
 起点课堂会员权益
起点课堂会员权益3万字解读:多模态AI(Multimodal AI)起源、演进与思考研究报告
多模态AI的发展历程是一部从单一感知到全面认知的技术史诗。从AlexNet在2012年引爆深度学习革命,到GPT-4o实现原生多模态理解,再到世界模型对AGI的终极探索,每一次技术跃迁都在重新定义人机交互的边界。本文将深度解析CNN、GAN、ViT、Diffusion等关键技术的演进脉络,揭示多模态AI如何逐步突破感知局限,走向对世界的理解与建模。
多模态AI作为一种融合视觉、语言、音频等多种感知模态的智能技术范式,正在重塑人机交互的边界。从2012年AlexNet在ImageNet竞赛中的惊艳表现,到2024年GPT-4o实现端到端原生多模态理解,再到2026年ViT-5对视觉Transformer的现代化升级,这条演进之路跨越了整整十余年,见证了深度学习从单一感知走向全面认知的历史性跨越。
本文将深入剖析多模态AI从卷积神经网络到世界模型的完整演进脉络,揭示其背后的技术逻辑与产业变革。我们将沿着时间轴,依次探索CNN开启的视觉感知时代、GAN点燃的生成式AI萌芽、ViT打破的模态壁垒、CLIP实现的图文对齐革命、Diffusion引领的文生图爆发、多模态大模型的理解突破、Sora带来的视频生成革命、原生多模态的端到端融合,以及世界模型所代表的AGI终极形态。
这不仅是技术演进的编年史,更是对人类认知边界的不断拓展。多模态AI的发展历程告诉我们:真正的智能,源于对世界的多维度感知与理解。每一次技术突破,都让我们离通用人工智能(AGI)更近一步。从”看懂”到”理解”,从”生成”到”建模”,多模态AI正在开启人工智能的新纪元。
本文适合对人工智能感兴趣的各类读者:技术从业者可以从中了解多模态AI的技术演进脉络和核心原理;产品经理可以从中洞察产业发展趋势和应用场景;普通读者可以从中感受人工智能的魅力和未来可能。无论你身处何种背景,相信都能从这篇文章中获得启发。

AI大模型发展时间线
图1:AI大模型发展历程时间线(图片来源:LifeArchitect.ai)
一、感知觉醒——卷积神经网络开启视觉时代(2012-2017)
1.1 深度学习前夜:图像识别的困境
在深度学习革命到来之前,计算机视觉领域长期被手工设计的特征描述符所主导。1999年,David Lowe提出的SIFT(Scale-Invariant Feature Transform,尺度不变特征变换)算法,通过检测图像中的关键点并提取其局部特征描述子,实现了对旋转、尺度、亮度变化的鲁棒性。紧随其后,Navneet Dalal和Bill Triggs在2005年提出的HOG(Histogram of Oriented Gradients,方向梯度直方图)特征,通过统计图像局部区域的梯度方向分布,在行人检测任务上取得了突破性进展。
这些方法虽然在特定任务上表现优异,但其本质都是人类专家基于对视觉世界的理解,手工设计的特征提取规则。它们存在三个根本性局限:首先,特征的表达能力受限于设计者的先验知识,难以捕捉更复杂、更抽象的语义信息;其次,不同任务需要设计不同的特征,缺乏通用性;最重要的是,这些手工特征无法从数据中自动学习优化,难以适应海量数据时代的需求。
2009年,李飞飞教授领导的团队在CVPR上发布了ImageNet数据集,这是一个包含超过1400万张图像、涵盖2万多个类别的大规模图像数据库。ImageNet的诞生为计算机视觉领域提供了一个统一的评估基准,每年的ImageNet大规模视觉识别挑战赛(ILSVRC)成为衡量算法性能的”奥林匹克”。然而,在2010年和2011年的比赛中,获胜算法的top-5错误率仍高达28%和26%,图像识别的准确率提升陷入了瓶颈。
1.2 AlexNet:深度学习的惊雷(2012)
2012年9月30日,一个注定要载入人工智能史册的日子。在当年的ImageNet竞赛中,多伦多大学Geoffrey Hinton教授的研究小组提交了一个名为AlexNet的卷积神经网络模型,以惊人的优势夺得冠军——其top-5错误率仅为15.3%,比第二名(26.2%)低了将近11个百分点。这是深度学习在计算机视觉领域的首次重大突破,标志着AI发展进入了一个全新时代。
AlexNet的成功并非偶然,而是三个关键技术突破的完美结合:
- ReLU激活函数:传统的神经网络使用sigmoid或tanh作为激活函数,这些函数在深层网络中存在严重的梯度消失问题。AlexNet首次在大规模图像识别任务中采用了ReLU(Rectified Linear Unit,修正线性单元)激活函数,即f(x) = max(0, x)。ReLU的计算简单高效,且在正区间梯度恒为1,有效缓解了梯度消失问题,使得训练更深的网络成为可能。
- Dropout正则化:为了防止过拟合,AlexNet引入了Dropout技术。在训练过程中,以一定概率(如0.5)随机”丢弃”一部分神经元,强制网络学习更鲁棒的特征表示。这种”集成学习”的思想显著提升了模型的泛化能力。
- GPU并行训练:AlexNet使用了两个GTX 580 GPU进行并行训练,这是深度学习与高性能计算结合的早期典范。GPU的大规模并行计算能力使得训练包含6000万参数的深度网络成为现实。
AlexNet的架构包含8层网络(5个卷积层+3个全连接层),使用了局部响应归一化(LRN)和重叠池化(Overlapping Pooling)等技术。它的成功证明了:通过端到端的深度学习,神经网络可以自动从原始像素中学习层次化的特征表示,无需人工设计特征提取器。
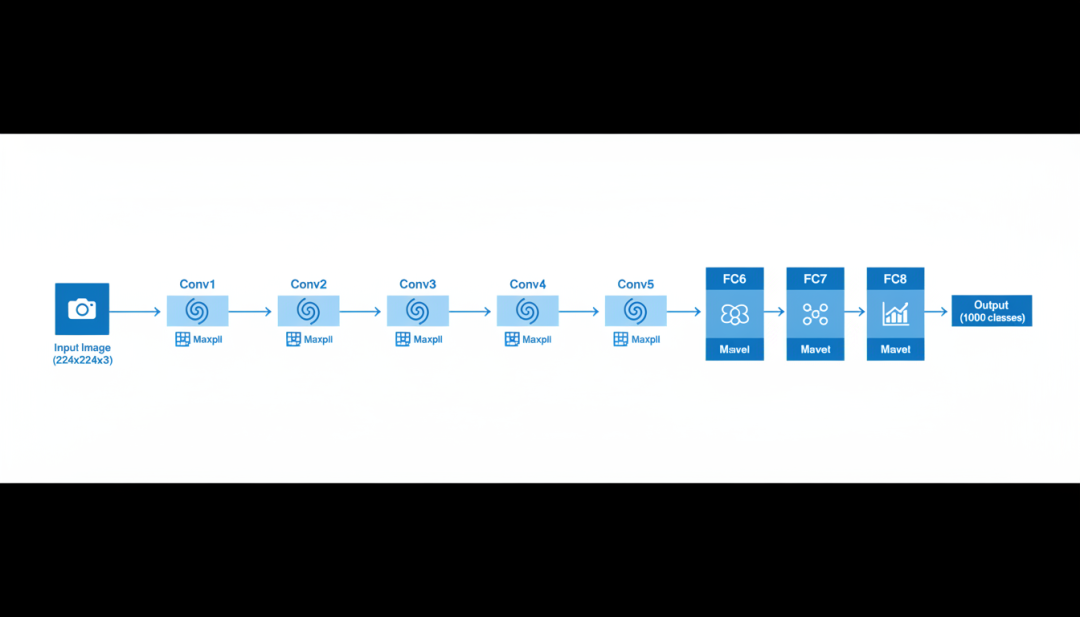
AlexNet架构图
图2:AlexNet CNN架构示意图,展示了从输入到输出的完整数据流
1.3 CNN架构的快速迭代
AlexNet的胜利点燃了整个学术界和工业界对深度学习的热情,卷积神经网络架构进入了快速迭代期。
VGGNet(2014):牛津大学视觉几何组(Visual Geometry Group)提出的VGGNet采用了极其简洁的设计理念——使用大量3×3的小卷积核堆叠来替代大卷积核。VGG-16和VGG-19分别包含16层和19层,通过增加网络深度来提升表达能力。VGGNet证明了网络深度的重要性,其简洁的架构设计也成为后续许多网络的基准。
GoogLeNet/Inception(2014):Google团队提出的GoogLeNet(又名Inception v1)采用了完全不同的设计思路。其核心创新是Inception模块,通过在同一层使用不同大小的卷积核(1×1、3×3、5×5)和池化操作,实现多尺度特征的并行提取。这种”网络中的网络”结构在保持计算效率的同时,大幅提升了特征的丰富度。GoogLeNet仅有22层,但参数数量却只有AlexNet的1/12,在2014年ImageNet竞赛中以6.67%的top-5错误率夺冠。
ResNet(2015):微软亚洲研究院的Kaiming He等人提出的残差网络(Residual Network)是CNN发展史上的又一里程碑。他们发现了一个反直觉的现象:随着网络深度增加,训练准确率反而下降,这并非过拟合导致,而是优化困难造成的”退化问题”。ResNet通过引入”跳跃连接”(Skip Connection),让网络学习残差映射F(x) = H(x) – x,而非直接学习目标映射H(x)。这种设计使得训练超深层网络成为可能,ResNet-152在ImageNet上取得了3.57%的top-5错误率,首次超越了人类的识别水平(约5.1%)。
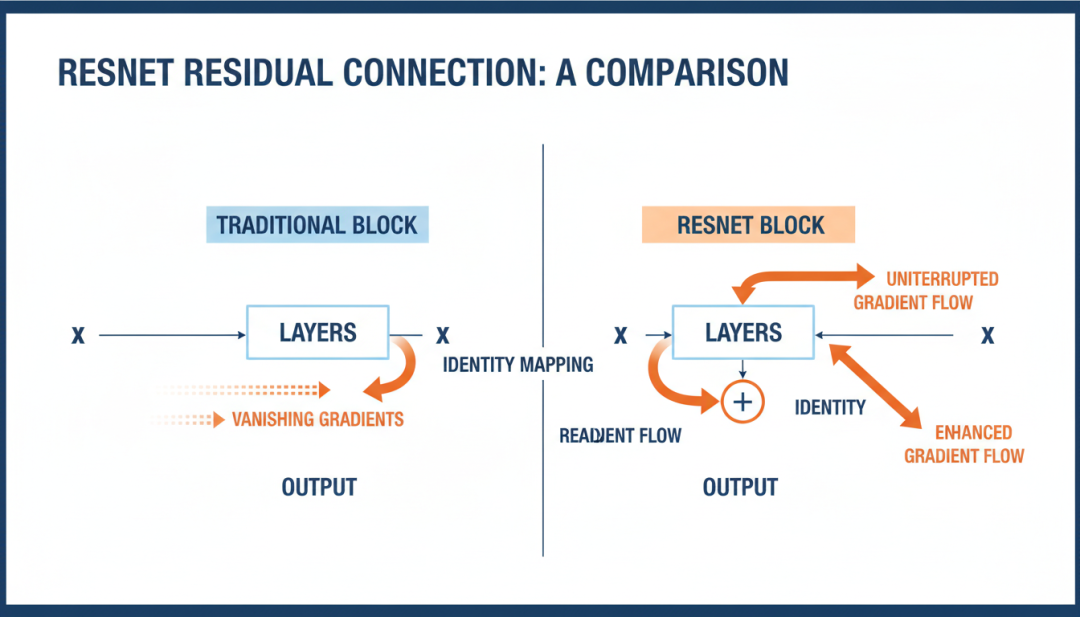
ResNet残差连接
图3:传统网络块与ResNet残差块的对比,展示了跳跃连接如何解决梯度消失问题
DenseNet(2016):康奈尔大学的Gao Huang等人提出了密集连接网络(Densely Connected Network),每一层都与前面所有层直接相连,形成特征的重用与传递。DenseNet在减少参数数量的同时,缓解了梯度消失问题,进一步提升了特征传播效率。
1.4 CNN的局限与反思
尽管CNN在图像分类、目标检测、语义分割等任务上取得了巨大成功,但其架构本身存在一些根本性局限:
- 局部感受野的”管中窥豹”:卷积核的局部性假设虽然赋予了CNN平移不变性,但也限制了其对全局上下文信息的感知能力。一个3×3的卷积核只能看到局部区域,深层网络虽然通过堆叠扩大了感受野,但这种扩大是渐进的、间接的,难以捕捉远距离的语义依赖关系。
- 缺乏全局语义理解:CNN擅长提取局部纹理和形状特征,但对图像的整体语义结构理解有限。例如,CNN可能准确识别出”猫”的特征,但难以理解”猫在沙发上睡觉”这样的整体场景语义。
- 归纳偏置的束缚:CNN的平移不变性和局部连接性是强大的归纳偏置,但在某些任务中也可能成为限制。例如,当需要精确的空间位置信息时,CNN的下采样操作会导致分辨率损失。
这些局限性为后续Transformer架构的登场埋下了伏笔。2017年,Google提出的Transformer架构在自然语言处理领域大放异彩,人们开始思考:这种基于自注意力机制的架构能否应用于计算机视觉?这个问题的答案,将在2020年揭晓。
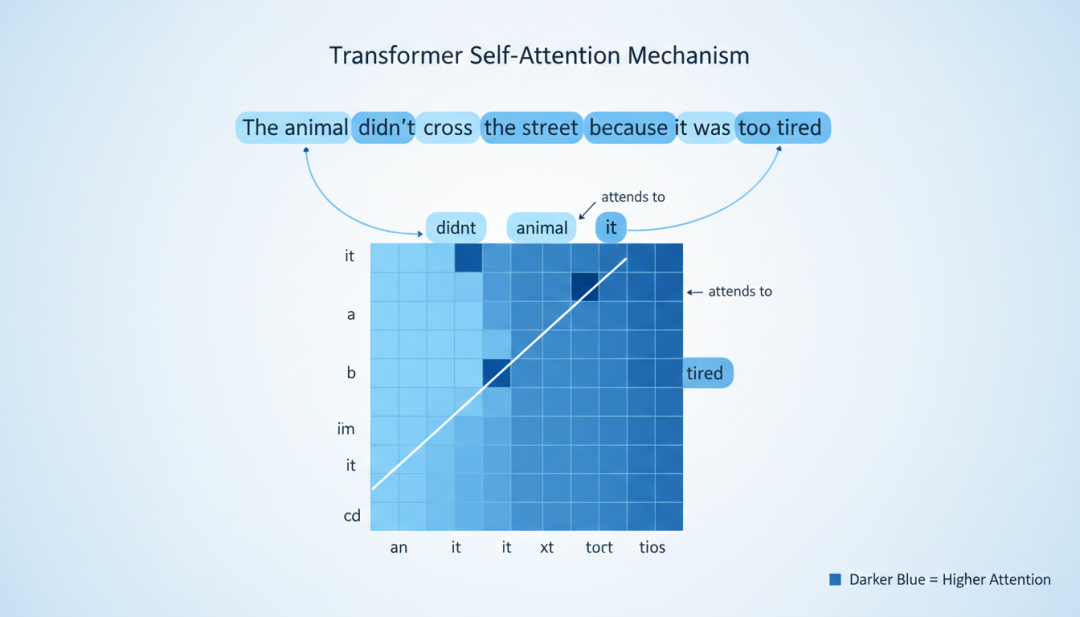
Transformer自注意力机制
图5:Transformer自注意力机制可视化,展示每个词如何关注句子中的其他词
二、生成萌芽——GAN开启AI创作时代(2014-2018)
2.1 生成对抗网络的诞生(2014)
2014年6月,蒙特利尔大学的Ian Goodfellow等人在NIPS会议上发表了一篇题为《Generative Adversarial Nets》的论文,正式提出了生成对抗网络(Generative Adversarial Networks,GAN)的概念。这篇论文的诞生颇具传奇色彩——据说Goodfellow是在一个深夜的学术讨论中突然灵光一现,意识到可以通过两个神经网络的对抗博弈来实现生成式建模,随后立即回家编写了代码,并在当晚就取得了初步成功。
GAN的核心思想源于博弈论中的”二人零和博弈”。它包含两个相互对抗的神经网络:
- 生成器(Generator):接收一个随机噪声向量z(通常来自简单分布如高斯分布或均匀分布),通过神经网络将其映射为与真实数据分布相似的样本G(z)。生成器的目标是”欺骗”判别器,使其无法区分生成样本与真实样本。
- 判别器(Discriminator):接收一个样本(可能是真实数据x,也可能是生成数据G(z)),输出一个标量D(x)表示该样本来自真实数据分布的概率。判别器的目标是尽可能准确地区分真实样本和生成样本。
两个网络通过对抗训练不断优化:生成器努力生成更逼真的样本来欺骗判别器,判别器则努力提升鉴别能力来识破生成器的”谎言”。在理想情况下,当训练达到纳什均衡时,生成器能够完美拟合真实数据分布,判别器对任何样本的输出概率都为0.5,即完全无法区分真假。
GAN的数学目标函数可以表示为:
min_G max_D V(D, G) = mathbb{E}_{x sim p_{data}(x)}[log D(x)] + mathbb{E}_{z sim p_z(z)}[log(1
– D(G(z)))]
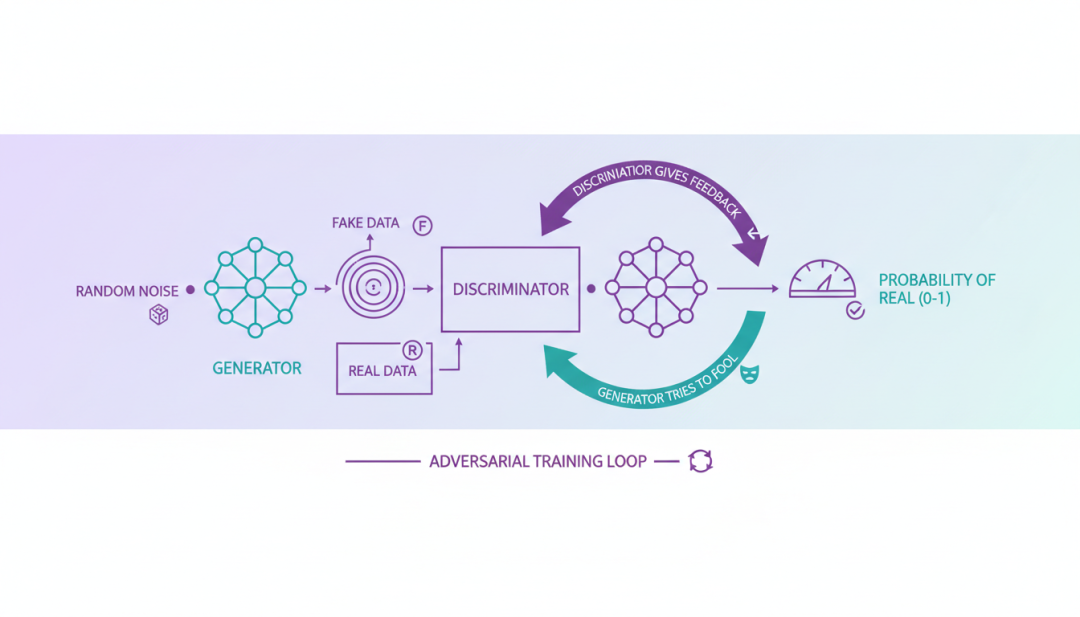
GAN生成对抗网络架构
图4:GAN生成对抗网络架构,展示生成器与判别器的对抗训练过程
这个minimax博弈框架具有深刻的理论意义:当生成器和判别器都有无限容量时,在最优判别器下,生成器的目标等价于最小化真实数据分布与生成分布之间的Jensen-Shannon散度。
2.2 GAN的核心技术演进
GAN提出后,迅速成为生成式AI领域最热门的研究方向,各种改进版本层出不穷。
DCGAN(2015):Radford等人提出的深度卷积GAN(Deep Convolutional GAN)是GAN发展史上的第一个重要里程碑。DCGAN将CNN引入GAN架构,提出了一系列稳定训练的经验性设计准则:使用步长卷积替代池化操作、在生成器和判别器中都使用Batch Normalization、移除全连接层、在生成器中使用ReLU激活(输出层使用Tanh)、在判别器中使用LeakyReLU激活。DCGAN生成的图像质量显著提升,且学习到的特征具有可解释性,开启了GAN的可视化研究。
CGAN(2014):条件GAN(Conditional GAN)通过向生成器和判别器额外输入条件信息y(如类别标签),实现了可控生成。CGAN的目标函数变为:
min_G max_DV(D, G)= mathbb{E}_{x sim p_{data}(x)}[logD(x|y)] + mathbb{E}_{z simp_z(z)}[log(1
– D(G(z|y)|y))]
这一设计使得GAN可以生成指定类别的样本,大大扩展了应用场景。
CycleGAN(2017):朱俊彦等人提出的CycleGAN实现了无监督的图像到图像翻译。传统的图像翻译方法需要配对的训练数据(如同一场景的晴天和雨天版本),而CycleGAN通过引入”循环一致性损失”(Cycle Consistency Loss),可以在没有配对数据的情况下学习两个域之间的映射关系。例如,可以将马自动转换为斑马,或将夏季风景转换为冬季风景,而无需成对的训练样本。
StyleGAN(2018-2019):NVIDIA提出的StyleGAN系列将GAN的生成能力推向了新的高度。StyleGAN的核心创新是借鉴了风格迁移领域的”自适应实例归一化”(AdaIN),将潜在向量z通过一个全连接网络映射为中间潜在空间W,然后在生成器的每一层通过AdaIN注入风格信息。这种设计实现了对生成图像的高层次语义控制,可以独立调整年龄、姿态、表情、发色等属性。StyleGAN2进一步解决了”液滴伪影”问题,StyleGAN3则实现了对平移和旋转的等变性。
2.3 GAN的应用与瓶颈
GAN在多个领域展现了强大的应用潜力:
- 艺术创作:GAN可以生成风格独特的艺术作品,如Christie’s拍卖行以43.25万美元售出的AI画作《Edmond de Belamy》。
- 数据增强:在医疗、工业检测等数据稀缺的领域,GAN可以生成合成数据来扩充训练集。
- 图像修复与超分辨率:GAN可以将低分辨率图像恢复为高分辨率,或修复图像中的缺失区域。
- 人脸生成与编辑:StyleGAN可以生成以假乱真的人脸图像,并实现精细的属性编辑。
然而,GAN也存在一些根本性瓶颈:
- 训练不稳定性:生成器和判别器的训练需要微妙的平衡,稍有不慎就会导致训练崩溃。常见的失败模式包括:生成器产生单一模式的”模式坍塌”(Mode Collapse)、判别器过强导致生成器梯度消失等。
- 评估困难:与分类、回归等任务有明确的评估指标不同,生成模型的质量评估一直是一个开放问题。Inception Score(IS)和Fréchet Inception Distance(FID)等常用指标都存在各自的局限性。
- 样本多样性不足:尽管GAN可以生成高质量样本,但在覆盖真实数据分布的所有模式方面仍有不足,容易出现”记忆”训练数据的现象。
2.4 GAN的历史定位
尽管GAN存在诸多局限,但它在AI发展史上的地位不可磨灭:
首先,GAN证明了AI不仅可以”识别”和”理解”,还可以”创造”。这一认知突破为后续生成式AI的发展奠定了心理基础。
其次,GAN开启了AI创作的大众认知。2018年,”This Person Does Not Exist”网站使用StyleGAN生成虚拟人脸,让普通用户第一次直观感受到AI的生成能力。
最后,GAN为后续扩散模型的爆发培养了用户群体和开发者社区。许多在GAN时代积累的技术(如条件生成、潜在空间编辑)在扩散模型时代得到了继承和发展。
2015年,Jascha Sohl-Dickstein等人提出了扩散模型(Diffusion Model)的雏形,但当时并未引起广泛关注。直到2020-2022年,随着DDPM、LDM等关键工作的发表,扩散模型才逐渐取代GAN成为生成式AI的主流范式。GAN与扩散模型的交替,恰如RNN与Transformer在NLP领域的更迭,是技术演进螺旋上升的生动写照。
三、大一统前夜——Vision Transformer打破模态壁垒(2020)
3.1 Transformer的跨界野心
2017年6月,Google机器翻译团队发表了那篇改变NLP历史的论文《Attention Is All You Need》,正式提出了Transformer架构。Transformer完全基于自注意力机制(Self-Attention),摒弃了RNN和CNN的顺序计算模式,实现了并行化训练和长距离依赖建模。随后,BERT(2018)和GPT系列(2018-至今)的横空出世,证明了Transformer在自然语言理解与生成的强大能力。
然而,Transformer在计算机视觉领域的应用却长期滞后。CV研究者普遍认为,图像的二维空间结构需要CNN的局部归纳偏置来有效建模,而Transformer的全局自注意力计算复杂度过高,难以处理高分辨率图像。这种认知在2020年被彻底打破。
3.2 ViT的核心创新(Google, 2020)
2020年10月,Google Research的Alexey Dosovitskiy等人在ICLR 2021发表了题为《An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale》的论文,正式提出了Vision Transformer(ViT)。这篇论文的标题本身就是一个宣言:图像可以被看作是一系列”视觉词”(Visual Words)的序列,Transformer可以像处理文本一样处理图像。
ViT的核心创新可以概括为三点:
- 图像即序列:ViT将输入图像分割为固定大小的图像块(Patches)。对于224×224的图像,使用16×16的Patch大小,可以得到(224/16)² = 196个Patch。每个Patch被展平为一个向量(16×16×3=768维),然后通过一个可学习的线性投影矩阵映射为固定维度的Patch嵌入(Patch Embedding)。这样,一幅图像就被转换为了一个长度为196的Token序列,与NLP中的词序列完全类似。
- 类别Token与位置嵌入:为了执行分类任务,ViT在Patch序列前添加了一个可学习的类别Token([CLS] Token),其对应的最终输出状态被用作图像的整体表示。同时,为了保留位置信息,ViT为每个Patch添加了可学习的一维位置嵌入(Positional Embedding)。
- 纯Transformer编码器:ViT的架构完全采用标准的Transformer编码器,由交替的多头自注意力(Multi-Head Self-Attention, MSA)和多层感知机(MLP)块组成,在每个块之前应用Layer Normalization(Pre-LN变体)。
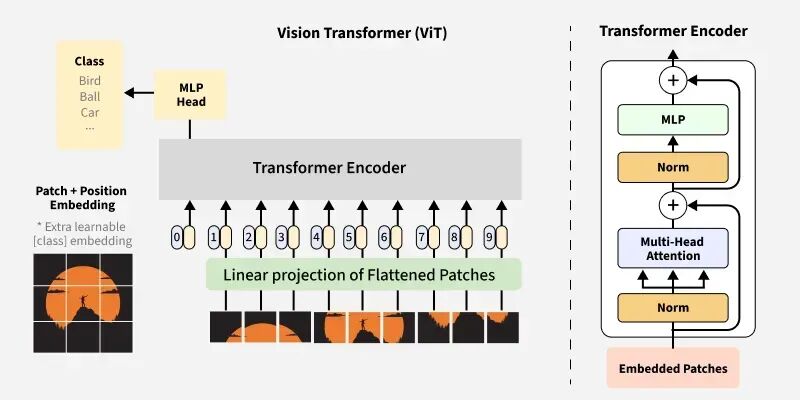
Vision Transformer架构
图6:Vision Transformer架构图,展示图像如何被分割为Patch并输入Transformer编码器
ViT的架构公式化表示为:
z_0= [x_{class}; x_p^1E; x_p^2E; cdots; x_p^NE] + E_{pos}z’_l = MSA(LN(z_{l-1})) + z_{l-1}z_l = MLP(LN(z’_l)) + z’_ly = LN(z_L^0)
其中,x_p^i是第i个展平的图像Patch,E是Patch嵌入投影矩阵,E_{pos}是位置嵌入,L是Transformer层数。
3.3 ViT的实验发现
ViT的实验结果揭示了几个重要发现:
- 大数据集上的惊艳表现:当在中等规模数据集(如ImageNet,约130万张图像)上从头训练时,ViT-Large(86M参数)的准确率不如ResNet-152,作者将其归因于Transformer缺乏CNN的归纳偏置(局部性、平移等变性),导致数据效率较低。然而,当在大规模数据集JFT-300M(3亿张图像)上预训练后,ViT-Huge(632M参数)在ImageNet上达到了88.55%的top-1准确率,超越了当时所有CNN模型。
- “Scale is All You Need”:ViT的实验结果强有力地证明,当数据量足够大时,Transformer的纯注意力机制可以自动学习CNN的归纳偏置,无需显式设计。这一发现与GPT系列在NLP领域的”规模法则”(Scaling Law)遥相呼应。
- 预训练的重要性:ViT的成功很大程度上依赖于大规模预训练。在JFT-300M上预训练后,即使在下游任务的数据集上微调,也能取得优异性能。这确立了”预训练+微调”作为视觉任务的新范式。
3.4 ViT的后续发展
ViT的提出引发了视觉Transformer研究的热潮,各种改进版本层出不穷。
DeiT(Data-efficient Image Transformer,2021):Facebook AI提出的DeiT通过知识蒸馏(Knowledge Distillation)技术,使得ViT可以在ImageNet上从头训练而无需大规模预训练数据集。DeiT引入了一个蒸馏Token(Distillation Token),让模型学习教师网络(通常是CNN)的软标签。DeiT-Tiny仅用5.7M参数就在ImageNet上达到了72.2%的准确率,证明了数据效率优化的重要性。
Swin Transformer(2021):微软亚洲研究院提出的Swin Transformer引入了层次化(Hierarchical)和窗口化(Window-based)的自注意力机制。Swin Transformer将图像划分为不重叠的窗口,在每个窗口内计算自注意力,然后通过移位窗口(Shifted Window)实现跨窗口信息交互。这种设计将自注意力的计算复杂度从O(N²)降低到O(N),同时保留了多尺度特征提取能力,使其适用于目标检测、语义分割等密集预测任务。
ViT-5(2026):最新的ViT-5架构代表了现代ViT的集大成。它采用了以下关键设计:
- LayerScale:在每个块的输出引入可学习的缩放因子,提升训练稳定性
- RMSNorm:用RMSNorm替代LayerNorm,减少计算开销
- 2D RoPE:采用二维旋转位置编码,增强空间建模能力
- Register Tokens:引入寄存器Token,抑制注意力伪影
- QK-Norm:对Query和Key进行归一化,提升训练稳定性
- 移除QKV偏置:去除QKV投影层的偏置项,改善训练效率
ViT-5在ImageNet-1K上,Base模型达到84.2%的top-1准确率,超过DeiT-III-Base的83.8%;Large模型在384×384分辨率下达到86.0%,显著超越之前的ViT架构。
3.5 ViT的历史意义
ViT的提出具有划时代的意义:
首先,ViT证明了Transformer可以统一处理文本和图像,打破了CV和NLP之间的技术壁垒。这为后续多模态模型的融合奠定了架构基础。
其次,ViT确立了”规模法则”在视觉领域的适用性,推动了大规模视觉预训练的发展。CLIP、DALL-E、Sora等后续模型都受益于这一范式转变。
最后,ViT简化了视觉模型的设计。相比CNN复杂的架构设计(不同大小的卷积核、池化策略、跳跃连接等),ViT的架构更加简洁统一,主要调整的超参数只有模型深度、宽度和Patch大小。
ViT的成功让人们看到了一个激动人心的可能性:是否存在一种统一的架构,可以同时处理文本、图像、音频、视频等多种模态?这个问题的答案,将在2021年揭晓。
四、罗塞塔石碑——CLIP实现图文对齐革命(2021)
4.1 多模态的”巴别塔困境”
在CLIP出现之前,计算机视觉(CV)和自然语言处理(NLP)是两个相对独立的领域。CV研究者专注于如何让机器”看懂”图像,NLP研究者致力于让机器”理解”语言,但两者之间缺乏有效的”翻译”机制。
早期的多模态方法主要采用以下策略:
- 独立编码+浅层融合:使用CNN提取图像特征,使用RNN/Transformer提取文本特征,然后在特征层面进行简单的拼接或相加。这种方法的问题在于,图像和文本的编码是独立的,缺乏深层次的语义交互。
- 预训练CNN+微调分类器:在ImageNet上预训练CNN,然后将其作为特征提取器,在特定任务上训练分类器。这种方法受限于ImageNet的1000个类别,难以处理开放词汇(Open Vocabulary)的语义概念。
- 图像描述生成:使用编码器-解码器架构生成图像描述。虽然这类方法可以生成文本,但其目标是生成描述性语句,而非建立图文之间的语义对齐。
这些方法的共同局限是:它们将视觉和语言视为两个独立的模态,缺乏统一的语义表示空间。当用户想搜索”一只在草地上奔跑的金毛犬”时,传统方法难以准确理解这一复杂语义查询。
4.2 CLIP的核心架构(OpenAI, 2021)
2021年2月,OpenAI发布了CLIP(Contrastive Language-Image Pre-training),这是一个在4亿对互联网图文数据上训练的视觉-语言模型。CLIP的核心创新在于:通过对比学习,将图像和文本映射到一个共享的语义嵌入空间中。
CLIP的架构包含两个主要组件:
- 图像编码器:可以采用CNN(如ResNet)或ViT架构。在CLIP的原始论文中,作者尝试了ResNet-50、ResNet-101、EfficientNet以及ViT-B/32、ViT-B/16、ViT-L/14等多种变体。图像编码器将输入图像x映射为图像特征向量I = f(x)。
- 文本编码器:采用Transformer架构,基于GPT-2的架构进行修改(宽度512,8个注意力头,12层)。文本编码器将输入文本t映射为文本特征向量T = g(t)。
CLIP的训练目标是最大化匹配图文对的相似度,同时最小化不匹配图文对的相似度。具体来说,对于一个包含N对图文数据的批次,CLIP计算所有N×N个可能的图文相似度,形成一个相似度矩阵。对角线上的N个元素对应匹配的图文对,非对角线上的N²-N个元素对应不匹配的图文对。
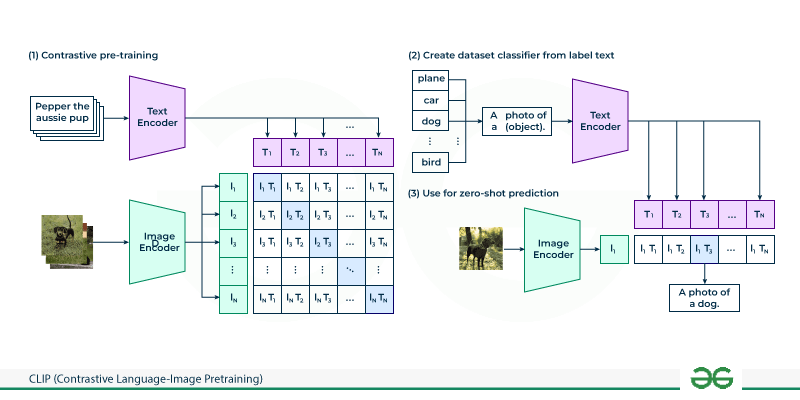
CLIP架构与对比学习
图7:CLIP架构图,展示图像编码器、文本编码器和对比学习的核心思想
CLIP使用对称的交叉熵损失(Symmetric Cross-Entropy Loss)进行训练:
L= frac{1}{2} left[ -sum_{i=1}^{N} log frac{exp(I_i cdot T_i / tau)}{sum_{j=1}^{N} exp(I_i cdot T_j / tau)}
– sum_{i=1}^{N} log frac{exp(I_i cdot T_i / tau)}{sum_{j=1}^{N} exp(I_j cdot T_i / tau)} right]
其中,tau是可学习的温度参数,用于控制分布的锐度。
4.3 CLIP的惊人能力
CLIP在多个基准测试上展现了前所未有的能力:
- Zero-shot图像分类:CLIP可以在没有任何下游训练数据的情况下,直接对新类别进行分类。给定一个图像和一组候选类别名称,CLIP将类别名称转换为文本描述(如”a photo of a {label}”),计算图像与每个描述的相似度,选择相似度最高的类别。在ImageNet上,CLIP(ViT-L/14)的zero-shot准确率达到76.2%,与在ImageNet上全监督训练的ResNet-50(76.1%)相当。
- 跨模态检索:CLIP可以实现以文搜图和以图搜文。给定文本查询,CLIP可以从大规模图像库中检索最相关的图像;反之亦然。这种能力为搜索引擎、推荐系统等应用开辟了新可能。
- 语义理解:CLIP能够理解复杂的语义概念,包括抽象概念(如”爱情”、”自由”)、属性组合(如”红色的圆形物体”)、空间关系(如”猫在沙发上”)等。这种语义理解能力远超传统的基于标签的分类方法。
- 鲁棒性:CLIP对图像分布的偏移表现出很强的鲁棒性。在ImageNet-V2、ImageNet-R、ImageNet-A等分布偏移测试集上,CLIP的性能下降幅度远小于传统监督学习方法。
4.4 CLIP的技术细节
数据工程:CLIP的成功很大程度上归功于大规模数据收集。OpenAI从互联网上收集了4亿对(图像,文本)数据,形成了WebImageText(WIT)数据集。这些数据覆盖了广泛的视觉概念,为CLIP的泛化能力奠定了基础。
对比学习的效率优势:相比生成式方法(如图像描述生成),对比学习只需要判断图文是否匹配,而不需要生成完整的文本序列,训练效率更高。CLIP的训练使用了256个V100 GPU,训练时间约为12天。
温度参数的作用:CLIP中的温度参数tau是可学习的,而非固定值。这使得模型可以自动调整相似度分布的锐度,在训练过程中动态优化。
对比学习的数学原理:CLIP的对比学习目标函数可以看作是在最大化互信息的下界。具体来说,对于匹配的图文对(I, T),CLIP最大化它们的互信息I(I; T),而对比损失实际上是InfoNCE(Noise Contrastive Estimation)损失的一种形式,它通过将正样本与大量负样本进行对比,来学习有意义的表征。
CLIP的局限性:尽管CLIP展现了强大的能力,但它也存在一些局限性:
- 细粒度识别不足:CLIP在区分细粒度类别(如不同品种的狗)时表现不如专门训练的分类器
- 计数和方位理解:CLIP在理解物体数量和空间方位方面存在困难
- 偏见问题:CLIP可能从训练数据中学习到社会偏见,如性别刻板印象
4.5 CLIP的产业影响
CLIP的发布引发了多模态AI的产业革命:
- Stable Diffusion的文本编码器:Stable Diffusion使用CLIP的文本编码器将用户的文本提示转换为语义嵌入,引导扩散模型的生成过程。可以说,没有CLIP,就没有Stable Diffusion的成功。
- DALL-E 2的语义桥梁:DALL-E 2使用CLIP的图像编码器将图像映射到语义空间,实现了文本到图像的语义对齐。
- 多模态大模型的基石:CLIP开创了”对比预训练+零样本迁移”的范式,被后续的多模态模型广泛采用。
- SigLIP(2024-2025):Google DeepMind提出的SigLIP使用Sigmoid损失替代Softmax损失,将训练效率提升了4倍。SigLIP-2进一步引入自监督预训练和视觉定位能力,成为CLIP的有力继任者。
CLIP的意义可以类比于罗塞塔石碑——它建立了图像和文本之间的”翻译”机制,让机器可以同时”看懂”图像和”理解”语言,开启了多模态AI的新纪元。
五、文生图爆发——扩散模型引领生成革命(2022)
5.1 扩散模型的理论基础(2015-2020)
扩散模型的理论基础可以追溯到2015年。Jascha Sohl-Dickstein等人发表了《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》,首次提出了使用扩散过程进行生成建模的思想。这篇论文的灵感来源于非平衡态热力学:通过模拟分子从高浓度向低浓度的扩散过程,可以逐步将复杂的数据分布”简化”为简单的噪声分布,然后学习逆向过程来恢复数据。
然而,早期的扩散模型计算效率低下,生成质量也不如GAN,因此并未引起广泛关注。直到2020年,Jonathan Ho等人发表了《Denoising Diffusion Probabilistic Models》(DDPM),对原始扩散模型进行了关键改进,才开启了扩散模型的复兴。
DDPM的核心创新包括:
- 简化的训练目标:DDPM发现,原始的变分下界(VLB)训练目标可以简化为预测噪声的形式。具体来说,模型不再直接预测原始数据x₀,而是预测在每一步添加的噪声epsilon。这一简化使得训练更加稳定,生成质量显著提升。
- 方差调度优化:DDPM设计了一个线性的方差调度方案beta_t,从beta_1 = 10^{-4}线性增加到beta_T = 0.02。这种设计使得扩散过程在保持可逆性的同时,不会破坏数据的信息。
- U-Net架构:DDPM采用U-Net作为去噪网络,这种编码器-解码器结构可以有效融合多尺度特征,适合图像生成任务。

扩散模型去噪过程
图8:扩散模型的前向加噪与反向去噪过程,展示图像如何从噪声中逐步恢复
5.2 Latent Diffusion:从像素到潜空间(CVPR 2022)
尽管DDPM在生成质量上取得了突破,但其在像素空间进行扩散的计算成本仍然很高。生成一张256×256的图像需要多次前向传播,推理速度慢,难以实用化。
2022年,Robin Rombach等人提出了Latent Diffusion Model(LDM),发表在CVPR 2022上。LDM的核心洞察是:图像在像素空间存在大量冗余信息,可以在一个压缩的潜空间(Latent Space)中进行扩散,从而大幅降低计算成本。
LDM的架构包含三个主要组件:
- 感知压缩模型(Perceptual Compression Model):使用变分自编码器(VAE)将图像从像素空间压缩到潜空间。编码器mathcal{E}将图像x压缩为潜变量z = mathcal{E}(x),解码器mathcal{D}将潜变量恢复为图像tilde{x} = mathcal{D}(z)。压缩因子通常为4×(如256×256×3的图像压缩为64×64×4的潜变量)。
- 扩散模型(DM):在潜空间z中进行扩散和去噪。由于潜空间的维度远低于像素空间,扩散模型的计算复杂度大幅降低。
- 条件机制(Conditioning Mechanism):通过交叉注意力机制(Cross-Attention)引入条件信息(如文本、类别、语义图等)。具体来说,条件信息c首先被编码为特征向量tau_theta(c),然后在U-Net的每一层通过交叉注意力与特征图交互。
LDM的交叉注意力机制公式为:
Attention(Q, K, V) = softmaxleft(frac{QK^T}{sqrt{d}}right) cdot V
其中,Q = W_Q^{(i)} cdot varphi_i(z_t),K = W_K^{(i)} cdot tau_theta(c),V = W_V^{(i)} cdot tau_theta(c),varphi_i(z_t)是U-Net第i层的中间特征。
5.3 Stable Diffusion:开源社区的狂欢
2022年8月,Stability AI基于LDM发布了Stable Diffusion,这是一个可以在消费级GPU(8GB显存)上运行的文生图模型。Stable Diffusion的发布引发了开源社区的狂欢,成为AI生成艺术的主流工具。
Stable Diffusion的成功因素包括:
开源开放:Stable Diffusion的模型权重、代码完全开源,任何人都可以免费使用、修改和分发。
低门槛:8GB显存的要求使得大多数消费级GPU都可以运行,降低了使用门槛。
生态丰富:开源社区围绕Stable Diffusion开发了丰富的工具链,包括:
- WebUI:图形化界面,降低使用门槛
- LoRA:低秩适配,实现个性化微调
- ControlNet:可控生成,精确控制生成结果
- ComfyUI:节点式工作流,灵活组合生成流程
社区活跃:Civitai等社区汇聚了大量用户分享的微调模型和生成作品,形成了活跃的内容生态。
5.4 商业产品的三足鼎立
2022年,文生图领域形成了三足鼎立的竞争格局:
- DALL-E 2(OpenAI,2022.04):DALL-E 2采用CLIP的图像编码器将图像映射到语义空间,然后使用GLIDE(Guided Language-to-Image Diffusion for Generation and Editing)进行文本到图像的生成。DALL-E 2引入了”unCLIP”技术,可以生成与参考图像风格一致的新图像。DALL-E 2的生成质量极高,但初期仅对少数用户开放。
- Midjourney(2022.07):Midjourney是一个专注于艺术美学的文生图工具,通过Discord平台提供服务。Midjourney的模型在艺术风格、光影效果、构图美学等方面进行了专门优化,生成的图像具有强烈的艺术感。Midjourney采用订阅制商业模式,用户群体以艺术家、设计师为主。
- Stable Diffusion(Stability AI,2022.08):Stable Diffusion以其开源、可控、可定制的特点,成为开发者和研究者的首选。Stable Diffusion的生态系统最为丰富,ControlNet、LoRA、IP-Adapter等可控生成技术都是基于Stable Diffusion开发的。
5.5 可控生成技术
可控生成是文生图技术从”玩具”走向”工具”的关键。2023年,ControlNet、LoRA、IP-Adapter等技术的提出,使得用户可以精确控制生成结果。
ControlNet(2023.02):ControlNet通过在U-Net的每一层添加可学习的副本,实现对生成过程的精确控制。ControlNet支持多种控制条件:
- Canny边缘:通过边缘图控制图像轮廓
- OpenPose:通过人体姿态控制人物动作
- Depth:通过深度图控制空间关系
- Semantic Segmentation:通过语义分割图控制物体布局
- Scribble:通过涂鸦草图控制图像内容
ControlNet的训练采用”零卷积”初始化,即新添加的卷积层初始权重为零,确保训练开始时不会破坏预训练模型的能力。
LoRA(Low-Rank Adaptation,2021):LoRA最初是为大语言模型微调提出的,后来被广泛应用于Stable Diffusion的个性化训练。LoRA的核心思想是:在冻结预训练模型参数的情况下,通过低秩矩阵来近似权重的更新。
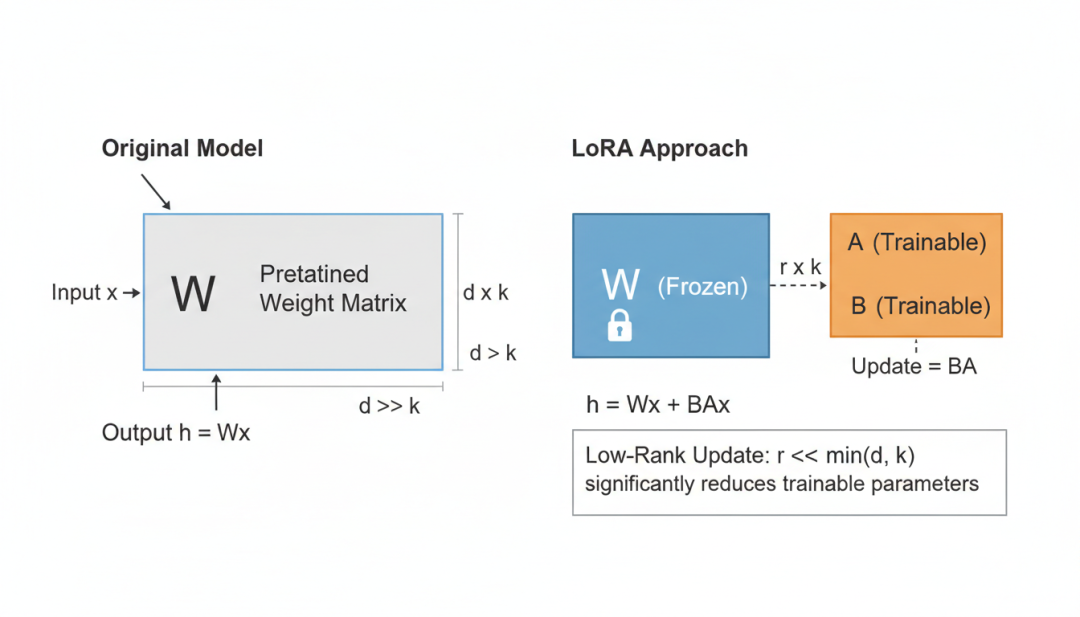
LoRA低秩适配架构
图9:LoRA架构示意图,展示如何通过低秩矩阵分解实现参数高效微调
具体来说,对于原始权重矩阵W_0,LoRA添加一个低秩分解BA,其中B in mathbb{R}^{d times r},A in mathbb{R}^{r times k},r ll min(d, k)。前向传播变为h = W_0x + BAx。LoRA的训练参数量仅为原始模型的0.1%-1%,但可以实现高质量的个性化生成。
IP-Adapter(2023.08):IP-Adapter(Image Prompt Adapter)允许用户使用图像作为提示来引导生成。IP-Adapter使用CLIP的图像编码器提取参考图像的特征,然后通过解耦的交叉注意力机制注入到扩散模型中。与LoRA需要训练不同,IP-Adapter可以直接使用预训练模型,实现”即插即用”的图像提示功能。扩散模型的技术细节:扩散模型的核心是一个马尔可夫链过程。在前向过程中,模型逐步向数据添加高斯噪声,经过T步后,数据几乎变成纯噪声。在反向过程中,模型学习逐步去噪,从噪声中恢复数据。数学上,前向过程可以表示为:
q(x_t | x_{t-1})= mathcal{N}(x_t; sqrt{1-beta_t} x_{t-1}, beta_t I)
反向过程则学习一个神经网络来预测噪声:
p_theta(x_{t-1} |x_t) = mathcal{N}(x_{t-1}; mu_theta(x_t, t), Sigma_theta(x_t, t))
DDPM的关键发现是,直接预测噪声epsilon比预测原始数据x_0更简单有效。这一简化使得扩散模型的训练变得稳定且高效。
扩散模型vs GAN:相比GAN,扩散模型具有以下优势:
- 训练更稳定:不需要对抗训练,避免了GAN的模式坍塌问题
- 覆盖更多模式:扩散模型可以更好地覆盖数据分布的所有模式
- 可逆性:扩散过程是可逆的,支持图像编辑、插值等操作
- 条件生成更灵活:通过分类器引导或无分类器引导,可以灵活控制生成结果
扩散模型的成功标志着生成式AI进入了实用化阶段。从GAN到扩散模型,生成式AI走过了一条从”能生成”到”生成得好”再到”生成得可控”的演进之路。然而,扩散模型的成功主要集中在图像生成领域,如何将这种生成能力扩展到文本、音频、视频等多种模态,成为下一个挑战。这个挑战的答案,将在2023年揭晓。
六、看懂世界——多模态大模型时代来临(2023)
6.1 从图文对齐到图文理解
CLIP实现了图像和文本的语义对齐,但它本质上是一个”对比学习”模型,只能判断图文是否匹配,而无法进行深层次的视觉理解。例如,CLIP可以判断一张图片和”一只猫在沙发上”是否匹配,但无法回答”猫是什么颜色”、”沙发是什么材质”等具体问题。
多模态理解的”最后一公里”在于:如何让大语言模型”看懂”图像,并基于视觉信息进行推理、问答、描述等复杂任务。这一挑战在2023年被攻克。
6.2 代表性模型架构
2023年,学术界和工业界提出了多种多模态大模型架构,核心思想都是将视觉编码器与大语言模型连接起来,让语言模型具备视觉理解能力。
- BLIP-2(Salesforce,2023.01):BLIP-2(Bootstrapping Language-Image Pre-training)提出了Q-Former(Querying Transformer)架构,作为视觉编码器和LLM之间的桥梁。Q-Former使用一组可学习的查询Token(Query Tokens)从冻结的视觉编码器中提取视觉特征,然后通过全连接层映射到LLM的输入空间。BLIP-2的创新在于:通过两阶段预训练(视觉-语言表示学习 + 视觉到语言的生成学习),实现了高效的模态对齐。
- LLaVA(Microsoft,2023.03):LLaVA(Large Language and Vision Assistant)采用了一个极简的架构:CLIP视觉编码器 + 线性投影层 + Vicuna LLM。CLIP提取的视觉特征通过一个可训练的线性投影层映射到LLM的词嵌入空间,然后与文本Token拼接输入LLM。LLaVA使用GPT-4生成的多模态指令跟随数据(158K条)进行微调,展现了强大的多模态对话能力。
- MiniGPT-4(KAUST,2023.04):MiniGPT-4采用了与LLaVA类似的架构:EVA-CLIP视觉编码器 + 单个投影层 + Vicuna LLM。MiniGPT-4的创新在于:使用高质量的多模态数据集进行微调,包括详细图像描述、图像问答等任务。
- Qwen-VL(Alibaba,2023.08):Qwen-VL是阿里通义千问团队开源的多模态大模型,基于Qwen-7B LLM和ViT-G视觉编码器。Qwen-VL支持多图输入、图文交错、位置感知(通过特殊的box Token表示边界框)等功能,在多个基准测试上取得了SOTA性能。
GPT-4V多模态用例
图10:多模态大模型的应用场景,包括图像理解、文档分析、代码生成等
6.3 GPT-4V:多模态理解的里程碑(2023.09)
2023年9月,OpenAI发布了GPT-4V(GPT-4 with Vision),这是GPT-4的多模态版本,可以接受图像输入并进行理解和推理。GPT-4V的发布标志着多模态大模型进入了实用化阶段。
GPT-4V展现了以下能力:
- 复杂图像理解:可以理解包含多个物体、复杂场景的图像,识别物体类别、属性、关系等。
- 文档与图表理解:可以阅读和理解包含文字、表格、图表的文档,提取关键信息,回答相关问题。
- 手写识别:可以识别手写文字,包括数学公式、笔记等。
- 视觉推理:可以基于视觉信息进行逻辑推理,如”图中哪个物体最重”、”这两个人谁更高”等。
- 多模态对话:可以进行多轮对话,结合图像和文本进行交互。
GPT-4V的架构细节并未公开,但据推测,它可能采用了类似Flamingo的架构:使用Perceiver Resampler将视觉特征压缩为固定数量的Token,然后与文本Token交错输入LLM。
6.4 Gemini:谷歌的反击(2023.12)
2023年12月,Google发布了Gemini 1.0,这是Google迄今为止最强大的多模态模型。Gemini从设计之初就是原生多模态的(Natively Multimodal),而非简单地将不同模态的模型拼接在一起。
Gemini 1.0包含三个版本:
- Gemini Ultra:最大规模版本,用于最复杂的任务
- Gemini Pro:平衡性能和效率的版本
- Gemini Nano:轻量级版本,可在移动设备上运行
Gemini在多模态理解方面取得了多项突破:
- 视频理解:Gemini可以理解视频内容,回答关于视频的问题。例如,可以观看一段烹饪视频,然后回答”这道菜需要哪些食材”。
- 多模态推理:Gemini可以结合图像、文本、音频等多种模态进行推理。例如,可以分析一张包含图表的图像,然后回答关于数据趋势的问题。
- 代码生成:Gemini可以根据视觉输入生成代码。例如,可以绘制一个网页草图,Gemini可以生成相应的HTML/CSS代码。
6.5 技术范式的统一
2023年,多模态大模型的技术范式逐渐统一:
- 视觉指令微调(Visual Instruction Tuning):借鉴LLM的指令微调思想,多模态大模型也采用指令跟随数据进行微调。LLaVA使用GPT-4生成的多模态指令数据,包括对话、详细描述、复杂推理等类型。
- 多模态思维链(Multimodal Chain of Thought):将思维链技术扩展到多模态领域,让模型在回答复杂问题时展示推理过程。例如,在回答数学问题时,模型可以展示识别题目、理解题意、分步计算的过程。
- 幻觉问题的挑战:多模态大模型仍然存在幻觉问题,即生成与图像内容不符的描述。例如,模型可能”看到”图像中不存在的物体,或错误描述物体的属性。解决幻觉问题是多模态大模型研究的重要方向。
多模态大模型的成功标志着AI从”单模态理解”走向”多模态理解”。然而,这些模型主要处理静态图像,如何将理解能力扩展到动态视频,成为下一个前沿。这个前沿的突破,将在2024年实现。
七、视频革命——从静态到动态的跨越(2023-2024)
7.1 视频生成的早期探索
视频生成是比图像生成更具挑战性的任务。视频不仅包含空间信息(每帧图像的内容),还包含时间信息(帧与帧之间的运动关系)。早期的视频生成方法主要基于GAN和VAE,但生成的视频存在时长短(通常只有3-4秒)、一致性差(人物或场景在帧间变化)、运动不自然等问题。
Runway Gen-2(2023.06):Runway是AI视频生成领域的先行者。Gen-2基于Stable Diffusion进行扩展,通过添加时序层(Temporal Layers)来建模帧间关系。Gen-2支持文本到视频、图像到视频、视频到视频等多种生成模式,但生成的视频时长仍有限(4秒),且存在明显的闪烁问题。
Pika Labs(2023.11):Pika Labs是另一家AI视频生成初创公司,其产品在视频编辑、风格转换等方面表现突出。Pika采用了混合架构,结合了GAN、VAE和扩散模型的优点。
这些早期探索为后续的技术突破奠定了基础,但真正的革命性突破来自OpenAI的Sora。
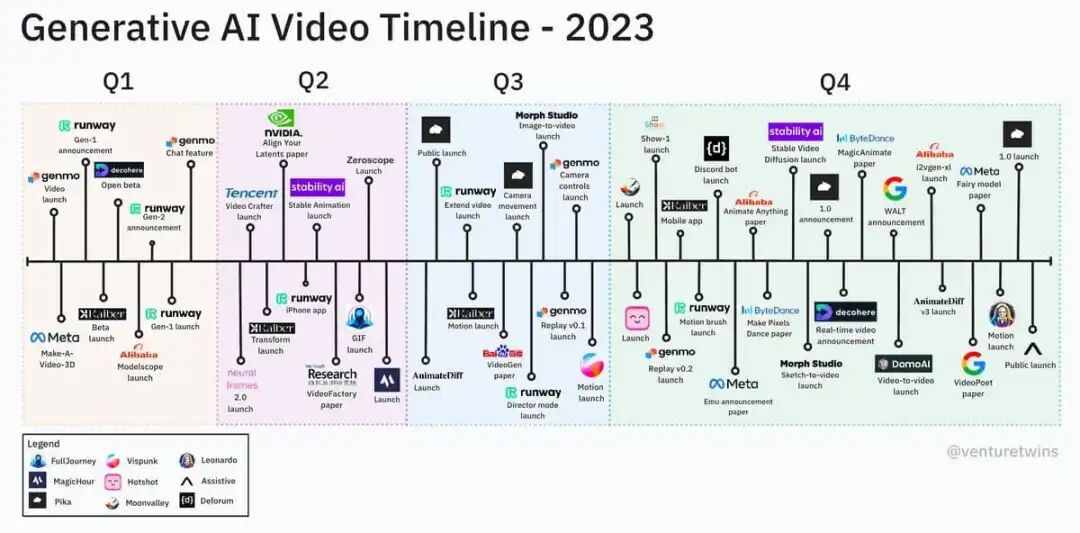
生成式AI视频时间线
图11:生成式AI视频发展历程时间线,从早期探索到Sora的突破
7.2 Sora:世界模拟器的震撼登场(2024.02)
2024年2月16日,OpenAI发布了Sora,这是一个能够生成长达60秒、1080p分辨率视频的文本到视频生成模型。Sora的发布震撼了整个AI界和产业界,其生成视频的质量、一致性和物理合理性远超之前的任何模型。
Sora的核心技术创新包括:
- DiT架构(Diffusion Transformer):Sora采用了DiT架构,将扩散模型与Transformer相结合。传统的扩散模型使用U-Net作为去噪网络,而Sora使用Transformer替代U-Net,实现了更强的扩展性和表达能力。
- 时空联合建模:Sora将视频视为一个4D数据块(高度×宽度×时间×通道),在统一的框架下建模空间和时间信息。具体来说,Sora首先将视频压缩到一个低维的潜空间,然后将潜空间表示切分为时空Patch(Spacetime Patches),这些Patch作为Transformer的输入Token。
- 视频压缩网络:Sora训练了一个视频压缩网络(Video Compression Network),将原始视频压缩到一个低维潜空间。这个压缩网络同时包含空间压缩(类似图像VAE)和时间压缩(建模帧间关系),实现了对视频的高效表示。
- 大规模视频数据训练:Sora在大规模视频数据上进行训练,数据来源包括公开数据集、授权数据以及由专业内容创作者提供的数据。这种大规模训练使得Sora能够学习丰富的物理世界知识。
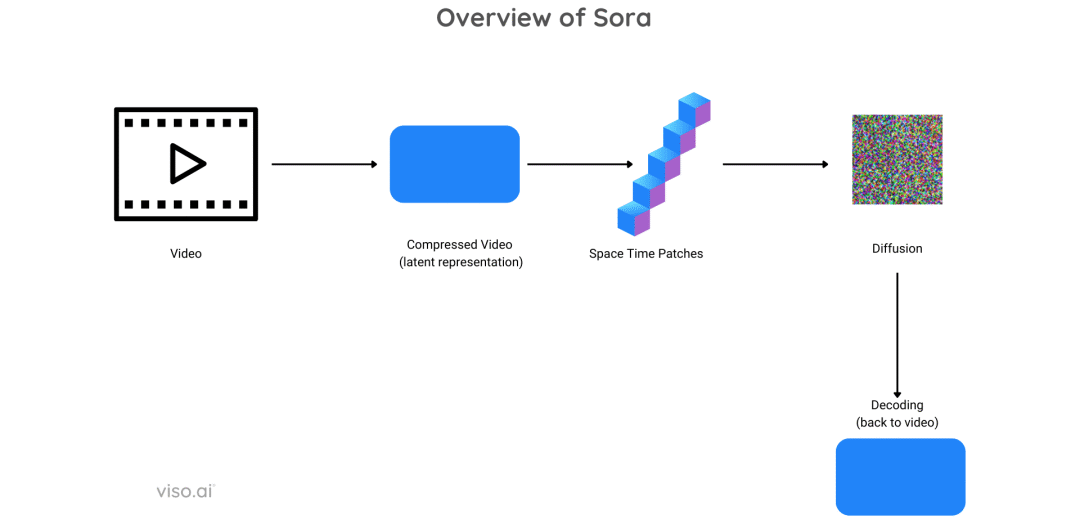
Sora架构概览
图12:Sora视频生成架构概览,展示从文本到视频的生成流程
7.3 Sora的技术突破
Sora的生成能力代表了视频生成技术的重大突破:
- 长视频生成:Sora可以生成最长60秒的视频,远超之前模型的3-4秒。这得益于其高效的时空建模和强大的Transformer架构。
- 时序一致性:Sora生成的视频在时间上具有高度一致性,人物、场景、物体在帧间保持稳定,不会出现明显的闪烁或突变。
- 物理规律理解:Sora展现了一定程度的物理规律理解能力。例如,可以生成人物行走、物体碰撞、液体流动等符合物理常识的视频。
- 镜头语言:Sora可以理解并执行复杂的镜头运动指令,如”摄像机跟随主体移动”、”从远景推近到特写”等。
- 多角色交互:Sora可以在同一场景中生成多个角色,并保持角色之间、角色与环境之间的合理交互。
Sora的技术架构细节:Sora的核心是DiT(Diffusion Transformer)架构,这是将扩散模型与Transformer结合的产物。具体来说,Sora首先使用一个视频压缩网络(Video Compression Network)将输入视频压缩到低维潜空间,这个压缩网络类似于VAE,但专门针对视频进行了优化,可以同时压缩空间和时间维度。
然后,Sora将压缩后的视频表示切分为时空Patch(Spacetime Patches)。每个Patch包含了一定空间区域和时间跨度的信息。这些Patch被展平为Token序列,输入到Transformer中进行处理。Transformer的自注意力机制可以捕捉Patch之间的长距离依赖关系,无论是空间上的还是时间上的。
在训练过程中,Sora学习预测在每一步扩散过程中添加的噪声。通过迭代去噪,Sora可以从纯噪声中生成连贯的视频。条件信息(如文本提示)通过交叉注意力机制注入到模型中,引导生成过程。
7.4 产业影响与争议
Sora的发布引发了广泛的产业影响和学术争议:
- “世界模拟器”的定义之争:OpenAI将Sora称为”世界模拟器”(World Simulator),但这一说法引发了争议。批评者指出,Sora生成的视频中仍然存在物理错误(如物体穿透、重力异常等),它更像是一个”视频生成器”而非真正的”世界模拟器”。
- 影视行业的冲击:Sora的生成能力对影视制作、广告、游戏等行业具有潜在的颠覆性影响。一些从业者担心AI会取代人类创作者,而另一些人则认为AI将成为创作工具,提升生产效率。
- 安全与伦理问题:Sora可以生成高度逼真的虚假视频,可能被用于制作深度伪造(Deepfake)内容,引发虚假信息传播、诈骗等安全问题。OpenAI表示将采取安全措施,包括添加水印、限制敏感内容生成等。
7.5 竞争格局
Sora发布后,国内外多家公司推出了竞争产品:
- 可灵(Kling,快手,2024.06):快手发布的可灵AI是国产视频生成的标杆产品,支持最长2分钟的视频生成,在运动幅度、物理规律理解等方面表现优异。
- Vidu(生数科技,2024.07):清华系创业公司生数科技发布的Vidu,在视频一致性、长视频生成等方面有独特优势。
- Runway Gen-3(2024.06):Runway发布的Gen-3 Alpha,在视频质量、一致性方面有显著提升,追赶Sora的步伐。
- Pika 2.0(2024.12):Pika Labs发布的2.0版本,引入了Scene Ingredients(场景成分)功能,允许用户上传角色、物体、场景等元素,实现更可控的视频生成。
视频生成技术的突破标志着多模态AI从”静态理解”走向”动态生成”。然而,无论是图像生成还是视频生成,这些模型本质上都是”拼接式”的——不同模态的编码器是独立的,信息在模态间传递时存在损失。如何实现真正的”原生多模态”,成为下一个技术前沿。
第八章:原生融合——端到端多模态的崛起(2024)
8.1 拼接式vs原生多模态
在GPT-4o之前,多模态大模型主要采用”拼接式”架构:
- 使用独立的视觉编码器(如CLIP、ViT)提取图像特征
- 使用独立的音频编码器提取音频特征
- 将这些特征通过投影层映射到大语言模型的输入空间
- 大语言模型作为“中央处理器”,融合多模态信息并生成输出
这种架构的问题在于:
- 信息损失:不同模态的编码是独立的,编码器可能丢失对后续任务重要的信息。例如,CLIP的视觉编码器是为图文对齐优化的,可能丢失对精细视觉任务重要的细节。
- 延迟问题:多模态信息需要经过多个独立的编码器处理,增加了端到端的延迟,难以实现实时交互。
- 模态间对齐困难:不同模态的特征空间可能存在差异,对齐不完美会导致理解偏差。
- 原生多模态(Natively Multimodal)则采用完全不同的思路:从设计之初就是一个统一的神经网络,可以同时处理文本、图像、音频、视频等多种模态,所有模态共享同一个表征空间。
GPT-4o多模态能力
图13:GPT-4o的多模态能力展示,包括文本、图像、音频、视频的统一处理
8.2 GPT-4o:全知全能的Omni(2024.05)
2024年5月13日,OpenAI发布了GPT-4o,其中的”o”代表”Omni”(全能)。GPT-4o是OpenAI首个端到端训练的原生多模态模型,可以同时处理文本、图像、音频、视频,并以极低的延迟进行交互。
GPT-4o的核心技术创新包括:
- 端到端统一架构:GPT-4o是一个单一的神经网络,可以同时处理文本、图像、音频、视频。与GPT-4V使用独立的视觉编码器不同,GPT-4o的视觉、音频、文本处理能力都是模型固有的,而非外部模块拼接。
- 232ms延迟:GPT-4o的音频交互延迟平均为232毫秒,接近人类对话的自然节奏(人类对话的平均延迟约为200-300毫秒)。这得益于端到端架构,避免了传统语音交互中”语音→文本→语音”的多步转换延迟。
- 情感语音:GPT-4o可以理解和表达情感,包括非语言信号(如笑声、叹息、语气词)。用户可以说”用兴奋的语气讲一个故事”,GPT-4o会生成带有相应情感色彩的语音。
- 视觉理解增强:GPT-4o的视觉理解能力相比GPT-4V有显著提升,可以处理更高分辨率的图像,理解更复杂的视觉内容(如图表、文档、照片等)。
- 原生图像生成:GPT-4o集成了DALL-E 3的图像生成能力,可以直接生成图像,无需调用外部API。更重要的是,GPT-4o可以以对话方式编辑图像,如”把这张图片中的猫换成狗”。
8.3 Gemini 2.0:谷歌的实时多模态(2024.12)
2024年12月11日,Google发布了Gemini 2.0,这是Google迄今为止最强大的AI模型。Gemini 2.0延续了Gemini 1.0的原生多模态设计理念,并在实时交互、多模态推理、工具使用等方面取得了重大突破。
Gemini 2.0的核心创新包括:
- Multimodal Live API:Gemini 2.0引入了Multimodal Live API,支持实时音视频流输入。用户可以通过摄像头和麦克风与模型进行实时交互,模型可以”看到”和”听到”用户的实时环境,并做出即时响应。
- 原生图像生成:Gemini 2.0 Flash引入了原生图像生成功能,可以直接生成图像,并支持多轮对话式图像编辑。例如,用户可以说”生成一张猫的图片”,然后”让猫戴上帽子”,”把背景换成海滩”等。
- 多模态推理:Gemini 2.0展现了强大的多模态推理能力。例如,可以分析一段视频,理解其中的事件、人物关系、情感变化等,并进行复杂的推理。
- 工具使用:Gemini 2.0原生支持工具使用(Function Calling),可以调用Google搜索、代码执行、第三方API等工具,扩展了模型的能力边界。

Gemini 2.0
图14:Gemini 2.0官方宣传图,展示其多模态实时交互能力
8.4 原生多模态的技术优势
原生多模态相比拼接式多模态具有以下优势:
- 信息无损传递:所有模态共享同一个表征空间,信息在模态间传递时不会损失。
- 跨模态涌现能力:模型可以学习到跨模态的深层关联,产生拼接式架构无法实现的能力。例如,GPT-4o可以根据语音的情感色彩生成相应的图像风格。
- 实时交互体验:端到端架构大幅降低了延迟,实现了接近实时的多模态交互。
- 统一训练优化:所有模态在统一的框架下训练,可以相互促进,提升整体性能。
8.5 应用场景的爆发
原生多模态技术的成熟催生了大量应用场景:
- 实时翻译与字幕:可以实时将语音翻译为另一种语言,并生成同步字幕,支持多模态输入(如手势、表情)。
- 智能客服与陪伴:可以理解用户的语音、图像、视频输入,提供更自然、更智能的交互体验。
- 教育与培训:可以根据学生的学习进度和反馈,动态调整教学内容和方式,支持多模态输入输出。
- 辅助决策与分析:可以综合分析文本报告、数据图表、现场视频等多种信息,为决策提供支持。
- 内容创作:可以同时进行文本写作、图像生成、视频剪辑,成为全能型创作助手。
原生多模态技术的突破标志着AI从”多模态理解”走向”多模态融合”。然而,无论是原生多模态还是拼接式多模态,这些模型本质上都是”被动响应”的——它们接收输入,然后生成输出,缺乏对世界的主动建模和预测能力。如何实现真正的”世界模型”,成为通往AGI的关键一步。
- 原生多模态的技术挑战:尽管原生多模态展现了强大的能力,但它也面临着一些技术挑战:
- 数据收集与对齐:训练原生多模态模型需要大量高质量的跨模态对齐数据。如何收集、清洗、标注这些数据是一个巨大的工程挑战。
- 计算资源需求:原生多模态模型通常比单模态模型更大、更复杂,需要更多的计算资源进行训练和推理。如何在保持性能的同时降低成本,是一个重要的研究方向。
- 模态间的平衡:不同模态的信息密度和重要性可能不同。如何在模型中平衡不同模态的贡献,避免某一模态主导,是一个需要仔细设计的问题。
- 可解释性:原生多模态模型的决策过程更加复杂,难以解释。如何提高模型的可解释性,让用户理解模型为什么会做出某个决策,是一个重要的研究方向。
九、终极形态——世界模型与AGI之路(2024-♾️)
9.1 世界模型的概念起源
“世界模型”(World Model)的概念最早可以追溯到1943年。心理学家Kenneth Craik在其著作《The Nature of Explanation》中提出,人类大脑会构建外部世界的内部模型,用于预测未来事件和指导行为。Craik写道:”如果生物体携带一个外部现实的小规模模型,并在其内部运行可能的行动,就可以预测未来事件,从而选择最优行动。”
这一思想深刻影响了认知科学和人工智能领域。2018年,Yann LeCun在IJCAI的演讲中正式将”世界模型”引入AI领域,提出了”基于模型的强化学习”(Model-Based Reinforcement Learning)框架。LeCun认为,真正的智能需要具备以下能力:
- 感知:(Perception):观察世界,提取状态表示
- 世界模型:(World Model):预测行动的后果
- 代价模型:(Cost Model):评估预测的代价
- 行动器:(Actor):选择最优行动
- 短期记忆:(Short-term Memory):存储历史信息
LeCun强调,当前的大语言模型(如GPT系列)本质上是”自回归模型”,只能根据历史预测下一个Token,缺乏对世界的深层理解和因果推理能力。真正的世界模型应该能够:
- 理解物理规律(如重力、惯性、碰撞)
- 进行因果推理(如“如果我推这个物体,它会怎样”)
- 长期规划(如“为了到达目标,我需要采取哪些步骤”)
- 快速学习(从少量样本中学习新技能)
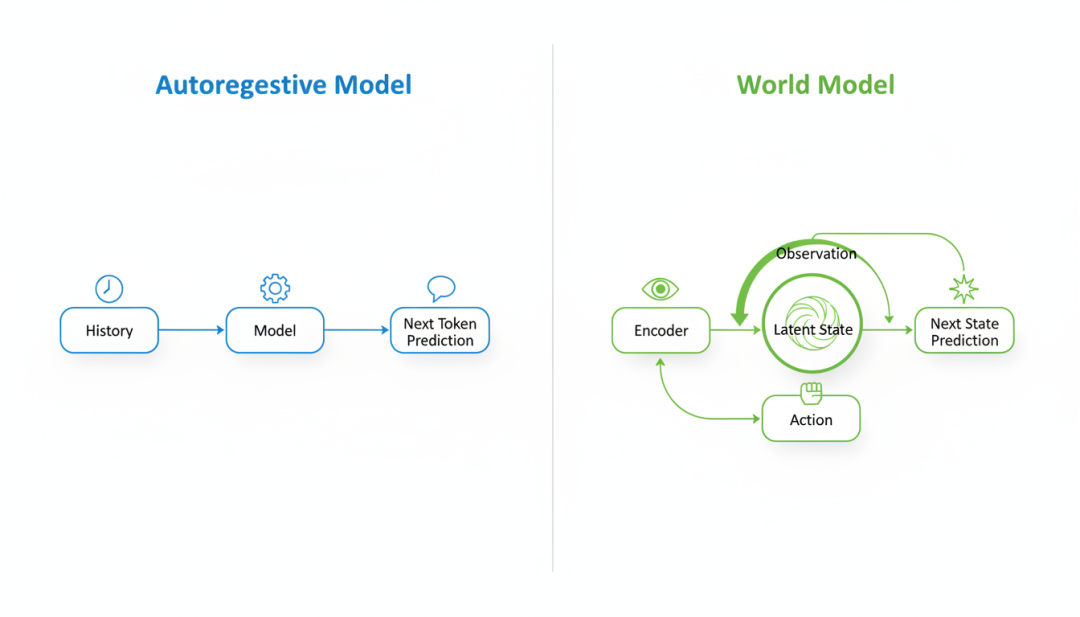
世界模型架构
图15:自回归模型与世界模型的对比,展示世界模型如何通过潜在状态进行预测和规划
9.2 世界模型的两大流派
当前,世界模型的研究主要分为两大流派:
表征派(LeCun的JEPA)
Yann LeCun主张,世界模型应该学习世界的抽象表征,而非像素级细节。他提出了JEPA(Joint Embedding Predictive Architecture,联合嵌入预测架构)框架。
JEPA的核心思想是:
- 使用编码器将输入(如图像)映射到抽象表征空间
- 在表征空间中进行预测,而非像素空间
- 通过对比学习或重建损失训练模型
JEPA的具体实现包括:
- I-JEPA(Image JEPA,2023):在图像表征空间中进行预测。I-JEPA通过掩码预测任务学习视觉表征:给定图像的一部分,预测另一部分的表征。这种方法迫使模型学习语义信息,而非低级像素细节。
- V-JEPA(Video JEPA,2024):将JEPA扩展到视频领域,学习视频的时空表征。V-JEPA通过预测视频中未来帧的表征,学习物理规律和因果关系。
LeCun认为,表征派的优势在于:
- 计算效率高:在抽象空间预测比像素空间更高效
- 泛化能力强:抽象表征更容易迁移到新任务
- 因果推理:抽象空间更适合因果推理
生成派(Sora/Genie)
与表征派不同,生成派主张直接在像素空间进行预测和生成。这一流派的代表是OpenAI的Sora和DeepMind的Genie。
Sora(OpenAI,2024):如前所述,Sora是一个视频生成模型,可以生成长达60秒的高质量视频。OpenAI将Sora称为”世界模拟器”,因为它可以模拟物理世界的某些方面(如物体运动、碰撞、光影等)。Genie(DeepMind,2024.02):Genie是一个交互式世界模型,可以从无标签的视频数据中学习可交互的虚拟环境。给定一张静态图像,Genie可以生成一个可交互的游戏世界,用户可以通过键盘控制角色行动。Genie包含三个组件:
- 潜在动作模型(Latent Action Model):从视频中学习潜在的动作表示
- 视频分词器(Video Tokenizer):将视频压缩为离散的Token
- 动态模型(Dynamics Model):预测给定动作和历史的下一帧
生成派的优势在于:
- 视觉逼真:生成的内容在视觉上高度逼真
- 可交互:用户可以与生成的世界进行交互
- 数据驱动:可以从大量无标签视频数据中学习
9.3 世界模型的核心能力
世界模型的核心能力包括:
因果推断:理解”如果…会怎样”(Counterfactual Reasoning)。例如,理解”如果我推这个物体,它会怎样”、”如果我不采取行动,会发生什么”。
物理直觉:理解基本的物理规律,如:
- 物体恒存(Object Permanence):物体在被遮挡后仍然存在
- 重力:物体会下落
- 惯性:运动的物体会保持运动
- 碰撞:物体碰撞后会反弹或停止
长期规划:基于对未来的预测,制定长期行动计划。例如,为了到达目标,需要采取哪些步骤,每一步的预期结果是什么。
快速学习:从少量样本中学习新技能。人类可以从一次演示中学习一个新任务,世界模型也应该具备这种能力。
9.4 技术挑战与争议
世界模型的研究面临诸多挑战和争议:
- 生成派vs表征派的路线之争:生成派(如Sora)强调像素级生成的视觉逼真性,表征派(如JEPA)强调抽象表征的因果推理能力。哪条路线更接近真正的世界模型,目前尚无定论。
- 物理规律学习的样本效率:当前的世界模型(如Sora)需要海量视频数据才能学习到基本的物理规律,而人类婴儿仅需少量经验就能建立物理直觉。如何提升样本效率是关键挑战。
- 世界模型的评估标准:如何评估一个世界模型的质量?视觉逼真性、物理准确性、因果一致性、交互可控性,哪个更重要?目前缺乏统一的评估标准。
- 与具身智能的结合:世界模型最终需要与物理世界交互。如何将虚拟世界模型迁移到真实世界,是具身智能(Embodied AI)研究的核心问题。
9.5 通往AGI的路径
世界模型被认为是通往通用人工智能(AGI)的关键一步。其潜在路径包括:
- 世界模型作为”认知引擎”:世界模型可以作为AI系统的”认知引擎”,提供对世界的深层理解和预测能力。大语言模型可以作为”语言接口”,与世界模型交互。
- 与具身智能的结合:将世界模型与机器人结合,让AI系统可以在物理世界中学习、推理和行动。这是实现真正智能的必经之路。
- 多模态理解的终极形态:世界模型可以融合视觉、听觉、触觉等多种模态,建立对世界的全面理解。这是多模态AI的终极形态。
- 持续学习与适应:世界模型应该能够持续学习,适应环境的变化。这与人类的终身学习能力类似。
世界模型的研究仍处于早期阶段,但它代表了AI发展的终极愿景:让机器像人类一样理解世界、预测未来、制定计划、采取行动。这一愿景的实现,将标志着通用人工智能的真正到来。
世界模型与多模态AI的关系:世界模型可以看作是多模态AI的终极形态。多模态AI关注如何让机器理解和生成多种模态的内容,而世界模型则更进一步,关注如何让机器理解这些模态背后的物理规律和因果关系。
从CNN到ViT,从CLIP到Sora,从GPT-4o到世界模型,多模态AI走过了一条从”感知”到”理解”再到”建模”的演进之路。每一步突破都让我们离真正的智能更近一步。
十、2025-2026——多模态AI的爆发与深化
10.1 2025年:推理模型的崛起
2025年被业界称为”推理模型元年”。在这一年,各大AI厂商纷纷推出具有深度推理能力的多模态模型,标志着AI从”快速响应”走向”深度思考”。
- Kimi k1.5(月之暗面,2025.01):Kimi k1.5是月之暗面推出的多模态推理模型,其核心创新在于将强化学习(RL)的上下文窗口扩展到128K。通过长思维链(Long-CoT)技术,k1.5能够在回答复杂问题时展示详细的推理过程,包括规划、反思和修正。k1.5采用部分轨迹重采样(Partial Rollouts)技术提升训练效率,在数学推理、代码生成等任务上取得了优异成绩。
- Claude 3.7 Sonnet(Anthropic,2025.02):Claude 3.7 Sonnet引入了”扩展思考模式”(Extended Thinking),允许模型在回答前进行更长时间的推理。其上下文窗口达到200K,支持更长的文档分析和复杂任务处理。
- OpenAI o3系列(2025.04-06):OpenAI在2025年推出了o3系列推理模型,包括o3、o4-mini和o3-pro。o3是OpenAI最强大的推理模型,在编程、数学、科学推理和视觉感知等任务上创下新纪录。o3在Codeforces、SWE-bench和MMMU等基准测试中取得SOTA成绩,相比o1在困难任务上的重大错误减少了20%。o4-mini则是一个更小、更快的推理模型,在AIME 2024和2025上取得了最佳成绩。
- GPT-4.1(OpenAI,2025.04):GPT-4.1支持高达100万Token的上下文窗口,在编码、指令遵循和长上下文处理方面有显著提升。
- Qwen3系列(阿里,2025.05):阿里发布了Qwen3系列模型,包括Qwen3-235B-A22B,这是一个混合专家(MoE)架构的大型语言模型,总参数量235B,激活参数22B。Qwen3支持”思考模式”和”非思考模式”的混合推理,在多语言指令遵循和智能体能力方面表现出色。
10.2 2025年:视频生成的全面爆发
2025年,视频生成技术迎来了全面爆发期。
- 可灵2.1(快手,2025.05):快手的可灵AI升级至2.1版本,在运动幅度、物理规律理解和视频一致性方面有显著提升。
- Midjourney V1视频模型(2025.06):Midjourney发布了其首款视频生成模型V1,将其在图像生成领域的艺术美学优势延伸至视频领域。
- Wan2.2(阿里,2025.07):阿里开源的视频生成模型Wan升级至2.2版本,进一步提升了视频生成的质量和可控性。
- Google Veo 3.0(2025.05):Google的视频生成模型Veo升级至3.0版本,在视频质量和时长方面都有显著提升。
10.3 2025年:原生多模态的持续演进
Gemini 2.5系列(Google,2025):Google在2025年持续升级Gemini 2.5系列,包括Gemini 2.5 Flash、Gemini 2.5 Pro等版本。5月,Google推出了Gemini Diffusion扩散模型和Gemini 2.5 Pro Deep Think深度思考模式。8月,Gemini 2.5 Flash Image发布,在图像生成领域取得突破。
豆包Seed1.5-VL(字节跳动,2025.05):字节跳动发布了多模态推理模型Seed1.5-VL,在视觉问答、图文匹配等任务上表现出色。
Qwen2.5-Omni(阿里,2025.03):Qwen2.5-Omni是一个全模态模型,支持文本、图像、音频、视频的连续流式处理。其架构分为”思考者”(Thinker)和”说话者”(Talker)两部分,通过TMRoPE位置编码实现同步多模态处理。
10.4 2025年:开源模型的繁荣
2025年,开源多模态模型生态持续繁荣。
- DeepSeek-V3.1(深度求索,2025.08):DeepSeek发布了混合推理模型V3.1,在推理能力和多模态理解方面有显著提升。
- GLM-4.5系列(智谱AI,2025):智谱AI发布了GLM-4.5系列,包括GLM-4.5、GLM-4.5-X推理模型和GLM-4.5V多模态模型。
- gpt-oss(OpenAI,2025.08):OpenAI罕见地开源了两个推理模型gpt-oss-120b和gpt-oss-20b,支持函数调用和结构化输出,可在自有基础设施上运行。
- Flux.1 Kontext(Black Forest Labs,2025.08):开源图像生成模型Flux升级至Kontext版本,在上下文理解和图像编辑方面有显著提升。
10.5 2026年1-2月:ViT-5与现代视觉Transformer
2026年2月8日,ViT-5论文发布,标志着视觉Transformer进入现代化新阶段。
ViT-5的核心创新:
- LayerScale:在每个块的输出引入可学习的缩放因子,提升训练稳定性
- RMSNorm:用RMSNorm替代LayerNorm,减少计算开销
- 2D RoPE:采用二维旋转位置编码,增强空间建模能力
- Register Tokens:引入寄存器Token,抑制注意力伪影
- QK-Norm:对Query和Key进行归一化,提升训练稳定性
ViT-5在ImageNet-1K上,Base模型达到84.2%的top-1准确率,超过DeiT-III-Base的83.8%;Large模型在384×384分辨率下达到86.0%,显著超越之前的ViT架构。
十一、总结与展望
10.1 多模态AI演进的核心规律
回顾多模态AI十余年的发展历程,可以总结出以下核心规律:
- 从专用到通用:从CNN时代的专用视觉模型,到ViT的通用视觉架构,再到原生多模态的统一模型,AI系统的能力越来越通用,适用范围越来越广。
- 从拼接端到原生:从拼接式多模态(独立编码器+LLM)到原生多模态(统一神经网络),模态间的信息传递越来越无缝,融合越来越深入。
- 从感知到理解到生成:从CNN的图像分类(感知),到CLIP的图文对齐(理解),到扩散模型的图像生成(生成),再到Sora的视频生成(动态生成),AI的能力从”看懂”走向”创造”。
- 从静态到动态:从静态图像的理解和生成,到动态视频的生成,AI对世界的建模从”快照”走向”过程”。
- 从被动到主动:从被动响应输入的模型,到主动预测未来的世界模型,AI的行为模式从”反应式”走向”前瞻式”。
10.2 技术范式的三次跃迁
多模态AI的发展历程可以概括为三次技术范式的跃迁:
第一次跃迁:CNN时代(2012-2017)——从手工特征到学习特征
AlexNet的成功证明了深度学习可以自动从数据中学习特征表示,无需人工设计特征提取器。这一跃迁标志着机器学习从”特征工程”走向”表示学习”。
第二次跃迁:Transformer时代(2017-2023)——从模态壁垒到统一架构
Transformer架构首先在NLP领域取得成功,随后通过ViT扩展到视觉领域,再通过CLIP实现图文对齐,最终通过原生多模态模型实现真正的统一。这一跃迁标志着AI从”单模态专家”走向”多模态通才”。
第三次跃迁:原生多模态与世界模型时代(2024-♾️)——从拼接融合到端到端统一
GPT-4o和Gemini 2.0代表的原生多模态,以及Sora、JEPA代表的世界模型,标志着AI从”拼接式多模态”走向”端到端统一”,再到seedance2.0和see dream5.0的开年王炸,这一跃迁将为通往AGI铺平道路。
写到最后
多模态AI的发展历程,是人类不断拓展认知边界、追求智能本质的生动写照。从CNN到世界模型,每一步突破都凝聚着无数研究者的智慧与汗水。我们有理由相信,在不远的将来,多模态AI将成为人类探索世界、创造未来的强大工具,为人类社会带来前所未有的变革。
参考文献
1. Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. NeurIPS.
2. Goodfellow, I., et al. (2014). Generative adversarial nets. NeurIPS.
3. Dosovitskiy, A., et al. (2020). An image is worth 16×16 words: Transformers for image recognition at scale. ICLR.
4. Radford, A., et al. (2021). Learning transferable visual models from natural language supervision. ICML.
5. Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. NeurIPS.
6. Rombach, R., et al. (2022). High-resolution image synthesis with latent diffusion models. CVPR.
7. Liu, H., et al. (2023). Visual instruction tuning. NeurIPS.
8. OpenAI. (2024). Video generation models as world simulators. Technical Report.
9. LeCun, Y. (2022). A path towards autonomous machine intelligence. Open Review.
10. Assran, M., et al. (2023). Self-supervised learning from images with a joint-embedding predictive architecture. CVPR.
本文由 @卡萨丁AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


