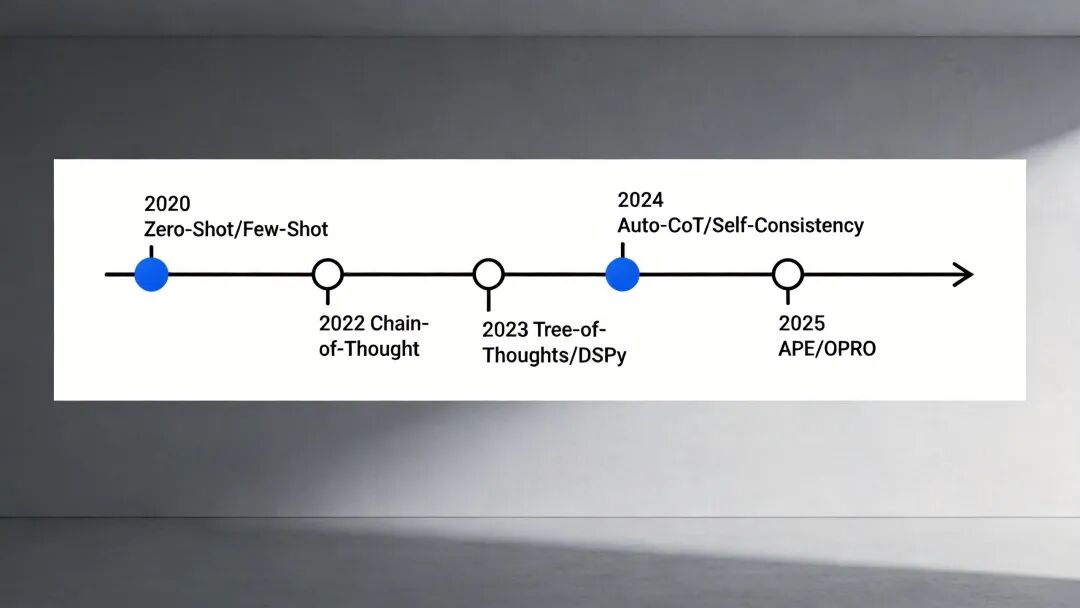
图1:Prompt Engineering演进时间线(2020-2025)
一、基础范式——Zero-Shot与Few-Shot
1.1 Zero-Shot Prompting:零样本提示
Zero-Shot Prompting(零样本提示)是最基础的提示方式,即直接向模型提出问题,不提供任何示例。这种方式依赖于模型在预训练阶段学到的知识。
Zero-Shot的核心假设是:模型已经通过海量预训练数据学会了各种任务的”模式”,只需要通过恰当的指令就能激活这些能力。
示例:
输入:将以下中文翻译成英文:”今天天气很好。”
输出:”The weather is nice today.”
Zero-Shot的优势在于简单直接,无需准备示例。但缺点也很明显:对于复杂任务,模型可能无法准确理解任务要求,导致输出质量不稳定。
在实际应用中,Zero-Shot适合那些模型在预训练阶段已经充分学习过的任务,如简单的翻译、摘要、分类等。但对于需要特定格式输出或领域知识的任务,Zero-Shot往往表现不佳。
为了提升Zero-Shot的效果,研究者提出了一些技巧:
- 角色设定:在提示中明确模型的角色,如”你是一位资深翻译专家”
- 任务描述:详细描述任务要求和输出格式
- 分步指令:将复杂任务分解为多个步骤
1.2 Few-Shot Prompting:少样本提示
Few-Shot Prompting(少样本提示)通过在提示中提供几个输入-输出示例,让模型”学习”任务的模式。这种方式利用了大模型的上下文学习(In-Context Learning)能力。
2020年,OpenAI在GPT-3论文中首次系统性地展示了Few-Shot Learning的威力。他们发现在某些任务上,仅需提供几个示例,GPT-3就能达到甚至超越专门微调模型的效果。
示例:
输入:将以下中文翻译成英文:
中文:你好。
英文:Hello.
中文:谢谢。
英文:Thank you.
中文:今天天气很好。
英文:
Few-Shot的关键在于示例的选择。研究表明,示例的质量、多样性、顺序都会影响模型表现。一个好的Few-Shot示例应该:
- 清晰明确:输入和输出的对应关系一目了然
- 覆盖边界情况:包含各种可能的输入类型
- 格式一致:所有示例遵循相同的格式
关于示例的数量,研究表明通常3-5个示例就能取得不错的效果,过多的示例并不一定能带来更好的性能,反而会增加token消耗。示例的顺序也有影响——将最清晰的示例放在前面通常效果更好。
此外,示例与测试样本的相似度也很重要。如果示例与测试样本在语义上更接近,模型的表现通常会更好。这启发了后来的动态示例选择技术,即根据输入动态选择最相关的示例。
在实际应用中,Few-Shot提示的设计需要考虑多个因素。首先是示例的质量——示例应该清晰、准确、有代表性。其次是示例的多样性——应该覆盖任务的各种可能情况。最后是示例的顺序——通常将最清晰的示例放在前面效果更好。
1.3 Zero-Shot vs Few-Shot:如何选择?
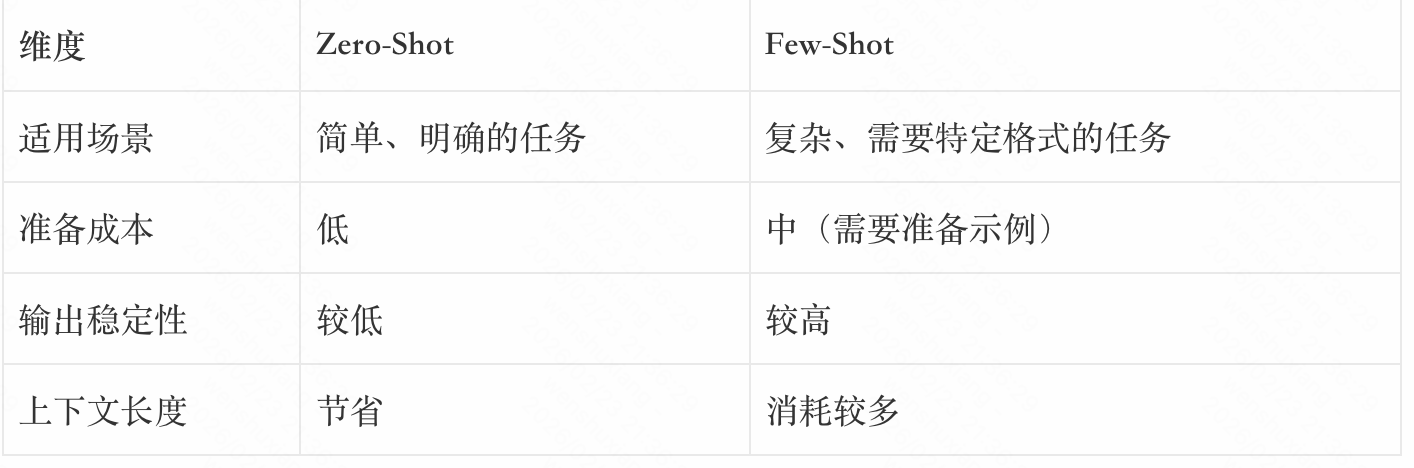
在实际应用中,建议先从Zero-Shot开始,如果效果不理想,再尝试Few-Shot。对于需要严格输出格式的任务(如JSON输出),Few-Shot通常是更好的选择。
二、推理革命——Chain-of-Thought
2.1 思维链的诞生
2022年1月,Google研究院的Jason Wei等人在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中提出了Chain-of-Thought(CoT,思维链)技术,开启了提示工程的新篇章。
CoT的核心思想是:让模型在给出最终答案之前,先生成中间推理步骤。这类似于人类解决复杂问题时的”草稿纸”思维——我们不会直接写出答案,而是先一步步推导。
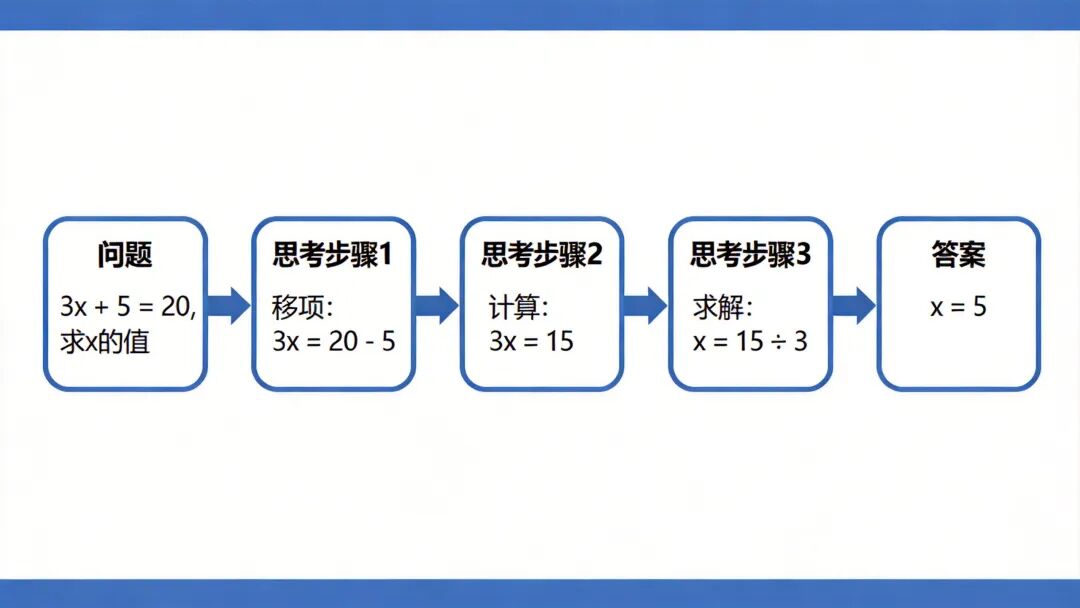
图2:Chain-of-Thought思维链示意图
2.2 CoT的工作原理
CoT通过在Few-Shot示例中加入推理过程,引导模型生成类似的推理链。
标准Few-Shot示例:
Q: 罗杰有5个球,又买了2罐,每罐3个球。他现在有几个球?A: 11
CoT Few-Shot示例:
Q: 罗杰有5个球,又买了2罐,每罐3个球。他现在有几个球?A: 罗杰开始有5个球。2罐每罐3个球,共6个球。5+6=11。答案是11。
当模型看到带有推理过程的示例后,它会模仿这种风格,在回答新问题时也先生成推理过程,再给出答案。
2.3 CoT的效果
论文显示,CoT在多个推理基准上带来了显著提升:
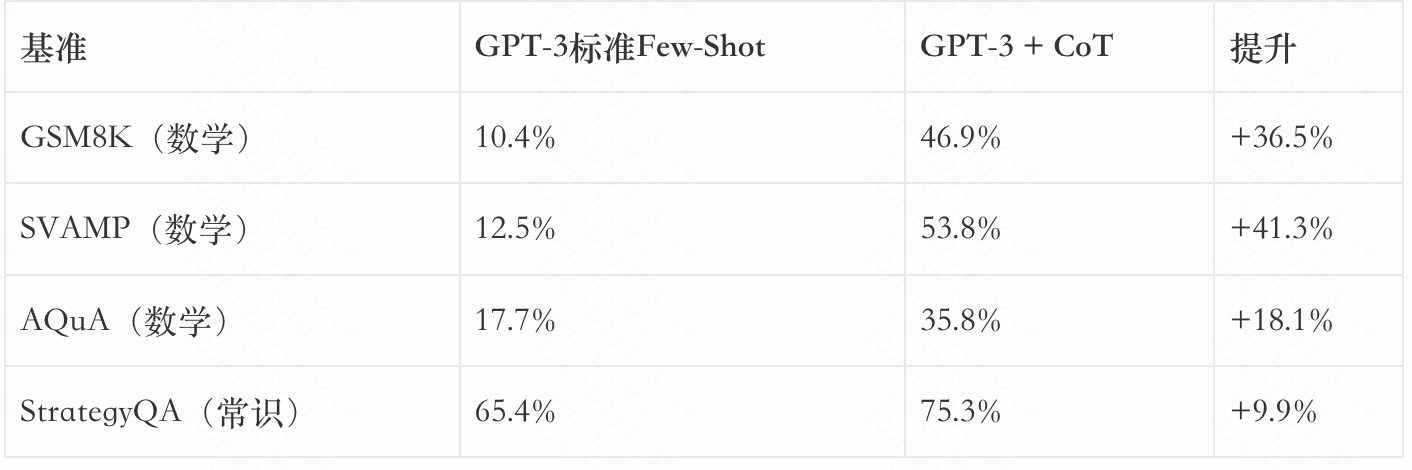
CoT的效果在大型模型上尤为明显。研究表明,模型参数量需要达到约100B,CoT才能发挥显著作用。这提示我们:CoT需要模型具备足够的知识容量和推理能力。
CoT的成功不仅在于提升了准确性,还在于增强了可解释性。通过查看模型的推理步骤,我们可以理解模型是如何得出结论的,这对于调试和改进模型非常重要。如果模型在某个步骤出错,我们可以针对性地改进提示,引导模型朝正确的方向思考。
2.4 Zero-Shot CoT:无需示例的思维链
2022年5月,Kojima等人在论文《Large Language Models are Zero-Shot Reasoners》中提出了Zero-Shot CoT技术。他们发现,只需要在问题后加上一句”Let’s think step by step“(让我们一步步思考),就能触发模型的推理能力。
示例:
Q: 罗杰有5个球,又买了2罐,每罐3个球。他现在有几个球?Let’s think step by step.
这种方法的惊人之处在于:无需任何示例,仅通过一句简单的指令,就能激活模型的推理能力。这大大降低了CoT的应用门槛。
后续研究还发现,不同措辞的效果有所差异。例如,”Let’s work through this step by step”在某些任务上可能比”Let’s think step by step”效果更好。这催生了一个有趣的研究方向:提示词优化。
Zero-Shot CoT的优势在于简单直接,无需准备示例。但它的效果通常不如Few-Shot CoT稳定,因为模型需要自己”领悟”如何生成推理步骤。对于复杂任务,Few-Shot CoT通常是更好的选择。
CoT的成功揭示了一个重要洞察:显式推理对于复杂任务至关重要。模型不仅需要知道答案,还需要知道如何得到答案。这种显式推理不仅提升了准确性,还增强了可解释性——我们可以检查模型的推理过程,发现错误所在。
在实际应用中,CoT特别适合以下场景:
- 数学问题:需要逐步计算的算术、代数、几何问题
- 逻辑推理:需要多步推理的逻辑谜题、常识推理
- 代码生成:需要逐步思考的算法设计、调试
- 复杂决策:需要权衡多个因素的决策问题
三、探索与决策——Tree-of-Thoughts
3.1 从线性到树状
2023年,Yao等人和Long几乎同时提出了Tree-of-Thoughts(ToT,思维树)框架,将CoT从线性推理扩展到树状探索。
CoT的一个局限是:一旦开始推理,就只能沿着单一路径前进,无法回溯或探索其他可能性。这与人类解决复杂问题的方式不同——我们往往会尝试多种思路,比较后再做决定。
ToT的核心思想是:维护一个思维树,每个节点代表一个中间推理状态,模型可以探索多条路径,评估后选择最优路径。
3.2 ToT的四个核心步骤
ToT框架包含四个关键步骤:
1. 分解(Decomposition)
将复杂问题分解为多个中间步骤。例如,解决”24点游戏”可以分解为:选择两个数字→应用运算→得到中间结果→重复直到得到24。
2. 生成(Generation)
从当前状态生成多个候选下一步。例如,给定数字[4, 9, 10, 13],可以生成多个候选:4+9=13、9-4=5、10*4=40等。
3. 评估(Evaluation)
评估每个候选的价值。模型可以自我评估,也可以使用独立的评估模型。评估可以是数值分数(0-10),也可以是相对排序(A比B好)。
4. 搜索(Search)
使用搜索算法(如BFS、DFS)在思维树中探索。模型可以选择最有希望的路径深入,也可以回溯尝试其他路径。
3.3 ToT的效果
论文显示,ToT在需要探索的复杂任务上显著优于CoT:
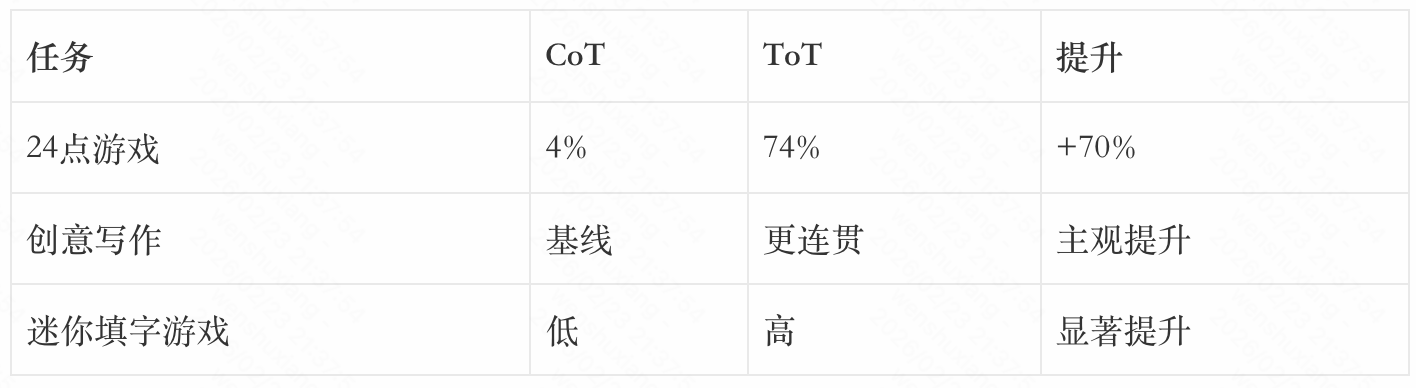
ToT的优势在于能够探索多种可能性、进行自我评估、必要时回溯。这更接近人类的深思熟虑过程。
3.4 ToT的局限
ToT的代价是更高的计算成本。由于需要生成和评估多个候选,ToT通常需要调用模型多次,成本远高于单次CoT。
此外,ToT需要设计合适的分解策略、生成方法、评估标准和搜索算法,这增加了应用复杂度。因此,ToT更适合那些值得投入额外计算成本的复杂任务。
ToT的应用场景包括:
- 创意写作:探索不同的情节发展方向,选择最吸引人的故事线
- 游戏策略:评估不同的走法,选择胜率最高的策略
- 数学证明:尝试不同的证明路径,找到最简洁的证明
- 决策制定:比较不同方案的优劣,做出最优决策
在实际应用中,ToT的效果很大程度上取决于评估函数的设计。一个好的评估函数应该能够准确判断中间状态的价值,引导搜索朝着正确的方向进行。
四、行动与推理——ReAct
4.1 推理与行动的结合
2022年10月,Yao等人在论文《ReAct: Synergizing Reasoning and Acting in Language Models》中提出了ReAct框架,将推理(Reasoning)与行动(Acting)结合起来。
ReAct的核心思想是:模型不仅应该能够推理,还应该能够根据推理结果采取行动,并根据行动反馈调整推理。
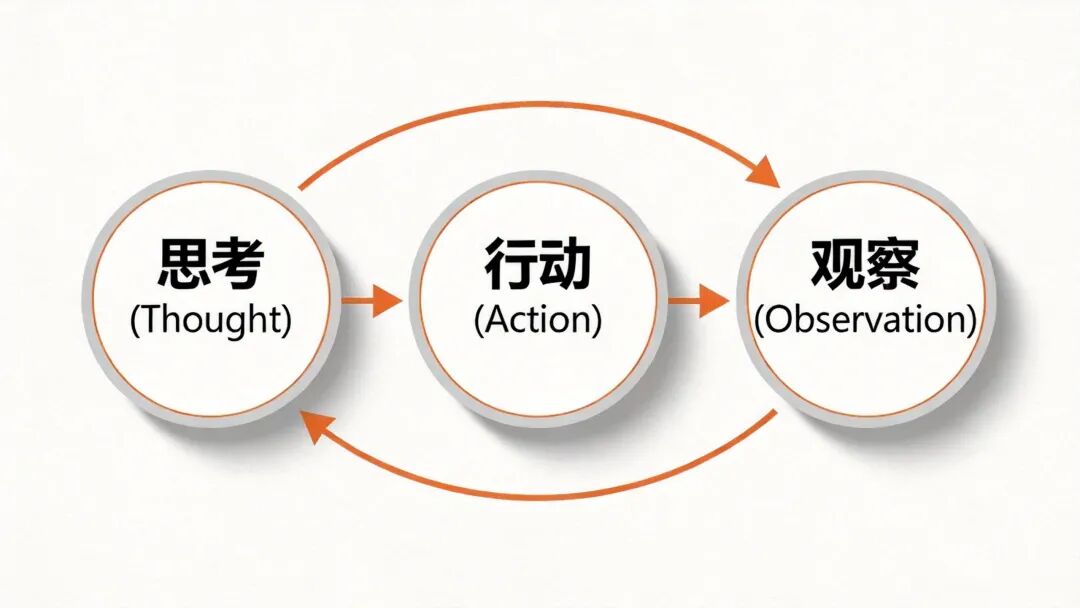
图3:ReAct推理-行动-观察循环
4.2 ReAct的循环结构
ReAct遵循一个循环结构:
思考(Thought)→行动(Action)→观察(Observation)→思考(Thought)→…
示例(问答任务):
问题:2024年奥斯卡最佳影片是什么?思考:我需要搜索2024年奥斯卡最佳影片的信息。行动:搜索[2024年奥斯卡最佳影片]观察:搜索结果:《奥本海默》获得2024年第96届奥斯卡最佳影片奖。思考:我已经找到了答案。答案:《奥本海默》
ReAct的关键在于行动。模型可以调用外部工具(如搜索引擎、计算器、API)来获取信息,然后根据观察结果继续推理。
4.3 ReAct的应用场景
ReAct特别适合以下场景:
- 知识密集型任务:需要查询外部知识库
- 工具使用:需要调用计算器、代码解释器等工具
- 多步骤任务:需要分解为多个子任务并逐步执行
ReAct为后来的Agent框架奠定了基础。今天的许多AI Agent(如AutoGPT、LangChain Agent)都采用了类似的推理-行动循环结构。
ReAct的优势在于将推理与外部世界连接起来。模型不再是孤立的文本生成器,而是能够与外部环境交互的智能体。这种能力对于需要实时信息或复杂操作的任务至关重要。
ReAct的挑战在于需要设计合适的工具接口和错误处理机制。当工具调用失败或返回意外结果时,模型需要能够优雅地处理这些情况。
五、自动优化——APE与OPRO
5.1 从手工到自动:APE
2022年9月,Zhou等人在论文《Large Language Models Are Human-Level Prompt Engineers》中提出了APE(Automatic Prompt Engineer,自动提示工程师)技术。
APE的核心思想是:使用大模型自动生成和优化提示词。具体来说,APE包含三个步骤:
- 生成候选提示:使用大模型根据任务描述和示例,生成多个候选提示。
- 评估候选提示:在验证集上评估每个候选提示的效果。
- 选择最优提示:选择效果最好的提示作为最终提示。
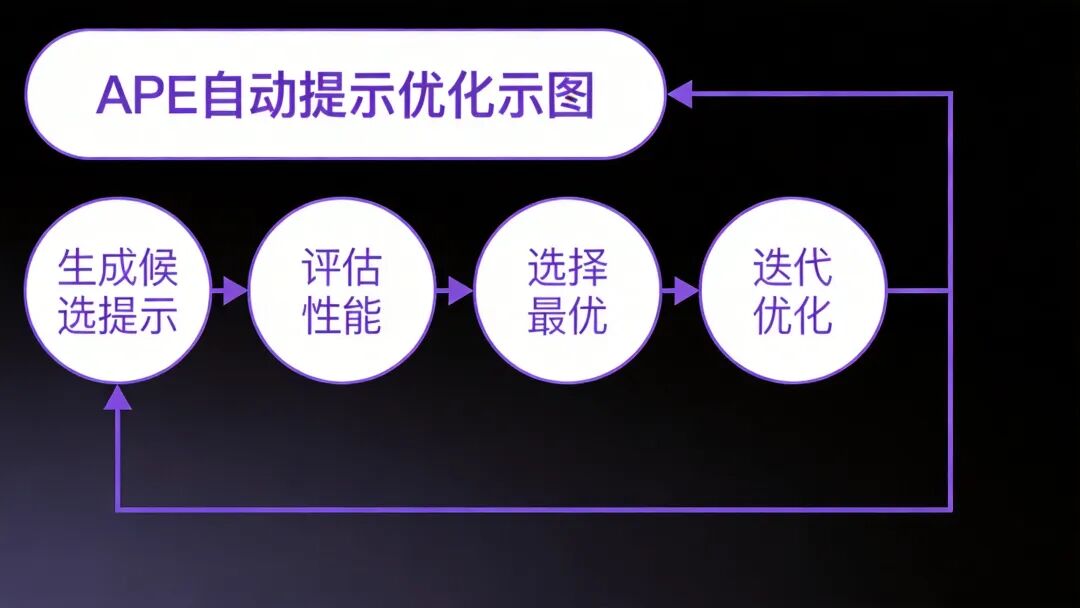
图4:APE自动提示优化流程
5.2 APE的效果
论文显示,APE生成的提示在多个任务上超越了人工设计的提示:
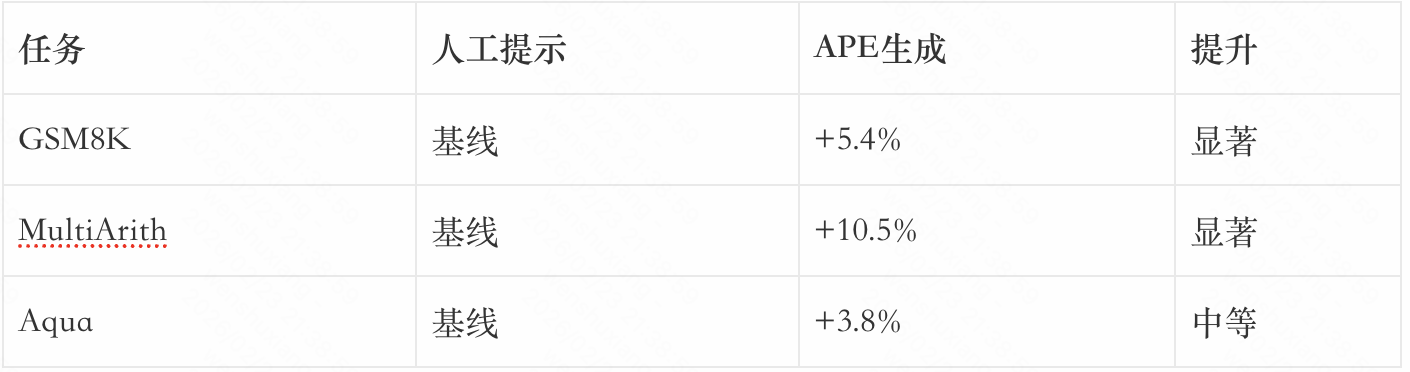
APE的惊人之处在于,它生成的提示有时比专家设计的提示效果更好。例如,APE发现”Let’s work through this problem step by step”在某些任务上比”Let’s think step by step”效果更好。
5.3 OPRO:提示即优化
2023年9月,Google DeepMind的Yang等人在论文《Large Language Models as Optimizers》中提出了OPRO(Optimization by PROmpting)技术。
OPRO将提示优化视为一个优化问题:给定一个任务,寻找能够最大化任务准确率的提示。与APE不同,OPRO采用迭代优化的方式:
- 初始化:从一些初始提示开始。
- 生成新提示:让模型根据历史提示及其效果,生成新的候选提示。
- 评估:评估新提示的效果。
- 迭代:重复步骤2-3,直到收敛或达到迭代次数上限。
OPRO的核心洞察是:大模型不仅可以作为任务执行者,还可以作为优化器。通过让模型”反思”历史提示的优缺点,它可以生成更好的新提示。
5.4 OPRO的效果
论文显示,OPRO在提示优化任务上取得了令人瞩目的效果:
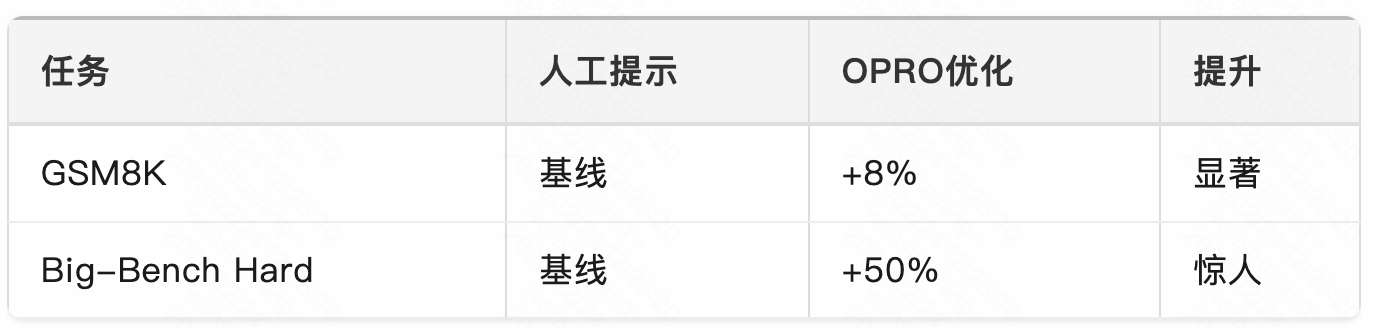
OPRO发现的提示有时非常出人意料。例如,在情感分析任务上,OPRO发现的一个有效提示是:”You are an expert at sentiment analysis. Analyze the sentiment of the following text with great care and precision.”(你是情感分析专家,仔细分析以下文本的情感。)
这种”角色扮演”式的提示,虽然简单,但在某些任务上效果显著。OPRO的优势在于能够自动发现这类非直观的提示技巧。
APE和OPRO代表了提示工程的一个重要方向:自动化。它们让机器能够自动发现最优提示,大大降低了人工调优的成本。对于需要为大量任务设计提示的企业而言,这种自动化能力具有重要价值。
然而,自动优化也有其局限。首先,它需要大量的验证数据来评估候选提示的效果。其次,优化过程本身需要多次调用模型,成本不菲。最后,自动发现的提示有时难以解释,不利于调试和维护。
六、编程式提示——DSPy
6.1 提示工程的痛点
传统的提示工程存在诸多痛点:
- 难以模块化:提示词通常是长字符串,难以复用和组合
- 缺乏抽象:每个任务都需要从头设计提示
- 优化困难:手动调优耗时耗力,且难以找到最优解
- 与代码割裂:提示词嵌入在字符串中,难以版本控制和测试
2023年,斯坦福大学的研究者提出了DSPy框架,试图用编程的方式解决这些问题。
6.2 DSPy的核心理念
DSPy将提示工程从”字符串操作”提升为”模块化编程”。其核心思想是:
1. 签名(Signature):定义输入输出类型,而非具体的提示词。
class Translate(dspy.Signature): “””Translate Chinese to English.””” chinese = dspy.InputField() english = dspy.OutputField()
2. 模块(Module):封装可复用的提示逻辑。
translator = dspy.ChainOfThought(Translate)result = translator(chinese=”今天天气很好”)
3. 优化器(Optimizer):自动优化提示词和示例。
optimizer = dspy.BootstrapFewShot()optimized = optimizer.compile(translator, trainset)
DSPy的优势在于声明式编程:开发者只需要定义”做什么”(签名),而不需要关心”怎么做”(具体的提示词)。优化器会自动找到最优的提示策略。
DSPy的出现标志着提示工程从”字符串操作”向”编程范式”的转变。这种转变带来了诸多好处:
- 模块化:提示逻辑可以封装为可复用的模块
- 可测试:提示可以像代码一样进行单元测试
- 可版本控制:提示的变更可以纳入版本控制系统
- 可优化:提示可以像模型一样进行自动优化
这种转变对于企业应用具有重要意义。在过去,提示词通常是散落在各个代码文件中的字符串,难以管理和维护。而现在,提示可以像代码一样进行版本控制、代码审查、单元测试,大大提升了可维护性。
此外,DSPy的声明式编程范式还带来了另一个好处:可读性。通过阅读签名,开发者可以快速理解一个模块的功能,而无需阅读冗长的提示词。这对于团队协作和代码维护非常有帮助。
6.3 DSPy的优化器
DSPy提供了多种优化器:
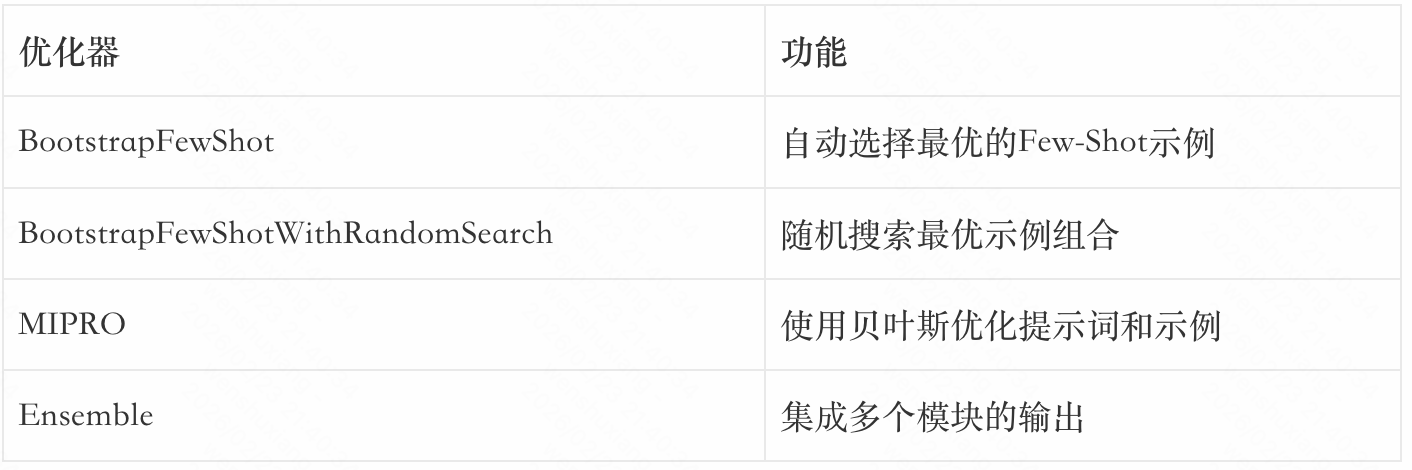
这些优化器让开发者可以像调优机器学习模型一样调优提示工程流程,大大降低了应用门槛。
例如,BootstrapFewShot会自动从训练集中选择最有价值的示例,而MIPRO会使用贝叶斯优化来同时优化提示词和示例。这些优化过程都是自动化的,开发者只需要提供训练数据和评估指标,就能得到优化后的提示。
6.4 DSPy的意义
DSPy代表了提示工程的一个重要方向:从手工调优到编程式优化。它将提示工程纳入软件工程的范畴,使得提示可以像代码一样模块化、可测试、可版本控制。
对于企业应用而言,DSPy的价值在于规模化:当需要为数百个不同任务设计提示时,手工调优是不现实的,而DSPy的自动优化能力可以大大提升效率。
DSPy的出现标志着提示工程从”艺术”到”工程”的转变。这种转变对于推动大模型的商业化应用具有重要意义。只有当提示工程变得可管理、可维护、可优化时,大模型才能真正融入企业的软件开发生命周期。
DSPy的另一个价值在于可移植性。由于提示逻辑与具体模型解耦,你可以轻松地将一个为GPT-4设计的提示迁移到Claude或Llama上,而无需重写大量代码。这种可移植性对于避免供应商锁定非常重要。
七、技术演进的核心逻辑
7.1 从简单到复杂
回顾Prompt Engineering的演进历程,我们可以看到一个清晰的脉络:
Zero-Shot → Few-Shot → Chain-of-Thought → Tree-of-Thoughts → 自动优化
这个演进的核心驱动力是任务复杂度的提升。随着大模型被应用到越来越复杂的任务上,简单的提示方式已经无法满足需求,需要更复杂的提示技术来引导模型。
这种演进也反映了我们对大模型能力认识的深化。最初,我们认为模型只需要知道答案。后来,我们发现模型需要知道如何得到答案。现在,我们认识到模型还需要能够探索多种可能性、评估不同方案、必要时回溯调整。
图5:不同提示技术的复杂度与效果对比
7.2 从手工到自动
另一个重要的演进方向是从手工调优到自动优化:
手工设计 → APE → OPRO → DSPy优化器
这个演进的核心驱动力是规模化需求。当企业需要将大模型应用到数百个场景时,手工调优每个场景的提示是不现实的。自动优化技术的出现,让机器能够自动发现最优提示,大大降低了应用门槛。
自动优化技术的另一个价值在于发现非直观的提示技巧。人工设计提示时,我们往往受限于经验和直觉,容易陷入思维定势。而自动优化可以探索更广阔的提示空间,发现一些人类难以想到的提示技巧。
7.3 从字符串到编程
DSPy的出现标志着提示工程从”字符串操作”向”编程范式”的转变。这种转变带来了诸多好处:
- 模块化:提示逻辑可以封装为可复用的模块
- 可测试:提示可以像代码一样进行单元测试
- 可版本控制:提示的变更可以纳入版本控制系统
- 可优化:提示可以像模型一样进行自动优化
八、实践指南与未来展望
8.1 如何选择提示技术?
在实际应用中,如何选择合适的提示技术?以下是一些建议:
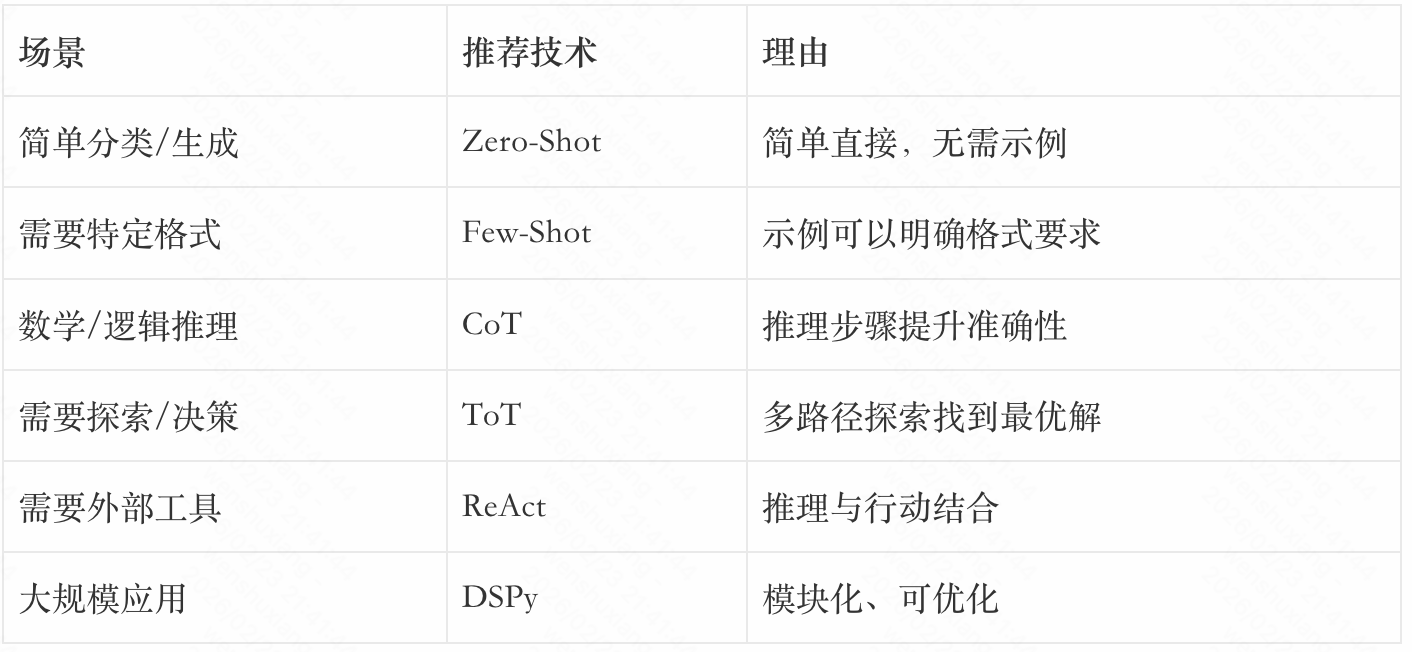
8.2 提示工程的最佳实践
1. 从简单开始
不要一开始就使用复杂的提示技术。先从Zero-Shot开始,如果效果不理想,再尝试Few-Shot,然后是CoT,依此类推。这种渐进式的方法可以帮助你理解问题的本质,避免过度工程化。
在实际项目中,建议建立一个提示优化的迭代流程:首先用Zero-Shot快速验证可行性,然后用Few-Shot提升稳定性,最后用CoT等高级技术解决复杂推理问题。
2. 设计好的示例
对于Few-Shot和CoT,示例的质量至关重要。好的示例应该清晰、多样、覆盖边界情况。
3. 迭代优化
提示工程是一个迭代过程。根据模型输出不断调整提示,直到达到满意的效果。
4. 考虑成本
复杂的提示技术(如ToT)通常需要更多的token和API调用。在效果提升和成本增加之间找到平衡。对于生产环境,建议进行成本效益分析,确保投入产出比合理。例如,如果ToT能将准确率从80%提升到90%,但成本增加了5倍,那么需要评估这10%的提升是否值得。
5. 记录和版本控制
提示的变更应该像代码一样进行版本控制。记录每次变更的原因和效果,便于回溯和协作。建议使用Git等版本控制系统管理提示,并在提交信息中说明变更的原因和预期效果。
6. 建立评估体系
建立标准化的评估流程,用数据驱动提示优化。避免凭感觉调优,而是用A/B测试等方法验证效果。建议建立一套评估指标,如准确率、召回率、F1分数等,并定期运行评估来监控提示的效果。
8.3 未来展望
Prompt Engineering仍在快速发展中。以下是一些值得关注的方向:
1. 更强大的自动优化
未来的自动优化技术可能会结合强化学习、遗传算法等方法,找到更优的提示策略。
2. 多模态提示
随着多模态模型的发展,提示工程将不仅限于文本,还包括图像、音频等多种模态。
3. 提示即接口
提示可能成为人与AI系统交互的主要接口,类似于今天的API。提示工程将成为软件工程的核心技能之一。
4. 模型自适应
未来的模型可能会自动适应提示,无需人工设计。模型能够理解用户意图,自动选择最优的推理策略。这种”元学习”能力将大大降低提示工程的应用门槛。
5. 安全与对齐
随着提示工程的发展,提示安全和对齐问题将越来越重要。如何设计提示来防止模型产生有害输出,如何确保提示不会泄露敏感信息,这些都将成为重要的研究方向。提示注入攻击(Prompt Injection)等安全问题也需要引起重视。
6. 跨模型迁移
不同模型对提示的敏感度不同。未来的研究可能会关注如何让提示在不同模型之间更好地迁移,减少为每个模型重新调优提示的工作量。
结语:提示工程的未来
从2020年的Zero-Shot到2025年的DSPy,Prompt Engineering经历了从”玄学”到”科学”的蜕变。这场变革的核心是效率与规模化——如何让大模型的能力更有效地被利用,如何将这些能力规模化地应用到各种场景中。
今天,Prompt Engineering已经成为AI应用开发的核心技能。无论是简单的文本生成,还是复杂的推理任务,都离不开精心设计的提示。而随着自动优化技术的发展,提示工程的门槛正在不断降低。越来越多的开发者可以借助APE、OPRO、DSPy等工具,快速构建高质量的提示。
未来,提示工程可能会朝着两个方向发展:
一是更加自动化。模型能够自动理解任务需求,自动选择最优的提示策略,人工干预越来越少。未来的模型可能会内置提示优化能力,用户只需要描述任务,模型就能自动找到最佳提示方式。
二是更加工程化。提示工程将成为软件工程的一部分,有成熟的框架、工具、最佳实践,可以像开发软件一样开发提示。DSPy的出现只是开始,未来会有更多类似的框架涌现。提示工程将有自己的设计模式、反模式、最佳实践指南,就像今天的软件工程一样成熟。
三是更加多模态。随着多模态模型的发展,提示工程将不仅限于文本,还包括图像、音频、视频等多种模态。多模态提示工程将开辟全新的应用场景,如视觉问答、视频理解、跨模态检索等。
四是更加个性化。未来的提示可能会根据用户的历史行为、偏好、上下文进行个性化调整。同一个任务,不同用户可能会看到不同的提示,以获得最佳体验。
附录:关键概念速查
基础概念
Zero-Shot:零样本提示,直接提问,不提供示例。
Few-Shot:少样本提示,提供几个输入-输出示例。
In-Context Learning:上下文学习,模型从提示中的示例学习任务模式。
推理技术
Chain-of-Thought (CoT):思维链,让模型生成中间推理步骤。
Zero-Shot CoT:零样本思维链,通过”Let’s think step by step”触发推理。
Tree-of-Thoughts (ToT):思维树,维护思维树,探索多条推理路径。
Self-Consistency:自一致性,多次采样,选择最一致的答案。
行动与工具
ReAct:推理与行动结合,模型可以调用外部工具。
Toolformer:学习使用工具的模型框架。
自动优化
APE:自动提示工程师,自动生成和优化提示。
OPRO:基于提示的优化,迭代优化提示词。
DSPy:编程式提示框架,模块化、可优化。
评估基准
GSM8K:小学数学应用题基准,包含8500个高质量数学问题,测试模型的数学推理能力。
SVAMP:数学单词问题基准,测试模型理解数学问题的能力。
Big-Bench Hard:大模型能力评估基准,包含多个挑战性任务,测试模型的综合能力。
HumanEval:代码生成基准,测试模型编写Python函数的能力。
MMLU:大规模多任务语言理解基准,测试模型在57个学科的知识水平。
StrategyQA:策略问答基准,测试模型的常识推理能力。
相关技术框架
LangChain:流行的LLM应用开发框架,提供链式调用、工具集成等功能。
LlamaIndex:数据索引和检索框架,用于构建RAG应用。
Guidance:结构化生成框架,确保模型输出符合特定格式。
Outlines:JSON模式强制生成框架,确保输出符合JSON Schema。
本文由 @卡萨丁AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









建议附录放在最前面,这样方便读者能大概的知晓各种范式的意思。